MySQL Cluster如何创建磁盘表方法解读
一、概念
MySQL Cluster采用一系列的Disk Data objects来实现磁盘表。
Tablespaces:作用是作为其他Disk Data objects的容器。
Undo log files:存储事务进行回滚需要的信息,一个或者多个undo log files组成一个log files group,最后,该log file group关联到一个tablespaces。
Data files:作用是存储表中的数据,data file直接关联到tablespaces。
在每一个数据节点上undo log files和data files都是实际的文件,默认的,存放在ndb_node_id_fs文件夹下,该路径是在MySQL Cluster的config.ini中用DataDir指定的,node_id是data node的node ID。可以用绝对路径或者相对路径指定undo log或者data file的路径。tablespaces和log file group则不是实际的文件。
注意:尽管不是所有的Disk Data Object都作为文件存储,但是他们共享同一的命名空间,这意味着每个Disk Data Object必须唯一命名。
二、创建步骤
MySQL Cluster创建一个磁盘表需要包含以下几步:
2.1、创建一个log file group,将一个或者多个undo log files关联到它上面(undo log file也叫做 undofile)。注意,undo log file只是在创建磁盘表的时候才需要,创建ndb的内存表的时候不需要。
2.2、创建一个tablespaces,关联一个log file group和一个或者多个data files到上面。
2.3、使用该tablespaces创建一个磁盘表存储数据。
下面做一个例子:
2.4、创建log file group:
我们创建一个名为lg_cloudstor的log file group,包含cloudstor_undo_1.log和cloudstor_undo_2.log两个undo log file。初始大小分别为200M和100M(默认的undo log file的初始大小为128M),你还可以指定log file group的重写缓冲大小(默认为8M),这里我们设置为20M。创建log file group的时候必须和一个undo log file一起创建。如下:
代码如下:
CREATE LOGFILE GROUP lg_cloudstor
ADD UNDOFILE 'cloudstor_undo_1.log'
INITIAL_SIZE 200M
UNDO_BUFFER_SIZE 20M
ENGINE NDBCLUSTER;
该语句可能会出错,出现ERROR 1064 (42000)语法错误的信息,原因是字符集的问题,先执行:set character_set_client=latin1; 在执行: 
添加新的undo log file:
代码如下:
ALTER LOGFILE GROUP lg_cloudstor
ADD UNDOFILE 'cloudstor_undo_2.log'
INITIAL_SIZE 100M
ENGINE NDBCLUSTER;
2.5、创建tablespace
下来我们创建一个tablespace,创建tablespace必须指明一个log file group用于存储undo log。还必须指定一个data file,tablespace创建完成后,你可以稍后添加更多的data file到tablespace。下来我们创建一个使用log file group为lg_cloudstor名为 ts_cloudstore的表空间,这个表空间包含cloudstore_data_1.dbf和cloudstore_data_2.dbf两个data file,初始大小为100M(默认为128M),自动扩展为10M。
代码如下:
CREATE TABLESPACE ts_cloudstore
ADD DATAFILE 'cloudstore_data_1.dbf'
USE LOGFILE GROUP lg_cloudstor
INITIAL_SIZE 100M
AUTOEXTEND_SIZE 10M
ENGINE NDBCLUSTER;
ALTER TABLESPACE ts_cloudstore
ADD DATAFILE 'cloudstore_data_2.dbf'
INITIAL_SIZE 100M
AUTOEXTEND_SIZE 10M
ENGINE NDBCLUSTER;
下来我们可以看下新建的这些文件在物理磁盘上的数据文件: 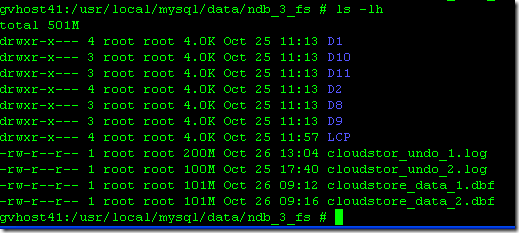
2.6、创建磁盘表
下来创建一个将没有索引的列存储在表空间ts_cloudstore的磁盘表。
代码如下:
create table Disktable
(
id int auto_increment primary key,
c1 varchar(50) not null,
c2 varchar(30) default null,
c3 date default null,
index(c1)
)
TABLESPACE ts_cloudstore STORAGE DISK
ENGINE NDBCLUSTER;
