SQL Server在AlwaysOn中使用内存表的“踩坑”记录
前言
最近因为线上alwayson环境的一个数据库上使用内存表。经过大概一个星期监控程序发现了一个非常严重问题这个数据库的日志文件不会截断,已用空间一直在增加(存在定时的每个小时的日志备份),同时内存表数据库文件也无法删除,下面就介绍一下后面我的处理过程,话不多说了,来一起看看详细的介绍吧。
数据库:SQL Server2014 Enterprise Edition (64-bit)
删除文件
使用一个单独非alwayson环境的数据库测试。
一、创建内存表
---创建内存表文件组 ALTER DATABASE [test] ADD FILEGROUP [test_ag] CONTAINS MEMORY_OPTIMIZED_DATA GO ----创建内存表数据库文件 ALTER DATABASE [test] ADD FILE ( NAME = 'test_memory', FILENAME ='D:\database\memory' ) TO FILEGROUP [test_ag]; GO
二、删除内存表数据库文件
USE [test] GO ALTER DATABASE [test] REMOVE FILE [test_memory] GO

备注:此时还未创建表,创建完后数据库文件执行删除就无法删除,接下来试试在线文档的删除方法方法
三、官方相关的删除方法
即使已使用“DBCC SHRINKFILE”操作清空 FILESTREAM 容器,但出于各种系统维护原因,数据库可能仍然需要保留对已删除文件的引用。 sp_filestream_force_garbage_collection (TRANSACT-SQL)将运行 FILESTREAM 垃圾回收器删除这些文件时,则可以安全进行这些操作。 除非 FILESTREAM 垃圾回收器已从 FILESTREAM 容器中删除所有文件,否则 ALTER DATABASEREMOVE FILE 操作将无法删除 FILESTREAM 容器并返回错误。 建议使用以下过程删除 FILESTREAM 容器。
1.运行DBCC SHRINKFILE (TRANSACT-SQL)带有 EMPTYFILE 选项以将此容器的活动内容移动到其他容器
USE test; GO -- Create a data file and assume it contains data. ALTER DATABASE test ADD FILE ( NAME = Test1data, FILENAME = 'D:\database\t1data.ndf', SIZE = 5MB ); GO -- Empty the data file. DBCC SHRINKFILE (test_memory, EMPTYFILE); GO

2.确保已在 FULL 或 BULK_LOGGED 恢复模型中执行日志备份。
3.确保复制日志读取器作业已运行(如果相关)。

通过log_reuse_wait_desc的状态可以看到当前数据库已经无需日志备份,当然我已经执行过日志备份。
4.运行sp_filestream_force_garbage_collection (TRANSACT-SQL)强制垃圾回收器删除不再需要此容器中的任何文件
USE [test] GO EXEC sp_filestream_force_garbage_collection @dbname = N'test' @filename = N' test_memory ';
5.执行带有 REMOVE FILE 选项的 ALTER DATABASE,以删除此容器。
USE [test] GO ALTER DATABASE [test] REMOVE FILE [test_memory] GO
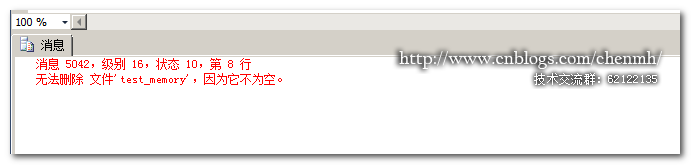
还是无法删除!!!
