深入理解python多进程编程
1、python多进程编程背景
python中的多进程最大的好处就是充分利用多核cpu的资源,不像python中的多线程,受制于GIL的限制,从而只能进行cpu分配,在python的多进程中,适合于所有的场合,基本上能用多线程的,那么基本上就能用多进程。
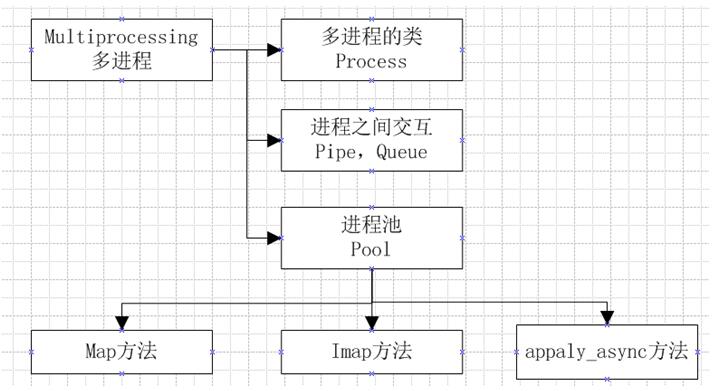
在进行多进程编程的时候,其实和多线程差不多,在多线程的包threading中,存在一个线程类Thread,在其中有三种方法来创建一个线程,启动线程,其实在多进程编程中,存在一个进程类Process,也可以使用那集中方法来使用;在多线程中,内存中的数据是可以直接共享的,例如list等,但是在多进程中,内存数据是不能共享的,从而需要用单独的数据结构来处理共享的数据;在多线程中,数据共享,要保证数据的正确性,从而必须要有所,但是在多进程中,锁的考虑应该很少,因为进程是不共享内存信息的,进程之间的交互数据必须要通过特殊的数据结构,在多进程中,主要的内容如下图:
2、多进程的类Process
多进程的类Process和多线程的类Thread差不多的方法,两者的接口基本相同,具体看以下的代码:
#!/usr/bin/env python
from multiprocessing import Process
import os
import time
def func(name):
print 'start a process'
time.sleep(3)
print 'the process parent id :',os.getppid()
print 'the process id is :',os.getpid()
if __name__ =='__main__':
processes = []
for i in range(2):
p = Process(target=func,args=(i,))
processes.append(p)
for i in processes:
i.start()
print 'start all process'
for i in processes:
i.join()
#pass
print 'all sub process is done!'
在上面例子中可以看到,多进程和多线程的API接口是一样一样的,显示创建进程,然后进行start开始运行,然后join等待进程结束。
在需要执行的函数中,打印出了进程的id和pid,从而可以看到父进程和子进程的id号,在linu中,进程主要是使用fork出来的,在创建进程的时候可以查询到父进程和子进程的id号,而在多线程中是无法找到线程的id,执行效果如下:
start all process start a process start a process the process parent id : 8036 the process parent id : 8036 the process id is : 8037 the process id is : 8038 all sub process is done!
在操作系统中查询的id的时候,最好用pstree,清晰:
├─sshd(1508)─┬─sshd(2259)───bash(2261)───python(7520)─┬─python(7521)
│ │ ├─python(7522)
│ │ ├─python(7523)
│ │ ├─python(7524)
│ │ ├─python(7525)
│ │ ├─python(7526)
│ │ ├─python(7527)
│ │ ├─python(7528)
│ │ ├─python(7529)
│ │ ├─python(7530)
│ │ ├─python(7531)
│ │ └─python(7532)
在进行运行的时候,可以看到,如果没有join语句,那么主进程是不会等待子进程结束的,是一直会执行下去,然后再等待子进程的执行。
在多进程的时候,说,我怎么得到多进程的返回值呢?然后写了下面的代码:
#!/usr/bin/env python
import multiprocessing
class MyProcess(multiprocessing.Process):
def __init__(self,name,func,args):
super(MyProcess,self).__init__()
self.name = name
self.func = func
self.args = args
self.res = ''
def run(self):
self.res = self.func(*self.args)
print self.name
print self.res
return (self.res,'kel')
def func(name):
print 'start process...'
