Python线性回归实战分析
一、线性回归的理论
1)线性回归的基本概念
线性回归是一种有监督的学习算法,它介绍的自变量的和因变量的之间的线性的相关关系,分为一元线性回归和多元的线性回归。一元线性回归是一个自变量和一个因变量间的回归,可以看成是多远线性回归的特例。线性回归可以用来预测和分类,从回归方程可以看出自变量和因变量的相互影响关系。
线性回归模型如下:
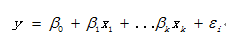
对于线性回归的模型假定如下:
(1) 误差项的均值为0,且误差项与解释变量之间线性无关
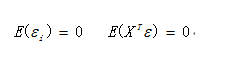
(2) 误差项是独立同分布的,即每个误差项之间相互独立且每个误差项的方差是相等的。
(3) 解释变量之间线性无关
(4) 正态性假设,即误差项是服从正态分布的
以上的假设是建立回归模型的基本条件,所以对于回归结果要进行一一验证,如果不满足假定,就要进行相关的修正。
2) 模型的参数求解
(1)矩估计
一般是通过样本矩来估计总体的参数,常见是样本的一阶原点矩来估计总体的均值,二阶中心矩来估计总体的方差。
(2)最小二乘估计
一般最小二乘估计是适用于因变量是连续型的变量,最常用的是普通最小二乘法( Ordinary Least Square,OLS),它的原理是所选择的回归模型应该使所有观察值的残差平方和达到最小。预测值用 表示,对应的实际值 ,残差平方和 ,最小二乘估计是求得参数的值,使得L最小。对于线性回归求得的参数值是唯一的。
(3)极大似然估计
极大似然估计是基于概率的思想,它要求样本的概率分布是已知的,参数估计的值是使得大量样本发生的概率最大,用似然函数来度量,似然函数是各个样本的密度函数的乘积,为方便求解对其求对数,加负号求解极小值,得到参数的估计结果。
3)模型的优缺点
优点:结果易于理解,计算上不复杂
缺点:对于非线性的数据拟合不好
二、用Python实现线性回归的小例子
数据来源于网络爬虫,武汉市商品房价格为因变量和几个相关关键词的百度指数的搜索量为自变量。
由于本文的自变量有98个,首先进行自变量的选择,先是通过相关系数矩阵筛选掉不相关的变量,根据Pearson相关系数矩阵进行变量的选取,一般选取相关系数的值大于0.3的变量进行回归分析,由于本文的变量较多,先进行手动筛选然后利用相关系数进行选取,本文选取相关系数大于0.55的变量进行回归分析。
经过相关系数的分析选取8个变量进行下一步的分析,分析的Python代码如下:
# -*- coding: utf-8 -*-
#### Required Packages
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import statsmodels.api as sm
data = pd.read_csv('Hdata.csv')
print data
dataset = np.array(data)
######相关性分析
X = dataset[:,1:98]
y = dataset[:,0]
cor = np.corrcoef(dataset,rowvar=0)[:,0]
######输出相关矩阵的第一列
print cor
#######筛选后的数据读取
data1 = pd.read_csv('H1data.csv')
dataset1 = np.array(data)
######筛选后的变量######
X1 = dataset1[:,1:8]
Y1 = dataset1[:,0]
est = sm.OLS(Y1,X1).fit()
print est.summary()
贴出线性回归的结果如下:
OLS RegressionResults
=======================================================================
Dep. Variable: y R-squared: 0.978
Model: OLS Adj. R-squared: 0.974
Method: Least Squares F-statistic: 287.5
Date: Sat, 08 Apr 2017 Prob (F-statistic): 9.35e-36
Time: 15:15:14 Log-Likelihood: -442.82
No. Observations: 53 AIC: 899.6
Df Residuals: 46 BIC: 913.4
Df Model: 7
Covariance Type: nonrobust
=======================================================================
coef std err t P>|t| [95.0% Conf. Int.]