四、问题分析
一开始是在alwayson的环境中删除,提示由于副本的原因无法删除。后面单独在一个非alwayson的环境下的数据库测试同样是无法删除,起初以为是创建了内存表的原因后面测试仅仅创建文件组和文件然后来删除文件同样是无法删除,个人猜测有可能是buffer的缘故;在buffer中一直存在内存表相关的文件存在,通过执行DBCC DROPCLEANBUFFERS命令也无法清空buffer中的内存表对象。使尽浑身解数还是无法将它删除掉,最后只能投降了!!!线上环境等不下去;只能使用最不愿使用的生成表结构导出数据的办法来重建新的数据库。
生成脚本重建数据库
创建一个新的数据库同时保证当前数据库可用(重命名当前的数据库,新创建的数据库使用之前的名称这样可以保证应用程序那边不需要改变),这样如果出现什么问题也可以及时的切换回来。
步骤如下(在允许停机维护的情况下进行):
1.禁用所有相关作业
2禁用应用程序登入用户
同时保证相关进程事务都已完成。
ALTER LOGIN [test] DISABLE GO USE [master] GO ALTER DATABASE [test] SET SINGLE_USER WITH ROLLBACK IMMEDIATE;--将数据库设置成单用户并回滚当前连接 USE [test];---保持连接操作,防止其它用户此时进行连接 GO
3.执行checkpoint刷新所有脏页
CHECKPOINT ---返回当前buffer中每个数据库所占的buffer大小和buffer中脏页的大小 WITH CTE1 AS ( SELECT COUNT(*) * 8 / 1024 AS dirty_cached_size_MB , COUNT(*) AS dirty_pages, CASE database_id WHEN 32767 THEN 'ResourceDb' ELSE DB_NAME(database_id) END AS database_name FROM sys.dm_os_buffer_descriptors WHERE is_modified = 1 GROUP BY DB_NAME(database_id),database_id ), CET2 AS ( SELECT COUNT(*) * 8 / 1024 AS cached_size_MB , COUNT(*) AS pages, CASE database_id WHEN 32767 THEN 'ResourceDb' ELSE DB_NAME(database_id) END AS database_name FROM sys.dm_os_buffer_descriptors GROUP BY DB_NAME(database_id),database_id ) SELECT CET2.database_name, CET2.cached_size_MB, --CET2.pages, CTE1.dirty_cached_size_MB --CTE1.dirty_pages FROM CTE1 INNER JOIN CET2 ON CTE1.database_name = CET2.database_name ---将数据库选项改成多用户访问 ALTER DATABASE [test] SET MULTI_USER;
4.生成数据库脚本
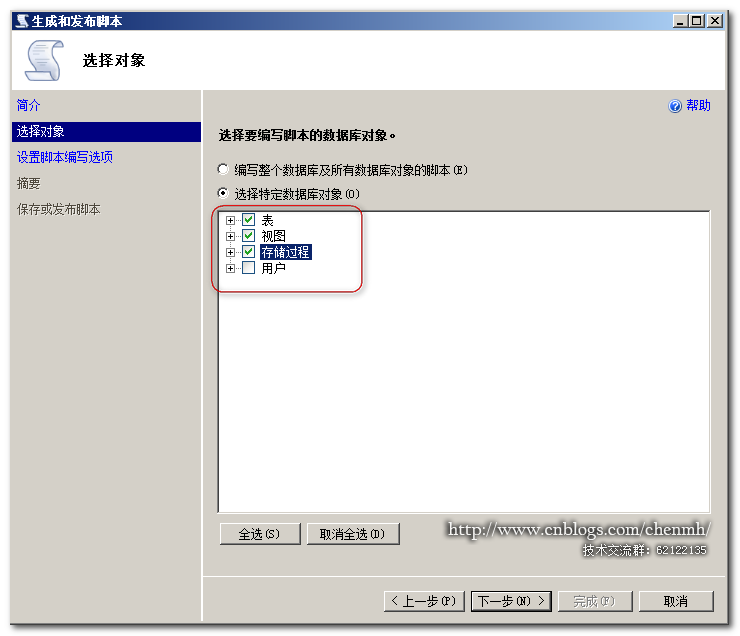
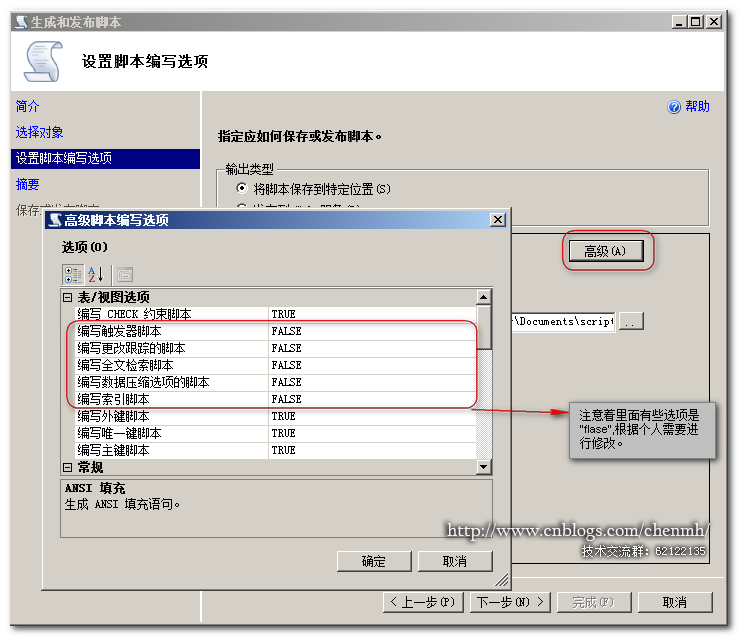
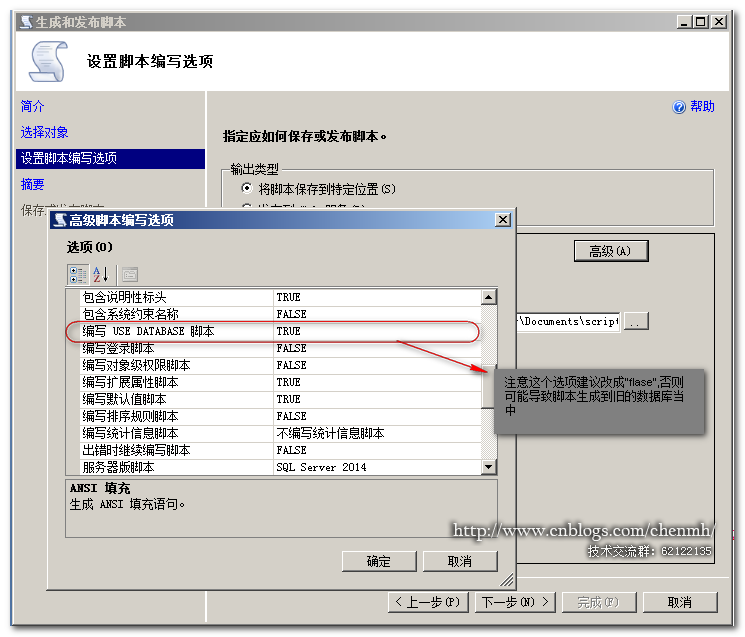
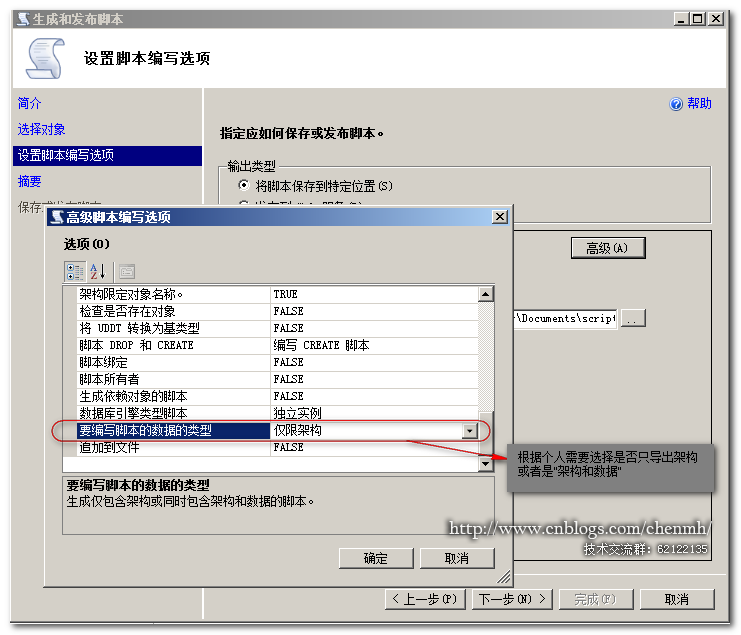
