深入解析pandas数据聚合和重组
目录
- 1GroupBy技术
- 1.1简介
- 1.3选取一个或一组列
- 1.4通过字典或Series进行分组
- 1.5利用函数进行分组
- 2数据聚合
- 2.1简介
- 2.1面向列的多函数应用
- 2.2以‘无索引’的方式返回聚合数据
介绍pandas数据聚合和重组的相关知识,仅供参考。
1GroupBy技术
1.1简介
简介:根据一个或多个键进行分组,每一组应用函数,再进行合并
分组的键有多种形式:
- 列表或数组,长度与待分组的轴一样
- 表示DataFrame某个列名的值
- 字典或Series,给出待分组轴上的值与分组名之间的对应关系
- 函数,用于处理轴索引或索引中的各个标签
实例:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
df =DataFrame({'key1':list('aabba'),'key2':['one','two','one','two','one'],\
'data1':np.random.randn(5),'data2':np.random.randn(5)})
#根据key1进行分组,并计算data1的均值。
#注意下面的方式,取出来进行分组,而不是在DataFrame中分组,这种方式很灵活
#可以看到这是一个GroupBy对象,具备了应用函数的基础
#这个过程是将Series进行聚合,产生了新的Series
grouped = df['data1'].groupby(df['key1'])
print(grouped,'\n')
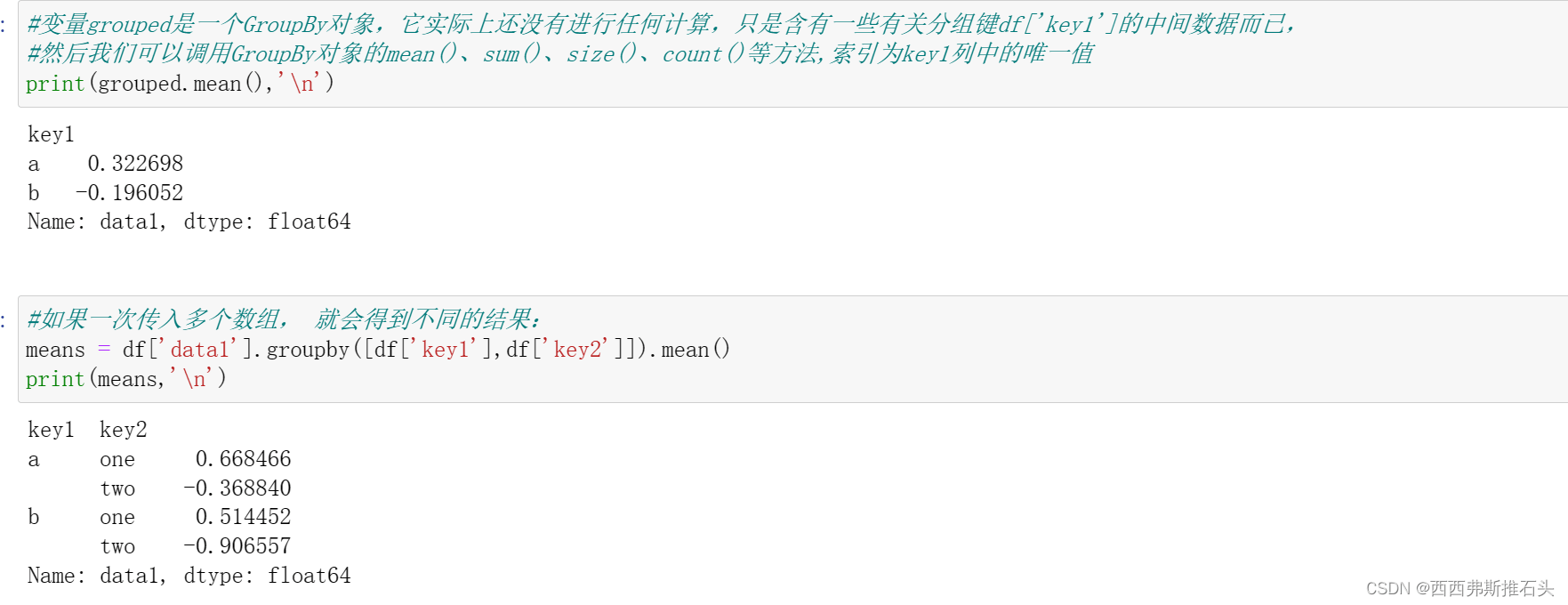
注:
取出来进行分组,而不是在DataFrame中分组分组键中的缺失值被排除在外 1.2对分组进行迭代
GroupBy对象支持迭代,可以产生一组二元元组(由分组名和数据块组成)
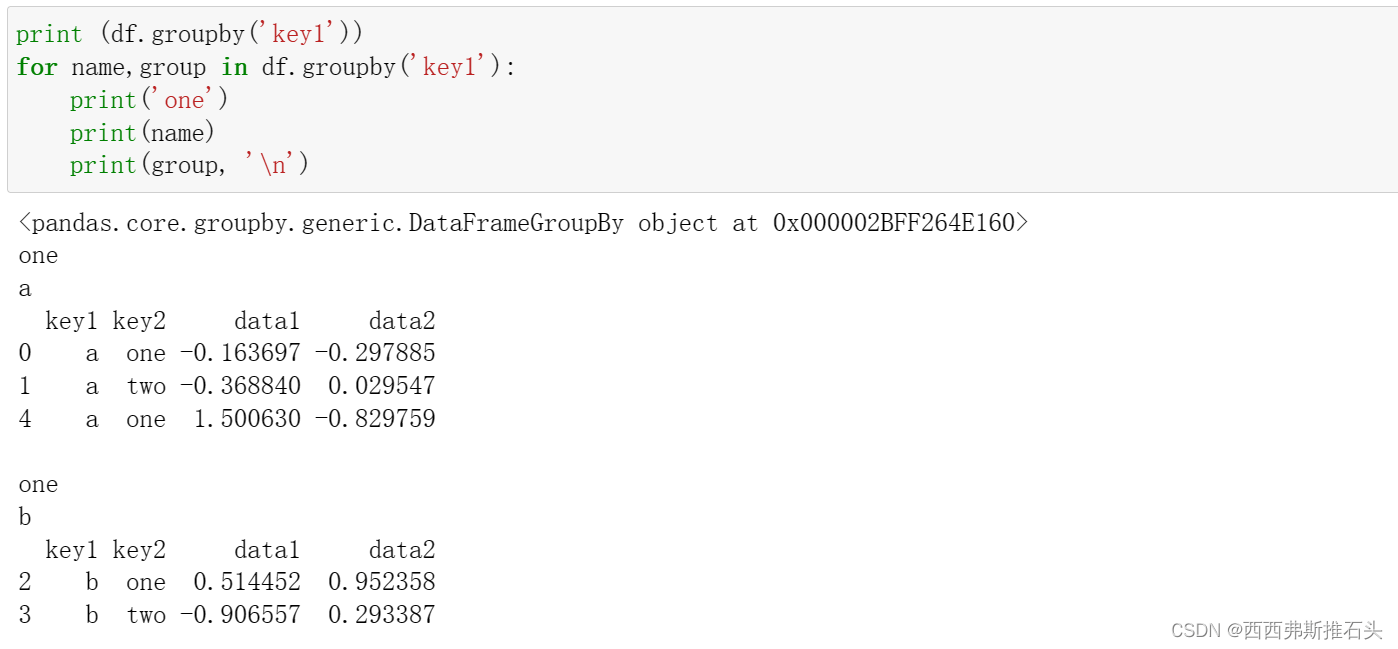

