正则表达式用法详解
正则表达式之基本概念
在我们写页面时,往往需要对表单的数据比如账号、身份证号等进行验证,而最有效的、用的最多的便是使用正则表达式来验证。那什么是正则表达式呢?
正则表达式(Regular Expression)是用于描述一组字符串特征的模式,用来匹配特定的字符串。 它的应用非常广泛,特别是在字符串处理方面。其常见的应用如下:
- 验证字符串,即验证给定的字符串或子字符串是否符合指定的特征,例如,验证是否是合法的邮件地址、验证是否是合法的HTTP地址等等。
- 查找字符串,从给定的文本当中查找符合指定特征的字符串,这样比查找固定字符串更加灵活。
- 替换字符串,即查找到符合某特征的字符串之后将之替换。
- 提取字符串,即从给定的字符串中提取符合指定特征的子字符串。
第一部分:正则表达式之工具
正所谓工欲善其事必先利其器! 所以我们需要知道下面几个主要的工具:
http://www.regexpal.com/ 这个网站中,我们可以在线测试正则表达式。
http://regexr.com/ 这个网站更为推荐,它自身还包括了一个实例使我们直接测试。
第二部分:正则表达式之元字符
正则表达式中元字符恐怕是我们听得最多的了。元字符(Metacharacter)是一类非常特殊的字符,它能够匹配一个位置或者字符集合中的一个字符。 如.、\w等都是元字符。
刚刚说到,元字符既可以匹配位置,也可以匹配字符,那么我们就可以通过此来将元字符分为匹配位置的元字符和匹配字符的元字符。
A匹配位置的元字符---^、$、\b
即匹配位置的元字符只有^(脱字符号)、$(美元符号)和\b这三个字符。分别匹配行的开始、行的结尾以及单词的开始或结尾。它们匹配的都只是位置。
1.^匹配行的开始位置
如^zzw匹配的是以"zzw"为行开头的"zzw"(注意:我这里想要表达的是:尽管加了一个^,它匹配的仍是字符串,而不是一整行!),如果zzw不是作为行开头的字符串,则它不会被匹配。
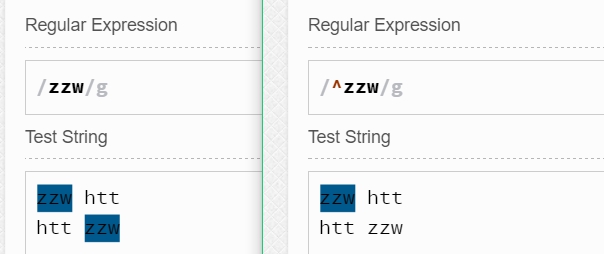
2.$匹配行的结尾位置
如zzw$匹配的是以"zzw"为行结尾的"zzw"(同样,这里$只是匹配的一个位置,那个位置是零宽度,而不是一整行),如果zzw不是作为行的结尾,那么它不会被匹配。

于是结合^和$我们就不难猜测^zzw$匹配的是某行中只有zzw这个字符串了。

而^$匹配的则是一个空行,这个空行中不包含任何字符串。
3. \b匹配单词的开始或结束
如 \bzzw匹配的是zzw之前是空格符号、标点符号或换行符号的zzw(注意:但\b匹配的仅是一个零宽度的位置,而不会匹配空格、标点符号或换行符号)。
而zzw\b匹配的是zzw之后是空格符号、标点符号或换行符号的zzw(同样,\b匹配的是一个零宽度的位置)。
显然 \bzzw\b匹配的就是zzw的前后必须是空格符号、标点符号或换行符号的zzw。

B 匹配字符的元字符---. 、\w、\W、\s、\S、\d、\D
即匹配字符的元字符共有七个。
其中.(点号)表示匹配除换行符之外的任意字符;
- \w 匹配单词字符(不仅仅是字母,还有下划线、数字和汉字);\W匹配任意的非单词字符(注意,与\w刚好相反);
- \s匹配的是任意的空白字符(如空格、制表符、换行符、中文全角空格等);
