MySQL8.0中的窗口函数的示例代码
目录
- 1.窗口函数与聚合函数
- 2.常见的窗口函数
- 3.over子句
- 4.代码示例
- 4.1row_number\dense_rank\ rank
- 4.2cume_dist\percent_rank
- 4.3first_value\last_value\nth_value
- 4.4ntile()
- 4.5lag\lead
- 4.6聚合函数
- 4.7orderby子句
- 4.8 window子句
- 4.9 rows和range
在以前的MySQL版本中是没有窗口函数的,直到MySQL8.0才引入了窗口函数。窗口函数是对查询中的每一条记录执行一个计算,并且这个计算结果是用与该条记录相关的多条记录得到的。
1.窗口函数与聚合函数
窗口函数与聚合函数很像,他们都是在一组记录而不是整张表上执行的。但是,一个聚合函数在一组记录执行后只返回一条结果而窗口函却会对改分组内的每行记录都返回一个结果。
2.常见的窗口函数
MySQL8.0中定义的窗口函数主要有以下几种:
| 函数名 | 参数 | 描述 |
| cume_dist() | 否 | 累计分布值。即分组值小于等于当前值的行数与分组总行数的比值。取值范围为(0,1]。 |
| dense_rank() | 否 | 不间断的组内排序。使用这个函数时,可以出现1,1,2,2这种形式的分组。 |
| first_value() | 是;first_value(expr) | 返回分组内截止当前行的第一个值。 |
| lag() | 是;lag(expr,[N,[default]]) | 从当前行开始往前取第N行,如果N缺失默认为1。若没有没有,则默认返回default。default默认值为NULL |
| last_value() | 是;last_value(expr) | 返回分组内截止当前行的最后一个值。 |
| lead() | 是;lead(expr,[N,[default]]) | 从当前行开始往后取第N行。函数功能与lag()相反,其余与lag()相同。 |
| nth_value() | 是;nth_value(expr,N) | 返回分组内截止当前行的第N行。first_value\last_value\nth_value函数功能相似,只是返回分组内截止当前行的不同行号的数据。 |
| ntile() | 是;ntile(N) | 返回当前行在分组内的分桶号。在计算时要先将改分组内的所有数据划分成N个桶,之后返回每个记录所在的分桶号。返回范围从1到N |
| percent_rank() | 否 | 累计百分比。该函数的计算结果为:小于该条记录值的所有记录的行数/该分组的总行数-1. 所以改记录的返回值为[0,1] |
| rank() | 否 | 间断的组内排序。其排序结果可能出现如下结果:1,1,3,4,4,6 |
| row_number() | 否 | 当前行在其分组内的序号。不管其排序结果中是否出现重复值,其排序结果都为:1,2,3,4,5 |
注:‘参数’列说明该函数是否可以加参数。“否”说明该函数的括号内不可以加参数。expr即可以代表字段,也可以代表在字段上的计算,比如sum(col)等。以下相同。
3. over子句
over子句可以指定如何将记录划分分区以供窗口函数处理。如果over()为空,则是将整个查询记录作为一个分组。如果over子句不为空,则其可以指定查询记录划分分组的方式以及记录在分组内部的排序方式。除此之外,over子句也可以和聚合函数一起用。如果聚合函数后出现over子句,那么这些聚合函数也就变成了窗口函数。如果没有over子句,则他们仍然是聚合函数。可以使用over子句的聚合函数主要有以下几种:
avg()、bit_and()、bit_or()、bit_xor()、count()、max()、min()、stddev_pop()、stddev()、std()、stddev_samp()、sum()、var_pop()、variance()、var_samp()
而对于前一部分中介绍的窗口函数来说,over()子句是强制必须要有的。
over子句中常见的语法形式为:
over_clause:
{OVER (window_spec) | OVER window_name}
其中:
window_spec:
[window_name] [partition_clause] [order_clause] [frame_clause]
window_name: 是指在查询语句定义的window子句。如果遇到group by、having子句order by子句,那么window子句要放到having子句和order by子句中间。其语法如下:
WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...
