深入PHP中的HashTable结构详解
HashTable是Zend引擎中最重要、使用最广泛的数据结构,它被用来存储几乎所有的东西。
1.2.1 数据结构
HashTable数据结构定义如下:
代码如下:
typedef struct bucket {
ulong h; // 存放hash
uint nKeyLength;
void *pData; // 指向value,是用户数据的副本
void *pDataPtr;
struct bucket *pListNext; // pListNext和pListLast组成
struct bucket *pListLast; // 整个HashTable的双链表
struct bucket *pNext; // pNext和pLast用于组成某个hash对应
struct bucket *pLast; // 的双链表
char arKey[1]; // key
} Bucket;
typedef struct _hashtable {
uint nTableSize;
uint nTableMask;
uint nNumOfElements;
ulong nNextFreeElement;
Bucket *pInternalPointer; /* Used for element traversal */
Bucket *pListHead;
Bucket *pListTail;
Bucket **arBuckets; // hash数组
dtor_func_t pDestructor; // HashTable初始化时指定,销毁Bucket时调用
zend_bool persistent; // 是否采用C的内存分配例程
unsigned char nApplyCount;
zend_bool bApplyProtection;
#if ZEND_DEBUG
int inconsistent;
#endif
} HashTable;
总的来说,Zend的HashTable是一种链表散列,同时也为线性遍历进行了优化,图示如下:
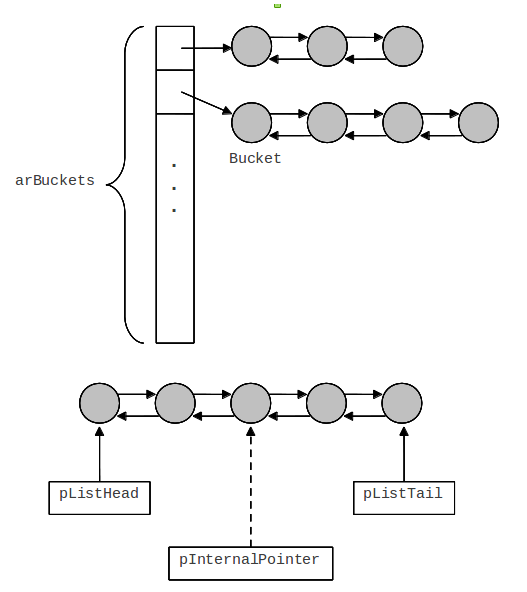
HashTable中包含两种数据结构,一个链表散列和一个双向链表,前者用于进行快速键-值查询,后者方便线性遍历和排序,一个Bucket同时存在于这两个数据结构中。
关于该数据结构的几点解释:
链表散列中为什么使用双向链表?
一般的链表散列只需要按key进行操作,只需要单链表就够了。但是,Zend有时需要从链表散列中删除给定的Bucket,使用双链表可以非常高效的实现。
nTableMask是干什么的?
这个值用于hash值到arBuckets数组下标的转换。当初始化一个HashTable,Zend首先为arBuckets数组分配nTableSize大小的内存,nTableSize取不小于用户指定大小的最小的2^n,即二进制的10*。nTableMask = nTableSize – 1,即二进制的01*,此时h & nTableMask就恰好落在 [0, nTableSize – 1] 里,Zend就以其为index来访问arBuckets数组。
pDataPtr是干什么的?
通常情况下,当用户插入一个键值对时,Zend会将value复制一份,并将pData指向value副本。复制操作需要调用Zend内部例程 emalloc来分配内存,这是个非常耗时的操作,并且会消耗比value大的一块内存(多出的内存用于存放cookie),如果value很小的话,将会造成较大的浪费。考虑到HashTable多用于存放指针值,于是Zend引入pDataPtr,当value小到和指针一样长时,Zend就直接将其复制到pDataPtr里,并且将pData指向pDataPtr。这就避免了emalloc操作,同时也有利于提高Cache命中率。
arKey大小为什么只有1?为什么不使用指针管理key?
