Python读取excel文件中的数据,绘制折线图及散点图
目录
- 一、导包
- 二、绘制简单折线
- 三、pandas操作Excel的行列
- 四、pandas处理Excel数据成为字典
- 五、绘制简单折线图
- 六、绘制简单散点图
一、导包
import pandas as pd import matplotlib.pyplot as plt
二、绘制简单折线
数据:有一个Excel文件lemon.xlsx,有两个表单,表单名分别为:Python 以及student。
Python的表单数据如下所示:
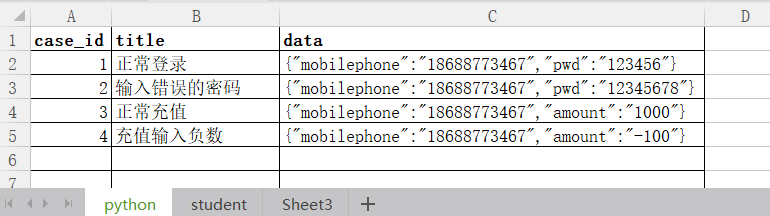
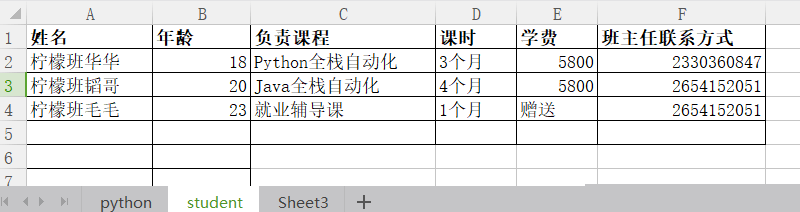
student的表单数据如下所示:
1、在利用pandas模块进行操作前,可以先引入这个模块,如下:
import pandas as pd
2、读取Excel文件的两种方式:
#方法一:默认读取第一个表单
df=pd.read_excel('lemon.xlsx')#这个会直接默认读取到这个Excel的第一个表单
data=df.head()#默认读取前5行的数据
print("获取到所有的值:\n{0}".format(data))#格式化输出
得到的结果是一个二维矩阵,如下所示:

#方法二:通过指定表单名的方式来读取
df=pd.read_excel('lemon.xlsx',sheet_name='student')#可以通过sheet_name来指定读取的表单
data=df.head()#默认读取前5行的数据
print("获取到所有的值:\n{0}".format(data))#格式化输出
得到的结果如下所示,也是一个二维矩阵:

#方法三:通过表单索引来指定要访问的表单,0表示第一个表单
#也可以采用表单名和索引的双重方式来定位表单
#也可以同时定位多个表单,方式都罗列如下所示
df=pd.read_excel('lemon.xlsx',sheet_name=['python','student'])#可以通过表单名同时指定多个
# df=pd.read_excel('lemon.xlsx',sheet_name=0)#可以通过表单索引来指定读取的表单
# df=pd.read_excel('lemon.xlsx',sheet_name=['python',1])#可以混合的方式来指定
# df=pd.read_excel('lemon.xlsx',sheet_name=[1,2])#可以通过索引 同时指定多个
data=df.values#获取所有的数据,注意这里不能用head()方法哦~
print("获取到所有的值:\n{0}".format(data))#格式化输出
三、pandas操作Excel的行列
1、读取指定的单行,数据会存在列表里面
#1:读取指定行
df=pd.read_excel('lemon.xlsx')#这个会直接默认读取到这个Excel的第一个表单
data=df.ix[0].values#0表示第一行 这里读取数据并不包含表头,要注意哦!
