Python Pandas数据处理高频操作详解
目录
- 引入依赖
- 算法相关依赖
- 获取数据
- 生成df
- 重命名列
- 增加列
- 缺失值处理
- 独热编码
- 替换值
- 删除列
- 数据筛选
- 差值计算
- 数据修改
- 时间格式转换
- 设置索引列
- 折线图
- 散点图
- 柱状图
- 热力图
- 66个最常用的pandas数据分析函数
- 从各种不同的来源和格式导入数据
- 导出数据
- 创建测试对象
- 查看、检查数据
- 数据选取
- 数据清理
- 筛选,排序和分组依据
- 数据合并
- 数据统计
- 16个函数,用于数据清洗
- 1.cat函数
- 2.contains
- 3.startswith/endswith
- 4.count
- 5.get
- 6.len
- 7.upper/lower
- 8.pad+side参数/center
- 9.repeat
- 10.slice_replace
- 11.replace
- 12.replace
- 13.split方法+expand参数
- 14.strip/rstrip/lstrip
- 15.findall
- 16.extract/extractall
引入依赖
# 导入模块
import pymysql
import pandas as pd
import numpy as np
import time
# 数据库
from sqlalchemy import create_engine
# 可视化
import matplotlib.pyplot as plt
# 如果你的设备是配备Retina屏幕的mac,可以在jupyter notebook中,使用下面一行代码有效提高图像画质
%config InlineBackend.figure_format = 'retina'
# 解决 plt 中文显示的问题 mymac
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
# 设置显示中文 需要先安装字体 aistudio
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import seaborn as sns
# notebook渲染图片
%matplotlib inline
import pyecharts
# 忽略版本问题
import warnings
warnings.filterwarnings("ignore")
# 下载中文字体 !wget https://mydueros.cdn.bcebos.com/font/simhei.ttf # 将字体文件复制到 matplotlib'字体路径 !cp simhei.ttf /opt/conda/envs/python35-paddle120-env/Lib/python3,7/site-packages/matplotib/mpl-data/fonts. # 一般只需要将字体文件复制到系统字体田录下即可,但是在 studio上该路径没有写权限,所以此方法不能用 # !cp simhei. ttf /usr/share/fonts/ # 创建系统字体文件路径 !mkdir .fonts # 复制文件到该路径 !cp simhei.ttf .fonts/ !rm -rf .cache/matplotlib
算法相关依赖
# 数据归一化 from sklearn.preprocessing import MinMaxScaler # kmeans聚类 from sklearn.cluster import KMeans # DBSCAN聚类 from sklearn.cluster import DBSCAN # 线性回归算法 from sklearn.linear_model import LinearRegression # 逻辑回归算法 from sklearn.linear_model import LogisticRegression # 高斯贝叶斯 from sklearn.naive_bayes import GaussianNB # 划分训练/测试集 from sklearn.model_selection import train_test_split # 准确度报告 from sklearn import metrics # 矩阵报告和均方误差 from sklearn.metrics import classification_report, mean_squared_error
获取数据
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:root@127.0.0.1:3306/ry?charset=utf8')
# 查询插入后相关表名及行数
result_query_sql = "use information_schema;"
engine.execute(result_query_sql)
result_query_sql = "SELECT table_name,table_rows FROM tables WHERE TABLE_NAME LIKE 'log%%' order by table_rows desc;"