而
window_spec:
[window_name] [partition_clause] [order_clause] [frame_clause]
从语法结构可以看出来window子句其实只是把放在over()括号中的内容单独抽出来。
partition_clause:即parittion by expr子句。用来指定记录分组方式。语法中的expr不仅可以是字段本身,也可以是计算表达式。比如,记录中有个timestramp类型的字段 ts,在MySQL中,partition by ts 和partition by hour(ts)都是有效的。
order_clause: 即 order by expr desc|asc,expr desc|asc。 用来指定分组内的排序方式。
frame_clause: 用来指定当前分组中的子集划分方式。frame可以在依据当前行的位置在每个分组内移动。使用frame来计算流水流水总和(从分区开始到当前行)及滚动平均(rolling averages)。
其语法结构如下:
frame_clause:
frame_units frame_extent
frame_units:
{ROWS | RANGE}
frame_extent:
{frame_start | frame_between}
frame_between:
BETWEEN frame_start AND frame_end
frame_start, frame_end:
{ CURRENT ROW
| UNBOUNDED PRECEDING
| UNBOUNDED FOLLOWING
|expr PRECEDING
| expr FOLLOWING
}
其中:
frame_units用来指示当前行和frame的关系
ROWS: 用来定义frame的开始行和结束行(偏移量依据的是位置);RANGE: 定义frame的区间。(偏移量的基准为当前行的值)
frame_entent用来指示frame的开始行和结束行。一种是通过指定start和end(frame_start,frame_end。frame_end可以不指定,没有明确给出的话当前行默认为结束行),另一种使用between(frame_between)。frame_between的语法很简单。下面来看frame_start和frame_end。
current row:和rows一起用时,边界就是当前行。和range一起用时,边界是当前行的对等点(个人理解,这里所说的对等点应为与当前行的值相等的所有记录)。
unbounded precceding:使用它时,每个分区的第一行即为边界。
unbounded following:使用它时,每个分区的第一行即为边界。
expr preceding\expr following: 可以由expr个性化的设置向上(preceding)向下(following)的偏移量。
4.代码示例
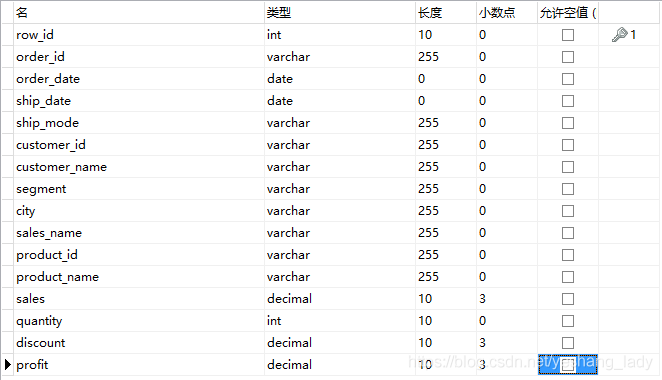
表结构如下:
4.1 row_number\dense_rank\ rank
select order_date,sum(quantity) as quantity, rank()over(ORDER BY sum(quantity) desc) as rank_result, dense_rank()over(ORDER BY sum(quantity) desc) as dense_result, row_number()over(ORDER BY sum(quantity) desc) as row_result from spm_order group by order_date -- 限定一部分数据,没有实际意义,能展示出这三个函数的区别就可以了 having quantity>=98 order by quantity desc
运行结果如下:
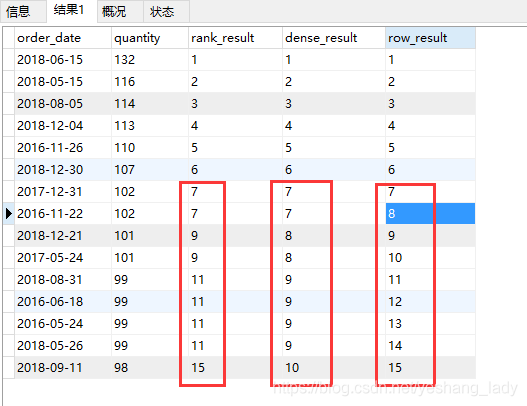
从上面结果看出:
- rank()函数一旦遇到重复值,序号会断。比如2个7之后下个出现的序号是9。
- dense_rank()函数中即使有重复值,但是序号是连续的。2个7之后下个出现的序号是8。
- row_number()不会出现相同的序号。
4.2 cume_dist\percent_rank