groupby默认在axis=0上进行分组,但可以设置在任何轴上分组

1.3选取一个或一组列
对于由DataFrame产生的GroupBy对象,如果用一个或一组列名进行索引,可实现选取部分列进行聚合的目的,即下面语法效果相同。

1.4通过字典或Series进行分组
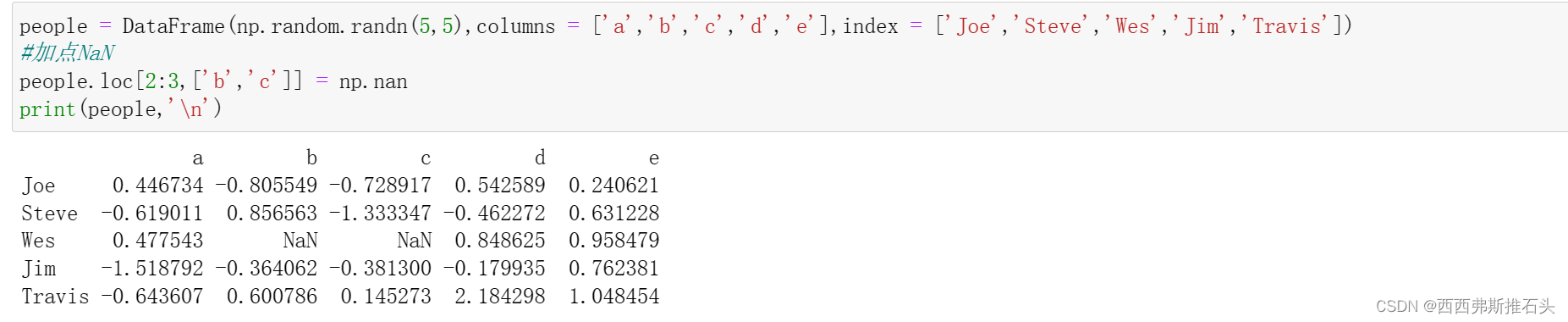
假设已经知道列的分组方式,现在需要利用这个信息进行分组统计。
下面为groupby传入一个已知信息的字典:

相当于将每一个列重设名,再按新的名字进行求和。
Series也有这样的功能,被看作一个固定大小的映射,可以用Series作为分组键,pandas会自动检查对齐。

1.5利用函数进行分组
将函数、数组、字典、Series混用也ok,因为最终都会转换为数组

2数据聚合
2.1简介
简介:
这里的数据聚合是说任何能够从数组产生标量值的过程常见的聚合运算都有就地计算数据集统计信息的优化实现。当然不止这些,可以用自己定义的运算,还可以调用分组对象上已经定义好的任何方法。
例:quantile可计算Series或DataFrame列的样本分位数。

对于自己定义的聚合函数,只需将其传入aggregate或agg即可:

有些方法(describe)也可应用

自定义函数比经过优化的函数要慢得多,这是因为在构造中间分组数据块时存在非常大的开销(函数调用、数据重排等)
可使用的函数:

2.1面向列的多函数应用
有时候需要对不同的列应用不同的函数 ,或者对一列应用不同的函数

若传入一组函数或函数名,得到的DataFrame列就会以相应的函数命名

上面有个问题就是列名是自动给出的,以函数名为列名,若传入元组(name,function)组成的列表,就会自动将第一个元素作为列名

对两列都应用functions:
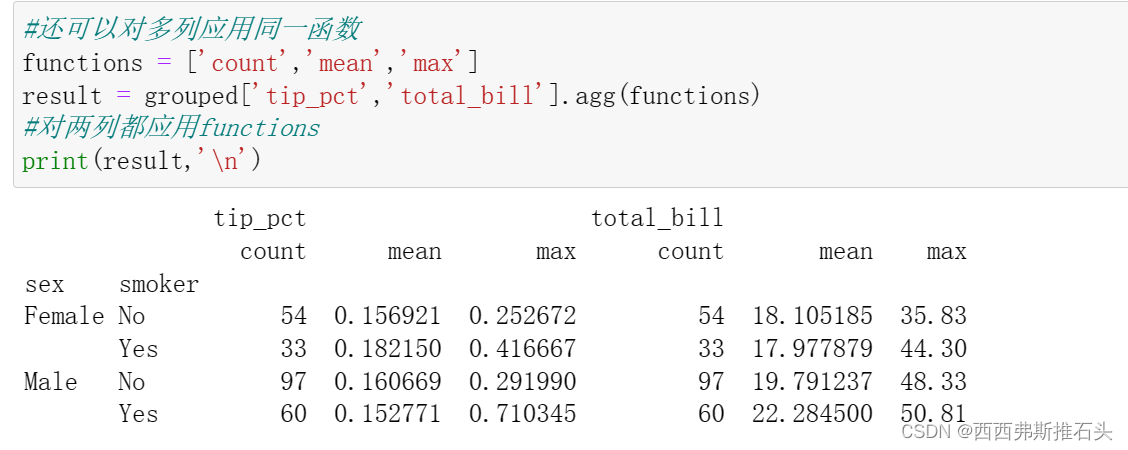
得到的结果的列名是层次化索引,可以直接用外层索引选取数据:

如果想对不同的列应用不同的函数,具体的办法是向agg传入一个从列映射到函数的字典:

2.2以‘无索引’的方式返回聚合数据
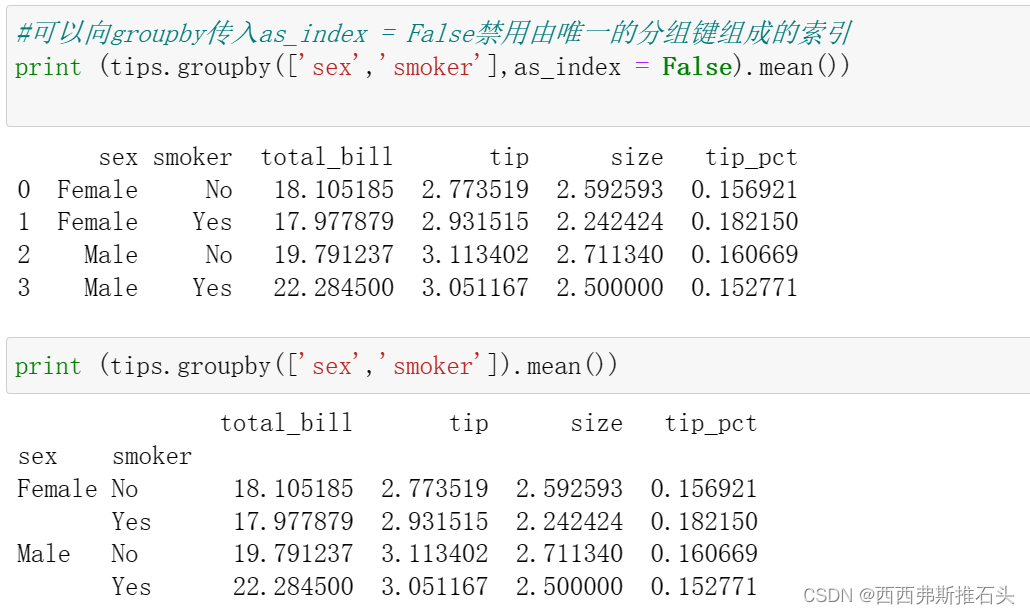
到目前为止,示例中的聚合数据都是由唯一的分组键组成的索引(可能还是层次化的)
由于并不是总需要如此,可以向groupby传入as_index = False禁用该功能
到此这篇关于pandas数据聚合和重组的文章就介绍到这了,更多相关pandas数据聚合内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python Pandas中数据的合并与分组聚合
目录 一.字符串离散化示例 二.数据合并 2.1 join 2.2 merge 三.数据的分组和聚合 四.索引 总结 一.字符串离散化示例 对于一组电影数据,我们希望统计电影分类情况,应该如何处理数据?(每一个电影都有很多个分类) 思路:首先构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1 代码: # coding=utf-8 import pandas as pd from matplotlib import pyplot as plt import numpy as
-
pandas数据分组和聚合操作方法
<Python for Data Analysis> GroupBy 分组运算:split-apply-combine(拆分-应用-合并) DataFrame可以在其行(axis=0)或列(axis=1)上进行分组.然后,将一个函数应用到各个分组并产生新值.最后,所有这些函数的执行结果会被合并到最终的结果对象中去. GroupBy的size方法可以返回一个含有分组大小的Series. 对分组进行迭代 for (k1,k2), group in df.groupby(['key1','key2'
-
Pandas数据分析多文件批次聚合处理实例解析
目录 前言 一.多文件场景 方法一 方法二 二.多文件读取 前言 很多情况下我们处理的文件并不只是一个单纯的CSV文件或者Excel文件.我们会结合更多是数据去进行聚合统计分析,或许是需要解析到一整个数据存储压缩包,或许是对一整个目录文件读取再进行数据操作,这都需要我们掌握一定的多文件处理方法和策略.此篇文章正是基于此场景下处理多文件方法整合策略. 一.多文件场景 我们就以2020年CCF大数据与智能竞赛的数据来作为实例来处理: 现在我们有这么文本文件需要进行读取分析,按照往常我们一个一个读取显
-
深入解析pandas数据聚合和重组
目录 1GroupBy技术 1.1简介 1.3选取一个或一组列 1.4通过字典或Series进行分组 1.5利用函数进行分组 2数据聚合 2.1简介 2.1面向列的多函数应用 2.2以‘无索引’的方式返回聚合数据 介绍pandas数据聚合和重组的相关知识,仅供参考. 1GroupBy技术 1.1简介 简介:根据一个或多个键进行分组,每一组应用函数,再进行合并 分组的键有多种形式: 列表或数组,长度与待分组的轴一样 表示DataFrame某个列名的值 字典或Series,给出待分组轴上的值与分组名
-
Pandas数据离散化原理及实例解析
这篇文章主要介绍了Pandas数据离散化原理及实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 为什么要离散化 连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数.离散化方法经常作为数据挖掘的工具 扔掉一些信息,可以让模型更健壮,泛化能力更强 什么是数据的离散化 连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值 分箱 案例 1.
-
python用pandas数据加载、存储与文件格式的实例