print("读取指定行的数据:\n{0}".format(data))
得到的结果如下所示:

2、读取指定的多行,数据会存在嵌套的列表里面
df=pd.read_excel('lemon.xlsx')
data=df.ix[[1,2]].values#读取指定多行的话,就要在ix[]里面嵌套列表指定行数
print("读取指定行的数据:\n{0}".format(data))
3、读取指定的行列
df=pd.read_excel('lemon.xlsx')
data=df.ix[1,2]#读取第一行第二列的值,这里不需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))
4、读取指定的多行多列值
df=pd.read_excel('lemon.xlsx')
data=df.ix[[1,2],['title','data']].values#读取第一行第二行的title以及data列的值,这里需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))
5、获取所有行的指定列
df=pd.read_excel('lemon.xlsx')
data=df.ix[:,['title','data']].values#读所有行的title以及data列的值,这里需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))
6、获取行号并打印输出
df=pd.read_excel('lemon.xlsx')
print("输出行号列表",df.index.values)
输出结果是:
输出行号列表 [0 1 2 3]
7、获取列名并打印输出
df=pd.read_excel('lemon.xlsx')
print("输出列标题",df.columns.values)
运行结果如下所示:
输出列标题 ['case_id' 'title' 'data']
8、获取指定行数的值
df=pd.read_excel('lemon.xlsx')
print("输出值",df.sample(3).values)#这个方法类似于head()方法以及df.values方法
输出值
[[2 '输入错误的密码' '{"mobilephone":"18688773467","pwd":"12345678"}']
[3 '正常充值' '{"mobilephone":"18688773467","amount":"1000"}']
[1 '正常登录' '{"mobilephone":"18688773467","pwd":"123456"}']]
9、获取指定列的值
df=pd.read_excel('lemon.xlsx')
print("输出值\n",df['data'].values)
四、pandas处理Excel数据成为字典
我们有这样的数据
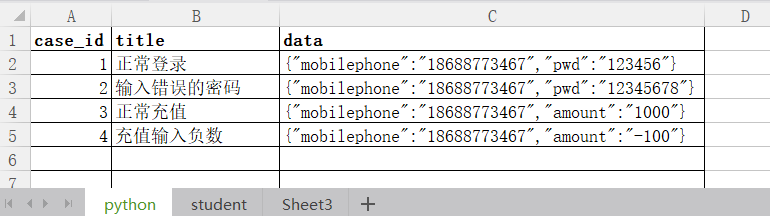
处理成列表嵌套字典,且字典的key为表头名。
实现的代码如下所示:
df=pd.read_excel('lemon.xlsx')
test_data=[]
for i in df.index.values:#获取行号的索引,并对其进行遍历:
#根据i来获取每一行指定的数据 并利用to_dict转成字典
row_data=df.ix[i,['case_id','module','title','http_method','url','data','expected']].to_dict()
test_data.append(row_data)
print("最终获取到的数据是:{0}".format(test_data))
最后得到的结果是:
最终获取到的数据是:
[{'title': '正常登录', 'case_id': 1, 'data': '{"mobilephone":"18688773467","pwd":"123456"}'},
{'title': '输入错误的密码', 'case_id': 2, 'data': '{"mobilephone":"18688773467","pwd":"12345678"}'},
{'title': '正常充值', 'case_id': 3, 'data': '{"mobilephone":"18688773467","amount":"1000"}'},
{'title': '充值输入负数', 'case_id': 4, 'data': '{"mobilephone":"18688773467","amount":"-100"}'}]