df_result = pd.read_sql(result_query_sql, engine)
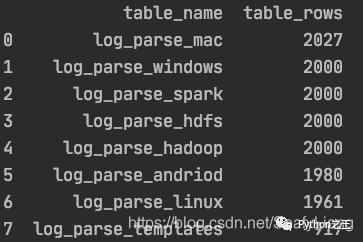
生成df
# list转df
df_result = pd.DataFrame(pred,columns=['pred'])
df_result['actual'] = test_target
df_result
# df取子df
df_new = df_old[['col1','col2']]
# dict生成df
df_test = pd.DataFrame({<!-- -->'A':[0.587221, 0.135673, 0.135673, 0.135673, 0.135673],
'B':['a', 'b', 'c', 'd', 'e'],
'C':[1, 2, 3, 4, 5]})
# 指定列名
data = pd.DataFrame(dataset.data, columns=dataset.feature_names)
# 使用numpy生成20个指定分布(如标准正态分布)的数
tem = np.random.normal(0, 1, 20)
df3 = pd.DataFrame(tem)
# 生成一个和df长度相同的随机数dataframe
df1 = pd.DataFrame(pd.Series(np.random.randint(1, 10, 135)))
重命名列
# 重命名列
data_scaled = data_scaled.rename(columns={<!-- -->'本体油位': 'OILLV'})
增加列
# df2df df_jj2yyb['r_time'] = pd.to_datetime(df_jj2yyb['cTime']) # 新增一列根据salary将数据分为3组 bins = [0,5000, 20000, 50000] group_names = ['低', '中', '高'] df['categories'] = pd.cut(df['salary'], bins, labels=group_names)
缺失值处理
# 检查数据中是否含有任何缺失值
df.isnull().values.any()
# 查看每列数据缺失值情况
df.isnull().sum()
# 提取某列含有空值的行
df[df['日期'].isnull()]
# 输出每列缺失值具体行数
for i in df.columns:
if df[i].count() != len(df):
row = df[i][df[i].isnull().values].index.tolist()
print('列名:"{}", 第{}行位置有缺失值'.format(i,row))
# 众数填充
heart_df['Thal'].fillna(heart_df['Thal'].mode(dropna=True)[0], inplace=True)
# 连续值列的空值用平均值填充
dfcolumns = heart_df_encoded.columns.values.tolist()
for item in dfcolumns:
if heart_df_encoded[item].dtype == 'float':
heart_df_encoded[item].fillna(heart_df_encoded[item].median(), inplace=True)
独热编码
df_encoded = pd.get_dummies(df_data)
替换值
# 按列值替换
num_encode = {<!-- -->
'AHD': {<!-- -->'No':0, "Yes":1},
}
heart_df.replace(num_encode,inplace=True)
删除列
df_jj2.drop(['coll_time', 'polar', 'conn_type', 'phase', 'id', 'Unnamed: 0'],axis=1,inplace=True)
数据筛选
# 取第33行数据
df.iloc[32]
# 某列以xxx字符串开头
df_jj2 = df_512.loc[df_512["transformer"].str.startswith('JJ2')]
df_jj2yya = df_jj2.loc[df_jj2["变压器编号"]=='JJ2YYA']
# 提取第一列中不在第二列出现的数字
df['col1'][~df['col1'].isin(df['col2'])]
# 查找两列值相等的行号
np.where(df.secondType == df.thirdType)
# 包含字符串
results = df['grammer'].str.contains("Python")
# 提取列名
df.columns
# 查看某列唯一值(种类)
df['education'].nunique()
# 删除重复数据
df.drop_duplicates(inplace=True)
# 某列等于某值
df[df.col_name==0.587221]
# df.col_name==0.587221 各行判断结果返回值(True/False)
# 查看某列唯一值及计数
df_jj2["变压器编号"].value_counts()
