C#如何解析http报文
下面通过一段内容有文字说明有代码分析,并附有展示图供大家学习。
要解析HTTP报文,需要实现以下操作:
读取HTTP报头提供的各种属性
分析属性值,从中获取内容编码和字符集编码
将报头数据和内容进行分离
判断内容是否文本还是二进制,如果是二进制的则不进行处理
如果内容是文本,按报头中提供的内容编码和字符集编码进行解压缩和解码
目前没有找到.Net框架内置的解析方法,理论上HttpClient等类在内部应该已经实现了解析,但不知为何没有公开这些处理方法。(亦或是我没找到)
那么只能自己来解析这些数据了。
我们先来看看这个经过gzip压缩的文本内容的HTTP报文:

这里提供一个老外写的简陋的解析类(已经过修改,原代码中存在一些严重BUG):
public enum HTTPHeaderField
{
Accept = 0,
Accept_Charset = 1,
Accept_Encoding = 2,
Accept_Language = 3,
Accept_Ranges = 4,
Authorization = 5,
Cache_Control = 6,
Connection = 7,
Cookie = 8,
Content_Length = 9,
Content_Type = 10,
Date = 11,
Expect = 12,
From = 13,
Host = 14,
If_Match = 15,
If_Modified_Since = 16,
If_None_Match = 17,
If_Range = 18,
If_Unmodified_Since = 19,
Max_Forwards = 20,
Pragma = 21,
Proxy_Authorization = 22,
Range = 23,
Referer = 24,
TE = 25,
Upgrade = 26,
User_Agent = 27,
Via = 28,
Warn = 29,
Age = 30,
Allow = 31,
Content_Encoding = 32,
Content_Language = 33,
Content_Location = 34,
Content_Disposition = 35,
Content_MD5 = 36,
Content_Range = 37,
ETag = 38,
Expires = 39,
Last_Modified = 40,
Location = 41,
Proxy_Authenticate = 42,
Refresh = 43,
Retry_After = 44,
Server = 45,
Set_Cookie = 46,
Trailer = 47,
Transfer_Encoding = 48,
Vary = 49,
Warning = 50,
WWW_Authenticate = 51
};
class HTTPHeader
{
#region PROPERTIES
private string[] m_StrHTTPField = new string[52];
private byte[] m_byteData = new byte[4096];
public string[] HTTPField
{
get { return m_StrHTTPField; }
set { m_StrHTTPField = value; }
}
public byte[] Data
{
get { return m_byteData; }
set { m_byteData = value; }
}
#endregion
// convertion
System.Text.ASCIIEncoding encoding = new System.Text.ASCIIEncoding();
#region CONSTRUCTEUR
/// <summary>
/// Constructeur par défaut - non utilisé
/// </summary>
private HTTPHeader()
{ }
public HTTPHeader(byte[] ByteHTTPRequest)
{
string HTTPRequest = encoding.GetString(ByteHTTPRequest);
try
{
int IndexHeaderEnd;
string Header;
// Si la taille de requête est supérieur ou égale à 1460, alors toutes la chaine est l'entête http
if (HTTPRequest.Length <= 1460)
Header = HTTPRequest;
else
{
IndexHeaderEnd = HTTPRequest.IndexOf("\r\n\r\n");
Header = HTTPRequest.Substring(0, IndexHeaderEnd);
Data = ByteHTTPRequest.Skip(IndexHeaderEnd + 4).ToArray();
}