return name.upper()
if __name__ == '__main__':
processes = []
result = []
for i in range(3):
p = MyProcess('process',func,('kel',))
processes.append(p)
for i in processes:
i.start()
for i in processes:
i.join()
for i in processes:
result.append(i.res)
for i in result:
print i
尝试从结果中返回值,从而在主进程中得到子进程的返回值,然而,,,并没有结果,后来一想,在进程中,进程之间是不共享内存的 ,那么使用list来存放数据显然是不可行的,进程之间的交互必须依赖于特殊的数据结构,从而以上的代码仅仅是执行进程,不能得到进程的返回值,但是以上代码修改为线程,那么是可以得到返回值的。
3、进程间的交互Queue
进程间交互的时候,首先就可以使用在多线程里面一样的Queue结构,但是在多进程中,必须使用multiprocessing里的Queue,代码如下:
#!/usr/bin/env python
import multiprocessing
class MyProcess(multiprocessing.Process):
def __init__(self,name,func,args):
super(MyProcess,self).__init__()
self.name = name
self.func = func
self.args = args
self.res = ''
def run(self):
self.res = self.func(*self.args)
def func(name,q):
print 'start process...'
q.put(name.upper())
if __name__ == '__main__':
processes = []
q = multiprocessing.Queue()
for i in range(3):
p = MyProcess('process',func,('kel',q))
processes.append(p)
for i in processes:
i.start()
for i in processes:
i.join()
while q.qsize() > 0:
print q.get()
其实这个是上面例子的改进,在其中,并没有使用什么其他的代码,主要就是使用Queue来保存数据,从而可以达到进程间交换数据的目的。
在进行使用Queue的时候,其实用的是socket,感觉,因为在其中使用的还是发送send,然后是接收recv。
在进行数据交互的时候,其实是父进程和所有的子进程进行数据交互,所有的子进程之间基本是没有交互的,除非,但是,也是可以的,例如,每个进程去Queue中取数据,但是这个时候应该是要考虑锁,不然可能会造成数据混乱。
4、 进程之间交互Pipe
在进程之间交互数据的时候还可以使用Pipe,代码如下:
#!/usr/bin/env python
import multiprocessing
class MyProcess(multiprocessing.Process):
def __init__(self,name,func,args):
super(MyProcess,self).__init__()
self.name = name
self.func = func
self.args = args
self.res = ''
def run(self):
self.res = self.func(*self.args)
def func(name,q):
print 'start process...'
child_conn.send(name.upper())
if __name__ == '__main__':
processes = []
parent_conn,child_conn = multiprocessing.Pipe()
for i in range(3):
p = MyProcess('process',func,('kel',child_conn))
processes.append(p)
for i in processes:
i.start()
for i in processes:
i.join()
for i in processes:
print parent_conn.recv()
在以上代码中,主要是使用Pipe中返回的两个socket来进行传输和接收数据,在父进程中,使用的是parent_conn,在子进程中使用的是child_conn,从而子进程发送数据的方法send,而在父进程中进行接收方法recv
最好的地方在于,明确的知道收发的次数,但是如果某个出现异常,那么估计pipe不能使用了。
5、进程池pool
其实在使用多进程的时候,感觉使用pool是最方便的,在多线程中是不存在pool的。
在使用pool的时候,可以限制每次的进程数,也就是剩余的进程是在排队,而只有在设定的数量的进程在运行,在默认的情况下,进程是cpu的个数,也就是根据multiprocessing.cpu_count()得出的结果。
在poo中,有两个方法,一个是map一个是imap,其实这两方法超级方便,在执行结束之后,可以得到每个进程的返回结果,但是缺点就是每次的时候,只能有一个参数,也就是在执行的函数中,最多是只有一个参数的,否则,需要使用组合参数的方法,代码如下所示:
#!/usr/bin/env python
import multiprocessing
def func(name):
print 'start process'
return name.upper()
if __name__ == '__main__':
p = multiprocessing.Pool(5)
print p.map(func,['kel','smile'])
