Go prometheus metrics条目自动回收与清理方法
目录
- 事件背景
- 现象获取
- 架构图
- 问题定位
- 原理分析
- 处理方法
- 最终效果
事件背景
现网上运行着一个自己开发的 metrics exporter,它是专门来捕获后端资源的运行状态,并生成对应的 prometheus metrics 供监控报警系统使用。当然这个 exporter 只是负责远程监控资源,并不能实际控制后端的资源,也不能实时动态获得被监控的资源的变动事件。当我们的运维小伙伴手动错误删除后端被监控的资源,导致业务流量异常。此时也没有报警出来,而这个报警却是依赖这个 metrics exporter 所采集的数据,导致了一次小型事件。因为这个事件,才有今天写文章的动力,同时也分享下解决这个问题的方法。
现象获取
架构图
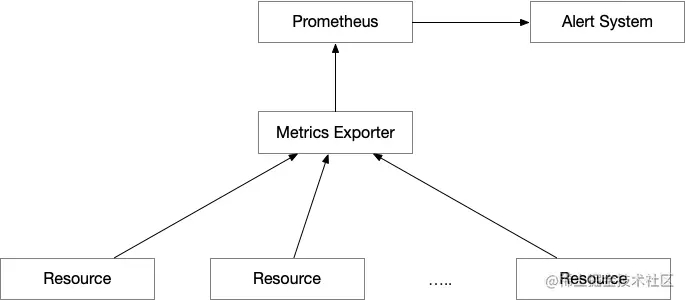
问题定位
通过跟小伙伴们一起复盘,以及追查可能出现问题的位置后,大家都觉得没有任何问题。在运维删除对应的监控资源后,同时没有关闭报警规则的情况下,应该有大量的任何异常报警产生。但实际情况,没有任何报警发出来。
当大家一筹莫展的时候,我突然说了一句,会不会是数据采集出现了问题?大家眼前一亮,赶紧拿出 metrics exporter 的代码检查。通过反复检查,也没有发现可疑的地方,于是大家又开始了思考。这时我打开了 metrics exporter 调试模式,打上断点,然后请运维小伙伴删除一个测试资源,观察监控数据的变化。果不其然,资源删除了,对应监控的 metrics 条目的值没有变化(也就是说,还是上次资源的状态)。
这下破案了,搞了半天是因为 metrics 条目内容没有跟随资源的删除而被自动的删除。导致了报警系统一直认为被删除的资源还在运行,而且状态正常。
原理分析
既然知道了原因,再回过头看 metrics exporter 的代码,代码中有 prometheus.MustRegister、prometheus.Unregister 和相关的 MetricsVec 值变更的实现和调用。就是没有判断监控资源在下线或者删除的情况下,如何删除和清理创建出来的 MetricsVec。
在我的印象中 MetricsVec 会根据 labels 会自动创建相关的条目,从来没有手动的添加和创建。根据这个逻辑我也认为,MetricsVec 中如果 labels 对应的值不更新或者处于不活跃的状态,应该自动删除才是。
最后还是把 golang 的 github.com/prometheus/client_golang 这个库想太完美了。没有花时间对 github.com/prometheus/client_golang 内部结构、原理、处理机制充分理解,才导致这个事件的发生。
github.com/prometheus/client_golang 中的 metrics 主要是 4 个种类,这个可以 baidu 上搜索,很多介绍,我这里不详细展开。这些种类的 metrics 又可以分为:一次性使用和多次使用。
- 一次性使用:当请求到达了 http 服务器,被 promhttp 中的 handler 处理后,返回数据给请求方。随后 metrics 数据就失效了,不保存。下次再有请求到 http 接口查询 metrics,数据重新计算生成,返回给请求方。
- 多次性使用:当请求到达了 http 服务器,被 promhttp 中的 handler 处理后,返回数据给请求方。随后 metrics 保存,并不会删除,需要手动清理和删除。 下次再有请求到 http 接口查询 metrics,直接返回之前存储过的数据给请求方。
注意这两者的区别,他们有不同的应用场景。
- 一次性使用:一次请求一次新数据,数据与数据间隔时间由数据读取者决定。 如果有多个数据读取者,每一个读取者读取到的数据可能不会相同。每一个请求计算一次,如果采集请求量比较大,或者内部计算压力比较大,都会导致负载压力很高。 计算和输出是同步逻辑。 例如:k8s 上的很多 exporter 是这样的方式。
- 多次性使用:每次请求都是从 map 中获得,数据与数据间隔时间由数据写入者决定。如果有多个数据读取者,每一个读取者采集的数据相同(读取的过程中没有更新数据写入)。每一个请求获得都是相同的计算结果,1 次计算多数读取。计算和输出是异步逻辑。例如:http server 上 http 请求状态统计,延迟统计,转发字节汇总,并发量等等。
这次项目中写的 metrics exporter 本应该是采用 “一次性使用” 这样的模型来开发,但是内部结构模型采用了 “多次性使用” 模型,因为指标数据写入者和数据读取者之间没有必然联系,不属于一个会话系统,所以之间是异步结构。具体我们看下图:
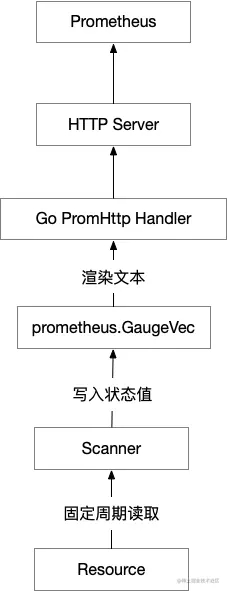
从图中有 2 个身份说明下:
- 数据读取者:主要是 Prometheus 系统的采集器,根据配置的规则周期性的来 metrics 接口读取数据。
- 数据写入者:开发的 scanner ,通过接口去读远程资源状态信息和相关数据,通过计算得到最后的结果,写入指定的 metrics 条目内。
在此次项目中 metrics 条目是用 prometheus.GaugeVec 作为采集数据计算后结果的存储类型。
说了这么多,想要分析真正的原因,就必须深入 github.com/prometheus/client_golang 代码中 GaugeVec 这个具体代码实现。
// GaugeVec is a Collector that bundles a set of Gauges that all share the same
// Desc, but have different values for their variable labels. This is used if