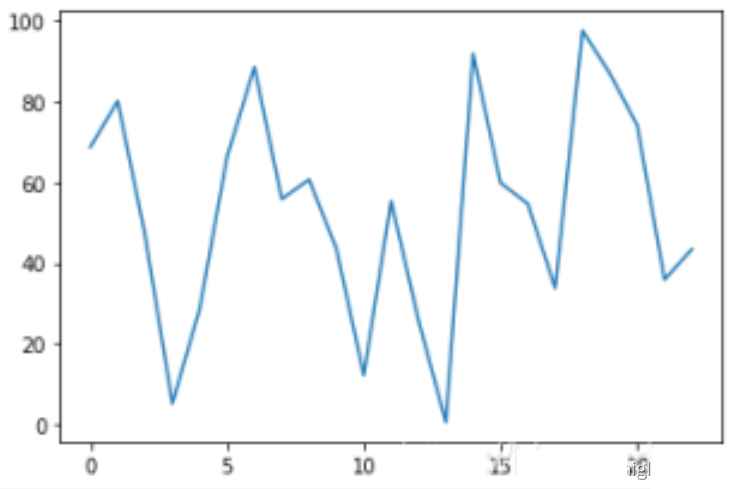
五、绘制简单折线图
所用数据:
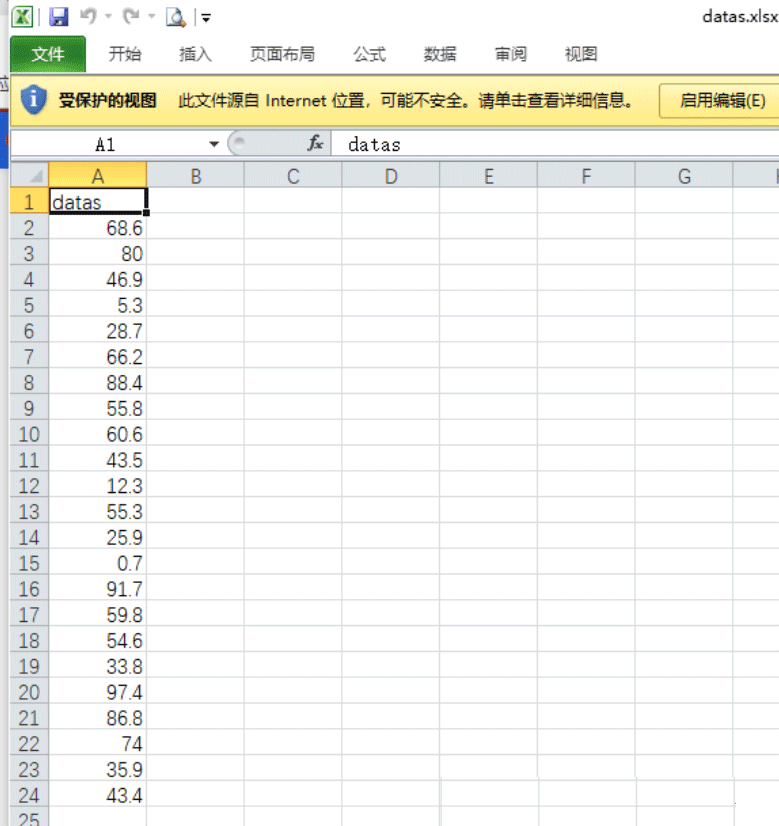
# -*- coding: utf-8 -*-
"""
Created on Tue Sep 29 18:24:14 2020
@author: chenj
"""
# 导入 pandas 和 matplotlib
import pandas as pd
import matplotlib.pyplot as plt
# 读取文件
# =============================================================================
# 可能遇到的问题 路径分隔符 建议用“/”或“\\” 读取桌面文件时 用“\”可能会失败
# =============================================================================
data_source = pd.read_excel('F:/南师2020作业/人工智能/datas.xlsx')
# 函数plot()尝试根据数字绘制出有意义的图形
print(data_source['datas'])
plt.plot(data_source['datas'])
六、绘制简单散点图
使用scatter绘制散点图并设置其样式 1、绘制单个点,使用函数scatter,并向它传递x,y坐标,并可使用参数s指定点的大小
plt.scatter(2,4,s=20)
2、绘制一系列点,向scatter传递两个分别包含x值和y值的列表
x_values=[1,2,3,4,5] y_values=[1,4,9,16,25] plt.scatter(x_values,y_values,s=20)
3、设置坐标轴的取值范围:函数axis()要求提供四个值,x,y坐标轴的最大值和最小值
plt.axis([0,1100,0,1100000])
4、使用参数edgecolor在函数scatter中设置数据点的轮廓
plt.scatter(x_values,y_values,edgecolor='black',s=20)
当参数值为'none'时不使用轮廓
5、向scatter传递参数c,指定要使用的颜色
可使用颜色名称,或者使用RGB颜色模式自定义颜色,元组中包含三个0~1之间的小数值,分别表示红绿蓝颜色分量。
plt.scatter(x_values,y_values,c=(0,0,0.8),edgecolor='none',s=20)为由浅蓝色组成的散点图
6、使用颜色映射
颜色映射是一系列颜色,它们从起始颜色渐变到结束颜色,在可视化中颜色映射用于突出数据的规律。
例如,可用较浅的颜色表示较小的数值,较深的颜色表示较大的数值。
模块pyplot内置了一组颜色映射,要使用颜色映射,需要告诉pyplot如何设置数据集中每个点的颜色。
plt.scatter(x_values,y_values,c=y_values,cmap=plt.cm.Blues,s=40)
plt.title("Square numbers",fontsize=24)
我们将参数c设置成了一个y值列表,并使用参数cmap告诉pyplot使用哪个颜色映射。这些代
码将y值较小的点显示为浅蓝色,并将y值较大的点显示为深蓝色。
7、自动保存图表:使用函数plt.savefig()
plt.savefig('D:/www/figure.png',bbox_inches='tight')
第一个参数是文件名,第二个参数指定将图表多余的空白区域减掉,如果要保留图表周围多余的空白区域,可省略这个实参。
8、设置绘图窗口尺寸
函数figure用于指定图表的宽度、高度、分辨率和背景色。
形参figsize指定一个元组,向matplotlib指出绘图窗口的尺寸,单位为英寸。
形参dpi向figure传递分辨率,默认为80
plt.figure(dpi=128,figsize=(10,6))
9、实例程序
#a.py
import matplotlib.pyplot as plt
x_values=list(range(1,1001))
y_values=[x**2 for x in x_values]
plt.scatter(x_values,y_values,c=y_values,cmap=plt.cm.Blues,s=40)