5.重命名旧的数据库
注意:如果数据库是在alwayson中,需要先从可用性数据库中删除,否则无法重命名数据库。
/*
1.断开数据库所有连接同时禁止新的连接进来
2.比如禁止登入用户、将实例设为单用户模式等。
*/
----1.设置数据库脱机
USE [master]
ALTER DATABASE [test] SET OFFLINE WITH ROLLBACK IMMEDIATE;
----2.手动修改数据库物理文件名,例如将test.mdf改成test_old.mdf
----3.语句修改
USE [master]
ALTER DATABASE [test]
MODIFY FILE (NAME = test, FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\test_old.mdf');
GO
ALTER DATABASE [test]
MODIFY FILE (NAME = test_log, FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\test_old_log.ldf');
GO
---4.设置数据库在线
USE [master]
ALTER DATABASE [test] SET ONLINE
----5.修改数据库逻辑文件名
USE [test]
GO
ALTER DATABASE [test] MODIFY FILE (NAME=N'test', NEWNAME=N'test_old')
GO
USE [test]
GO
ALTER DATABASE [test] MODIFY FILE (NAME=N'test_log', NEWNAME=N'test_old_log')
GO
----6.重命名数据库
USE [master]
EXEC sp_renamedb N'test', N'test_old';
----7.查询
SELECT *
FROM sys.master_files
WHERE database_id = DB_ID('test_old');
6.创建新的数据库同时导入脚本到新的数据库
如果同时导出表结构和数据在ssms工具中执行可能会因为脚本过大无法执行,可以使用sqlcmd工具执行脚本导入,具体方法可以百度一下。当然还有其他方法就是只导出表结构然后通过“导出数据\导入数据”的方法同步数据。
注意:如果使用“导出数据\导入数据”的方法同步数据,注意勾选“启用标示插入”
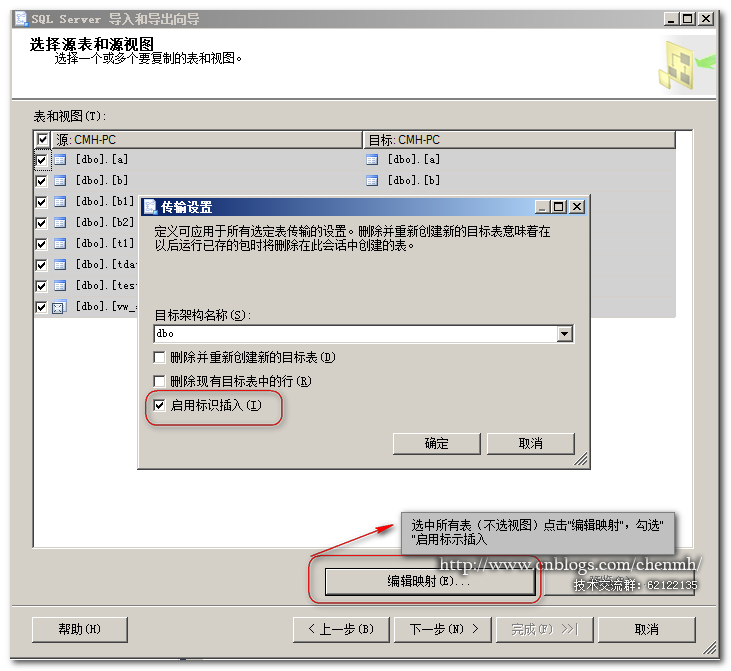
7.其它
1.如果存在alwayson记得将新的数据库加入到可用性数据库组中。
2.将新的数据库加入到备份作业中。
3.对比新旧两个数据库的表数量是否相同。
4.配置登入用户新的数据库权限。
总结
内存表是2014新引入的功能所以对于新功能的第一个版本使用要比较慎重,特别是在线上环境。虽然在上线之前做过测试,但是显然备份这块的测试往往比较容易被忽略因为没有线上的这种环境。好在是这次影响的是一个新上的项目数据量和并发都很小且允许节假日停机维护;如果是非常大的系统对于需要导入导出数据肯定是非常头疼的事情关键还得看允许停机的时长。因为自己在生产环境踩了坑,写这篇文章希望后面的人可以避免踩坑。
备注:内存表在2014版本的alwayson中无法同步到辅助副本,这就导致了它的作用大打折扣,2016版本可以同步到辅助副本,建议有条件的直接上2016。
好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对我们的支持。
相关推荐
-

SQLServer 2012中设置AlwaysOn解决网络抖动导致的提交延迟问题