// you want to count the same thing partitioned by various dimensions
// (e.g. number of operations queued, partitioned by user and operation
// type). Create instances with NewGaugeVec.
type GaugeVec struct {
*MetricVec
}
type MetricVec struct {
*metricMap
curry []curriedLabelValue
// hashAdd and hashAddByte can be replaced for testing collision handling.
hashAdd func(h uint64, s string) uint64
hashAddByte func(h uint64, b byte) uint64
}
// metricMap is a helper for metricVec and shared between differently curried
// metricVecs.
type metricMap struct {
mtx sync.RWMutex // Protects metrics.
metrics map[uint64][]metricWithLabelValues // 真正的数据存储位置
desc *Desc
newMetric func(labelValues ...string) Metric
}
通过上面的代码,一条 metric 条目是保存在 metricMap.metrics 下。 我们继续往下看:
读取数据
// Collect implements Collector.
func (m *metricMap) Collect(ch chan<- Metric) {
m.mtx.RLock()
defer m.mtx.RUnlock()
// 遍历 map
for _, metrics := range m.metrics {
for _, metric := range metrics {
ch <- metric.metric // 读取数据到通道
}
}
}
写入数据
// To create Gauge instances, use NewGauge.
type Gauge interface {
Metric
Collector
// Set sets the Gauge to an arbitrary value.
Set(float64)
// Inc increments the Gauge by 1. Use Add to increment it by arbitrary
// values.
Inc()
// Dec decrements the Gauge by 1. Use Sub to decrement it by arbitrary
// values.
Dec()
// Add adds the given value to the Gauge. (The value can be negative,
// resulting in a decrease of the Gauge.)
Add(float64)
// Sub subtracts the given value from the Gauge. (The value can be
// negative, resulting in an increase of the Gauge.)
Sub(float64)
// SetToCurrentTime sets the Gauge to the current Unix time in seconds.
SetToCurrentTime()
}
func NewGauge(opts GaugeOpts) Gauge {
desc := NewDesc(
BuildFQName(opts.Namespace, opts.Subsystem, opts.Name),
opts.Help,
nil,
opts.ConstLabels,
)
result := &gauge{desc: desc, labelPairs: desc.constLabelPairs}
result.init(result) // Init self-collection.
return result
}
type gauge struct {
// valBits contains the bits of the represented float64 value. It has
// to go first in the struct to guarantee alignment for atomic
// operations. http://golang.org/pkg/sync/atomic/#pkg-note-BUG
valBits uint64
selfCollector
desc *Desc
labelPairs []*dto.LabelPair
}
func (g *gauge) Set(val float64) {
atomic.StoreUint64(&g.valBits, math.Float64bits(val)) // 写入数据到变量
}
看到上面的代码,有的小伙伴就会说读取和写入的位置不一样啊,没有找到真正的位置。不要着急,后面还有。
// getOrCreateMetricWithLabelValues retrieves the metric by hash and label value
// or creates it and returns the new one.