HTTPHeaderParse(Header);
}
catch (Exception)
{ }
}
#endregion
#region METHODES
private void HTTPHeaderParse(string Header)
{
#region HTTP HEADER REQUEST & RESPONSE
HTTPHeaderField HHField;
string HTTPfield, buffer;
int Index;
foreach (int IndexHTTPfield in Enum.GetValues(typeof(HTTPHeaderField)))
{
HHField = (HTTPHeaderField)IndexHTTPfield;
HTTPfield = "\n" + HHField.ToString().Replace('_', '-') + ": "; //Ajout de \n devant pour éviter les doublons entre cookie et set_cookie
// Si le champ n'est pas présent dans la requête, on passe au champ suivant
Index = Header.IndexOf(HTTPfield);
if (Index == -1)
continue;
buffer = Header.Substring(Index + HTTPfield.Length);
Index = buffer.IndexOf("\r\n");
if (Index == -1)
m_StrHTTPField[IndexHTTPfield] = buffer.Trim();
else
m_StrHTTPField[IndexHTTPfield] = buffer.Substring(0, Index).Trim();
//Console.WriteLine("Index = " + IndexHTTPfield + " | champ = " + HTTPfield.Substring(1) + " " + m_StrHTTPField[IndexHTTPfield]);
}
// Affichage de tout les champs
/*for (int j = 0; j < m_StrHTTPField.Length; j++)
{
HHField = (HTTPHeaderField)j;
Console.WriteLine("m_StrHTTPField[" + j + "]; " + HHField + " = " + m_StrHTTPField[j]);
}
*/
#endregion
}
#endregion
}
编写以下代码以实现解析文件:
class Program
{
static void Main(string[] args)
{
SRART: Console.WriteLine("输入待解析的HTTP报文数据文件完整路径:");
var filename = Console.ReadLine();
try
{
FileStream fs = new FileStream(filename, FileMode.Open);
BinaryReader br = new BinaryReader(fs);
var data = br.ReadBytes((int)fs.Length);
var header = new HTTPHeader(data);
var x = 0;
foreach (var f in header.HTTPField)
{
if (!String.IsNullOrEmpty(f))
{
Console.WriteLine($"[{x:00}] - {(HTTPHeaderField) x} : {f}");
}
x++;
}
Console.WriteLine($"总数据尺寸{fs.Length}字节,实际数据尺寸{header.Data.Length}字节");
Console.WriteLine(Encoding.UTF8.GetString(header.Data));
Console.WriteLine();
br.Close();
fs.Close();
}
catch (Exception e)
{
Console.WriteLine(e);
}
goto SRART;
}
}
这里还未实现gzip解压缩和字符解码,直接用UTF8解码输出的。(需要时再写吧,都是体力活儿~)
效果图展示:
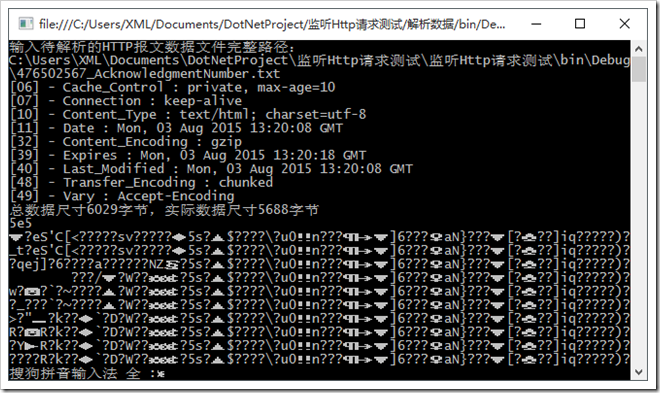

下面的图是没有经过gzip压缩过的数据。
以上就是用C#如何解析http报文的全部内容,哪位大侠还有好的方法欢迎提出宝贵意见,喜欢大家喜欢以上内容所述。
相关推荐
-

HTTPS混合内容解析附解决方法
什么是HTTPS混合内容 我们可能会有这样的经验,当我们通过HTTPS访问一个网站的时候,突然有提示:"本页面包含有不安全的内容".这个时候会询问是否显示"不安全的内容",这个时候,就是遇到了有混合内容的页面了. HTTPS下的页面,几乎很少是采用单一连接,HTML标识.图片.JS脚本以及其他页面资源不仅是多个连接获取到,甚至可能是来自完全不同的服务器和网站.为了确保一个页面进行了正确的加密,所有的页面资源都通过HTTPS进去获取是必要的.但在实际情况中,全部资源都
