使用python scrapy爬取天气并导出csv文件
目录
- 爬取xxx天气
- 安装
- 创建scray爬虫项目
- 文件说明
- 开始爬虫
- 补充:scrapy导出csv时字段的一些问题
- 1.字段顺序问题:
- 2.输出csv有空行的问题
- 总结
爬取xxx天气
爬取网址:https://tianqi.2345.com/today-60038.htm
安装
pip install scrapy
我使用的版本是scrapy 2.5
创建scray爬虫项目
在命令行如下输入命令
scrapy startproject name
name为项目名称
如,scrapy startproject spider_weather
之后再输入
scrapy genspider spider_name 域名
如,scrapy genspider changshu tianqi.2345.com
查看文件夹
- spider_weather
- spider
- __init__.py
- changshu.py
- __init__.py
- items.py
- middlewares.py
- pipelines.py
- settings.py
- scrapy.cfg
文件说明
| 名称 | 作用 |
|---|---|
| scrapy.cfg | 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中) |
| items.py | 设置数据存储模板,用于结构化数据,如:Django的Model |
| pipelines | 数据处理行为,如:一般结构化的数据持久化 |
| settings.py | 配置文件,如:递归的层数、并发数,延迟下载等 |
| spiders | 爬虫目录,如:创建文件,编写爬虫规则 |
开始爬虫
1.在spiders文件夹里面对自己创建的爬虫文件进行数据爬取、如在此案例中的spiders/changshu.py
代码演示如下
import scrapy
class ChangshuSpider(scrapy.Spider):
name = 'changshu'
allowed_domains = ['tianqi.2345.com']
start_urls = ['https://tianqi.2345.com/today-60038.htm']
def parse(self, response):
# 日期、天气状态、温度、风级
# 利用xpath解析数据、不会xpath的同学可以去稍微学习一下,语法简单
dates = response.xpath('//a[@class="seven-day-item "]/em/text()').getall()
states = response.xpath('//a[@class="seven-day-item "]/i/text()').getall()
temps = response.xpath('//a[@class="seven-day-item "]/span[@class="tem-show"]/text()').getall()
winds = response.xpath('//a[@class="seven-day-item "]/span[@class="wind-name"]/text()').getall()
# 返回每条数据
for date, state, temp, wind in zip(dates,states,temps,winds):
yield {
'date' : date,
'state': state,
'temp': temp,
'wind': wind
}
2.在settings.py文件中进行配置
修改UA
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
修改机器爬虫配置
ROBOTSTXT_OBEY = False
整个文件如下:
# Scrapy settings for spider_weather project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'spider_weather'
SPIDER_MODULES = ['spider_weather.spiders']
NEWSPIDER_MODULE = 'spider_weather.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'spider_weather.middlewares.SpiderWeatherSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'spider_weather.middlewares.SpiderWeatherDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# ITEM_PIPELINES = {
# 'spider_weather.pipelines.SpiderWeatherPipeline': 300,
# }
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
3.然后在命令行中输入如下代码
scrapy crawl changshu -o weather.csv
注意:需要进入spider_weather路径下运行
scrapy crawl 文件名 -o weather.csv(导出文件)
4.结果如下
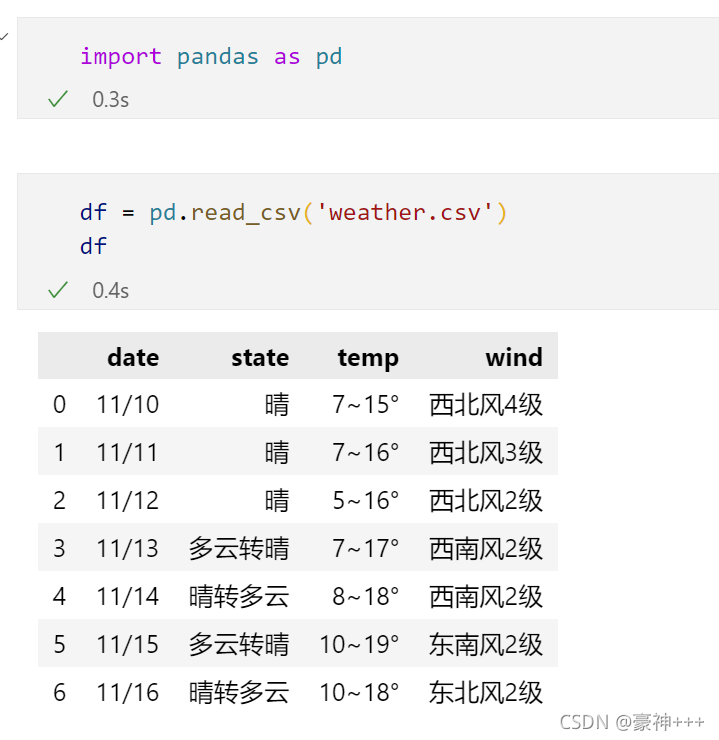
补充:scrapy导出csv时字段的一些问题
scrapy -o csv格式输出的时候,发现输出文件中字段的顺序不是按照items.py中的顺序,也不是爬虫文件中写入的顺序,这样导出的数据因为某些字段变得不好看,此外,导出得csv文件不同的item之间被空行隔开,本文主要描述解决这些问题的方法。
1.字段顺序问题:
需要在scrapy的spiders同层目录,新建csv_item_exporter.py文件内容如下(文件名可改,目录定死)
from scrapy.conf import settings from scrapy.contrib.exporter import CsvItemExporter class MyProjectCsvItemExporter(CsvItemExporter): def init(self, *args, **kwargs): delimiter = settings.get(‘CSV_DELIMITER', ‘,') kwargs[‘delimiter'] = delimiter fields_to_export = settings.get(‘FIELDS_TO_EXPORT', []) if fields_to_export : kwargs[‘fields_to_export'] = fields_to_export super(MyProjectCsvItemExporter, self).init(*args, **kwargs)
2)在settings.py中新增以下内容
#定义输出格式
FEED_EXPORTERS = {