//
// This function holds the mutex.
func (m *metricMap) getOrCreateMetricWithLabelValues(hash uint64, lvs []string, curry []curriedLabelValue,) Metric { // 返回了一个接口
m.mtx.RLock()
metric, ok := m.getMetricWithHashAndLabelValues(hash, lvs, curry)
m.mtx.RUnlock()
if ok {
return metric
}
m.mtx.Lock()
defer m.mtx.Unlock()
metric, ok = m.getMetricWithHashAndLabelValues(hash, lvs, curry)
if !ok {
inlinedLVs := inlineLabelValues(lvs, curry)
metric = m.newMetric(inlinedLVs...)
m.metrics[hash] = append(m.metrics[hash], metricWithLabelValues{values: inlinedLVs, metric: metric}) // 这里写入 metricMap.metrics
}
return metric
}
// A Metric models a single sample value with its meta data being exported to
// Prometheus. Implementations of Metric in this package are Gauge, Counter,
// Histogram, Summary, and Untyped.
type Metric interface { // 哦哦哦哦,是接口啊。Gauge 实现这个接口
// Desc returns the descriptor for the Metric. This method idempotently
// returns the same descriptor throughout the lifetime of the
// Metric. The returned descriptor is immutable by contract. A Metric
// unable to describe itself must return an invalid descriptor (created
// with NewInvalidDesc).
Desc() *Desc
// Write encodes the Metric into a "Metric" Protocol Buffer data
// transmission object.
//
// Metric implementations must observe concurrency safety as reads of
// this metric may occur at any time, and any blocking occurs at the
// expense of total performance of rendering all registered
// metrics. Ideally, Metric implementations should support concurrent
// readers.
//
// While populating dto.Metric, it is the responsibility of the
// implementation to ensure validity of the Metric protobuf (like valid
// UTF-8 strings or syntactically valid metric and label names). It is
// recommended to sort labels lexicographically. Callers of Write should
// still make sure of sorting if they depend on it.
Write(*dto.Metric) error
// TODO(beorn7): The original rationale of passing in a pre-allocated
// dto.Metric protobuf to save allocations has disappeared. The
// signature of this method should be changed to "Write() (*dto.Metric,
// error)".
}