# 时间段筛选
df_jj2yyb_0501_0701 = df_jj2yyb[(df_jj2yyb['r_time'] >=pd.to_datetime('20200501')) & (df_jj2yyb['r_time'] <= pd.to_datetime('20200701'))]
# 数值筛选
df[(df['popularity'] > 3) & (df['popularity'] < 7)]
# 某列字符串截取
df['Time'].str[0:8]
# 随机取num行
ins_1 = df.sample(n=num)
# 数据去重
df.drop_duplicates(['grammer'])
# 按某列排序(降序)
df.sort_values("popularity",inplace=True, ascending=False)
# 取某列最大值所在行
df[df['popularity'] == df['popularity'].max()]
# 取某列最大num行
df.nlargest(num,'col_name')
# 最大num列画横向柱形图
df.nlargest(10).plot(kind='barh')
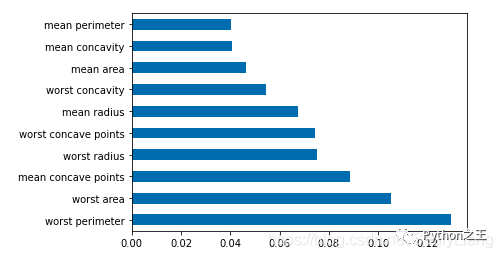
差值计算
# axis=0或index表示上下移动, periods表示移动的次数,为正时向下移,为负时向上移动。 print(df.diff( periods=1, axis=‘index‘)) print(df.diff( periods=-1, axis=0)) # axis=1或columns表示左右移动,periods表示移动的次数,为正时向右移,为负时向左移动。 print(df.diff( periods=1, axis=‘columns‘)) print(df.diff( periods=-1, axis=1)) # 变化率计算 data['收盘价(元)'].pct_change() # 以5个数据作为一个数据滑动窗口,在这个5个数据上取均值 df['收盘价(元)'].rolling(5).mean()
数据修改
# 删除最后一行
df = df.drop(labels=df.shape[0]-1)
# 添加一行数据['Perl',6.6]
row = {<!-- -->'grammer':'Perl','popularity':6.6}
df = df.append(row,ignore_index=True)
# 某列小数转百分数
df.style.format({<!-- -->'data': '{0:.2%}'.format})
# 反转行
df.iloc[::-1, :]
# 以两列制作数据透视
pd.pivot_table(df,values=["salary","score"],index="positionId")
# 同时对两列进行计算
df[["salary","score"]].agg([np.sum,np.mean,np.min])
# 对不同列执行不同的计算
df.agg({<!-- -->"salary":np.sum,"score":np.mean})
时间格式转换
# 时间戳转时间字符串
df_jj2['cTime'] =df_jj2['coll_time'].apply(lambda x: time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(x)))
# 时间字符串转时间格式
df_jj2yyb['r_time'] = pd.to_datetime(df_jj2yyb['cTime'])
# 时间格式转时间戳
dtime = pd.to_datetime(df_jj2yyb['r_time'])
v = (dtime.values - np.datetime64('1970-01-01T08:00:00Z')) / np.timedelta64(1, 'ms')
df_jj2yyb['timestamp'] = v
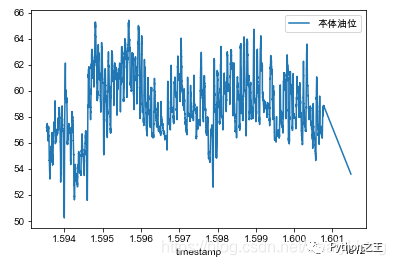
设置索引列
df_jj2yyb_small_noise = df_jj2yyb_small_noise.set_index('timestamp')
折线图
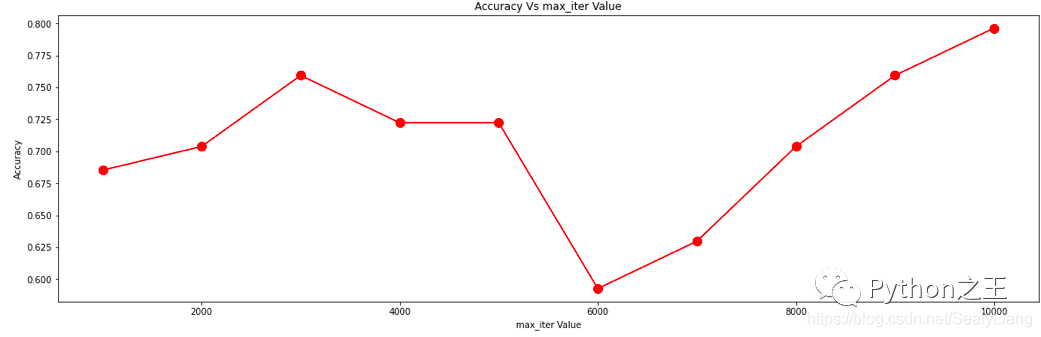
fig, ax = plt.subplots() df.plot(legend=True, ax=ax) plt.legend(loc=1) plt.show()
plt.figure(figsize=(20, 6))
plt.plot(max_iter_list, accuracy, color='red', marker='o',
markersize=10)
plt.title('Accuracy Vs max_iter Value')
plt.xlabel('max_iter Value')
plt.ylabel('Accuracy')
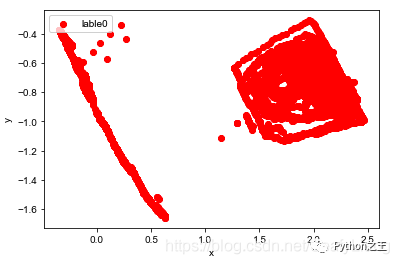
散点图
plt.scatter(df[:, 0], df[:, 1], c="red", marker='o', label='lable0')