-----------------------------------------------------------------------
x1 -0.3691 0.494 -0.747 0.0459 -1.364 0.626
x2 0.3249 0.353 0.920 0.0362 -0.386 1.036
x3 1.0987 0.837 1.312 0.0196 -0.587 2.784
x4 0.7613 0.790 0.964 0.0340 -0.829 2.351
x5 -1.5766 1.099 -1.435 0.0158 -3.789 0.636
x6 -0.1572 1.077 -0.146 0.0885 -2.325 2.011
x7 3.2003 1.603 1.997 0.052 -0.026 6.427
=======================================================================
Omnibus: 0.413 Durbin-Watson: 1.748
Prob(Omnibus): 0.814 Jarque-Bera (JB): 0.100
Skew: 0.097 Prob(JB): 0.951
Kurtosis: 3.089 Cond. No. 95.5
=======================================================================
从回归分析的结果可以看出来,模型的拟合优度R-squared=0.978,说明模型的拟合效果很好,据其大小对拟合效果的优劣性进行判定。对模型整体的显著性可以通过F统计量来看,结果显示的F统计量对应的P值显著小于0.05(0.05是显著性水平,也可以选取0.01),说明模型整体是显著的,它的显著性说明被解释变量能不能由这些解释变量进行解释,F检验是对整体的检验,F检验的通过不代表每一个解释变量是显著的。对每一个变量的显著性要看t检验统计量的值,t检验统计量对应的P值小于0.05(0.01或者0.1也行,具体看情况分析,一般选取0.05)视为是显著的,从结果可以看出,X6和X7的变量的p是大于0.05的,也就是这两个变量对被解释变量的影响是不显著的要剔除。但是如果你只是关心预测的问题那么可以不剔除。但是如果有研究解释变量对被解释变量的影响的程度的,要做进一步的研究。接下来看DW的值,DW的值为1.748,说明模型不存在自相关性。看JB检验统计量的值,JB检验统计量是对正态性的假设进行检验的,JB的值对应的p值为0.951显著大于0.05,可以认为模型满足正态性的假设的。对于参数的实际意义本文就不做解释了。
对于DW值判断相关性的依据如下:
DW=0时,残差序列存在完全正自相关,
DW=(0,2)时,残差序列存在正自相关,
DW=2时,残差序列无自相关,
DW=(2,4)时,残差序列存在负自相关,
DW=4时,残差序列存在完全负自相关。
对于建立模型的一般步骤简单描述如下:
(1) 根据数据的表现形式选取合适的模型
(2) 对选取的模型选取适用的参数估计方法
(3) 对参数的结果进行检验
(4) 对结果进行解释
您可能感兴趣的文章:
- Python编程实现线性回归和批量梯度下降法代码实例
- Python数据拟合与广义线性回归算法学习
- Python编程实现使用线性回归预测数据
- python编程线性回归代码示例
- Python scikit-learn 做线性回归的示例代码
相关推荐
-

python编程线性回归代码示例
用python进行线性回归分析非常方便,有现成的库可以使用比如:numpy.linalog.lstsq例子.scipy.stats.linregress例子.pandas.ols例子等. 不过本文使用sklearn库的linear_model.LinearRegression,支持任意维度,非常好用. 一.二维直线的例子 预备知识:线性方程y=a∗x+b.y=a∗x+b表示平面一直线 下面的例子中,我们根据房屋面积.房屋价格的历史数据,建立线性回归模型. 然后,根据给出的房屋面积,来预测房屋价格
-
Python scikit-learn 做线性回归的示例代码
一.概述 机器学习算法在近几年大数据点燃的热火熏陶下已经变得被人所"熟知",就算不懂得其中各算法理论,叫你喊上一两个著名算法的名字,你也能昂首挺胸脱口而出.当然了,算法之林虽大,但能者还是有限,能适应某些环境并取得较好效果的算法会脱颖而出,而表现平平者则被历史所淡忘.随着机器学习社区的发展和实践验证,这群脱颖而出者也逐渐被人所认可和青睐,同时获得了更多社区力量的支持.改进和推广. 以最广泛的分类算法为例,大致可以分为线性和非线性两大派别.线性算法有著名的逻辑回归.朴素贝叶斯.最大熵等,
-
Python数据拟合与广义线性回归算法学习
机器学习中的预测问题通常分为2类:回归与分类. 简单的说回归就是预测数值,而分类是给数据打上标签归类. 本文讲述如何用Python进行基本的数据拟合,以及如何对拟合结果的误差进行分析. 本例中使用一个2次函数加上随机的扰动来生成500个点,然后尝试用1.2.100次方的多项式对该数据进行拟合. 拟合的目的是使得根据训练数据能够拟合出一个多项式函数,这个函数能够很好的拟合现有数据,并且能对未知的数据进行预测. 代码如下: import matplotlib.pyplot as plt import
-
Python编程实现使用线性回归预测数据
本文中,我们将进行大量的编程--但在这之前,我们先介绍一下我们今天要解决的实例问题. 1) 预测房子价格 房价大概是我们中国每一个普通老百姓比较关心的问题,最近几年保障啊,小编这点微末工资着实有点受不了. 我们想预测特定房子的价值,预测依据是房屋面积. 2) 预测下周哪个电视节目会有更多的观众 闪电侠和绿箭侠是我最喜欢的电视节目,特别是绿箭侠,当初追的昏天黑地的,不过后来由于一些原因,没有接着往下看.我想看看下周哪个节目会有更多的观众. 3) 替换数据集中的缺失值 我们经常要和带有缺失值的数据集