看到这里就知道了写入、存储、读取已经连接到了一起。 同时如果没有显式的调用方法删除 metricMap.metrics 的内容,那么记录的 metrics 条目的值就会一直存在,而原生代码中只是创建和变更内部值。正是因为这个逻辑才导致上面说的事情。
处理方法
既然找到原因,也找到对应的代码以及对应的内部逻辑,就清楚了 prometheus.GaugeVec 这个变量真正的使用方法。到此解决方案也就有了,找到合适的位置添加代码,显式调用 DeleteLabelValues 这个方法来删除无效 metrics 条目。
为了最后实现整体效果,我总结下有几个关键词:“异步”、“多次性使用”、“自动回收”。
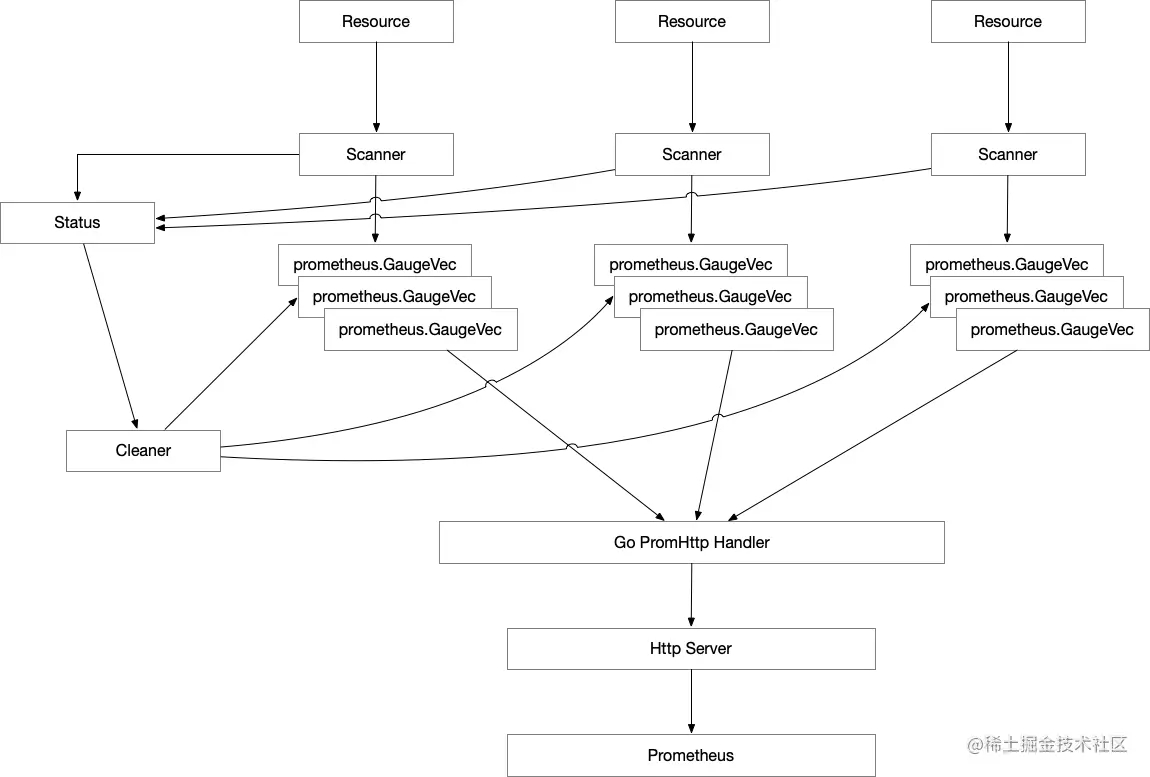
最后的改造思路:
- 创建一个 scanner 扫描结果存储的状态机 (status)
- 每次 scanner 扫描结果会向这个状态机做更新动作,并记录对应的更新时间
- 启动一个 goroutine (cleaner) 定期扫描状态机,然后遍历分析记录数据的更新时间。如果遍历到对应数据的更新时间跟现在的时间差值超过一个固定的阈值,就主动删除状态机中对应的信息,同时删除对应的 metrics 条目
通过这个动作就可以实现自动回收和清理无效的 metrics 条目,最后验证下来确实有效。
最终效果
通过测试代码来验证这个方案的效果,具体如下演示:
package main
import (
"context"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
"net/http"
"strconv"
"sync"
"time"
)
type metricsMetaData struct {
UpdatedAt int64
Labels []string
}
func main() {
var wg sync.WaitGroup
var status sync.Map
vec := prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Namespace: "app",
Name: "running_status",
}, []string{"id"},
)
prometheus.MustRegister(vec)
defer prometheus.Unregister(vec)
// 写入数据
for i := 0; i < 10; i++ {
labels := strconv.Itoa(i)
vec.WithLabelValues(labels).Set(1) // 写入 metric 条目
status.Store(labels, metricsMetaData{UpdatedAt: time.Now().Unix(), Labels: []string{labels}}) // 写入状态
}
// 创建退出 ctx
stopCtx, stopCancel := context.WithCancel(context.Background())
// 启动清理器
go func(ctx *context.Context, g *sync.WaitGroup) {
defer g.Done()
ticker := time.NewTicker(time.Second * 2)
for {
select {
case <-ticker.C:
now := time.Now().Unix()
status.Range(func(key, value interface{}) bool {
if now-value.(metricsMetaData).UpdatedAt > 5 {
vec.DeleteLabelValues(value.(metricsMetaData).Labels...) // 删除 metrics 条目
status.Delete(key) // 删除 map 中的记录
}
return true
})
break
case <-(*ctx).Done():
return
}
}
}(&stopCtx, &wg)
wg.Add(1)
// 创建 http
http.Handle("/metrics", promhttp.Handler())
srv := http.Server{Addr: "0.0.0.0:8080"}
// 启动 http server
go func(srv *http.Server, g *sync.WaitGroup) {
defer g.Done()
_ = srv.ListenAndServe()
}(&srv, &wg)
wg.Add(1)
// 退出
time.Sleep(time.Second * 10)
stopCancel()
_ = srv.Shutdown(context.Background())
wg.Wait()
}
结果动画:

以上就是Go prometheus metrics条目自动回收与清理方法的详细内容,更多关于Go prometheus metrics回收清理的资料请关注我们其它相关文章!