for i in p.imap(func,['kel','smile']):
print i
在使用map的时候,直接返回的一个是一个list,从而这个list也就是函数执行的结果,而在imap中,返回的是一个由结果组成的迭代器,如果需要使用多个参数的话,那么估计需要*args,从而使用参数args。
在使用apply.async的时候,可以直接使用多个参数,如下所示:
#!/usr/bin/env python
import multiprocessing
import time
def func(name):
print 'start process'
time.sleep(2)
return name.upper()
if __name__ == '__main__':
results = []
p = multiprocessing.Pool(5)
for i in range(7):
res = p.apply_async(func,args=('kel',))
results.append(res)
for i in results:
print i.get(2.1)
在进行得到各个结果的时候,注意使用了一个list来进行append,要不然在得到结果get的时候会阻塞进程,从而将多进程编程了单进程,从而使用了一个list来存放相关的结果,在进行得到get数据的时候,可以设置超时时间,也就是get(timeout=5),这种设置。
总结:
在进行多进程编程的时候,注意进程之间的交互,在执行函数之后,如何得到执行函数的结果,可以使用特殊的数据结构,例如Queue或者Pipe或者其他,在使用pool的时候,可以直接得到结果,map和imap都是直接得到一个list和可迭代对象,而apply_async得到的结果需要用一个list装起来,然后得到每个结果。
以上这篇深入理解python多进程编程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python多进程分块读取超大文件的方法
本文实例讲述了Python多进程分块读取超大文件的方法.分享给大家供大家参考,具体如下: 读取超大的文本文件,使用多进程分块读取,将每一块单独输出成文件 # -*- coding: GBK -*- import urlparse import datetime import os from multiprocessing import Process,Queue,Array,RLock """ 多进程分块读取文件 """ WORKERS = 4
-
初步解析Python下的多进程编程
要让Python程序实现多进程(multiprocessing),我们先了解操作系统的相关知识. Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊.普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回. 子进程永远返回0,而父进程返回子进程的ID.这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用get
-
浅析Python中的多进程与多线程的使用
在批评Python的讨论中,常常说起Python多线程是多么的难用.还有人对 global interpreter lock(也被亲切的称为"GIL")指指点点,说它阻碍了Python的多线程程序同时运行.因此,如果你是从其他语言(比如C++或Java)转过来的话,Python线程模块并不会像你想象的那样去运行.必须要说明的是,我们还是可以用Python写出能并发或并行的代码,并且能带来性能的显著提升,只要你能顾及到一些事情.如果你还没看过的话,我建议你看看Eqbal Quran的文章
-
Python多线程、异步+多进程爬虫实现代码
安装Tornado 省事点可以直接用grequests库,下面用的是tornado的异步client. 异步用到了tornado,根据官方文档的例子修改得到一个简单的异步爬虫类.可以参考下最新的文档学习下. pip install tornado 异步爬虫 #!/usr/bin/env python # -*- coding:utf-8 -*- import time from datetime import timedelta from tornado import httpclient, g
-
Python多进程同步简单实现代码
本文讲述了Python多进程同步简单实现代码.分享给大家供大家参考,具体如下: #encoding=utf8 from multiprocessing import Process, Lock def func(lock, a): lock.acquire() print a lock.release() if __name__ == '__main__': lock = Lock() workers = [] # 创建两个进程 for i in range(0, 2): p = Process
-
Python多进程机制实例详解
本文实例讲述了Python多进程机制.分享给大家供大家参考.具体如下: 在以前只是接触过PYTHON的多线程机制,今天搜了一下多进程,相关文章好像不是特别多.看了几篇,小试了一把.程序如下,主要内容就是通过PRODUCER读一个本地文件,一行一行的放到队列中去.然后会有相应的WORKER从队列中取出这些行. import multiprocessing import os import sys import Queue import time def writeQ(q,obj): q.put(o
-

深入理解python多进程编程