arKey是存放key的数组,但其大小却只有1,并不足以放下key。在HashTable的初始化函数里可以找到如下代码:
代码如下:
p = (Bucket *) pemalloc(sizeof(Bucket) - 1 + nKeyLength, ht->persistent);
可见,Zend为一个Bucket分配了一块足够放下自己和key的内存,上半部分是Bucket,下半部分是key,而arKey“恰好”是Bucket的最后一个元素,于是就可以使用arKey来访问key了。这种手法在内存管理例程中最为常见,当分配内存时,实际上是分配了比指定大小要大的内存,多出的上半部分通常被称为cookie,它存储了这块内存的信息,比如块大小、上一块指针、下一块指针等,baidu的Transmit程序就使用了这种方法。
不用指针管理key,是为了减少一次emalloc操作,同时也可以提高Cache命中率。另一个必需的理由是,key绝大部分情况下是固定不变的,不会因为key变长了而导致重新分配整个Bucket。这同时也解释了为什么不把value也一起作为数组分配了——因为value是可变的。
1.2.2 PHP数组
关于HashTable还有一个疑问没有回答,就是nNextFreeElement是干什么的?
不同于一般的散列,Zend的HashTable允许用户直接指定hash值,而忽略key,甚至可以不指定key(此时,nKeyLength为0)。同时,HashTable也支持append操作,用户连hash值也不用指定,只需要提供value,此时,Zend就用nNextFreeElement作为hash,之后将nNextFreeElement递增。
HashTable的这种行为看起来很奇怪,因为这将无法按key访问value,已经完全不是个散列了。理解问题的关键在于,PHP数组就是使用HashTable实现的——关联数组使用正常的k-v映射将元素加入HashTable,其key为用户指定的字符串;非关联数组则直接使用数组下标作为hash值,不存在key;而当在一个数组中混合使用关联和非关联时,或者使用array_push操作时,就需要用nNextFreeElement了。
再来看value,PHP数组的value直接使用了zval这个通用结构,pData指向的是zval*,按照上一节的介绍,这个zval*将直接存储在pDataPtr里。由于直接使用了zval,数组的元素可以是任意PHP类型。
数组的遍历操作,即foreach、each等,是通过HashTable的双向链表来进行的,pInternalPointer作为游标记录了当前位置。
1.2.3 变量符号表
除了数组,HashTable还被用来存储许多其他数据,比如,PHP函数、变量符号、加载的模块、类成员等。
一个变量符号表就相当于一个关联数组,其key是变量名(可见,使用很长的变量名并不是个好主意),value是zval*。
在任一时刻PHP代码都可以看见两个变量符号表——symbol_table和active_symbol_table——前者用于存储全局变量,称为全局符号表;后者是个指针,指向当前活动的变量符号表,通常情况下就是全局符号表。但是,当每次进入一个PHP函数时(此处指的是用户使用PHP代码创建的函数),Zend都会创建函数局部的变量符号表,并将active_symbol_table指向局部符号表。Zend总是使用active_symbol_table来访问变量,这样就实现了局部变量的作用域控制。
但如果在函数局部访问标记为global的变量,Zend会进行特殊处理——在active_symbol_table中创建symbol_table中同名变量的引用,如果symbol_table中没有同名变量则会先创建。
1.3 内存和文件
程序拥有的资源一般包括内存和文件,对于通常的程序,这些资源是面向进程的,当进程结束后,操作系统或C库会自动回收那些我们没有显式释放的资源。
但是,PHP程序有其特殊性,它是基于页面的,一个页面运行时同样也会申请内存或文件这样的资源,然而当页面运行结束后,操作系统或C库也许不会知道需要进行资源回收。比如,我们将php作为模块编译到apache里,并且以prefork或worker模式运行apache。这种情况下apache进程或线程是复用的,php页面分配的内存将永驻内存直到出core。
为了解决这种问题,Zend提供了一套内存分配API,它们的作用和C中相应函数一样,不同的是这些函数从Zend自己的内存池中分配内存,并且它们可以实现基于页面的自动回收。在我们的模块中,为页面分配的内存应该使用这些API,而不是C例程,否则Zend会在页面结束时尝试efree掉我们的内存,其结果通常就是crush。
emalloc()
efree()
estrdup()
estrndup()
ecalloc()
erealloc()
另外,Zend还提供了一组形如VCWD_xxx的宏用于替代C库和操作系统相应的文件API,这些宏能够支持PHP的虚拟工作目录,在模块代码中应该总是使用它们。宏的具体定义参见PHP源代码”TSRM/tsrm_virtual_cwd.h”。可能你会注意到,所有那些宏中并没有提供close操作,这是因为close的对象是已打开的资源,不涉及到文件路径,因此可以直接使用C或操作系统例程;同理,read/write之类的操作也是直接使用C或操作系统的例程。
相关推荐
-
遍历Hashtable 的几种方法