数据加载.存储与文件格式 pandas提供了一些用于将表格型数据读取为DataFrame对象的函数.其中read_csv和read_talbe用得最多 pandas中的解析函数: 函数 说明 read_csv 从文件.URL.文件型对象中加载带分隔符的数据,默认分隔符为逗号 read_table 从文件.URL.文件型对象中加载带分隔符的数据.默认分隔符为制表符("\t") read_fwf 读取定宽列格式数据(也就是说,没有分隔符) read_clipboard 读取剪贴板中的数据,
-
详解Spring Cloud 跨服务数据聚合框架
AG-Merge Spring Cloud 跨服务数据聚合框架 解决问题 解决Spring Cloud服务拆分后分页数据的属性或单个对象的属性拆分之痛, 支持对静态数据属性(数据字典).动态主键数据进行自动注入和转化, 其中聚合的静态数据会进行 一级混存 (guava). 举个栗子: 两个服务,A服务的某张表用到了B服务的某张表的值,我们在对A服务那张表查询的时候,把B服务某张表的值聚合在A服务的那次查询过程中 示例 具体示例代码可以看 ace-merge-demo 模块 |------- ac
-
Python遍历pandas数据方法总结
前言 Pandas是python的一个数据分析包,提供了大量的快速便捷处理数据的函数和方法.其中Pandas定义了Series 和 DataFrame两种数据类型,这使数据操作变得更简单.Series 是一种一维的数据结构,类似于将列表数据值与索引值相结合.DataFrame 是一种二维的数据结构,接近于电子表格或者mysql数据库的形式. 在数据分析中不可避免的涉及到对数据的遍历查询和处理,比如我们需要将dataframe两列数据两两相除,并将结果存储于一个新的列表中.本文通过该例程介绍对pa
-
pandas分组聚合详解
一 前言 pandas学到分组迭代,那么基础的pandas系列就学的差不多了,自我感觉不错,知识追寻者用pandas处理过一些数据,蛮好用的: 知识追寻者(Inheriting the spirit of open source, Spreading technology knowledge;) 二 分组 2.1 数据准备 # -*- coding: utf-8 -*- import pandas as pd import numpy as np frame = pd.DataFrame({ '
-
python 调用API接口 获取和解析 Json数据
任务背景: 调用API接口数据,抽取我们所需类型的数据,并写入指定mysql数据库. 先从宏观上看这个任务,并对任务进行分解: step1:需要学习python下的通过url读取数据的方式: step2:数据解析,也是核心部分,数据格式从python角度去理解,是字典?列表?还是各种嵌套? step3:连接mysql数据库,将数据写入. 从功能上看,该数据获取程序可以分为3个方法,即step1对应方法request_data(),step2对应方法parse_data(),step3对应data
-
Pandas实现聚合运算agg()的示例代码
目录 前言 1. 创建DataFrame对象 2. 单列聚合 3. 多列聚合 4. 多种聚合运算 5. 多种聚合运算并更改列名 6. 不同的列运用不同的聚合函数 7. 使用自定义的聚合函数 8. 方便的descibe 前言 在数据分析中,分组聚合二者缺一不可.对数据聚合(求和.平均值等)通常是不可避免的.pd.agg()很方便进行聚合操作. 1. 创建DataFrame对象 import pandas as pd df1 = pd.DataFrame({'sex':list('FFMFMMF')
-
python pandas分组聚合详细
目录 python pandas分组聚合 1.环境 2.分组 3.序列分组 4.多列分组 5.索引分组 7.聚合 8.单函数对多列 9.多函数对多列 python pandas分组聚合 1.环境 python3.9 win10 64bit pandas==1.2.1 groupby方法是pandas中的分组方法,对数据框采用groupby方法后,返回的是DataFrameGroupBy对象,一般分组操作后会进行聚合操作. 2.分组 import pandas as pd import numpy