SQLServer 批量插入数据的两种方法
--Create DataBase
create database BulkTestDB;
go
use BulkTestDB;
go
--Create Table
Create table BulkTestTable(
Id int primary key,
UserName nvarchar(32),
Pwd varchar(16))
go
--Create Table Valued
CREATE TYPE BulkUdt AS TABLE
(Id int,
UserName nvarchar(32),
Pwd varchar(16))
下面我们使用最简单的Insert语句来插入100万条数据,代码如下:
代码如下:
Stopwatch sw = new Stopwatch();
SqlConnection sqlConn = new SqlConnection(
ConfigurationManager.ConnectionStrings["ConnStr"].ConnectionString);//连接数据库
SqlCommand sqlComm = new SqlCommand();
sqlComm.CommandText = string.Format("insert into BulkTestTable(Id,UserName,Pwd)values(@p0,@p1,@p2)");//参数化SQL
sqlComm.Parameters.Add("@p0", SqlDbType.Int);
sqlComm.Parameters.Add("@p1", SqlDbType.NVarChar);
sqlComm.Parameters.Add("@p2", SqlDbType.VarChar);
sqlComm.CommandType = CommandType.Text;
sqlComm.Connection = sqlConn;
sqlConn.Open();
try
{
//循环插入100万条数据,每次插入10万条,插入10次。
for (int multiply = 0; multiply < 10; multiply++)
{
for (int count = multiply * 100000; count < (multiply + 1) * 100000; count++)
{
sqlComm.Parameters["@p0"].Value = count;
sqlComm.Parameters["@p1"].Value = string.Format("User-{0}", count * multiply);
sqlComm.Parameters["@p2"].Value = string.Format("Pwd-{0}", count * multiply);
sw.Start();
sqlComm.ExecuteNonQuery();
sw.Stop();
}
//每插入10万条数据后,显示此次插入所用时间
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
}
catch (Exception ex)
{
throw ex;
}
finally
{
sqlConn.Close();
}
Console.ReadLine();
耗时图如下:
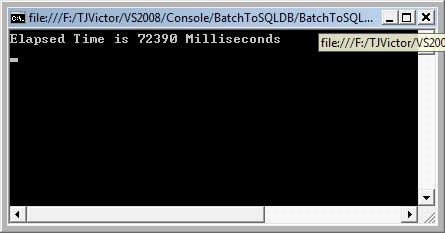
由于运行过慢,才插入10万条就耗时72390 milliseconds,所以我就手动强行停止了。
下面看一下使用Bulk插入的情况:
bulk方法主要思想是通过在客户端把数据都缓存在Table中,然后利用SqlBulkCopy一次性把Table中的数据插入到数据库
public static void BulkToDB(DataTable dt)
{
SqlConnection sqlConn = new SqlConnection(
ConfigurationManager.ConnectionStrings["ConnStr"].ConnectionString);
SqlBulkCopy bulkCopy = new SqlBulkCopy(sqlConn);
bulkCopy.DestinationTableName = "BulkTestTable";
bulkCopy.BatchSize = dt.Rows.Count;
try
{
sqlConn.Open();
if (dt != null && dt.Rows.Count != 0)
bulkCopy.WriteToServer(dt);
}
catch (Exception ex)
{
throw ex;
}
finally
{
sqlConn.Close();
if (bulkCopy != null)
bulkCopy.Close();
}
}
public static DataTable GetTableSchema()
{
DataTable dt = new DataTable();
dt.Columns.AddRange(new DataColumn[]{
new DataColumn("Id",typeof(int)),
new DataColumn("UserName",typeof(string)),
new DataColumn("Pwd",typeof(string))});
return dt;
}
static void Main(string[] args)
{
Stopwatch sw = new Stopwatch();