- \S匹配的是任意的非空白字符(注意:刚好和\s相反);
- \d匹配任意的数字;
- \D匹配任意的非数字字符(注意:刚好和\d相反)。
例子如下所示:
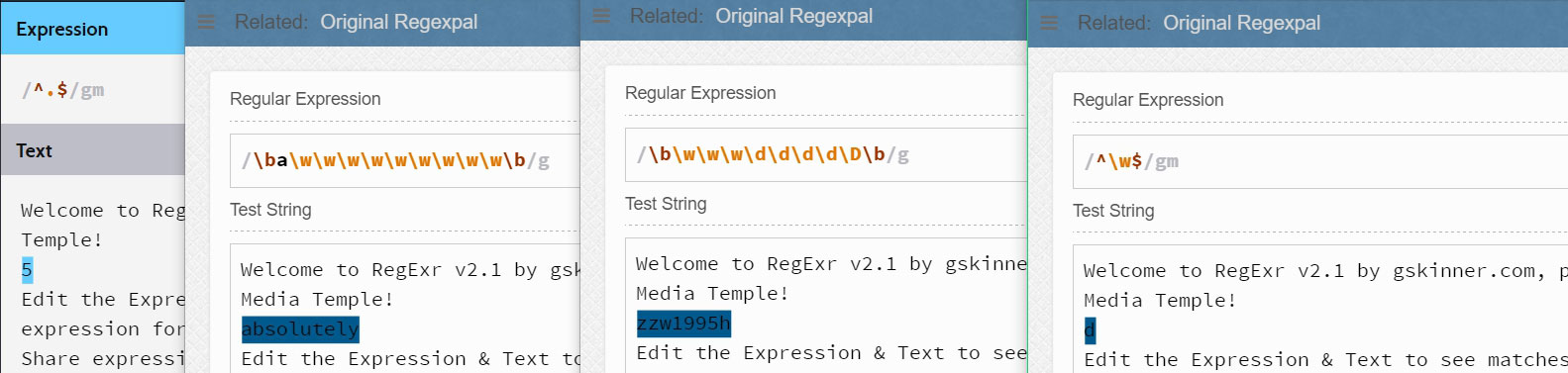
上面的四个例子从左到右依次表示:
- ^.$表示匹配一行中的唯一一个任意的非换行符的字符
- \ba\w\w\w\w\w\w\w\w\w\b表示匹配以字母a开始的后面有9个字母字符的单词。 (注意:其中的a并不是元字符,就是一个普通的字符,我们称之为字符串字面值(string literal)-所谓字符串字面值,就是字面上看起来是什么就是什么)
- \b\w\w\w\d\d\d\d\D\b表示匹配以3个字母字符开始后面紧跟着四个数字字符且最后一个不是数字字符的单词。
第三部分:正则表达式之文字匹配
这一部分我们将通过字符类、字符转义、反义这几个部分来学习。
A、字符类
字符类是正则表达式中的“迷你”语言,可以在[]中定义。
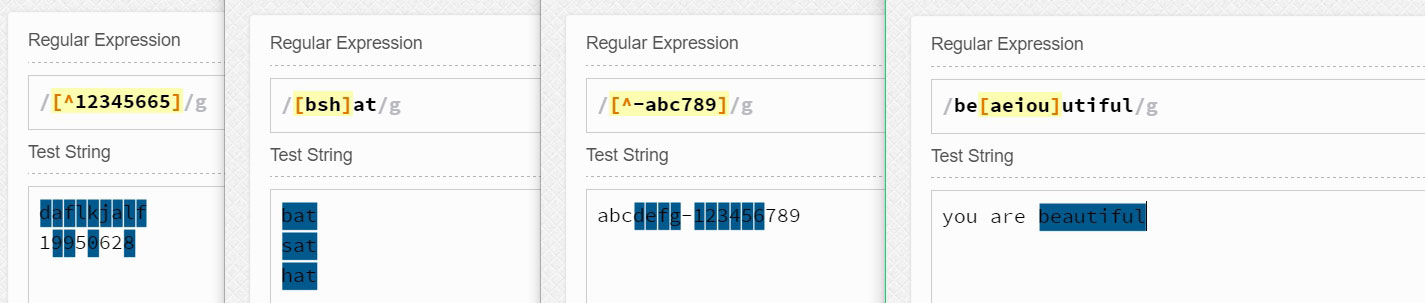
最简单的字符类可以由[]和几个简单的字母组成。比如[aeiou]可以匹配aeiou五个字母中的任意一个。[0123456]可以匹配0123456这七个数字中的任意一个。而<H[123456]>可以匹配到HTML标记中的<H1><H2><H3><H4><H5><H6>中的任意一个标记。而[bhc]at就会匹配字符串bat、hat、cat。也就是说字符类[]中的多个字符只会匹配其中一个。
但是显然[0123456]、<H[123456]>这样的表示太麻烦,需要写的很多,所以我们可以使用 -连字符)来简写之,如[0-6]和<H[1-6]>。于是可知[0-9]和\d的作用是一样的。[a-z]可以表示所有的小写字母,[A-Z]可以表示所有的大写字母。[a-zA-Z]可以表示所有的大写字母和小写字母。
值得注意的是 -(连字符) 只有在字符类中的中间位置时才是“到”的意思。而[-b]5中-没有在两个字符之间,所以它表示的是-5或者b5。
除此之外,我们知道^时只匹配行的开头,但是如果^出现在字符类中的第一个位置,那么它表示否定该字符类。如[^123]表示匹配不是数字1或2或3的其他任意字符。[^-]表示匹配不是-的任意字符。
由此我们也可以发现:在字符类中使用元字符(-、^等)时,不需要进行转义运算。
更常用的有[^aeiou]匹配元音之外的字符、[0-9a-zA-Z_]匹配任何数字、字母(大写和小写)和下划线,这等同于\w、[^0-9a-zA-Z_]匹配任何非数字、字母(大写和小写)和下划线,这等同于\W。
B、字符转义
我们知道元字符如&、^、.等都表示着特殊的涵义,如果我们希望把他们看作一般的字符去匹配字符串,并且恰好他们又都不在字符类(如[&]中),我们就需要使用\(反斜杠)进行转义了。
如我们可以使用www.jb51.net来匹配www.jb51.net。 我们可以用\*来匹配字符串中的*(通配符)。 我们还可以通过\\来匹配\。举例如下所示:

C.反义