plt.xlabel('x')
plt.ylabel('y')
plt.legend(loc=2)
plt.show()
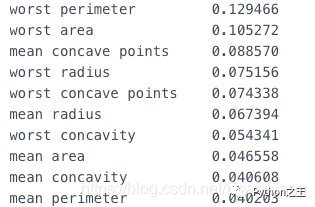
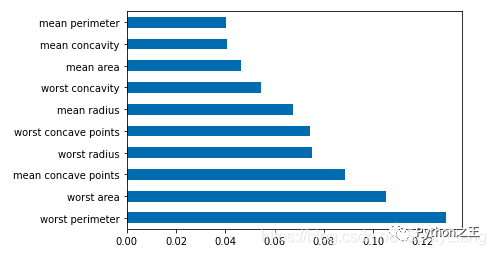
柱状图
df = pd.Series(tree.feature_importances_, index=data.columns) # 取某列最大Num行画横向柱形图 df.nlargest(10).plot(kind='barh')
热力图
df_corr = combine.corr() plt.figure(figsize=(20,20)) g=sns.heatmap(df_corr,annot=True,cmap="RdYlGn")
66个最常用的pandas数据分析函数
df #任何pandas DataFrame对象 s #任何pandas series对象
从各种不同的来源和格式导入数据
pd.read_csv(filename) # 从CSV文件 pd.read_table(filename) # 从分隔的文本文件(例如CSV)中 pd.read_excel(filename) # 从Excel文件 pd.read_sql(query, connection_object) # 从SQL表/数据库中读取 pd.read_json(json_string) # 从JSON格式的字符串,URL或文件中读取。 pd.read_html(url) # 解析html URL,字符串或文件,并将表提取到数据帧列表 pd.read_clipboard() # 获取剪贴板的内容并将其传递给 read_table() pd.DataFrame(dict) # 从字典中,列名称的键,列表中的数据的值
导出数据
df.to_csv(filename) # 写入CSV文件 df.to_excel(filename) # 写入Excel文件 df.to_sql(table_name, connection_object) # 写入SQL表 df.to_json(filename) # 以JSON格式写入文件
创建测试对象
pd.DataFrame(np.random.rand(20,5)) # 5列20行随机浮点数 pd.Series(my_list) # 从一个可迭代的序列创建一个序列 my_list
df.index = pd.date_range('1900/1/30', periods=df.shape[0]) # 添加日期索引
查看、检查数据
df.head(n) # DataFrame的前n行 df.tail(n) # DataFrame的最后n行 df.shape # 行数和列数 df.info() # 索引,数据类型和内存信息 df.describe() # 数值列的摘要统计信息 s.value_counts(dropna=False) # 查看唯一值和计数 df.apply(pd.Series.value_counts) # 所有列的唯一值和计数
数据选取
使用这些命令选择数据的特定子集。 df[col] # 返回带有标签col的列 df[[col1, col2]] # 返回列作为新的DataFrame s.iloc[0] # 按位置选择 s.loc['index_one'] # 按索引选择 df.iloc[0,:] # 第一行 df.iloc[0,0] # 第一栏的第一元素
数据清理
df.columns = ['a','b','c'] # 重命名列
pd.isnull() # 空值检查,返回Boolean Arrray
pd.notnull() # 与pd.isnull() 相反
df.dropna() # 删除所有包含空值的行
df.dropna(axis=1) # 删除所有包含空值的列
df.dropna(axis=1,thresh=n) # 删除所有具有少于n个非null值的行
df.fillna(x) # 将所有空值替换为x
s.fillna(s.mean()) # 用均值替换所有空值(均值可以用统计模块中的几乎所有函数替换 )
s.astype(float) # 将系列的数据类型转换为float
s.replace(1,'one') # 1 用 'one'
s.replace([1,3],['one','three']) # 替换所有等于的值 替换为所有1 'one' ,并 3 用 'three' df.rename(columns=lambda x: x + 1) # 列的重命名
df.rename(columns={<!-- -->'old_name': 'new_ name'})# 选择性重命名
df.set_index('column_one') # 更改索引
df.rename(index=lambda x: x + 1) # 大规模重命名索引
筛选,排序和分组依据