-
各类Http请求状态(status)及其含义详细解析
Web服务器响应浏览器或其他客户程序的请求时,其应答一般由以下几个部分组成:一个状态行,几个应答 头,一个空行,内容文档.下面是一个最简单的应答 : 状态行包含HTTP版本.状态代码.与状态代码对应的简短说明信息.在大多数情况下,除了Content-Type之 外的所有应答头都是可选的.但Content-Type是必需的,它描述的是后面文档的MIME类型.虽然大多数应答 都包含一个文档,但也有一些不包含,例如对HEAD请求的应答永远不会附带文档.有许多状态代码实际上用 来标识一次失败的请求,
-
解析ajax核心XMLHTTPRequest对象的创建与浏览器的兼容问题
MLHttpRequest 对象是AJAX功能的核心,要开发AJAX程序必须从了解XMLHttpRequest 对象开始. 了解XMLHttpRequest 对象就先从创建XMLHttpRequest 对象开始,在不同的浏览器中创建XMLHttpRequest 对象使用不同的方法: 先看看IE创建XMLHttpRequest 对象的方法(方法1): var xmlhttp=ActiveXobject("Msxml12.XMLHTTP");//较新的IE版本创建Msxml12.XMLHT
-
Android M(6.x)使用OkHttp包解析和发送JSON请求的教程
关于Android 6.0 Android老版本网络请求: 1,HttpUrlConnection 2,Apache Http Client Android6.0版本网络请求: 1,HttpUrlConnection 2,OkHttp Android6.0版本废弃了老的网络请求,那么它的优势是什么呢? 1,支持SPDY,共享同一个Socket来处理同一个服务器的所有请求 2,如果SPDY不可用,则通过连接池来减少请求延时 3,无缝的支持GZIP来减少数据流量 4,缓存响应数据来减少重复的网络请求
-
激动人心的 Angular HttpClient的源码解析
Angular 4.3.0-rc.0版本已经发布
-
Android天气预报之基于HttpGet对象解析天气数据的方法
本文实例所述为Android天气预报之解析天气数据的代码,可实现获取HttpGet对象读取天气网站天气数据,并从数据中解析出天气数据,比如温度.温度.风力.风向.未来几天天气趋势.当天天气状况.空气污染指数等信息,还包括了调用对应的图片或天气动画文件,对于开发android天气预报程序的可以参考本文实例. 具体功能代码如下: import java.io.IOException; import java.text.SimpleDateFormat; import java.util.ArrayL
-
深入解析nodejs HTTP服务
我最近在研究nodejs的路上,正好这两天了解了nodejs HTTP服务,那么今天也算个学习笔记吧! nodejs最重要的方面之一是具有非常迅速的实现HTTP和HTTPS服务器和服务的能力.http服务是相当低层次的,你可能要用到不同的模块,如express来实现完整的Web服务器,http模块不提供处理路由.cookie.缓存等的调用.我们主要用http模块的地方是实现供应用程序使用的后端Web服务. 1.处理URL 统一资源定位符(URL)为把一个请求发到正确的服务器的特定端口上,并访问
-
详解http访问解析流程原理
详解http访问解析流程原理 http访问网址域名解析流程: 1.在浏览器中输入www.qq.com域名,操作系统会先检查自己本地的hosts文件是否有这个网址映射关系,如果有,就先调用这个IP地址映射,完成域名解析. 2.如果hosts里没有这个域名的映射,则查找本地DNS解析器缓存,是否有这个网址映射关系,如果有,直接返回,完成域名解析. 3.如果hosts与本地DNS解析器缓存都没有相应的网址映射关系,首先会找TCP/ip参数中设置的首选DNS服务器,在此我们叫它本地DNS服务器,此服务器
-
C#如何解析http报文
下面通过一段内容有文字说明有代码分析,并附有展示图供大家学习. 要解析HTTP报文,需要实现以下操作: 读取HTTP报头提供的各种属性 分析属性值,从中获取内容编码和字符集编码 将报头数据和内容进行分离 判断内容是否文本还是二进制,如果是二进制的则不进行处理 如果内容是文本,按报头中提供的内容编码和字符集编码进行解压缩和解码 目前没有找到.Net框架内置的解析方法,理论上HttpClient等类在内部应该已经实现了解析,但不知为何没有公开这些处理方法.(亦或是我没找到) 那么只能自己来解析这些数
-
Java解析json报文实例解析
这篇文章主要介绍了Java解析json报文实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 json报文如下: { "code": 0, "data": { "city": { "cityId": 284609, "counname": "中国", "name": "东城区", "