事件起因:近期有研发反应,某数据库从08切换到12环境后,不定期出现写操作提交延迟的问题: 事件分析:在排除了系统资源争用等问题后,初步分析可能由于网络抖动导致同步模式alwayson节点经常出现会话超时等待提交的问题导致. 经过排查,扩展事件里发现不定期出现35202错误,这是一条副本连接恢复的消息. 由于机房网络环境复杂,数据库服务器和应用服务器混用一个交换机,在业务高峰期时,因上联端口流量打满而导致连接失败的情况屡有发生. 既然短期内无法改造网络环境,那就从SQLSERVER服务器自身出发
-
Windows2012配置SQLServer2014AlwaysOn的图解
SQLserver 2014 AlwaysOn增强了原有的数据库镜像功能,使得先前的单一数据库故障转移变成以组(多个数据)为单位的故障转移.同时可以支持多达9个复制伙伴,可读性辅助副本服务器等多个特性.对于以组为单位的数据库,主要是解决应用对于多个数据库之间存在的依赖性,从而进行整体转移.其次,可以将那些报表或者只读需求转移到只读辅助副本,从而大大减少主副本的负载,使得主副本更加容易扩展,更好地支持生产负载,以及对请求提供更快的响应. 本文描述了基于虚拟环境Windows 2012 + SQLs
-
SQL Server Alwayson创建代理作业的注意事项详解
前言 Always On 可用性组活动辅助功能包括支持在辅助副本上执行备份操作. 备份操作可能会给 I/O 和 CPU 带来很大的压力(使用备份压缩). 将备份负荷转移到已同步或正在同步的辅助副本后,您可以使用承载第一层工作负荷的主副本的服务器实例上的资源,您可以创建主数据库的任何类型的备份. 也可以创建辅助数据库的日志备份和仅复制完整备份.下面话不多说了,来一起看看详细的介绍吧. 一.概念 1.辅助副本上支持的备份类型 BACKUP DATABASE :在辅助副仅支持数据库.文件或文件组的仅复
-
基于Win2008 R2的WSFC实现 SQL Server 2012高可用性组(AlwaysOn Group)
两年前的<SQL Server 2008 R2数据库镜像部署>,今天"再续前缘"-- 微软新一代数据库产品SQL Server 2012已经面世一段时间了,不管从功能上讲还是性能上的体现,较之其早期产品都有了很大提升.特别是其引入高可用性组(AlwaysOn Group, AG)这一概念和功能,大大增强和提高了SQL Server的可用性,在之前的镜像数据库的基础上有了质的变化. SQL Server 2012高可用性组在实现过程中较之早起的SQL Server故障转移群集
-
SQLserver2014(ForAlwaysOn)安装图文教程
SQLserver 2014 AlwaysOn在SQLserver 2012的基础之上,进行了很大程度的增加,如可以通过"添加 Azure 副本向导"简化了用于 AlwaysOn 可用性组的混合解决方案创建:辅助副本的最大数目从 4 增加到 8: 断开与主副本的连接时,或者在缺少群集仲裁期间,可读辅助副本现在保持可用于读取工作负荷: 故障转移群集实例 (FCI) 现在可使用群集共享卷 (CSV) 作为群集共享磁盘: 提供了一个新的系统函数 sys.fn_hadr_is_primary_
-
SQL Server Alwayson添加监听器失败的解决方法
一.错误描述 1.群集服务未能使群集服务或应用程序"Alwayson22"完全联机或脱机.一个或多个资源可能处于失败状态.这可能会影响群集服务或应用程序的可用性 2.群集服务中的群集资源"Listen25"或应用程序"Alwayson22"失败/添加监听器失败 二.处理方法 从错误提示上可以得到问题所在,在确认群集已经启动.DNS.域服务都正常的情况下.是群集服务存在问题,从上图的错误看到"群集网络名称未联机",打开群集核心资