select order_date,num, cume_dist()over(order by num asc) as cume_result, percent_rank()over(order by num asc) as percent_result from (select order_date,count(1) as num from spm_order group by order_date having num>=27)a order by num asc
代码运行结果如下
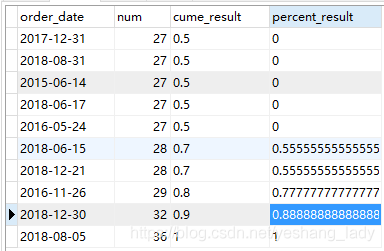
分析如下:
- cume_dist():首先总的记录有10条。当num=27时,num小于等于27的值共有5个,所以其cume_dist()值为0.5;当num=28时,小于等于28的值共有7个,所以cume_dist()值为0.7; 以此类推。
- percent_rank().当num=27时,num小于27的记录数为0,所以percent_rank()为0;当num=28时,num<28的记录数共有5个,所以percent_rank()的值为5/9; 而当num=29时,其cume_dist()=7/9;以此类推,直到最大值36对应的值为1.
- 这两个函数的作用有点像计算中位数。
4.3 first_value\last_value\nth_value
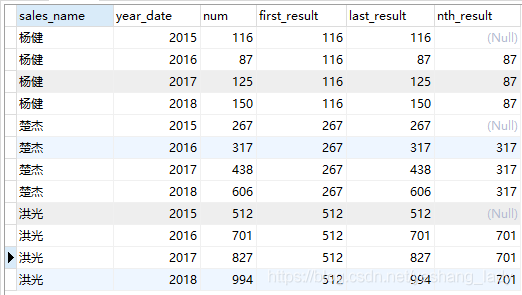
select sales_name,year_date,num,
first_value(num)over(PARTITION by sales_name order by year_date asc) as first_result,
last_value(num)over(PARTITION by sales_name order by year_date asc) as last_result,
nth_value(num,2)over(PARTITION by sales_name order by year_date asc) as nth_result
from (select sales_name,year(order_date)as year_date,count(1) as num
from spm_order
where sales_name in ('杨健','楚杰','洪光')
group by year(order_date),sales_name
order by sales_name asc,year_date asc)a
代码运行结果如下(要注意,这三个函数计算结果都是截止当前行)
4.4 ntile()
select sales_name,year_date,num,
ntile(8)over(order by num asc) as n_bin
from (select sales_name,year(order_date)as year_date,count(1) as num
from spm_order
where sales_name in ('杨健','楚杰','洪光')
group by year(order_date),sales_name
order by sales_name asc,year_date asc)a
代码运行结果如下:
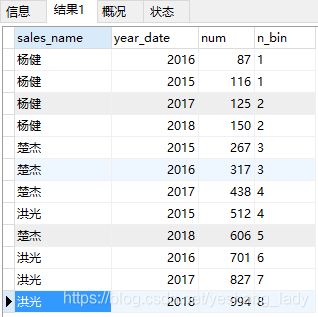
从结果上进行分析:
- 首先,分桶号从1到N,都会出现;
- 其次,关于每个桶应该有多少条记录。可以假设有N个桶,m个球(球数为总记录数),标号从1到N,依次往1号桶到N号桶里投球,每次只投1个球。循环往复,直到m个球全都投入到N个桶中。最后每个桶里有多少球,现在每个桶里就有多少条记录。
4.5 lag\lead
select sales_name,year_date,num,
lag(num,2)over(PARTITION by sales_name order by year_date asc) as lag_result,
lead(num,2)over(PARTITION BY sales_name order by year_date asc) as lead_result
from (select sales_name,year(order_date)as year_date,count(1) as num
from spm_order
where sales_name in ('杨健','楚杰','洪光')
group by year(order_date),sales_name
order by sales_name asc,year_date asc)a
代码运行结果如下:
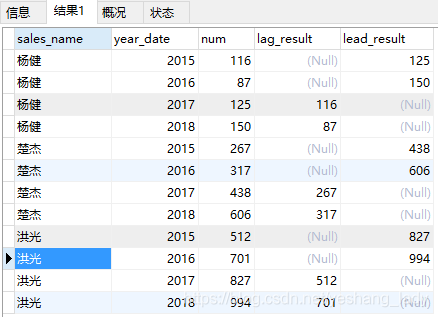