实际上我们在前面已经说过了,这里再说一遍是因为希望可以引起注意,即^再字符类中的最前面时表示对这个字符类中的字符表示否定。如a[^b]匹配a和a后面不是b的字符。又如<asp[^>]>表示匹配<asp和其后面的字符不是>的字符。举例如下:

第四部分:正则表达式之限定符
什么是限定符呢? 我们知道,在前面的例子中,我曾经使用过\ba\w\w\w\w\w\w\w\w\w\b表示匹配以字母a开始的后面有9个字母字符的单词,显然这样写是十分麻烦的,如果我们能把\w这些重复的用简单的形式来写就好了~ 没错,限定符就是干这个的,利用限定符我们可以重新写成\ba\w{9}\b。对,就是这么简单! 下面让我们了解更多吧。
- {n} 表示重复n次,如\w{5}表示匹配个单词字符。
- {n,} 表示重复至少n次,如\w{5}表示匹配至少5个单词字符,也可以是6个,7个……
- {n,m} 表示重复至少n次,最多m次,如\w{5,10} 表示匹配至少5个,最多10个单词字符。
- * 表示重复至少0次。 等同于{0,} ,即hu*t可以匹配ht或hut或huut或huuut……
- + 表示重复至少1次。 等同于{1,},即hu+t可以匹配 hut或huut或huuut……
- ? 表示重复0次或1次。等同于{0,1},即colou?r表示匹配color或者是colour。
显然,上面的限定符所指的i安定都是限定的前面的某一个字符。
但是,如果我们在上面的限定符之后加上一个?呢 ,这时我们称之为懒惰限定符。 相应地,我们称上面几种匹配为贪婪匹配。
- {n}? 等同于{n}
- {n,}? 尽可能少的使用重复,但至少使用n次
- {n,m}? 重复n次到m次之间,但要尽可能少的使用重复。
- *? 尽可能少的使用重复的第一个匹配
- +? 尽可能少的使用重复,但至少使用1次
- ?? 使用零次重复(如果有可能)或者一次重复
比如:对于aabab这个要 匹配的字符串而言,使用a.*b会匹配aabab,而如果使用a.*?b就会匹配aab和ab,而不是匹配所有。

第五部分:正则表达式之字符的运算
字符的运算包括替换、分组和反向引用,下面我将逐项介绍。
A 替换
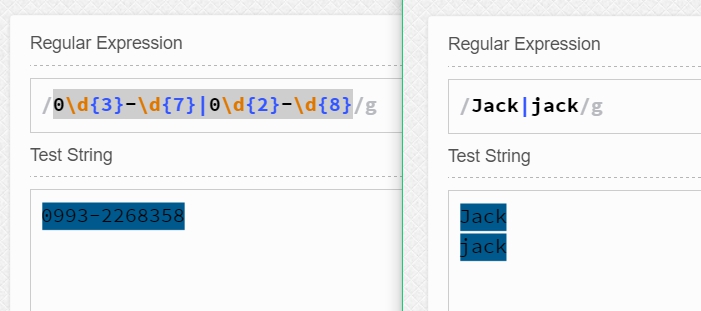
什么是替换呢? 显然就是指一个不行,我用另一个来替换,比如0\d{3}-\d{7}|0\d{2}-\d{8} 就表示匹配前4位为区号、后7位为本地号码的电话号码,亦可匹配前3位为区号、后8位为本地号码的电话号码。| 表示的就是替换了。 又如[Jj]ack和Jack|jack的匹配效果是一样的都是用来匹配Jack或jack的。也就是说,替换|是或运算的关系。
在一般的或运算中0 0结果为0, 0 1结果为1, 1 0结果为1, 1 1结果为1。那么在正则表达式中同样是这样,如果一个都匹配不上就不匹配;如果有一个能匹配上就匹配一个;如果两个都能匹配上,就匹配两个。 举例如下所示:
B.分组
正则表达式中,分组也是一个非常重要的概念。看似复杂,实际上分组就是使用"("和")",即左圆括号和右圆括号将某些字符括起来看成一个整体来处理。
比如我们希望匹配abcabc。如果是abc{3}匹配的就是abccc,这不能达到预期,所以我们可以对abc分组,即(abc){3}就可以匹配到我们想要的字符串了。