这样,列c2,c3的数据将会存储在磁盘上,id和c1的数据仍会存储在内存中,因为只有没有索引的列才能存储在磁盘上。创建完成后,就可以进行正常的数据操作了。
log file group,tablespaces,Disk Data tables需要按照一定的顺序执行,删除这些的时候也是这样,删除规则为:有任何表空间使用log file group时,log file group不能删除;表空间含有任何data files的时候,不能删除表空间;Data files含有任何表残余的时候,不能从表空间删除数据文件。
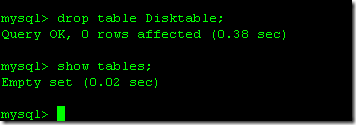
2.7、删除数据表
代码如下:
drop table Disktable;
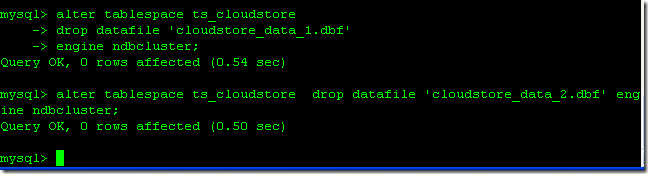
2.8、删除数据文件
当没有表在关联到表空间的时候,我们一个一个删除data files。
代码如下:
alter tablespace ts_cloudstore
drop datafile 'cloudstore_data_1.dbf'
engine ndbcluster;
alter tablespace ts_cloudstore
drop datafile 'cloudstore_data_2.dbf'
engine ndbcluster;
drop tablespace ts_cloudstore
engine ndbcluster;
drop logfile group lg_cloudstor
engine ndbcluster;
下来查看物理文件是否已经删除: 
可以在INFORMATION_SCHEMA数据库中的FILES表中查看磁盘表的信息。
2.11、几点注意的
在磁盘数据表中,TEXT和BLOB列的前256bytes存储在内存中,剩余内容存储在磁盘上;磁盘表中的每一行需要在内存中存储8bytes的数据用于指向磁盘上的数据,使用--initial选项启动集群时,不会删除磁盘上的数据文件,必须手动删除。
相关推荐
-

Windows Server 2003 下配置 MySQL 集群(Cluster)教程
MySQL 群集是 MySQL 适合于分布式计算环境的高可用.高冗余版本.它采用了 NDB Cluster 存储引擎,允许在 1 个群集中运行多个 MySQL 服务器.在 MySQL 5.0 及以上的二进制版本中,以及与最新的 Linux 版本兼容的 RPM 包中提供了该存储引擎. MySQL 群集是一种技术,该技术允许在无共享的系统中部署"内存中"和"磁盘中"数据库的 Cluster .通过无共享体系结构,系统能够使用廉价的硬件,而且对软硬件无特殊要求.此外,由于
-
MySQL Cluster集群的初级部署教程
Mysql Cluster概述 MySql Cluster最显著的优点就是高可用性,高实时性,高冗余,扩展性强. 它允许在无共享的系统中部署"内存中"数据库的Cluster.通过无共享体系结构,系统能够使用廉价的硬件.此外,由于每个组件有自己的内存和磁盘,所以不存在单点故障. 它由一组计算机构成,每台计算机上均运行者多种进程,包括mysql服务器,NDB cluster的数据节点,管理服务启,以及专门的数据访问程序 所有的这些节点构成一个完整的mysql集群体系.数据保存在"
-
win2003服务器下配置 MySQL 群集(Cluster)的方法
MySQL 群集是一种技术,该技术允许在无共享的系统中部署"内存中"和"磁盘中"数据库的 Cluster .通过无共享体系结构,系统能够使用廉价的硬件,而且对软硬件无特殊要求.此外,由于每个组件有自己的内存和磁盘,不存在单点故障.MySQL Cluster 由一组计算机构成,每台计算机上均运行着多种进程,包括 MySQL 服务器,NDB Cluster 的数据节点,管理服务器,以及(可能存在的)专门的数据访问程序. 管理服务器(MGM节点)负责管理 Cluster
-
CentOS中mysql cluster安装部署教程
一.安装要求 安装环境:CentOS-6.5-32bit 软件名称:mysql-cluster-gpl-7.2.25-linux2.6-i686.tar.gz 下载地址:http://mysql.mirror.kangaroot.net/Downloads/ 软件包:mysql-cluster-gpl-7.2.25-linux2.6-i686.tar.gz 软件包存放目录:/usr/local 管理节点(MGM): 192.168.1.71 数据节点1(NDBD1):192.168.1.72 数
-
MySQL Cluster如何创建磁盘表方法解读
一.概念 MySQL Cluster采用一系列的Disk Data objects来实现磁盘表. Tablespaces:作用是作为其他Disk Data objects的容器. Undo log files:存储事务进行回滚需要的信息,一个或者多个undo log files组成一个log files group,最后,该log file group关联到一个tablespaces. Data files:作用是存储表中的数据,data file直接关联到tablespaces. 在每一个数据
-
什么是分表和分区 MySql数据库分区和分表方法