for (int multiply = 0; multiply < 10; multiply++)
{
DataTable dt = Bulk.GetTableSchema();
for (int count = multiply * 100000; count < (multiply + 1) * 100000; count++)
{
DataRow r = dt.NewRow();
r[0] = count;
r[1] = string.Format("User-{0}", count * multiply);
r[2] = string.Format("Pwd-{0}", count * multiply);
dt.Rows.Add(r);
}
sw.Start();
Bulk.BulkToDB(dt);
sw.Stop();
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
Console.ReadLine();
}
耗时图如下: 
可见,使用Bulk后,效率和性能明显上升。使用Insert插入10万数据耗时72390,而现在使用Bulk插入100万数据才耗时17583。
最后再看看使用表值参数的效率,会另你大为惊讶的。
表值参数是SQL Server 2008新特性,简称TVPs。对于表值参数不熟悉的朋友,可以参考最新的book online,我也会另外写一篇关于表值参数的博客,不过此次不对表值参数的概念做过多的介绍。言归正传,看代码:
代码如下:
public static void TableValuedToDB(DataTable dt)
{
SqlConnection sqlConn = new SqlConnection(
ConfigurationManager.ConnectionStrings["ConnStr"].ConnectionString);
const string TSqlStatement =
"insert into BulkTestTable (Id,UserName,Pwd)" +
" SELECT nc.Id, nc.UserName,nc.Pwd" +
" FROM @NewBulkTestTvp AS nc";
SqlCommand cmd = new SqlCommand(TSqlStatement, sqlConn);
SqlParameter catParam = cmd.Parameters.AddWithValue("@NewBulkTestTvp", dt);
catParam.SqlDbType = SqlDbType.Structured;
//表值参数的名字叫BulkUdt,在上面的建立测试环境的SQL中有。
catParam.TypeName = "dbo.BulkUdt";
try
{
sqlConn.Open();
if (dt != null && dt.Rows.Count != 0)
{
cmd.ExecuteNonQuery();
}
}
catch (Exception ex)
{
throw ex;
}
finally
{
sqlConn.Close();
}
}
public static DataTable GetTableSchema()
{
DataTable dt = new DataTable();
dt.Columns.AddRange(new DataColumn[]{
new DataColumn("Id",typeof(int)),
new DataColumn("UserName",typeof(string)),
new DataColumn("Pwd",typeof(string))});
return dt;
}
static void Main(string[] args)
{
Stopwatch sw = new Stopwatch();
for (int multiply = 0; multiply < 10; multiply++)
{
DataTable dt = TableValued.GetTableSchema();
for (int count = multiply * 100000; count < (multiply + 1) * 100000; count++)
{
DataRow r = dt.NewRow();
r[0] = count;
r[1] = string.Format("User-{0}", count * multiply);
r[2] = string.Format("Pwd-{0}", count * multiply);
dt.Rows.Add(r);
}
sw.Start();
TableValued.TableValuedToDB(dt);
sw.Stop();
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
Console.ReadLine();
}
耗时图如下:
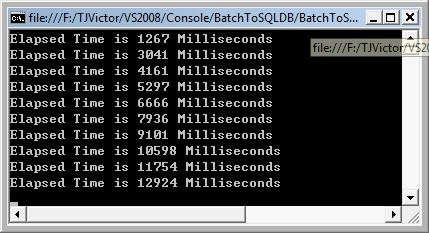
比Bulk还快5秒。
此文原创自CSDN TJVictor
相关推荐
-
快速插入大量数据的asp.net代码(Sqlserver)
复制代码 代码如下: using System.Data; using System.Diagnostics; using System.Data.SqlClient; string connectionString = "Data Source=HG-J3EJJ9LSW5PY;Initial Catalog=Test;User ID=sa;password=hg"; DataTable dataTable = sql_.select_datagrid(" select a
