python神经网络MobileNetV3 large模型的复现详解
目录
神经网络学习小记录38——MobileNetV3(large)模型的复现详解 学习前言什么是MobileNetV3代码下载MobileNetV3(large)的网络结构1、MobileNetV3(large)的整体结构2、MobileNetV3特有的bneck结构 网络实现代码
学习前言
为了防止某位我的粉丝寒假没有办法正常工作,我赶紧看了看MobilenetV3。
什么是MobileNetV3
最新的MobileNetV3的被写在了论文《Searching for MobileNetV3》中。
它是mobilnet的最新版,据说效果还是很好的。
作为一种轻量级网络,它的参数量还是一如既往的小。
它综合了以下四个特点:
1、MobileNetV1的深度可分离卷积(depthwise separable convolutions)。
2、MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)。
3、轻量级的注意力模型。
4、利用h-swish代替swish函数。
代码下载
https://github.com/bubbliiiing/classic-convolution-network
MobileNetV3(large)的网络结构 1、MobileNetV3(large)的整体结构
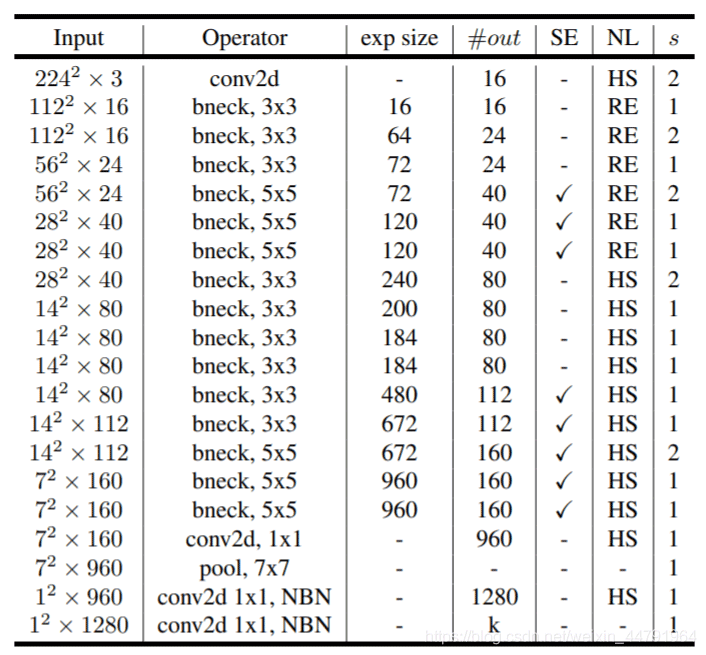
如何看懂这个表呢?我们从每一列出发:
第一列Input代表mobilenetV3每个特征层的shape变化;
第二列Operator代表每次特征层即将经历的block结构,我们可以看到在MobileNetV3中,特征提取经过了许多的bneck结构;
第三、四列分别代表了bneck内逆残差结构上升后的通道数、输入到bneck时特征层的通道数。
第五列SE代表了是否在这一层引入注意力机制。
第六列NL代表了激活函数的种类,HS代表h-swish,RE代表RELU。
第七列s代表了每一次block结构所用的步长。
2、MobileNetV3特有的bneck结构
bneck结构如下图所示:
它综合了以下四个特点:
a、MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)。
即先利用1x1卷积进行升维度,再进行下面的操作,并具有残差边。
b、MobileNetV1的深度可分离卷积(depthwise separable convolutions)。
在输入1x1卷积进行升维度后,进行3x3深度可分离卷积。
c、轻量级的注意力模型。
这个注意力机制的作用方式是调整每个通道的权重。
d、利用h-swish代替swish函数。
在结构中使用了h-swishj激活函数,代替swish函数,减少运算量,提高性能。
网络实现代码
由于keras代码没有预训练权重,所以只是把网络结构po出来。
from keras.layers import Conv2D, DepthwiseConv2D, Dense, GlobalAveragePooling2D,Inputfrom keras.layers import Activation, BatchNormalization, Add, Multiply, Reshapefrom keras.models import Modelfrom keras import backend as Kalpha = 1def relu6(x): # relu函数 return K.relu(x, max_value=6.0)def hard_swish(x): # 利用relu函数乘上x模拟sigmoid return x * K.relu(x + 3.0, max_value=6.0) / 6.0def return_activation(x, nl): # 用于判断使用哪个激活函数 if nl == 'HS': x = Activation(hard_swish)(x) if nl == 'RE': x = Activation(relu6)(x) return xdef conv_block(inputs, filters, kernel, strides, nl): # 一个卷积单元,也就是conv2d + batchnormalization + activation channel_axis = 1 if K.image_data_format() == 'channels_first' else -1 x = Conv2D(filters, kernel, padding='same', strides=strides)(inputs) x = BatchNormalization(axis=channel_axis)(x) return return_activation(x, nl)def squeeze(inputs): # 注意力机制单元 input_channels = int(inputs.shape[-1]) x = GlobalAveragePooling2D()(inputs) x = Dense(int(input_channels/4))(x) x = Activation(relu6)(x) x = Dense(input_channels)(x) x = Activation(hard_swish)(x) x = Reshape((1, 1, input_channels))(x) x = Multiply()([inputs, x]) return xdef bottleneck(inputs, filters, kernel, up_dim, stride, sq, nl): channel_axis = 1 if K.image_data_format() == 'channels_first' else -1 input_shape = K.int_shape(inputs) tchannel = int(up_dim) cchannel = int(alpha * filters) r = stride == 1 and input_shape[3] == filters # 1x1卷积调整通道数,通道数上升 x = conv_block(inputs, tchannel, (1, 1), (1, 1), nl) # 进行3x3深度可分离卷积 x = DepthwiseConv2D(kernel, strides=(stride, stride), depth_multiplier=1, padding='same')(x) x = BatchNormalization(axis=channel_axis)(x) x = return_activation(x, nl) # 引入注意力机制 if sq: x = squeeze(x) # 