-
微信公众号被动消息回复原理解析
背景:某分厂需要实时查询工件堆放的位置,要求快速便捷,因此设计了采用微信公众号被动回复信息的方案. 技术实现:开发者服务器--基于Angular2框架的已发布网站,编程语言为Python,后台存储数据库为Mysql: 微信服务器--微信公众号,此业务只是处理微信客户端发送的文本信息,且不使用公众号的其他功能,因此不需要认证公众号: 微信客户端--关注公众号的微信使用者,即粉丝. 当粉丝给公众号发送特定的消息时,微信公众号自动回复相应内容,而其背后的实现原理可由下图所示: 由上图可知,粉丝(微信客
-
NodeJS学习笔记之网络编程
Node提供丰富的网络编程模块 Node模块 协议 net TCP dgram UDP http HTTP https HTTPS TCP服务事件分为下面两类 (1).服务器事件 对于通过net.createServer()创建的服务器而言,它是一个EventEmitter实例,自定义事件有以下几种: listening :在调用listen()绑定端口或Domain Socket后触发,简写为server.listen(port, listener),通过第二个参数传入. connection
-
WebSocket的通信过程与实现方法详解
什么是 WebSocket ? WebSocket 是一种标准协议,用于在客户端和服务端之间进行双向数据传输.但它跟 HTTP 没什么关系,它是基于 TCP 的一种独立实现. 以前客户端想知道服务端的处理进度,要不停地使用 Ajax 进行轮询,让浏览器隔个几秒就向服务器发一次请求,这对服务器压力较大.另外一种轮询就是采用 long poll 的方式,这就跟打电话差不多,没收到消息就一直不挂电话,也就是说,客户端发起连接后,如果没消息,就一直不返回 Response 给客户端,连接阶段一直是阻塞的
-
Spring Cloud Feign 自定义配置(重试、拦截与错误码处理) 代码实践
基于 spring-boot-starter-parent 2.1.9.RELEASE, spring-cloud-openfeign 2.1.3.RELEASE 引子 Feign 是一个声明式.模板化的HTTP客户端,简化了系统发起Http请求.创建它时,只需要创建一个接口,然后加上FeignClient注解,使用它时,就像调用本地方法一样,作为开发者的我们完全感知不到这是在调用远程的方法,也感知不到背后发起了HTTP请求: /** * @author axin * @suammry xx 客
-
SpringBoot从0到1整合银联无跳转支付功能附源码
前言 提示:这里可以添加本文要记录的大概内容: 例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容. 提示:以下是本篇文章正文内容,下面案例可供参考 一.官网 https://open.unionpay.com/tjweb/user/mchTest/param 个人登录后的相关参数查看 其实在接入支付之前建议大家了解下 对称加密,分对称加密RSA之类,摘要算法,https,证书等这些知识点,因为此代码后面的验签,判断都是基于此的
-
如何用C写一个web服务器之CGI协议
目录 前言 CGI CGI请求 CGI响应 Nginx和PHP的CGI实现 SAPI PHP-FPM 纠偏 代码实现 http_parser cJSON 前言 这次更新主要实现一下 CGI 协议. 先放上GitHub链接https://github.com/zhenbianshu/tinyServer 作为一个服务器,基本要求是能受理请求,提取信息并将消息分发给 CGI 解释器,再将解释器响应的消息包装后返回客户端.在这个过程中,除了和客户端 socket 之间的交互,还要牵扯到第三个实体 -
-
Redis核心原理与实践之字符串实现原理
本文分析Redis字符串的实现原理,内容摘自新书<Redis核心原理与实践>.这本书深入地分析了Redis常用特性的内部机制与实现方式,内容源自对Redis源码的分析,并从中总结出设计思路.实现原理.通过阅读本书,读者可以快速.轻松地了解Redis的内部运行机制. Redis是一个键值对数据库(key-value DB),下面是一个简单的Redis的命令: > SET msg "hello wolrd" 该命令将键"msg".值"hell
-
初步了解代理和负载均衡
目录 代理 正向代理 反向代理 负载均衡 负载均衡介绍 网络模型和负载均衡 负载均衡和反向代理 带着问题阅读 1.什么是代理,代理有什么好处 2.正向代理和负向代理有什么区别 3.反向代理和负载均衡有什么关系 4.四层负载均衡和七层有什么区别 代理 代理,通俗来说好比是中介的角色,比如在生活中我们处理法律问题.房产交易都会请专业人士代为处理.从网络角度讲,就是为事务参与双方提供连接通道的第三方网络服务器. 在网络场景中,根据被代理的角色和作用划分,代理可分为正向代理和反向代理. 正向代理 正向代