-
SQLServer用存储过程实现插入更新数据示例
实现 1)有相同的数据,直接返回(返回值:0): 2)有主键相同,但是数据不同的数据,进行更新处理(返回值:2): 3)没有数据,进行插入数据处理(返回值:1). [创建存储过程] Create proc Insert_Update @Id varchar(20), @Name varchar(20), @Telephone varchar(20), @Address varchar(20), @Job varchar(20), @returnValue int output as declar
-
sqlserver2008 拆分字符串
--说明:例如,将下列数据 id id_value ----------------- 1 'aa,bb' 2 'aa,bb,cc' 3 'aaa,bbb,ccc' --转换成以下的格式 id id_value ----------------- 1 'aa' 1 'bb' 2 'aa' 2 'bb' 2 'cc' 3 'aaa' 3 'bbb' 3 'ccc' --代码-------------------------------------------GO 复制代码 代码如下: create
-
使用SQL Server 获取插入记录后的ID(自动编号)
最近在开发项目的过程中遇到一个问题,就是在插入一条记录的后要立即获取所在数据库中ID,而该ID是自增的,怎么做?在sql server 2005中有几种方式可以实现. 要获取此ID,最简单的方法就是在查询之后select @@indentity --SQL语句创建数据库和表 复制代码 代码如下: create database dbdemo go use dbdemo go create table tbldemo ( id int primary key identity(1,1),
-
SqlServer下通过XML拆分字符串的方法
复制代码 代码如下: DECLARE @idoc int; DECLARE @doc xml; set @doc=cast('<Root><item><ProjID>'+replace(@SelectedProjectArray,',','</ProjID></item><item><ProjID>')+'</ProjID></item></Root>' as xml) EXEC sp_
-

sqlserver 不能将值NULL插入列id(列不允许有空值解决)
错误现象: Microsoft OLE DB Provider for SQL Server 错误 '80040e2f'不能将值 NULL 插入列 'id',表 'web.dbo.dingdan':列不允许有空值.INSERT 失败. /Untitled-2.asp,行 115 原因分析: SQL数据库中,建立表时没有将id列标识规范设置为"是".所以大家在创建表的时候一定将id设为自动增加id,标识之类的. 解决办法: 点击表,修改,设置id列标识规范为"是",如
-
SQL Server实现将特定字符串拆分并进行插入操作的方法
本文实例讲述了SQL Server实现将特定字符串拆分并进行插入操作的方法.分享给大家供大家参考,具体如下: --循环执行添加操作 declare @idx as int While Len(@UserList) > 0 Begin Set @idx = Charindex(',', @UserList); --只有一条数据 If @idx = 0 and Len(@UserList) > 0 Begin Insert Into BIS_MsgCenterInfo(ID,MsgID,UserI
-
sql server中批量插入与更新两种解决方案分享(asp.net)
若只是需要大批量插入数据使用bcp是最好的,若同时需要插入.删除.更新建议使用SqlDataAdapter我测试过有很高的效率,一般情况下这两种就满足需求了 bcp方式 复制代码 代码如下: /// <summary> /// 大批量插入数据(2000每批次) /// 已采用整体事物控制 /// </summary> /// <param name="connString">数据库链接字符串</param> /// <param n
-
sqlserver中向表中插入多行数据的insert语句
下面把在sql吧里一位高手的解决方法,公布下.供大家参考: 假设有个表有 学号.姓名.学校 这三列 然后向这个表中插入 040501 孙明 山东大学 040502 李浩 山东师范 040503 王刚 烟台大学 怎么插入这三行数据啊~~~~~~~ 复制代码 代码如下: insert 表名 select '040504','孙明','山东大学' union select '040502','李浩','山东师范' union select '040503','王刚','烟台大学'
-
SQLServer 批量插入数据的两种方法
运行下面的脚本,建立测试数据库和表值参数. 复制代码 代码如下: --Create DataBase create database BulkTestDB; go use BulkTestDB; go --Create Table Create table BulkTestTable( Id int primary key, UserName nvarchar(32), Pwd varchar(16)) go --Create Table Valued CREATE TYPE BulkUdt A