-
SQL Server 2016 无域群集配置 AlwaysON 可用性组图文教程
windows server 2016 与 sql server 2016 都可用允许不许要加入AD ,管理方面省了挺多操作,也不用担心域控出现问题影响各服务器了. 本测试版本: window server 2016 datacenter + sql server 2016 ctp IP规划: 主机名 IP 说明 ad 192.168.2.2 域服务器(kk.com)windows xp Server131 192.168.2.131 节点 Server132 192.168.2.132 节点
-
SQL Server在AlwaysOn中使用内存表的“踩坑”记录
前言 最近因为线上alwayson环境的一个数据库上使用内存表.经过大概一个星期监控程序发现了一个非常严重问题这个数据库的日志文件不会截断,已用空间一直在增加(存在定时的每个小时的日志备份),同时内存表数据库文件也无法删除,下面就介绍一下后面我的处理过程,话不多说了,来一起看看详细的介绍吧. 数据库:SQL Server2014 Enterprise Edition (64-bit) 删除文件 使用一个单独非alwayson环境的数据库测试. 一.创建内存表 ---创建内存表文件组 ALTER
-
Linux/Docker 中使用 System.Drawing.Common 踩坑记录分享
前言 在项目迁移到 .net core 上面后,我们可以使用 System.Drawing.Common 组件来操作 Image,Bitmap 类型,实现生成验证码.二维码,图片操作等功能.System.Drawing.Common 组件它是依赖于 GDI+ 的,然后在 Linux 上并没有 GDI+,面向谷歌编程之后发现,Mono 团队使用 C语言 实现了GDI+ 接口,提供对非Windows系统的 GDI+ 接口访问能力,这个应该就是libgdiplus.所以想让代码在 linux 上稳定运
-
sql语句中union的用法与踩坑记录
目录 sql语句union的用法 补充:SQLUNION踩过的坑 总结 sql语句union的用法 union联合的结果集不会有重复值,如果要有重复值,则使用union all union会自动压缩多个结果集合中重复的结果,使结果不会有重复行,union all 会将所有的结果共全部显示出来,不管是不是重复. union:会对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序. union all:对两个结果集进行并集操作,包括重复行,不会对结果进行排序. 1.sql Union用法
-
SQL Server数据库按百分比查询出表中的记录数
SQL Server数据库查询时,能否按百分比查询出记录的条数呢?答案是肯定的.本文我们就介绍这一实现方法. 实现该功能的代码如下: create procedure pro_topPercent ( @ipercent [int] =0 --默认不返回 ) as begin select top (@ipercent ) percent * from books end 或 create procedure pro_topPercent ( @ipercent [int] =0 ) as be
-
SQL Server查询某个字段在哪些表中存在