又如(\d{1,3}\.){3}\d{1,3}也用了分组的运算方式,它可以用来匹配简单的IP地址,如下所示:

C 反向引用
上面我们通过()可以进行分组,而分组的同时,每一个组被自动赋予了一个组号,该组号可以代表该组的表达式。
编组的规则是:从左到右、以分组的左括号"("为标志,第一个分组的组号为1,第二个分组的组号为2,以此类推。
这时,反向引用就派上用场啦。我们就可以用它来反向引用使用()括起来的字符组了。具体怎么引用呢?规则如下:
- \数字,使用数字命名的反向引用。注:这个是通用的一种方式。
- \k<name>,使用指定命名的反向引用。注:这个是.NET Frameword支持的一种方式。
下面的几个例子是使用数字命名的反向引用:

其中我们可以看到第一个和第二个匹配的并不相同---第一个匹配的是两个任意单词字符组成的单词,而第二个由于是使用了反向引用,那么它就必须是两个重复单词字符组成的单词。
最后一个我使用了两个分组,根据分组规则可知\w{3}\d{2}是第一个分组,\d{2}是第二个分组。 同样注意:反向引用的是同样的字符,如www55www5566,最后两位不同,这就无法正确匹配了。
使用指定命名(也就是自定义命名)的反向引用
对于上面的第二个例子,我们用自定义命名的反向引用可以写成\b(?<myName>\w)\k<myName>\b或者是\b(? 'myName' \w)\k<myName>\b。 本想举例试一下,结果都提示错误,可能是上面提到的两个在线网站不支持吧~
当然,如果我们希望只是将之看作一个整体,而不希望给其编号,可以使用(?:expression)的方式。如下所示:

另外,下面几个也是常用的分组:
- (?=expression)匹配字符串expression前面的位置
- (?!expression)匹配后面不是字符串expression的位置
- (?<=expression)匹配字符串expresssion后面的位置
- (?<!expression)匹配前面不是字符串expression的位置
- (?>expression)只匹配字符串expression一次
D.零宽度断言
之前介绍的^和$都是匹配的一个满足一定条件的位置。这里把满足的一个条件成为断言或零宽度断言。
常用的有:
- ^ 匹配行的开始位置
- $ 匹配行的结束位置
- \A 匹配必须出现在字符串的开头
- \Z 匹配必须出现在字符串的结尾或字符串结尾处的\换行符好n之前
- \z 匹配必须出现在字符串的结尾
- \G 匹配必须出现在上一个匹配结束的地方
- \b 匹配字符的开始或结束位置
- \B 匹配不是在字符的开始或结束位置
之前所提到的(?=expression)、(?!expression)、(?<=expression)、(?<!expression)也都是匹配一个位置。
其中(?=expression)称为零宽度预测先行断言,它断言自身位置的后面能够匹配表达式expression。如\b\w+(?=ed\b)可以匹配以字符串ed结尾的单词的前面部分,如reseted中的reset。
其中(?<=expression)又称为零宽度正回顾后发断言,它断言自身位置的前面能够匹配表达式expression。如(?<=\ban)\w+\b可以匹配除字符串an之外的部分。