方法一: IDictionaryEnumerator enumerator = thProduct.GetEnumerator(); while (enumerator.MoveNext()) { arrKey.Add("@"+enumerator.Key.ToString()); // Hashtable关健字 arrValue.Add(enumerator.Value.ToString()); // Hashtable值 } 方法二: usin
-
全面解析java中的hashtable
Hashtables提供了一个很有用的方法可以使应用程序的性能达到最佳. Hashtables(哈希表)在计算机领域中已不 是一个新概念了.它们是用来加快计算机的处理速度的,用当今的标准来处理,速度非常慢,而它们可以让你在查询许多数据条目时,很快地找到一个特殊的条目. 尽管现代的机器速度已快了几千倍,但是为了得到应用程序的最佳性能,hashtables仍然是个很有用的方法. 设想一下,你有一个包含约一千条记录的数据文件??比如一个小企业的客户记录还有一个程序,它把记录读到内存中进行处理.每个记录
-
java中vector与hashtable操作实例分享
众所周知,java中vector与hashtable是线程安全的,主要是java对两者的操作都加上了synchronized,也就是上锁了.因此 在vector与hashtable的操作是不会出现问题.但是有一种情况:就是将一个hashtable copy到另一个hashtable时,假如使用putAll方法的花,会抛出一个 java.util.ConcurrentModificationException异常.先上代码: TestSync.java 复制代码 代码如下: public clas
-
java中Hashtable和HashMap的区别分析
1.Hashtable是Dictionary的子类, 复制代码 代码如下: public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable HashMap: 复制代码 代码如下: public class HashMap<K,V> extends AbstractMap<K,V>
-
浅析Java中Map与HashMap,Hashtable,HashSet的区别
HashTable和HashMap区别 第一,继承的父类不同.Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类.但二者都实现了Map接口. 复制代码 代码如下: public class Hashtable<K,V>extends Dictionary<K,V>implements Map<K,V>, Cloneable, Serializable public class HashMap<K,V>extends
-
hashtable桶数通常会取一个素数分析
为什么一般hashtable的桶数会取一个素数 设有一个哈希函数 H( c ) = c % N; 当N取一个合数时,最简单的例子是取2^n,比如说取2^3=8,这时候 H( 11100(二进制) ) = H( 28 ) = 4 H( 10100(二进制) ) = H( 20 )= 4 这时候c的二进制第4位(从右向左数)就"失效"了,也就是说,无论第c的4位取什么值,都会导致H( c )的值一样.这时候c的第四位就根本不参与H( c )的运算,这样H( c )就无法完整地反映c的特性,
-
Java中HashMap和Hashtable及HashSet的区别
Hashtable类 Hashtable继承Map接口,实现一个key-value映射的哈希表.任何非空(non-null)的对象都可作为key或者value. 添加数据使用put(key,value),取出数据使用get(key),这两个基本操作的时间开销为常数. Hashtable通过initial capacity和load factor两个参数调整性能.通常缺省的load factor 0.75较好地实现了时间和空间的均衡.增大load factor可以节省空间但
-
java hashtable实现代码
复制代码 代码如下: public class HashTable{ private String[] name; //关键字 private int sum; //容量 public static void main(String[] args){ //测试 HashTable ht = new HashTable(); ht.add("chenhaitao"); ht.add("zhongcheng&
-

深入PHP中的HashTable结构详解
HashTable是Zend引擎中最重要.使用最广泛的数据结构,它被用来存储几乎所有的东西.1.2.1 数据结构HashTable数据结构定义如下: 复制代码 代码如下: typedef struct bucket { ulong h; // 存放hash uint nKeyLength; void *pData; // 指向value,是用户数据的副本 void *pDataPtr; struct bucket *pListNext; // pListNext和pListLast组成
-
ASP.NET MVC模式中应用程序结构详解