一.查询SQL Server中所有的表 SQL语句: SELECT * FROM sys.tables name列表示所有的表名. 二.查询SQL Server中所有的列 SQL语句: SELECT * FROM sys.columns name列表示所有的字段名称. 两张表根据object_id进行关联 语法: select * from sys.tables tinner join sys.columns c on t.object_id=c.object and c.name='要查询的字
-
SQL Server 数据页缓冲区的内存瓶颈分析
SQL Server会把经常使用到的数据缓存在内存里(就是数据页缓存),用以提高数据访问速度.因为磁盘访问速度远远低于内存,所以减少磁盘访问量同样是数据库优化的重要方面. 当数据页缓存区出现内存不足,则会出现查询慢,磁盘忙等等问题. 分析方法:主要是用到性能计数器. 查看如下性能计数器: 1. SQL SERVER:Buffer Manager-Lazy Writes/sec:内存不足则会频繁调用Lazy Writer把数数据写入磁盘,此值会经常不为0. 2. SQL SERVER:Buffer
-
SQL Server遍历表中记录的2种方法(使用表变量和游标)
SQL Server遍历表一般都要用到游标,SQL Server中可以很容易的用游标实现循环,实现SQL Server遍历表中记录.本文将介绍利用使用表变量和游标实现数据库中表的遍历. 表变量来实现表的遍历 以下代码中,代码块之间的差异已经用灰色的背景标记. 复制代码 代码如下: DECLARE @temp TABLE ( [id] INT IDENTITY(1, 1) , [Name] VARCHAR(10) ) DECLARE @tempId INT , @tempName VARCHAR(
-
SQL Server 数据库调整表中列的顺序操作方法及遇到问题
SQL Server 数据库中表一旦创建,我们不建议擅自调整列的顺序,特别是对应的应用系统已经上线,因为部分开发人员,不一定在代码中指明了列名.表是否可以调整列的顺序,其实可以自主设置,我们建议在安装后设置为禁止. 那么,如果确实需要调整某一列的顺序,我们是怎么操作的呢? 下面,我们就要演示一下怎么取消这种限制.当然,通过取消限制的演示,相信大家也知道了怎么添加限制了. 需求及问题描述 1)测试表 Test001 (2)更新前 (3)例如,需求为调整 SN5 和SN4的序列 点击保存时报错 修改
-
SQL Server 2016 Alwayson新增功能图文详解
概述 SQLServer2016发布版本到现在已有一年多的时间了,目前最新的稳定版本是SP1版本.接下来就开看看2016在Alwyson上做了哪些改进,记得之前我在写2014Alwayson的时候提到过几个需要改进的问题在2016上已经做了改进. 一.自动故障转移副本数量 在2016之前的版本自动故障转移副本最多只能配置2个副本,在2016上变成了3个. 说明:自动故障转移增加到三个副本影响并不是很大不是非常的重要,多增加一个故障转移副本也意味着你的作业也需要多维护一个副本.重要程度(一般).
-
Sql Server如何查看被锁的表及解锁的方法
查看被锁表: select spId from master..SysProcesses where db_Name(dbID) = '数据库名称' and spId <> @@SpId and dbID <> 0 解除锁: exec ('Kill '+cast(@spid as varchar)) 查看被锁表: select request_session_id spid,OBJECT_NAME(resource_associated_entity_id) tableName f