E 负向零宽度断言
(?!expression)称为负向零宽度断言,即断言自身位置的后面不能匹配字符串expression。
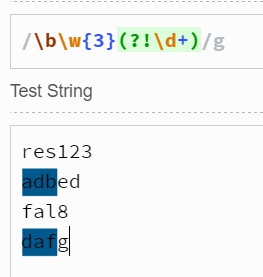
如\b\w{3}(?!\d)匹配的是后面不是数字的以三个单词字符开头的三个单词字符。如下所示:
F 优先级顺序
正则表达式中存在元字符、转义符、限定符、|等运算或表达式。在匹配过程中,正则表达式都事先规定了这些运算或表达式的优先级。正则表达式也可以像数学表达式一样来求值。也就是说,正则表达式可以从左到右、并按照一个给定的优先级来求值。
优先级顺序表(优先级由高到低)如下:
- 转义符:\
- 圆括号和方括号:()、(?:)、(?=)、[]
- 限定符: *、+、?、{n}、{n,}、{n,m}
- 位置和顺序:^、$、\(元字符)
- 或运算:|
我们可以看到或运算的优先级是最低的。
第六部分:典型正则表达式解释
A 匹配windows运算系统的名称
我们可以通过下面的正则表达式来精确匹配windows运算系统的名称
windows\s*((95)|(98)|(2000)|(2003)|(ME)|(XP)|(7)|(8)|(10))
这样就可以精准匹配windows的各种版本的运算系统了,显然这个是非常冗长的,我们还可以用一种不精准的方式匹配,如下所示:
windows\s*\w+
其中s*表示至少重复0次。即windows10(无空格), windows 10(一个空格), windows 10(两个空格)等都可以正确匹配。
B 匹配HTML标记
HTML标记一般由尖括号包围,如<a>、<table>、<input>等等。所以我们可以使用下面的正则表达式来匹配HTML标记。
<[a-zA-Z][^>]*>

到此这篇关于正则表达式用法详解的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

36个正则表达式(开发效率提高80%)
目录 写在前面 1.整数 2.正整数 3.负整数 4.数字 5.正数(正整数 + 0) 6.负数(负整数 + 0) 7.浮点数 8.正浮点数 9.负浮点数 10.浮点数 11.非负浮点数(正浮点数 + 0) 12.非正浮点数(负浮点数 + 0) 13.邮箱地址 14.颜色值匹配 15.url匹配 16.纯仅中文字符 17.仅ACSII字符 18.邮政编码 19.国内手机号码 20.IP V4 地址 21.非空字符 22.图片后缀 23.音频后缀 24.视频后缀 25.压缩文件后缀 26.日期格式
-
十分钟上手正则表达式 下篇
目录 一.正则表达式常用符号 1.1 问号[?] 1.2 加号[+] 1.3 花括号{} 1.4 管道符号[|] 1.5 小括号() 二.正则表达式实战示例 示例1: 示例2: 前面,我们就正则表达式一些常用的基本方法做了详细的介绍,本篇会讲解一些拓展性的知识,主要的就是常见的ERE模式符号以及shell脚本中常见的一些正则表达式例子. 快速学习正则表达式,不用死记硬背,示例让你通透(上篇) 一.正则表达式常用符号 本章示例着重于在gawk程序脚本中的较常见的ERE模式符号. 1.1 问号[?]