df[df[col] > 0.5] # 列 col 大于 0.5 df[(df[col] > 0.5) & (df[col] < 0.7)] # 小于 0.7 大于0.5的行 df.sort_values(col1) # 按col1升序对值进行排序 df.sort_values(col2,ascending=False) # 按col2 降序对值进行 排序 df.sort_values([col1,col2],ascending=[True,False]) #按 col1 升序排序,然后 col2 按降序排序 df.groupby(col) #从一个栏返回GROUPBY对象 df.groupby([col1,col2]) # 返回来自多个列的groupby对象 df.groupby(col1)[col2] # 返回中的值的平均值 col2,按中的值分组 col1 (平均值可以用统计模块中的几乎所有函数替换 ) df.pivot_table(index=col1,values=[col2,col3],aggfunc=mean) # 创建一个数据透视表组通过 col1 ,并计算平均值的 col2 和 col3 df.groupby(col1).agg(np.mean) # 在所有列中找到每个唯一col1 组的平均值 df.apply(np.mean) #np.mean() 在每列上应用该函数 df.apply(np.max,axis=1) # np.max() 在每行上应用功能
数据合并
df1.append(df2) # 将df2添加 df1的末尾 (各列应相同) pd.concat([df1, df2],axis=1) # 将 df1的列添加到df2的末尾 (行应相同) df1.join(df2,on=col1,how='inner') # SQL样式将列 df1 与 df2 行所在的列col 具有相同值的列连接起来。'how'可以是一个 'left', 'right', 'outer', 'inner'
数据统计
df.describe() # 数值列的摘要统计信息 df.mean() # 返回均值的所有列 df.corr() # 返回DataFrame中各列之间的相关性 df.count() # 返回非空值的每个数据帧列中的数字 df.max() # 返回每列中的最高值 df.min() # 返回每一列中的最小值 df.median() # 返回每列的中位数 df.std() # 返回每列的标准偏差
16个函数,用于数据清洗
# 导入数据集
import pandas as pd
df ={<!-- -->'姓名':[' 黄同学','黄至尊','黄老邪 ','陈大美','孙尚香'],
'英文名':['Huang tong_xue','huang zhi_zun','Huang Lao_xie','Chen Da_mei','sun shang_xiang'],
'性别':['男','women','men','女','男'],
'身份证':['463895200003128433','429475199912122345','420934199110102311','431085200005230122','420953199509082345'],
'身高':['mid:175_good','low:165_bad','low:159_bad','high:180_verygood','low:172_bad'],
'家庭住址':['湖北广水','河南信阳','广西桂林','湖北孝感','广东广州'],
'电话号码':['13434813546','19748672895','16728613064','14561586431','19384683910'],
'收入':['1.1万','8.5千','0.9万','6.5千','2.0万']}
df = pd.DataFrame(df)
df
1.cat函数
用于字符串的拼接
df["姓名"].str.cat(df["家庭住址"],sep='-'*3)
2.contains
判断某个字符串是否包含给定字符
df["家庭住址"].str.contains("广")
3.startswith/endswith
判断某个字符串是否以…开头/结尾
# 第一个行的“ 黄伟”是以空格开头的
df["姓名"].str.startswith("黄")
df["英文名"].str.endswith("e")
4.count
计算给定字符在字符串中出现的次数
df["电话号码"].str.count("3")
5.get
获取指定位置的字符串
df["姓名"].str.get(-1)
df["身高"].str.split(":")
df["身高"].str.split(":").str.get(0)
6.len
计算字符串长度
df["性别"].str.len()
7.upper/lower
英文大小写转换
df["英文名"].str.upper() df["英文名"].str.lower()
8.pad+side参数/center
在字符串的左边、右边或左右两边添加给定字符
df["家庭住址"].str.pad(10,fillchar="*") # 相当于ljust() df["家庭住址"].str.pad(10,side="right",fillchar="*") # 相当于rjust() df["家庭住址"].str.center(10,fillchar="*")
9.repeat
重复字符串几次
df["性别"].str.repeat(3)
10.slice_replace
使用给定的字符串,替换指定的位置的字符
df["电话号码"].str.slice_replace(4,8,"*"*4)