注意,lag()和lead()函数中出现的字段可以与over()子句中order by中出现的字段不一致。在代码lag(num,2)中2代表的想要取数的那一行相比当前行的偏移量(lead中也类似)。
4.6 聚合函数
select sales_name,year_date,num,
sum(num)over(PARTITION by sales_name) as sum_order,
avg(num)over(PARTITION by sales_name) as mean_order
from (select sales_name,year(order_date)as year_date,count(1) as num
from spm_order
where sales_name in ('杨健','楚杰','洪光')
group by year(order_date),sales_name
order by sales_name asc,year_date asc)a
代码运行结果如下:

4.7 order by子句
select sales_name,year_date,num,
sum(num)over(partition by sales_name) as count_1,
count(num)over(partition by sales_name order by num) as count_2
from (select sales_name,year(order_date)as year_date,count(1) as num
from spm_order
where sales_name in ('杨健','楚杰','洪光')
group by year(order_date),sales_name
order by sales_name asc,year_date asc)a
代码运行结果如下:

当frame_clause不存在的时候,默认的frame与order by子句是否存在有关:
- 如果有order by子句,则默认的frame是从当前分区第一行到当前行。即在此种情况下,默认的frame为 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
- 如果没有order by子句,则默认的frame是指该分区。如果此时也没有partition by子句,则相当于全部数据。
4.8 window子句
select sales_name,year(order_date) as year_1,count(1) as num,
sum(count(1)) over w as sales_order,
sum(count(1)) over (w_1) as year_order,
rank()over(w order by count(1) desc) as rank_order
-- 三种写法都是符合语法规范的
from spm_order
where sales_name in ('杨健','楚杰','洪光')
group by sales_name,year(order_date)
window w as (PARTITION by sales_name),
w_1 as (PARTITION by year(order_date))
order by sales_order
代码运行结果如下:
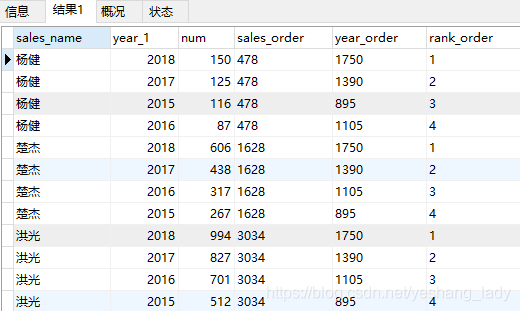
4.9 rows和range
rows和range是不能单独使用的,但是因为实在不理解这两个用法上的区别,所以就进行了单独的验证。
select sales_name,month_1,rn_1,num,
sum(num)over(order by month_1 rows between 2 preceding and 1 preceding) as month_row,
sum(num)over(order by month_1 range between 2 preceding and 1 preceding) as month_range,
sum(num)over(order by rn_1 range between 2 preceding and 1 preceding) as rn_range
from (SELECT sales_name,month(order_date) as month_1,count(1) as num,
-- 由于rank()over()返回的是unsigned,当相减结果为负时(between子句会用到减法)会报错,所以这里转成signed类型