plt.title("Square numbers",fontsize=24)
plt.xlabel("value",fontsize=24)
plt.ylabel("Square of Value",fontsize=24)
plt.tick_params(axis='both',labelsize=14)
plt.axis([0,1100,0,1100000])
plt.savefig('D:/www/figure.png',bbox_inches='tight')
plt.show()
# 导入 pandas 和 matplotlib
import pandas as pd
import matplotlib.pyplot as plt
# 导入中文显示库函数
from matplotlib.font_manager import FontProperties
font_set = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=15)
# 读取文件
df = pd.read_excel("F:/南师2020作业/人工智能/datas.xlsx")
# 输出数据行数
print("数据行数:" , len(df))
'''
由于只有一列数据我们使用 excel 行号作为 x 值的列表
用range()函数来创建一个列表 [1,24)
range()函数 遍历数字序列
'''
x = list(range(1,len(df)+1)) #[1,24)
# 读取指定的单列也就是 datas列,数据会存在列表里面
y = df['datas']
# for 循环输出数据行数
for a in (list(range(1,len(df)+1))):
print('行号:'+str(a)) #将int类型的a 转换为字符串
#设置 x值 和y值的列表
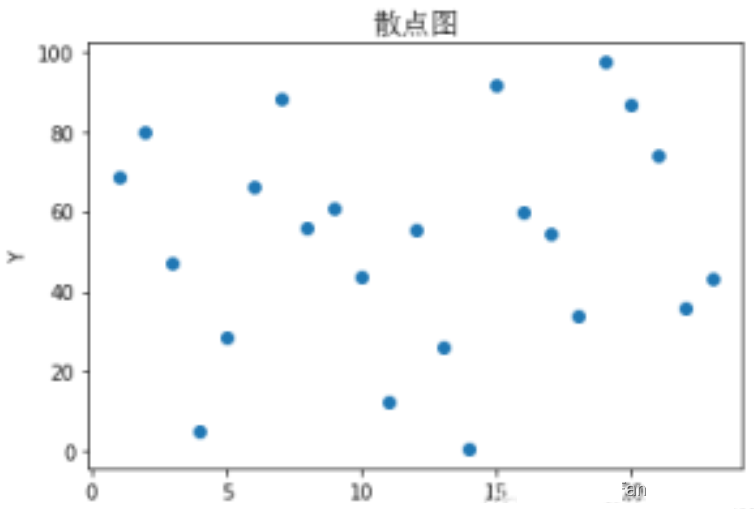
plt.scatter(x,y)
# 图表名称
plt.title('散点图',fontproperties=font_set)
# 设置x轴名称
plt.xlabel("X")
# 设置y轴名称
plt.ylabel("Y")
plt.show()
到此这篇关于Python读取excel文件中的数据,绘制折线图及散点图的文章就介绍到这了,更多相关Python读取excel文件数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python一步步带你操作Excel
目录 一.安装库的操作 二.xlwt库使用 三.xlrd库使用 四.openpyxl库使用-写入数据 五.openpyxl库使用-读取数据 ➤数据处理是 Python 的一大应用场景,而 Excel 则是最流行的数据处理软件.因此用 Python 进行数据相关的工作时,难免要和 Excel 打交道.Python处理Excel 常用的系列库有:xlrd.xlwt.xlutils.openpyxl ◈xlrd - 用于读取 Excel 文件,支持.xls和.xlsx格式 ◈xlwt - 用于写入 E
-
python用pdfplumber提取pdf表格数据并保存到excel文件中
目录 pdfplumber操作pdf文件 一.pdfplumber安装及导入 二.pdfplumber基础使用 1.基础知识 2.获取pdf基础信息 3.pdfplumber提取表格数据 三.提取pdf表格数据并保存到excel中 总结 pdfplumber操作pdf文件 python开源库pdfplumber,可以较为方便地获取pdf的各种信息,包含pdf的基本信息(作者.创建时间.修改时间…)及表格.文本.图片等信息,基本可以满足较为简单的格式转换功能. 一.pdfplumber安装及导入
-
python pandas处理excel表格数据的常用方法总结
目录 前言 1.读取xlsx表格:pd.read_excel() 2.获取表格的数据大小:shape 3.索引数据的方法:[ ] / loc[] / iloc[] 4.判断数据为空:np.isnan() / pd.isnull() 5.查找符合条件的数据 6.修改元素值:replace() 7.增加数据:[ ] 8.删除数据:del() / drop() 9.保存到excel文件:to_excel() 总结 前言 最近助教改作业导出的成绩表格跟老师给的名单顺序不一致,脑壳一亮就用pandas写了