目录 一.App_Data 二.App_Start 三.Content 四.Controllers 五.font 六.Models 七.Scripts 八.Views 九.Web.config 1.根目录下面的Web.config文件 2.Views文件夹下面的Web.config 十.Global.asax 在上一篇文章中,讲解了一些MVC的概念,并且创建了第一个ASP.NET MVC项目,这篇文章将讲解ASP.NET MVC程序中的代码解构,新创建的MVC应用程序解构如下图所示: 一.App
-
Android源码中的目录结构详解
Android 2.1 |-- Makefile |-- bionic (bionic C库) |-- bootable (启动引导相关代码) |-- build (存放系统编译规则及generic等基础开发包配置) |-- cts (Android兼容性测试套件标准) |-- dalvik
-
Mysql InnoDB引擎中的数据页结构详解
目录 Mysql InnoDB引擎数据页结构 一.页的简介 二.数据页的结构 三.记录在页中的存储结构 四.记录头信息 1. deleted_flag 2. min_rec_flag 3. n_owned 4. heap_no 5. record_type 6. next_record Mysql InnoDB引擎数据页结构 InnoDB 是 mysql 的默认引擎,也是我们最常用的,所以基于 InnoDB,学习页结构.而学习页结构,是为了更好的学习索引. 一.页的简介 页是 InnoDB 管理
-
Java中Properties的使用详解
Java中有个比较重要的类Properties(Java.util.Properties),主要用于读取Java的配置文件,各种语言都有自己所支 持的配置文件,配置文件中很多变量是经常改变的,这样做也是为了方便用户,让用户能够脱离程序本身去修改相关的变量设置.今天,我们就开始Properties的使用. Java中Properties的使用 Properties的文档说明: The Properties class represents a persistent set of propertie
-
基于java中集合的概念(详解)
1.集合是储存对象的,长度可变,可以封装不同的对象 2.迭代器: 其实就是取出元素的方式(只能判断,取出,移除,无法增加) 就是把取出方式定义在集合内部,这样取出方式就可以直接访问集合内部的元素,那么取出方式就被定义成了内部类. 二每一个容器的数据结构不同,所以取出的动作细节也不一样.但是都有共性内容判断和取出,那么可以将共性提取,这些内部类都符合一个规则Iterator Iterator it = list.iterator(); while(it.hasNext()){ System.out
-
Java中synchronized实现原理详解
记得刚刚开始学习Java的时候,一遇到多线程情况就是synchronized,相对于当时的我们来说synchronized是这么的神奇而又强大,那个时候我们赋予它一个名字"同步",也成为了我们解决多线程情况的百试不爽的良药.但是,随着我们学习的进行我们知道synchronized是一个重量级锁,相对于Lock,它会显得那么笨重,以至于我们认为它不是那么的高效而慢慢摒弃它. 诚然,随着Javs SE 1.6对synchronized进行的各种优化后,synchronized并不会显得那么
-
OpenStack 中的Nova组件详解
Open Stack Compute Infrastructure (Nova) Nova是OpenStack云中的计算组织控制器.支持OpenStack云中实例(instances)生命周期的所有活动都由Nova处理.这样使得Nova成为一个负责管理计算资源.网络.认证.所需可扩展性的平台.但是,Nova自身并没有提供任何虚拟化能力,相反它使用libvirt API来与被支持的Hypervisors交互.Nova 通过一个与Amazon Web Services(AWS)EC2 API兼容的w
-
Android中SQLite 使用方法详解
Android中SQLite 使用方法详解 现在的主流移动设备像android.iPhone等都使用SQLite作为复杂数据的存储引擎,在我们为移动设备开发应用程序时,也许就要使用到SQLite来存储我们大量的数据,所以我们就需要掌握移动设备上的SQLite开发技巧.对于Android平台来说,系统内置了丰富的API来供开发人员操作SQLite,我们可以轻松的完成对数据的存取. 下面就向大家介绍一下SQLite常用的操作方法,为了方便,我将代码写在了Activity的onCreate中: @Ov
-
Nodejs中 npm常用命令详解
npm是什么 NPM的全称是Node Package Manager,是随同NodeJS一起安装的包管理和分发工具,它很方便让JavaScript开发者下载.安装.上传以及管理已经安装的包. npm是一个node包管理和分发工具,已经成为了非官方的发布node模块(包)的标准.有了npm,可以很快的找到特定服务要使用的包,进行下载.安装以及管理已经安装的包. 1.npm install moduleNames:安装Node模块 安装完毕后会产生一个node_modules目录,其目录下就是安装的