-
Python编程实现线性回归和批量梯度下降法代码实例
通过学习斯坦福公开课的线性规划和梯度下降,参考他人代码自己做了测试,写了个类以后有时间再去扩展,代码注释以后再加,作业好多: import numpy as np import matplotlib.pyplot as plt import random class dataMinning: datasets = [] labelsets = [] addressD = '' #Data folder addressL = '' #Label folder npDatasets = np.zer
-
Python线性回归实战分析
一.线性回归的理论 1)线性回归的基本概念 线性回归是一种有监督的学习算法,它介绍的自变量的和因变量的之间的线性的相关关系,分为一元线性回归和多元的线性回归.一元线性回归是一个自变量和一个因变量间的回归,可以看成是多远线性回归的特例.线性回归可以用来预测和分类,从回归方程可以看出自变量和因变量的相互影响关系. 线性回归模型如下: 对于线性回归的模型假定如下: (1) 误差项的均值为0,且误差项与解释变量之间线性无关 (2) 误差项是独立同分布的,即每个误差项之间相互独立且每个误差项的方差是相等的
-
Python爬虫实战:分析《战狼2》豆瓣影评
刚接触python不久,做一个小项目来练练手.前几天看了<战狼2>,发现它在最新上映的电影里面是排行第一的,如下图所示.准备把豆瓣上对它的影评做一个分析. 目标总览 主要做了三件事: 抓取网页数据 清理数据 用词云进行展示 使用的python版本是3.5. 一.抓取网页数据 第一步要对网页进行访问,python中使用的是urllib库.代码如下: from urllib import request resp = request.urlopen('https://movie.douban.co
-
Python爬虫eval实现看漫画漫画柜mhgui实战分析
目录 ️ 看漫画MHG mhgui 实战分析 通过开发者工具的 DOM 事件绑定器 截取相应的代码文件 eval 函数解析 ️ 看漫画MHG mhgui 实战分析 本文所有MHG使用 MHG 替代~ 本次爬虫采集的案例是MHG,该站点貌似本身就游走在法律的边缘. 站点地址直接检索即可进入,在该目标站点,橡皮擦发现了 eval 加密的双重用法. 页面所有点位都无太大难点,而且漫画超多,但是当点击详情页的时候,发现加密点位了. https://i.看评论区.com/ps1/u/17287/cmdty
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境
-
Python爬虫实战之爬取携程评论
一.分析数据源 这里的数据源是指html网页?还是Aajx异步.对于爬虫初学者来说,可能不知道怎么判断,这里辰哥也手把手过一遍. 提示:以下操作均不需要登录(当然登录也可以) 咱们先在浏览器里面搜索携程,然后在携程里面任意搜索一个景点:长隆野生动物世界,这里就以长隆野生动物世界为例,讲解如何去爬取携程评论数据. 页面下方则是评论数据 从上面两张图可以看出,点击评论下一页,浏览器的链接没有变化,说明数据是Ajax异步请求.因此我们就找到了数据是异步加载过来的,这时候需要去network里面是查
-
Python爬虫实战之使用Scrapy爬取豆瓣图片
使用Scrapy爬取豆瓣某影星的所有个人图片 以莫妮卡·贝鲁奇为例 1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目 创建的项目结构如下 2.为了方便使用pycharm执行scrapy项目,新建main.py from scrapy import cmdline cmdline.execute("scrapy crawl banciyuan".split()) 再edit configuration 然后
-
python爬虫实战之制作属于自己的一个IP代理模块
一.使用PyChram的正则 首先,小编讲的不是爬取ip,而是讲了解PyCharm的正则,这里讲的正则不是Python的re模块哈! 而是PyCharm的正则功能,我们在PyChram的界面上按上Ctrl+R,可以发现,这里出现两行输入框 现在如果小编想把如下数据转换成一个字典存储 读者也许会一个一去改,但是小编只需在上述的那两个输入框内,输入一串字符串即可. 只需在第一个输入框中,输入(.*) : (.*) 在第二个输入框中,输入"$1":"$2",,看看效果如何
-
Python爬虫实战之用selenium爬取某旅游网站
一.selenium实战 这里我们只会用到很少的selenium语法,我这里就不补充别的用法了,以实战为目的 二.打开艺龙网 可以直接点击这里进入:艺龙网 这里是主页 三.精确目标 我们的目标是,鹤壁市,所以我们应该先点击搜索框,然后把北京删掉,替换成鹤壁市,那么怎么通过selenium实现呢? 打开pycharm,新建一个叫做艺龙网的py文件,先导包: from selenium import webdriver import time # 导包 driver = webdriver.Chro
-
Python趣味实战之手把手教你实现举牌小人生成器
Selenium库的安装与简单使用 1. 安装selenium库 pip install selenium 结果如下: 2. chromedriver驱动的配置 如果你想要驱动谷歌浏览器,自动打开浏览器,必须匹配chromedriver驱动,否则会报错. 配置chromedriver驱动,一定要注意 "驱动" 和 "谷歌浏览器" 版本一定是要相匹配,否则不能使用. ① 检查谷歌浏览器的版本 这里首先提供一个详细的地址供大家查看: https://jingyan.b
-
Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session