11.replace
将指定位置的字符,替换为给定的字符串
df["身高"].str.replace(":","-")
12.replace
将指定位置的字符,替换为给定的字符串(接受正则表达式)
replace中传入正则表达式,才叫好用;- 先不要管下面这个案例有没有用,你只需要知道,使用正则做数据清洗多好用;
df["收入"].str.replace("\d+\.\d+","正则")
13.split方法+expand参数
搭配join方法功能很强大
# 普通用法
df["身高"].str.split(":")
# split方法,搭配expand参数
df[["身高描述","final身高"]] = df["身高"].str.split(":",expand=True)
df
# split方法搭配join方法
df["身高"].str.split(":").str.join("?"*5)
14.strip/rstrip/lstrip
去除空白符、换行符
df["姓名"].str.len() df["姓名"] = df["姓名"].str.strip() df["姓名"].str.len()
15.findall
利用正则表达式,去字符串中匹配,返回查找结果的列表
findall使用正则表达式,做数据清洗,真的很香!
df["身高"]
df["身高"].str.findall("[a-zA-Z]+")
16.extract/extractall
接受正则表达式,抽取匹配的字符串(一定要加上括号)
df["身高"].str.extract("([a-zA-Z]+)")
# extractall提取得到复合索引
df["身高"].str.extractall("([a-zA-Z]+)")
# extract搭配expand参数
df["身高"].str.extract("([a-zA-Z]+).*?([a-zA-Z]+)",expand=True
以上就是Python Pandas数据处理高频操作详解的详细内容,更多关于Python Pandas数据处理的资料请关注我们其它相关文章!
相关推荐
-

Pandas数据处理加速技巧汇总
目录 数据准备 日期时间数据优化 数据的简单循环 循环 .itertuples() 和 .iterrows() 方法 .apply() 方法 .isin() 数据选择 .cut() 数据分箱 Numpy 方法处理 处理效率比较 HDFStore 防止重新处理 Pandas 处理数据的效率还是很优秀的,相对于大规模的数据集只要掌握好正确的方法,就能让在数据处理时间上节省很多很多的时间. Pandas 是建立在 NumPy 数组结构之上的,许多操作都是在 C 中执行的,要么通过 NumPy,要么通过
-
Python数据处理pandas读写操作IO工具CSV
目录 前言 1 CSV 和文本文件 1 参数解析 1.1 基础 1.2 列.索引.名称 1.3 常规解析配置 1.4 NA 和缺失数据处理 1.5 日期时间处理 1.6 迭代 1.7 引用.压缩和文件格式 1.8 错误处理 2. 指定数据列的类型 前言 前面我们介绍了 pandas 的基础语法操作,下面我们开始介绍 pandas 的数据读写操作. pandas 的 IO API 是一组顶层的 reader 函数,比如 pandas.read_csv(),会返回一个 pandas 对象. 而相应的
-
六个实用Pandas数据处理代码
目录 选取有空值的行 快速替换列值 对列进行分区 将一列分为多列 中文筛选 更改列的位置 前言: 今天和大家分享自己总结的6个常用的Pandas数据处理代码,对于经常处理数据的coder最好熟练掌握. 选取有空值的行 在观察数据结构时,该方法可以快速定位存在缺失值的行. df = pd.DataFrame({'A': [0, 1, 2], 'B': [0, 1, None], 'C': [0, None, 2]}) df[df.isnull().T.any()] 输出: A B C
-
Pandas处理时间序列数据操作详解
目录 前言 一.获取时间 二.时间索引 三.时间推移 前言 一般从数据库或者是从日志文件读出的数据均带有时间序列,做时序数据处理或者实时分析都需要对其时间序列进行归类归档.而Pandas是处理这些数据很好用的工具包.此篇博客基于Jupyter之上进行演示,本篇博客的愿景是希望我或者读者通过阅读这篇博客能够学会方法并能实际运用.希望读者看完能够提出问题或者看法,博主会长期维护博客做及时更新.纯分享,希望大家喜欢. 一.获取时间 python自带datetime库,通过调用此库可以获取本地时间 fr
-
Python 数据处理库 pandas 入门教程基本操作
pandas是一个Python语言的软件包,在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础编程库.本文是对它的一个入门教程. pandas提供了快速,灵活和富有表现力的数据结构,目的是使"关系"或"标记"数据的工作既简单又直观.它旨在成为在Python中进行实际数据分析的高级构建块. 入门介绍 pandas适合于许多不同类型的数据,包括: 具有异构类型列的表格数据,例如SQL表格或Excel数据 有序和无序(不一定是固定频率)时间序列数据.