-
基于Python实现文本文件转Excel
目录 一.前言 二.openpyxl模块 1.安装 2.简单操作 三.文本文件转excel文件 1.寻找规律 2.开始转换 补充 一.前言 Excel文件是我们常用的一种文件,在工作中使用非常频繁.Excel中有许多强大工具,因此用Excel来处理文件会给我们带来很多便捷.但是有时候我们拿到了文件不是Excel文件,而且我们又想用Excel中的工具,这个时候我们就可以想办法把这个文件转换成Excel文件了.今天我们就来实现一下,需要注意我们只能把有规律的文件转换成Excel,而且今天的内容也不是
-
如何利用python批量提取txt文本中所需文本并写入excel
目录 1.提取txt文本 2.增加数据框的列 3.引入基础csv数据,并扩列 汇总 总结 1.提取txt文本 我想要的文本是如图所示,宝可梦的外貌描述文本,由于原本的数据源结构并不是很稳定,而且也不是表格形式,因此在csdn上查了半天. 最原始的一行一行提取(不建议,未采用) fi = open("D:\python_learning\data\data\Axew.txt","r",encoding="utf-8") wflag =False #
-
Python pywin32实现word与Excel的处理
目录 pywin32处理Word和Excel的一些事 pywin32将Word转pdf pywin32将Excel格式处理并转pdf 总结 pywin32处理Word和Excel的一些事 我们知道Python处理word和Excel的可以借助第三库python-docx.xlrd.xlwt和openpyxl等实现,但这些模块只支持基本的读写操作,如果要实现一些较为深入功能,就要看模块是否有相应功能支持了.例如将word和Excel转为pdf,在word和Excel里面执行VBA实现特殊功能,在E
-
Python读取xlsx文件报错:xlrd.biffh.XLRDError: Excel xlsx file;not supported问题解决
目录 发现错误 (1)检查第三方库xlrd的版本: (2)别忘了修改import名称与调用的包名称 总结 发现错误 利用Python库xlrd中的xlrd.open_workbook()函数读取自定义xlsx表格文件时出错如下: Traceback (most recent call last): File "C:/Users/llll/PycharmProjects/pythonProject1/RandomForestRegression.py", line 96, in <
-
Python读取excel文件中的数据,绘制折线图及散点图
目录 一.导包 二.绘制简单折线 三.pandas操作Excel的行列 四.pandas处理Excel数据成为字典 五.绘制简单折线图 六.绘制简单散点图 一.导包 import pandas as pd import matplotlib.pyplot as plt 二.绘制简单折线 数据:有一个Excel文件lemon.xlsx,有两个表单,表单名分别为:Python 以及student. Python的表单数据如下所示: student的表单数据如下所示: 1.在利用pandas模块进行
-
Python读取excel文件中带公式的值的实现
在进行excel文件读取的时候,我自己设置了部分直接从公式获取单元格的值 但是用之前的读取方法进行读取的时候,返回值为空 import os import xlrd from xlutils.copy import copy file_path = os.path.abspath(os.path.dirname(__file__)) # 获取当前文件目录 print(file_path) root_path = os.path.dirname(file_path) # 获取文件上级目录 data
-
Python实现读取txt文件中的数据并绘制出图形操作示例
本文实例讲述了Python实现读取txt文件中的数据并绘制出图形操作.分享给大家供大家参考,具体如下: 下面的是某一文本文件中的数据. 6.1101,17.592 5.5277,9.1302 8.5186,13.662 7.0032,11.854 5.8598,6.8233 8.3829,11.886 7.4764,4.3483 8.5781,12 6.4862,6.5987 5.0546,3.8166 5.7107,3.2522 14.164,15.505 5.734,3.1551 8.408