相关推荐
-

Go语言七篇入门教程七GC垃圾回收三色标记
目录 GC 如何判断一个对象是否可达 三色标记法 原理如下 GC GC全称Garbage Collection 目前主流的垃圾回收算法有两类,分别是追踪式垃圾回收算法(Tracing garbage collection)和引用计数法( Reference counting ). 而三色标记法是属于追踪式垃圾回收算法的一种. 追踪式算法的核心思想是判断一个对象是否可达,因为一旦这个对象不可达就可以立刻被 GC 回收了. 如何判断一个对象是否可达 分为两步: 第一步找出所有的全局变量和当前函数栈里
-
Go语言metrics应用监控指标基本使用说明
目录 metrics是什么? 五种Metrics类型 metrics 是什么? 当我们需要为某个系统某个服务做监控.做统计,就需要用到Metrics 五种 Metrics 类型 Gauges :最简单的度量指标,只有一个简单的返回值,或者叫瞬时状态 Counters:Counter 就是计数器,Counter 只是用 Gauge 封装了 AtomicLong Meters:Meter度量一系列事件发生的速率(rate),例如TPS.Meters会统计最近1分钟,5分钟,15分钟,还有全部时间的速
-
详解prometheus监控golang服务实践记录
一.prometheus基本原理介绍 prometheus是基于metric采样的监控,可以自定义监控指标,如:服务每秒请求数.请求失败数.请求执行时间等,每经过一个时间间隔,数据都会从运行的服务中流出,存储到一个时间序列数据库中,之后可通过PromQL语法查询. 主要特点: 多维数据模型,时间序列数据通过metric名以key.value的形式标识: 使用PromQL语法灵活地查询数据: 不需要依赖分布式存储,各服务器节点是独立自治的: 时间序列的收集,通过 HTTP 调用,基于pull 模型
-
go:垃圾回收GC触发条件详解
版本: go version go1.13 darwin/amd64 在go源码runtime目录中找到gcTrigger结构体,就能看出大致调用的位置 GC调用方式 所在位置 代码 定时调用 runtime/proc.go:forcegchelper() gcStart(gcTrigger{kind: gcTriggerTime, now: nanotime()}) 分配内存时调用 runtime/malloc.go:mallocgc() gcTrigger{kind: gcTriggerHe
-
图解Golang的GC垃圾回收算法
虽然Golang的GC自打一开始,就被人所诟病,但是经过这么多年的发展,Golang的GC已经改善了非常多,变得非常优秀了. 以下是Golang GC算法的里程碑: v1.1 STW v1.3 Mark STW, Sweep 并行 v1.5 三色标记法 v1.8 hybrid write barrier 经典的GC算法有三种: 引用计数(reference counting) . 标记-清扫(mark & sweep) . 复制收集(Copy and Collection) . Golang的G
-
Go语言Elasticsearch数据清理工具思路详解
微服务架构中收集通常大家都采用ELK进行日志收集,同时我们还采用了SkyWalking进行链路跟踪,而SkyWalking数据存储也用到了ES,SkyWalking每天产生大量的索引数据,如下: WX20211008-104751@2x 这里一天大概产生了700左右个索引数据.对历史的链路数据我们不做过多的保留. 这里我整理了个小工具,可以定期清理es数据. 一.清理思路 可以看到索引数据都是以日期结尾,我们可以根据日期去匹配索引数据,并对索引进行删除.这里需要考虑一点,有的Es服务开启了索引保
-
Go prometheus metrics条目自动回收与清理方法
目录 事件背景 现象获取 架构图 问题定位 原理分析 处理方法 最终效果 事件背景 现网上运行着一个自己开发的 metrics exporter,它是专门来捕获后端资源的运行状态,并生成对应的 prometheus metrics 供监控报警系统使用.当然这个 exporter 只是负责远程监控资源,并不能实际控制后端的资源,也不能实时动态获得被监控的资源的变动事件.当我们的运维小伙伴手动错误删除后端被监控的资源,导致业务流量异常.此时也没有报警出来,而这个报警却是依赖这个 metrics ex
-
springboot集成普罗米修斯(Prometheus)的方法
Prometheus 是一套开源的系统监控报警框架.它由工作在 SoundCloud 的 员工创建,并在 2015 年正式发布的开源项目.2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,非常的受欢迎. 简介 Prometheus 具有以下特点: 一个多维数据模型,其中包含通过度量标准名称和键/值对标识的时间序列数据 PromQL,一种灵活的查询语言,可利用此维度 不依赖分布式存储: 单服务器节点是自治的 时间序列收集通过HTTP上
-