-
十分钟上手正则表达式 上篇
目录 一.正则表达式的定义: 二.正则表达式的类型 三.定义 BRE 模式 3.1 纯文本 3.2 特殊字符 3.3 锚字符 3.3.1 锁定在行首 3.3.2 锁定在行尾 3.3.3 组合锚点 3.4 点号字符 3.5 字符组 3.6 排除型字符组 3.7 区间 3.8 特殊的字符组 3.9 星号[*] 一.正则表达式的定义: 正则表达式是你所定义的 模式模板 ( pattern template ), Linux 工具可以用它来过滤文本. Linux工具(比如sed 编辑器或 gawk 程序
-
正则表达式那些让人头晕的元字符
目录 0.写在前面 1.特殊单字符 2.空白符 3.范围 4.量词 5.实战 1.如何表达一个两位数字的范围 2.如何表达一个三位数字的范围 3.组合 6.写在最后 0.写在前面 在开发中,正则表达式常用于邮箱.手机号的校验,文本的批量查找.替换等操作. 大部分同学,在拿到需求的时候,第一件事一定是打开浏览器,搜索:邮箱 正则表达式 怎么写,然后Ctrl C + V,测试几个条件没问题,就提交了,出了问题也不知道怎么修改,只能再求救热心网友. 本篇文章,主要带大家了解一下,正则表达式的基本用法,
-
正则表达式用法详解
正则表达式之基本概念 在我们写页面时,往往需要对表单的数据比如账号.身份证号等进行验证,而最有效的.用的最多的便是使用正则表达式来验证.那什么是正则表达式呢? 正则表达式(Regular Expression)是用于描述一组字符串特征的模式,用来匹配特定的字符串. 它的应用非常广泛,特别是在字符串处理方面.其常见的应用如下: 验证字符串,即验证给定的字符串或子字符串是否符合指定的特征,例如,验证是否是合法的邮件地址.验证是否是合法的HTTP地址等等. 查找字符串,从给定的文本当中查找符合指定特征
-
JScript中正则表达式用法详解
呵呵,先罗嗦几句,去年用C#做了一个语法高亮的小东西,根据配制文件中的信息把所给代码格式化成HTML,使它能在网页上显示出和编辑器里一样的语法元素高亮的效果以及支持代码折叠.没错,就是和博客园上看到的类似啦.因为我当时使用的是MSN Space,它没有提供这项功能,只好自己写一个咯. 我使用的是C#进行编写,起初使用的是超级繁琐的for,while,switch,if等基本语句来判断关键字等等,大家莫笑话,本人愚笨当时还不知道正则表达式是何物,所以只能用这种土办法了,当然土办法还是有效果的,只是
-
JS中正则表达式全局匹配模式 /g用法详解
本文章来详细介绍js中正则表达式的全局匹配模式 /g用法,代码如下: var str = "123#abc"; var re = /abc/ig; console.log(re.test(str)); //输出ture console.log(re.test(str)); //输出false console.log(re.test(str)); //输出ture console.log(re.test(str)); //输出false 在创建正则表达式对象时如果使用了"g&q
-
正则表达式grep用法详解
语法:grep 选项 'word' filename -c:打印符合要求的行数 -i:不区分大小写 -n:在输出符合要求的行的同时显示行号 -v:打印不符合要求的行 -A:后跟一个数字n,表示打印符合要求的行以及下面n行 -B:后跟一个数字n,表示打印符合要求的行以及上面n行 -C:后跟一个数字n,表示打印符合要求的行以及上下各n行 -r:会把目录下所有的文件全部遍历 --color:把匹配到的关键词用红色标示 例子: 过滤出带有某个关键词的行并输出行号 grep -n 'root' 1.txt
-
正则表达式中问号(?)的正确用法详解