-
MyBatis批量插入数据的三种方法实例
目录 前言 准备工作 1.循环单次插入 2.MP 批量插入 ① 控制器实现 ② 业务逻辑层实现 ③ 数据持久层实现 MP 性能测试 MP 源码分析 3.原生批量插入 ① 业务逻辑层扩展 ② 数据持久层扩展 ③ 添加 UserMapper.xml 原生批量插入性能测试 缺点分析 解决方案 总结 前言 批量插入功能是我们日常工作中比较常见的业务功能之一,之前我也写过一篇关于<MyBatis Plus 批量数据插入功能,yyds!>的文章,但评论区的反馈不是很好,主要有两个问题:第一,对 MyBat
-
SQLServer批量插入数据的三种方式及性能对比
昨天下午快下班的时候,无意中听到公司两位同事在探讨批量向数据库插入数据的性能优化问题,顿时来了兴趣,把自己的想法向两位同事说了一下,于是有了本文. 公司技术背景:数据库访问类(xxx.DataBase.Dll)调用存储过程实现数据库的访问. 技术方案一: 压缩时间下程序员写出的第一个版本,仅仅为了完成任务,没有从程序上做任何优化,实现方式是利用数据库访问类调用存储过程,利用循环逐条插入.很明显,这种方式效率并不高,于是有了前面的两位同事讨论效率低的问题. 技术方案二: 由于是考虑到大数据量的批量
-
ASP下批量删除数据的两种方法
方法一: 复制代码 代码如下: id=request.form("checkbox") id=Split(id,",") shu=0 for i=0 to UBound(id) sql="select * from jiang_fname where id="&id(i) set rs=conn.execute(sql) if not rs.eof then delete_file(rs("fname")) end i
-
Mybatis批量修改联合主键数据的两种方法
最近遇上需要批量修改有联合主键的表数据,网上找了很多文章,最终都没找到比较合适的方法,有些只能支持少量数据批量修改,超过十几条就不行了. 最终自己摸索总结了两种方式可以批量修改数据. 第一种: <update id="updateMoreEmpOrg" parameterType="java.util.List"> update hr_emp_org <trim prefix="set" suffixOverrides=&quo
-
mysql大批量插入数据的4种方法示例
前言 本文主要给大家介绍了关于mysql大批量插入数据的4种方法,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 方法一:循环插入 这个也是最普通的方式,如果数据量不是很大,可以使用,但是每次都要消耗连接数据库的资源. 大致思维如下 (我这里写伪代码,具体编写可以结合自己的业务逻辑或者框架语法编写) for($i=1;$i<=100;$i++){ $sql = 'insert...............'; //querysql } foreach($arr as $key =
-
c#读取excel数据的两种方法实现
方法一:OleDb: 用这种方法读取Excel速度还是非常的快的,但这种方式读取数据的时候不太灵活,不过可以在 DataTable 中对数据进行一些删减修改. 优点:读取方式简单.读取速度快 缺点:除了读取过程不太灵活之外,这种读取方式还有个弊端就是,当Excel数据量很大时.会非常占用内存,当内存不够时会抛出内存溢出的异常. 不过一般情况下还是非常不错的. (代码比原文相较有所修改) DataTable GetDataFromExcelByConn(bool hasTitle = false)
-
c# 向MySQL添加数据的两种方法
下面介绍两种执行SQL命令的方法,并作出相应地总结,第一种介绍一种常规用法,下面进行做简要地分析,首先我们需要执行打开数据库操作首先创建一个MySqlConnection对象,在其构造函数中传入一个连接字符串,然后执行Open操作打开数据库,在正确打开数据库之后我们才能进行相关的动作,在ExecuteSQL这个函数中, 我们执行MySqlCommand myCmd = new MySqlCommand(CmdString, conn),从而创建MySqlCommand对象,其中传入的两个参数分别
-
使用Java构造和解析Json数据的两种方法(详解二)
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,是理想的数据交换格式.同时,JSON是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON数据不须要任何特殊的 API 或工具包. 在www.json.org上公布了很多JAVA下的json构造和解析工具,其中org.json和json-lib比较简单,两者使用上差不多但还是有些区别.下面接着介绍用org.json构造和解析Json数据的方法
-
使用Java构造和解析Json数据的两种方法(详解一)
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,是理想的数据交换格式.同时,JSON是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON数据不须要任何特殊的 API 或工具包. 在www.json.org上公布了很多JAVA下的json构造和解析工具,其中org.json和json-lib比较简单,两者使用上差不多但还是有些区别.下面首先介绍用json-lib构造和解析Json数据的方法