在win10系统下,如何配置Spring Cloud alibaba Seata以及出现问题时怎么解决
实战开始 先看报错问题: config.txt: No such file or directory ========================================================================= Complete initialization parameters, total-count:0 , failure-count:0 =========================================================
-
SpringCloud Alibaba使用Seata处理分布式事务的技巧
Seata简介 在传统的单体项目中,我们使用@Transactional注解就能实现基本的ACID事务了. 但是前提是: 1) 数据库支持事务(如:MySQL的innoDB引擎) 2) 所有业务都在同一个数据库中执行 随着微服务架构的引入,需要对数据库进行分库分表,每个服务拥有自己的数据库,这样传统的事务就不起作用了,那么我们如何保证多个服务中数据的一致性呢? 这样就出现了分布式事务,而Seata就是为微服务架构而生的一种高性能.易于使用的分布式事务解决方案. Seata 中有三个基础组件: T
-
使用springCloud+nacos集成seata1.3.0搭建过程
1.docker安装seata 1.3.0镜像 docker pull seataio/seata-server:1.3.0 2.运行容器获取配置文件 docker run --name seata-server -p 8091:8091 -d seataio/seata-server:1.3.0 3.将容器中的配置拷贝到/usr/local/seata-1.3.0 docker cp seata-server:/seata-server /usr/local/seata-1.3.0 4.停止容
-
Kubernetes(K8S)容器集群管理环境完整部署详细教程-中篇
本文系列: Kubernetes(K8S)容器集群管理环境完整部署详细教程-上篇 Kubernetes(K8S)容器集群管理环境完整部署详细教程-中篇 Kubernetes(K8S)容器集群管理环境完整部署详细教程-下篇 接着Kubernetes(K8S)容器集群管理环境完整部署详细教程-上篇继续往下部署: 八.部署master节点 master节点的kube-apiserver.kube-scheduler 和 kube-controller-manager 均以多实例模式运行:kube-sc
-
Spring Cloud + Nacos + Seata整合过程(分布式事务解决方案)
目录 一.简介 二.seata-server部署 1.官网下载 2.解压到本地 3.修改配置文件 4.seata数据库初始化 5.业务数据库 6.启动seata-server 三.微服务项目集成Seata 1.引入依赖 2.配置文件 一.简介 Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务. 2019 年 1 月,阿里巴巴中间件团队发起了开源项目 Fescar(Fast & EaSy Commit And Rollback),和社区
-
victoriaMetrics代理性能优化问题解析
目录 起因 总结 后续 起因 最近有做一个Prometheus metrics代理的一个小项目,暂称为prom-proxy,目的是为了解析特定的指标(如容器.traefik.istio等指标),然后在原始指标中加入应用ID(当然还有其他指标操作,暂且不表).经过简单的本地验证,就发布到联调环境,跑了几个礼拜一切正常,以为相安无事.但自以为没事不代表真的没事. 昨天突然老环境和新上prom-proxy的环境都出现了数据丢失的情况,如下图: prom-proxy有一个自服务指标request_tot
-
使用Grafana监控Redis的操作方法
目录 Grafana简介 Prometheus简介 安装 使用 监控系统信息 监控SpringBoot应用 总结 参考资料 项目源码地址 当面对一个复杂的系统时,我们往往需要监控工具来帮助我们解决一些性能问题.比如之前我们使用SpringBoot Admin来监控应用,从而获取到SpringBoot Actuator暴露的指标信息.今天给大家介绍一个功能强大的监控工具Grafana,只要需要用到监控的地方,用它做可视化就对了! Grafana简介 Grafana是一款开源的数据可视化和分析工具,
-
MySQL on k8s 云原生环境部署
目录 一.概述 二.开始部署(一主两从) 1)添加源 2)修改配置 3)开始安装 4)测试验证 5)Prometheus监控 6)卸载 一.概述 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品.MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一.这里主要讲mysql部署在k8s上,