‘csv': ‘project_name.spiders.csv_item_exporter.MyProjectCsvItemExporter',
}
#指定csv输出字段的顺序
FIELDS_TO_EXPORT = [
‘name',
‘title',
‘info'
]
#指定分隔符
CSV_DELIMITER = ‘,'
设定完毕,执行scrapy crawl spider -o spider.csv的时候,字段就按顺序来了
2.输出csv有空行的问题
此时你可能会发现csv文件中有空行,这是因为scrapy默认输出时,每个item之间的分隔符是空行
解决办法:
在找到exporters.py的CsvItemExporter类,大概在215行中增加newline="",即可。
也可以继承重写CsvItemExporter类
总结
到此这篇关于使用python scrapy爬取天气并导出csv文件的文章就介绍到这了,更多相关scrapy爬取天气导出csv内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Scrapy-redis爬虫分布式爬取的分析和实现
Scrapy Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的时候,单个主机的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来. 而Scrapy-Redis则是一个基于Redis的Scrapy分布式组件.它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用.scrapy-redi
-
使用Python的Scrapy框架十分钟爬取美女图
简介 scrapy 是一个 python 下面功能丰富.使用快捷方便的爬虫框架.用 scrapy 可以快速的开发一个简单的爬虫,官方给出的一个简单例子足以证明其强大: 快速开发 下面开始10分钟倒计时: 当然开始前,可以先看看之前我们写过的 scrapy 入门文章 <零基础写python爬虫之使用Scrapy框架编写爬虫 1. 初始化项目 scrapy startproject mzt cd mzt scrapy genspider meizitu meizitu.com 2. 添加 spide
-
python爬取天气数据的实例详解
就在前几天还是二十多度的舒适温度,今天一下子就变成了个位数,小编已经感受到冬天寒风的无情了.之前对获取天气都是数据上的搜集,做成了一个数据表后,对温度变化的感知并不直观.那么,我们能不能用python中的方法做一个天气数据分析的图形,帮助我们更直接的看出天气变化呢? 使用pygal绘图,使用该模块前需先安装pip install pygal,然后导入import pygal bar = pygal.Line() # 创建折线图 bar.add('最低气温', lows) #添加两线的数据序列 b
-
使用Scrapy爬取动态数据
对于动态数据的爬取,可以选择selenium和PhantomJS两种方式,本文选择的是PhantomJS. 网址: https://s.taobao.com/search?q=%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%94%B5%E8%84%91&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-it
-
Python爬虫之教你利用Scrapy爬取图片
Scrapy下载图片项目介绍 Scrapy是一个适用爬取网站数据.提取结构性数据的应用程序框架,它可以通过定制化的修改来满足不同的爬虫需求. 使用Scrapy下载图片 项目创建 首先在终端创建项目 # win4000为项目名 $ scrapy startproject win4000 该命令将创建下述项目目录. 项目预览 查看项目目录 win4000 win4000 spiders __init__.py __init__.py items.py middlewares.py pipelines
-
用python爬取历史天气数据的方法示例
某天气网站(www.数字.com)存有2011年至今的天气数据,有天看到一本爬虫教材提到了爬取这些数据的方法,学习之,并加以改进. 准备爬的历史天气 爬之前先分析url.左上有年份.月份的下拉选择框,按F12,进去看看能否找到真正的url: 很容易就找到了,左边是储存月度数据的js文件,右边是文件源代码,貌似json格式. 双击左边js文件,地址栏内出现了url:http://tianqi.数字.com/t/wea_history/js/54511_20161.js url中的"54511&qu
-
Python爬取国外天气预报网站的方法
本文实例讲述了Python爬取国外天气预报网站的方法.分享给大家供大家参考.具体如下: crawl_weather.py如下: #encoding=utf-8 import httplib import urllib2 import time from threading import Thread import threading from Queue import Queue from time import sleep import re import copy lang = "fr&qu
-
Python使用Scrapy爬取妹子图
Python Scrapy爬虫,听说妹子图挺火,我整站爬取了,上周一共搞了大概8000多张图片.和大家分享一下. 核心爬虫代码 # -*- coding: utf-8 -*- from scrapy.selector import Selector import scrapy from scrapy.contrib.loader import ItemLoader, Identity from fun.items import MeizituItem class MeizituSpider(sc
-
python3爬取各类天气信息
本来是想从网上找找有没有现成的爬取空气质量状况和天气情况的爬虫程序,结果找了一会儿感觉还是自己写一个吧. 主要是爬取北京包括北京周边省会城市的空气质量数据和天气数据. 过程中出现了一个错误:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa1 in position 250. 原来发现是页面的编码是gbk,把语句改成data=urllib.request.urlopen(url).read().decode("gbk")就可以
-
Python下使用Scrapy爬取网页内容的实例
上周用了一周的时间学习了Python和Scrapy,实现了从0到1完整的网页爬虫实现.研究的时候很痛苦,但是很享受,做技术的嘛. 首先,安装Python,坑太多了,一个个爬.由于我是windows环境,没钱买mac, 在安装的时候遇到各种各样的问题,确实各种各样的依赖. 安装教程不再赘述.如果在安装的过程中遇到 ERROR:需要windows c/c++问题,一般是由于缺少windows开发编译环境,晚上大多数教程是安装一个VisualStudio,太不靠谱了,事实上只要安装一个WindowsS