-
python实现读取excel文件中所有sheet操作示例
本文实例讲述了python实现读取excel文件中所有sheet操作.分享给大家供大家参考,具体如下: 表格是这样的 实现把此文件所有sheet中 标识为1 的行,取出来,存入一个字典.所有行组成一个列表. # -*- coding: utf-8 -*- from openpyxl import load_workbook def get_data_from_excel(excel_dir):#读取excel,取出所有sheet要执行的接口信息,返回列表 work_book = load_wor
-
Python 读取位于包中的数据文件
问题 你的包中包含代码需要去读取的数据文件.你需要尽可能地用最便捷的方式来做这件事. 解决方案 假设你的包中的文件组织成如下: mypackage/ __init__.py somedata.dat spam.py 现在假设spam.py文件需要读取somedata.dat文件中的内容.你可以用以下代码来完成: # spam.py import pkgutil data = pkgutil.get_data(__package__, 'somedata.dat') 由此产
-
python 读取excel文件生成sql文件实例详解
python 读取excel文件生成sql文件实例详解 学了python这么久,总算是在工作中用到一次.这次是为了从excel文件中读取数据然后写入到数据库中.这个逻辑用java来写的话就太重了,所以这次考虑通过python脚本来实现. 在此之前需要给python添加一个xlrd模块,这个模块是专门用来操作excel文件的. 在mac中可以通过easy_install xlrd命令实现自动安装模块 import xdrlib ,sys import xlrd def open_excel(fil
-
Python读取CSV文件并进行数据可视化绘图
介绍:文件 sitka_weather_07-2018_simple.csv是阿拉斯加州锡特卡2018年1月1日的天气数据,其中包含当天的最高温度和最低温度.数据文件存储与data文件夹下,接下来用Python读取该文件数据,再基于数据进行可视化绘图.(详细细节请看代码注释) sitka_highs.py import csv # 导入csv模块 from datetime import datetime import matplotlib.pyplot as plt filename = 'd
-
python读取json文件并将数据插入到mongodb的方法
本文实例讲述了python读取json文件并将数据插入到mongodb的方法.分享给大家供大家参考.具体实现方法如下: #coding=utf-8 import sunburnt import urllib from pymongo import Connection from bson.objectid import ObjectId import logging from datetime import datetime import json from time import mktime
-
Python解析Excle文件中的数据方法
在公司里面,人力资源部每到发工资的时候就会头疼,如果公司内部有100多号员工,那么发完工资后需要给员工发送工资条的话,那么就需要截图如下图, 但是在公司的薪水保密协议不允许公开所有人的薪水,因此我们需要一个一个的发,现在我们给张三发一下薪资条 如果我们给1000人发的话,我们每个人都截图两次,面上的标题和线面的数据两栏,那么这个工程是比较大的.这个工作是循环的,死板的,那么我们就需要使用程序来解决这个问题. #coding=utf-8 import xlrd data = xlrd.open_w
-
Java读取txt文件中的数据赋给String变量方法
实例如下所示: public class MainActivity { private static final String fileName = "D:/Tao/MyEclipseWorkspace/resources/weather.txt"; public static void main(String[] args) { //读取文件 BufferedReader br = null; StringBuffer sb = null; try { br = new Buffer