1.python多进程编程背景 python中的多进程最大的好处就是充分利用多核cpu的资源,不像python中的多线程,受制于GIL的限制,从而只能进行cpu分配,在python的多进程中,适合于所有的场合,基本上能用多线程的,那么基本上就能用多进程. 在进行多进程编程的时候,其实和多线程差不多,在多线程的包threading中,存在一个线程类Thread,在其中有三种方法来创建一个线程,启动线程,其实在多进程编程中,存在一个进程类Process,也可以使用那集中方法来使用:在多线程中,内存中
-
Python多进程编程技术实例分析
本文以实例形式分析了Python多进程编程技术,有助于进一步Python程序设计技巧.分享给大家供大家参考.具体分析如下: 一般来说,由于Python的线程有些限制,例如多线程不能充分利用多核CPU等问题,因此在Python中我们更倾向使用多进程.但在做不阻塞的异步UI等场景,我们也会使用多线程.本篇文章主要探讨Python多进程的问题. Python在2.6引入了多进程的机制,并提供了丰富的组件及api以方便编写并发应用.multiprocessing包的组件Process, Queue, P
-
如何理解python面向对象编程
类是面向对象程序设计的一部分.面向对象程序设计或者简称为 OOP 致力于创建可重用代码块称之为类.当你想在你的程序中使用类时,你会从类中创建一个对象,这也是面向对象一词的由来.Python 并不总是面向对象的,但是你会在你的项目中用到对象.为了理解类,你需要理解面向对象的一些基础术语. 常用术语 class:类.类是代码块的主体,其中定义了建立的模型的属性和行为.这个模型可以来自于真实世界,也可以是虚拟游戏等. attribute:属性.是一系列信息的集合.在类中,一个属性通常是一个变量. be
-
深入理解python多线程编程
进程 进程的概念: 进程是资源分配的最小单位,他是操作系统进行资源分配和调度运行的基本单位.通俗理解:一个正在运行的一个程序就是一个进程.例如:正在运行的qq.wechat等,它们都是一个进程. 进程的创建步骤 1.导入进程包 import multiprocessing 2.通过进程类创建进程对象 进程对象 = multiprocessing.Process() 3.启动进程执行任务 进程对象.start() import multiprocessing import time def
-
探究Python多进程编程下线程之间变量的共享问题
1.问题: 群中有同学贴了如下一段代码,问为何 list 最后打印的是空值? from multiprocessing import Process, Manager import os manager = Manager() vip_list = [] #vip_list = manager.list() def testFunc(cc): vip_list.append(cc) print 'process id:', os.getpid() if __name__ == '__main_
-
Python多进程编程multiprocessing代码实例
在 多线程与多进程的比较 这一篇中记录了多进程编程的一种方式. 下面记录一下多进程编程的别一种方式,即使用multiprocessing编程 import multiprocessing import time def get_html(n): time.sleep(n) print('sub process %s' % n) return n if __name__ == '__main__': # 多进程编程 process = multiprocessing.Process(target=
-
Python多进程编程常用方法解析
python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU资源,在python中大部分情况需要使用多进程.python提供了非常好用的多进程包Multiprocessing,只需要定义一个函数,python会完成其它所有事情.借助这个包,可以轻松完成从单进程到并发执行的转换.multiprocessing支持子进程.通信和共享数据.执行不同形式的同步,提供了Process.Queue.Pipe.LocK等组件 一.Process 语法:Process([group[,target
-
Python面向对象编程中的类和对象学习教程
Python中一切都是对象.类提供了创建新类型对象的机制.这篇教程中,我们不谈类和面向对象的基本知识,而专注在更好地理解Python面向对象编程上.假设我们使用新风格的python类,它们继承自object父类. 定义类 class 语句可以定义一系列的属性.变量.方法,他们被该类的实例对象所共享.下面给出一个简单类定义: class Account(object): num_accounts = 0 def __init__(self, name, balance): self.name =
-
PHP多进程编程之僵尸进程问题的理解
PHP多进程编程之僵尸进程问题的理解 使用pcntl_fork函数可以让PHP实现多进程并发或者异步处理的效果:http://www.jb51.net/article/125789.htm 那么问题是我们产生的进程需要去控制,而不能置之不理.最基本的方式就是fork进程和杀死进程. 通过利用pcntl_fork函数,我们已经有了新的子进程,而子进程接下来完成我们需要处理的内容,那么我们就暂且叫做service()吧,而且我们需要很多个service()进行处理,再次参照我们之前的需求,父进程需要
-
Python 多进程和数据传递的理解
Python 多进程和数据传递的理解 python不仅线程用的是系统原生线程,进程也是用的原生进程 进程的用法和线程大同小异 import multiprocessing p = multiprocessing.Process(target=fun,args=()) 线程的基本方法在进程中都能够使用 但是进程和线程中有一个明显的区别:可以实现多核的运用 python本身会启动一个主进程,并且拥有一个主线程把主进程看做一家之主,那主线程也是他本身,其他线程就相当于老婆们 而进程,长大了的儿子们,线