cast(rank()over(order by month(order_date)) as signed) as rn_1
from spm_order
where sales_name in ('洪光','范彩')
group by sales_name,month(order_date))a
order by month_1 asc
代码运行结果如下:
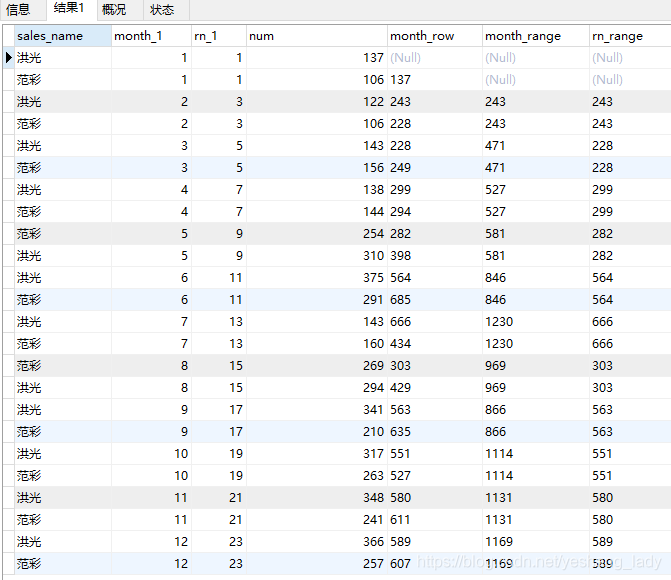
对以上代码分析:
首先,在这里我新建了一个rn_1列。rn_1列和month_1的区别在于,month_1的数据是连续的,而rn_1列是有中断的(两个1之后出现的是3,我是故意要创建一个中断的序列,来分析一下range的作用范围)
先来看month_row的区别,month_row列的计算结果为当前行在分区中按month_1升序排序之后排在其前面的两行(between and限定的)的sum求和值。所以rows后面的between and限定的偏移量是基于他们在分区中的排列位置的。
再来看month_range,通过分析其实验结果可以发现,month_range列的计算为分区内month_1=当前行-1和month_1=当前行-2(-1,-2是由between an子句决定的。preceding代表负,following代表正)所有列的sum求和值。再来看rn_range, rn_range列的计算结果为分区内month_1=当前行-2的所有里列的sum求和值。所以,rang后面的between and限定的偏移量依据的是当前行的数值。
到此这篇关于MySQL8.0中的窗口函数的示例代码的文章就介绍到这了,更多相关MySQL8.0 窗口函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Mysql8.0使用窗口函数解决排序问题
MySQL窗口函数简介 MySQL从8.0开始支持窗口函数,这个功能在大多商业数据库和部分开源数据库中早已支持,有的也叫分析函数. 什么叫窗口? 窗口的概念非常重要,它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数.对于每条记录都要在此窗口内执行函数,有的函数随着记录不同,窗口大小都是固定的,这种属于静态窗口:有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口. 窗口函数和普通聚合函数也很容易混淆,二者区别如下: 聚合函数是将多条记录聚合为一条:
-
MySQL8.0窗口函数入门实践及总结
前言 MySQL8.0之前,做数据排名统计等相当痛苦,因为没有像Oracle.SQL SERVER .PostgreSQL等其他数据库那样的窗口函数.但随着MySQL8.0中新增了窗口函数之后,针对这类统计就再也不是事了,本文就以常用的排序实例介绍MySQL的窗口函数. 1.准备工作 创建表及测试数据 mysql> use testdb; Database changed /* 创建表 */ mysql> create table tb_score(id int primary key aut
-

MySQL8.0中的窗口函数的示例代码
目录 1.窗口函数与聚合函数 2.常见的窗口函数 3.over子句 4.代码示例 4.1row_number\dense_rank\ rank 4.2cume_dist\percent_rank 4.3first_value\last_value\nth_value 4.4ntile() 4.5lag\lead 4.6聚合函数 4.7orderby子句 4.8 window子句 4.9 rows和range 在以前的MySQL版本中是没有窗口函数的,直到MySQL8.0才引入了窗口函数.窗口函数
-
SQL实现筛选出连续3天登录用户与窗口函数的示例代码
目录 还原试题 SQL窗口函数 一.窗口函数有什么用 二.什么是窗口函数 三.如何使用 1.专用窗口函数rank 2.其他专业窗口函数 3.聚合函数作为窗口函数 4.注意事项 四.总结 1.窗口函数语法 2.窗口函数有以下功能: 3.注意事项 解题思路 代码实现 其他解法与延展 还原试题 首先新建一张表来还原一下试题: CREATE TABLE last_3_day_test_table ( user_id varchar(300), login_date date ); INSERT INTO
-
JavaScript中removeChild 方法开发示例代码