-
使用pandas实现连续数据的离散化处理方式(分箱操作)
Python实现连续数据的离散化处理主要基于两个函数,pandas.cut和pandas.qcut,前者根据指定分界点对连续数据进行分箱处理,后者则可以根据指定箱子的数量对连续数据进行等宽分箱处理,所谓等宽指的是每个箱子中的数据量是相同的. 下面简单介绍一下这两个函数的用法: # 导入pandas包 import pandas as pd ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32] # 待分箱数据 bins = [18, 25,
-
pandas数据预处理之dataframe的groupby操作方法
在数据预处理过程中可能会遇到这样的问题,如下图:数据中某一个key有多组数据,如何分别对每个key进行相同的运算? dataframe里面给出了一个group by的一个操作,对于"group by"操作,我们通常是指以下一个或多个操作步骤: l (Splitting)按照一些规则将数据分为不同的组: l (Applying)对于每组数据分别执行一个函数: l (Combining)将结果组合到一个数据结构中: 使用dataframe实现groupby的用法: # -*- coding
-
Python Pandas数据处理高频操作详解
目录 引入依赖 算法相关依赖 获取数据 生成df 重命名列 增加列 缺失值处理 独热编码 替换值 删除列 数据筛选 差值计算 数据修改 时间格式转换 设置索引列 折线图 散点图 柱状图 热力图 66个最常用的pandas数据分析函数 从各种不同的来源和格式导入数据 导出数据 创建测试对象 查看.检查数据 数据选取 数据清理 筛选,排序和分组依据 数据合并 数据统计 16个函数,用于数据清洗 1.cat函数 2.contains 3.startswith/endswith 4.count 5.ge
-
Python pandas 列转行操作详解(类似hive中explode方法)
最近在工作上用到Python的pandas库来处理excel文件,遇到列转行的问题.找了一番资料后成功了,记录一下. 1. 如果需要爆炸的只有一列: df=pd.DataFrame({'A':[1,2],'B':[[1,2],[1,2]]}) df Out[1]: A B 0 1 [1, 2] 1 2 [1, 2] 如果要爆炸B这一列,可以直接用explode方法(前提是你的pandas的版本要高于或等于0.25) df.explode('B') A B 0 1 1 1 1 2 2 2 1 3
-
Python Pandas 中的数据结构详解
目录 1.Series 1.1通过列表创建Series 1.2通过字典创建Series 2.DataFrame 3.索引对象 4.查看DataFrame的常用属性 前言: Pandas有三种数据结构:Series.DataFrame和Panel.Series类似于数组:DataFrame类似于表格:Panel可视为Excel的多表单Sheet 1.Series Series是一种一维数组对象,包含一个值序列,并且包含数据标签,称为索引(index),通过索引来访问数组中的数据. 1.1通过列表创
-
Python读取word文本操作详解
本文研究的主要问题时Python读取word文本操作,分享了相关概念和实现代码,具体如下. 一,docx模块 Python可以利用python-docx模块处理word文档,处理方式是面向对象的.也就是说python-docx模块会把word文档,文档中的段落.文本.字体等都看做对象,对对象进行处理就是对word文档的内容处理. 二,相关概念 如果需要读取word文档中的文字(一般来说,程序也只需要认识word文档中的文字信息),需要先了解python-docx模块的几个概念. 1,Docume