1.为什么要分表和分区 日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能会更加糟糕.分表和表分区的目的就是减少数据库的负担,提高数据库的效率,通常点来讲就是提高表的增删改查效率. 2.什么是分表和分区 2.1 分表 分表是将一个大表按照一定的规则分解成多张具有独立存储空间的实体表,我们可以称为子表,每个表都对应三个文件,MYD数据文件,.MYI索引文件,.frm表结构
-
Java在Excel中创建透视表方法解析
本文内容介绍通过Java程序在Excel表格中根据数据来创建透视表. 环境准备 需要使用Excel类库工具-Free Spire.XLS for Java,这里使用的是免费版,可通过官网下载Jar包并解压,手动导入lib文件夹下的Spire.Xls.jar到Java程序:或者也可以通过Maven仓库下载导入. Java代码示例 import com.spire.xls.*; public class CreatePivotTable { public static void main(Strin
-
mysql多个TimeStamp设置的方法解读
timestamp设置默认值是Default CURRENT_TIMESTAMP timestamp设置随着表变化而自动更新是ON UPDATE CURRENT_TIMESTAMP 但是由于 一个表中至多只能有一个字段设置CURRENT_TIMESTAMP 两行设置DEFAULT CURRENT_TIMESTAMP是不行的. 还有一点要注意 复制代码 代码如下: CREATE TABLE `device` ( `id` INT(10) UNSIGNED NOT NULL AUTO_INCREME
-
mysql创建内存表的方法
如何创建内存表?创建内存表非常的简单,只需注明 ENGINE= MEMORY 即可: 复制代码 代码如下: CREATE TABLE `tablename` ( `columnName` varchar(256) NOT NUL) ENGINE=MEMORY DEFAULT CHARSET=latin1 MAX_ROWS=100000000; 注意: 当内存表中的数据大于max_heap_table_size设定的容量大小时,mysql会转换超出的数据存储到磁盘上,因此这是性能就大打折扣了,所
-
java使用JDBC动态创建数据表及SQL预处理的方法
本文实例讲述了java使用JDBC动态创建数据表及SQL预处理的方法.分享给大家供大家参考,具体如下: 这两天由于公司的需求,客户需要自定义数据表的字段,导致每张表的字段都不是固定的而且很难有一个通用的模板去维护,所以就使用JDBC动态去创建数据表,然后通过表的字段动态添加数据,数据的来源主要是用户提供的Excel直接导入到数据库中. 如果考虑到字段的类型,可以通过反射的机制去获取,现在主要用户需求就是将数据导入到数据库提供查询功能,不能修改,所以就直接都使用String类型来处理数据更加便捷.
-
MySQL快速复制数据库数据表的方法
某些时候,例如为了搭建一个测试环境,或者克隆一个网站,需要复制一个已存在的mysql数据库.使用以下方法,可以非常简单地实现. 假设已经存在的数据库名字叫db1,想要复制一份,命名为newdb.步骤如下: 1. 首先创建新的数据库newdb #mysql -u root -ppassword mysql>CREATE DATABASE `newdb` DEFAULT CHARACTER SET UTF8 COLLATE UTF8_GENERAL_CI; 2. 使用mysqldump及mysql的
-
MySQL查看、创建和删除索引的方法
本文实例讲述了MySQL查看.创建和删除索引的方法.分享给大家供大家参考.具体如下: 1.索引作用 在索引列上,除了上面提到的有序查找之外,数据库利用各种各样的快速定位技术,能够大大提高查询效率.特别是当数据量非常大,查询涉及多个表时,使用索引往往能使查询速度加快成千上万倍. 例如,有3个未索引的表t1.t2.t3,分别只包含列c1.c2.c3,每个表分别含有1000行数据组成,指为1-1000的数值,查找对应值相等行的查询如下所示. SELECT c1,c2,c3 FROM t1,t2,t3
-
Django使用Mysql数据库已经存在的数据表方法
使用scrapy爬取了网上的一些数据,存储在了mysql数据库中,想使用Django将数据展示出来,在网上看到都是使用Django的models和makemigration,migrate命令来创建新表,并使用. 可是我的数据已经存在了已经创建好,并且已经存储有数据了,不能再重新创建新表了. 了解Django的表明和models名称的映射关系就可以让Django使用已经存在的表. 假如在Django存在models如下: from django.db import models # Create
-
mysql 设置自动创建时间及修改时间的方法示例
本文实例讲述了mysql 设置自动创建时间及修改时间的方法.分享给大家供大家参考,具体如下: 第一种,通过ddl进行定义 CREATE TABLE `course` ( `course` varchar(255) DEFAULT NULL, `user` varchar(255) DEFAULT NULL, `score` int(11) DEFAULT NULL, `id` int(11) NOT NULL AUTO_INCREMENT, `create_time` datetime DEFA