目录 1.直接跟随在子表达式后面 2.非贪婪匹配 3.非获取匹配 4.断言 参考资料: 正则表达式中“?”的用法大概有以下几种 1.直接跟随在子表达式后面 这种方式是最常用的用法,具体表示匹配前面的一次或者0次,类似于{0,1},如:abc(d)?可匹配abc和abcd 2.非贪婪匹配 关于贪婪和非贪婪,贪婪匹配的意思是,在同一个匹配项中,尽量匹配更多所搜索的字符,非贪婪则相反.正则匹配的默认模式是贪婪模式,当?号跟在如下限制符后面时,使用非贪婪模式(*,+,?,{n},{n,},{n,m})
-
正则表达式RegExp语法与用法详解
目录 正则表达式的定义和用途 创建正则表达式 方式一:使用构造函数创建 方式二:使用字面量创建 正则表达式的语法 匹配字符 简写 模式修正符 贪婪匹配 断言 正则表达式的使用 搜索第一个符合条件的字符串 search() 搜索所有符合条件的字符串 match() 字符串拆分成数组 split() 字符串替换 replace() 过滤HTML标签 去除空格 常用正则表达式 总结 正则表达式的定义和用途 正则表达式用于定义一些字符串的规则.计算机可以根据正则表达式,来检查一个字符串是否符合指定的规则
-
Python正则表达式中group与groups的用法详解
目录 1 .group函数 1.1 返回整个匹配结果 1.2 返回指定分组的匹配结果 1.3 处理没有匹配结果的情况 2. groups函数 3. group和groups的使用场景 在Python中,正则表达式的group和groups方法是非常有用的函数,用于处理匹配结果的分组信息.group方法是re.MatchObject类中的一个函数,用于返回匹配对象的整个匹配结果或特定的分组匹配结果.而groups方法同样是re.MatchObject类中的函数,它返回的是所有分组匹配结果组成的元组
-
Python正则表达式re.search()用法详解
re.search():匹配整个字符串,并返回第一个成功的匹配.如果匹配失败,则返回None pattern: 匹配的规则, string : 要匹配的内容, flags 标志位 这个是可选的,就是可以不写,可以写, 比如要忽略字符的大小写就可以使用标志位 flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为: re.I 忽略大小写 re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境 re.M 多行模式 re.S 即为 . 并且包括换行符
-
Python正则表达式re.sub()用法详解
目录 1.匹配单个数字或字母 2.匹配多个数字或字母 3.匹配其他 总结 源代码.参数及其意义: def sub(pattern, repl, string, count=0, flags=0): """Return the string obtained by replacing the leftmost non-overlapping occurrences of the pattern in string by the replacement repl. repl ca
-
Linux正则表达式特性详解及BRE与ERE的异同点
Linux正则表达式(Regular Expression)主要遵从POSIX BRE或者POSIX ERE标准.什么是POSIX呢,POSIX Portable Operating System Interface 可移植操作系统接口ERE是BRE的扩展版本,具体更强的处理能力,并增加了一些元字符(metacharactor). BRE主要的能力集有: 1) 普通字符(Literal text),如a,b,c等 2)非打印字符,包括TAB,回车,换行,回车换行(WINDOWS) 3)任意字符.