-
对Python 数组的切片操作详解
高级特性 切片操作:对list,tuple元素进行截取操作,非常简便. L[0:3],L[:3] 截取前3个元素. L[1:3] 从1开始截取2个元素出来. L[-1] 取倒数第一个元素出来. L[-10] 取后10个数 L[10:20] 取前11-20个数 L[:10:2] 取前10个数,每两个取一个 L[::5] 所有数,每5个取一个 L[:] 原样复制一个list tuple,字符串也可以进行切片操作 以上这篇对Python 数组的切片操作详解就是小编分享给大家的全部内容了,希望能给大家一
-
python处理xml文件操作详解
目录 1.python 操作xml的方式介绍 2.ElementTree模块 3.解析xml格式字符串并获取根节点 4.读取节点内容,getroot() 5.通标标签名直接获取标签(find,findall) 6.全文搜索标签名(类似xpath路径查找标签) 7.修改节点 8.删除节点 9.构建文件 方式1 (Element) 方式2 (makeelement) 方式3 1.python 操作xml的方式介绍 查看全部包含“三种⽅法: ⼀是xml.dom. * 模块,它是W3CDOMAPI的实现
-
Python常用图像形态学操作详解
目录 腐蚀 膨胀 开运算与闭运算 开运算 闭运算 梯度运算 礼帽与黑帽 礼帽 黑帽 腐蚀 在一些图像中,会有一些异常的部分,比如这样的毛刺: 对于这样的情况,我们就可以应用复式操作了.需要注意的是,腐蚀操作只能处理二值图像,即像素矩阵的值只有0(黑色)和255(白色).我们先看看代码和效果: import cv2 import numpy as np img = cv2.imread('dagongren.png') # 腐蚀的代码 kernel = np.ones((3,3),np.uint8
-
Python入门之字符串操作详解
目录 字符串 字符串常用操作 拼接字符串 字符串复制 计算字符串的长度 截取字符串和获取单个字符 字符串包含判断 常用字符串方法 把字符串的第一个字符大写 统计字符串出现的次数 检查字符串开头 检查字符串结尾 大写转小写 小写转大写 大小写翻转 标题化字符串 空格删除 合并字符串 分割字符串 将字符串按照行分割 判断字符串只是数字 判断是空字符 字符串填充 字符串搜索 字符串替换 格式化字符串 字符串编码转换 字符串 字符串常用操作 拼接字符串 拼接字符串需要使用‘+’运算符可完成对多个字符串的
-
Python+OpenCV之形态学操作详解
目录 一. 腐蚀与膨胀 1.1 腐蚀操作 1.2 膨胀操作 二. 开运算与闭运算 2.1 开运算 2.2 闭运算 三.梯度运算 四.礼帽与黑帽 4.1 礼帽 4.2 黑帽 一. 腐蚀与膨胀 1.1 腐蚀操作 import cv2 import numpy as np img = cv2.imread('DataPreprocessing/img/dige.png') cv2.imshow("img", img) cv2.waitKey(0) cv2.destroyAllWindows(
-
Python使用Pandas库常见操作详解
本文实例讲述了Python使用Pandas库常见操作.分享给大家供大家参考,具体如下: 1.概述 Pandas 是Python的核心数据分析支持库,提供了快速.灵活.明确的数据结构,旨在简单.直观地处理关系型.标记型数据.Pandas常用于处理带行列标签的矩阵数据.与 SQL 或 Excel 表类似的表格数据,应用于金融.统计.社会科学.工程等领域里的数据整理与清洗.数据分析与建模.数据可视化与制表等工作. 数据类型:Pandas 不改变原始的输入数据,而是复制数据生成新的对象,有普通对象构成的