1. 概述 删除后的节点虽然不在文档树中了,但其实它还在内存中,可以随时再次被添加到别的位置. 当你遍历一个父节点的子节点并进行删除操作时,要注意,children属性是一个只读属性,并且它在子节点变化时会实时更新 // 拿到待删除节点: var self = document.getElementById('to-be-removed'); // 拿到父节点: var parent = self.parentElement; // 删除: var removed = parent.remove
-
如何在vue中使用ts的示例代码
本文介绍了如何在vue中使用ts的示例代码,分享给大家,具体如下: 注意:此文并不是把vue改为全部替换为ts,而是可以在原来的项目中植入ts文件,目前只是实践阶段,向ts转化过程中的过渡. ts有什么用? 类型检查.直接编译到原生js.引入新的语法糖 为什么用ts? TypeScript的设计目的应该是解决JavaScript的"痛点":弱类型和没有命名空间,导致很难模块化,不适合开发大型程序.另外它还提供了一些语法糖来帮助大家更方便地实践面向对象的编程. typescript不仅可
-
vue 2.0 购物车小球抛物线的示例代码
本文介绍了vue 2.0 购物车小球抛物线的示例代码,分享给大家,具体如下: 备注:此项目模仿 饿了吗.我用的是最新的Vue, 视频上的一些写法已经被废弃了. 布局代码 <div class="ball-container"> <transition name="drop" v-for="ball in balls" @before-enter="beforeDrop" @enter="droppi
-
Java 添加、替换、删除PDF中的图片的示例代码
概述 本文介绍通过java程序向PDF文档添加图片,以及替换和删除PDF中已有的图片.另外,关于图片的操作还可参考设置PDF 图片背景.设置PDF图片水印.读取PDF中的图片.将PDF保存为图片等文章. 工具:Free Spire.PDF for Java (免费版) Jar获取及导入:官网下载,并解压将lib文件夹下的jar文件导入java程序,或者通过maven仓库下载并导入. jar导入效果: Java代码示例 [示例1]添加图片到PDF import com.spire.pdf.*; i
-
在Java中操作Zookeeper的示例代码详解
依赖 <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.6.0</version> </dependency> 连接到zkServer //连接字符串,zkServer的ip.port,如果是集群逗号分隔 String connectStr = "192.
-
在Vue中使用antv的示例代码
一,在vue原型中使用 1.首先安装antv/g2 yarn add @antv/g2 --save 2.在main.js中挂在到vue原型实例中 const G2 = require('@antv/g2') Vue.prototype.$G2 = G2 3.在vue文件中可以直接在mounted生命周期中直接使用 <template> <div> <div id="c1"></div> </div> </templat
-
SpringBoot中实现数据字典的示例代码
我们在日常的项目开发中,对于数据字典肯定不模糊,它帮助了我们更加方便快捷地进行开发,下面一起来看看在 SpringBoot 中如何实现数据字典功能的 一.简介 1.定义 数据字典是指对数据的数据项.数据结构.数据流.数据存储.处理逻辑等进行定义和描述,其目的是对数据流程图中的各个元素做出详细的说明,使用数据字典为简单的建模项目.简而言之,数据字典是描述数据的信息集合,是对系统中使用的所有数据元素的定义的集合. 数据字典(Data dictionary)是一种用户可以访问的记录数据库和应用程序元数
-
在Java中使用Jwt的示例代码
JWT 特点 JWT 默认是不加密,但也是可以加密的.生成原始 Token 以后,可以用密钥再加密一次. JWT 不加密的情况下,不能将秘密数据写入 JWT. JWT 不仅可以用于认证,也可以用于交换信息.有效使用 JWT,可以降低服务器查询数据库的次数. JWT 的最大缺点是,由于服务器不保存 session 状态,因此无法在使用过程中废止某个 token,或者更改 token 的权限.也就是说,一旦 JWT 签发了,在到期之前就会始终有效,除非服务器部署额外的逻辑. JWT 本身包含了认证信