下降通道数 x = Conv2D(cchannel, (1, 1), strides=(1, 1), padding='same')(x) x = BatchNormalization(axis=channel_axis)(x) if r: x = Add()([x, inputs]) return xdef MobileNetv3_large(shape = (224,224,3),n_class = 1000): inputs = Input(shape) # 224,224,3 -> 112,112,16 x = conv_block(inputs, 16, (3, 3), strides=(2, 2), nl='HS') x = bottleneck(x, 16, (3, 3), up_dim=16, stride=1, sq=False, nl='RE') # 112,112,16 -> 56,56,24 x = bottleneck(x, 24, (3, 3), up_dim=64, stride=2, sq=False, nl='RE') x = bottleneck(x, 24, (3, 3), up_dim=72, stride=1, sq=False, nl='RE') # 56,56,24 -> 28,28,40 x = bottleneck(x, 40, (5, 5), up_dim=72, stride=2, sq=True, nl='RE') x = bottleneck(x, 40, (5, 5), up_dim=120, stride=1, sq=True, nl='RE') x = bottleneck(x, 40, (5, 5), up_dim=120, stride=1, sq=True, nl='RE') # 28,28,40 -> 14,14,80 x = bottleneck(x, 80, (3, 3), up_dim=240, stride=2, sq=False, nl='HS') x = bottleneck(x, 80, (3, 3), up_dim=200, stride=1, sq=False, nl='HS') x = bottleneck(x, 80, (3, 3), up_dim=184, stride=1, sq=False, nl='HS') x = bottleneck(x, 80, (3, 3), up_dim=184, stride=1, sq=False, nl='HS') # 14,14,80 -> 14,14,112 x = bottleneck(x, 112, (3, 3), up_dim=480, stride=1, sq=True, nl='HS') x = bottleneck(x, 112, (3, 3), up_dim=672, stride=1, sq=True, nl='HS') # 14,14,112 -> 7,7,160 x = bottleneck(x, 160, (5, 5), up_dim=672, stride=2, sq=True, nl='HS') x = bottleneck(x, 160, (5, 5), up_dim=960, stride=1, sq=True, nl='HS') x = bottleneck(x, 160, (5, 5), up_dim=960, stride=1, sq=True, nl='HS') # 7,7,160 -> 7,7,960 x = conv_block(x, 960, (1, 1), strides=(1, 1), nl='HS') x = GlobalAveragePooling2D()(x) x = Reshape((1, 1, 960))(x) x = Conv2D(1280, (1, 1), padding='same')(x) x = return_activation(x, 'HS') x = Conv2D(n_class, (1, 1), padding='same', activation='softmax')(x) x = Reshape((n_class,))(x) model = Model(inputs, x) return modelif __name__ == "__main__": model = MobileNetv3_large() model.summary()以上就是python神经网络MobileNetV3 large模型的复现详解的详细内容,更多关于MobileNetV3 large模型复现的资料请关注我们其它相关文章!
相关推荐
-

python神经网络MobileNetV3 large模型的复现详解
目录 神经网络学习小记录38——MobileNetV3(large)模型的复现详解 学习前言什么是MobileNetV3代码下载MobileNetV3(large)的网络结构1.MobileNetV3(large)的整体结构2.MobileNetV3特有的bneck结构 网络实现代码 学习前言 为了防止某位我的粉丝寒假没有办法正常工作,我赶紧看了看MobilenetV3. 什么是MobileNetV3 最新的MobileNetV3的被写在了论文<Searching for MobileNetV3
-
python神经网络MobileNetV3 small模型的复现详解
目录 什么是MobileNetV3 large与small的区别 MobileNetV3(small)的网络结构 1.MobileNetV3(small)的整体结构 2.MobileNetV3特有的bneck结构 网络实现代码 什么是MobileNetV3 不知道咋地,就是突然想把small也一起写了. 最新的MobileNetV3的被写在了论文<Searching for MobileNetV3>中. 它是mobilnet的最新版,据说效果还是很好的. 作为一种轻量级网络,它的参数量还是一如
-
python神经网络ResNet50模型的复现详解
目录 什么是残差网络 什么是ResNet50模型 ResNet50网络部分实现代码 图片预测 什么是残差网络 最近看yolo3里面讲到了残差网络,对这个网络结构很感兴趣,于是了解到这个网络结构最初的使用是在ResNet网络里. Residual net(残差网络): 将靠前若干层的某一层数据输出直接跳过多层引入到后面数据层的输入部分. 意味着后面的特征层的内容会有一部分由其前面的某一层线性贡献. 其结构如下: 深度残差网络的设计是为了克服由于网络深度加深而产生的学习效率变低与准确率无法有效提升的
-
python神经网络MobileNet模型的复现详解
目录 什么是MobileNet模型 MobileNet网络部分实现代码 图片预测 什么是MobileNet模型 MobileNet是一种轻量级网络,相比于其它结构网络,它不一定是最准的,但是它真的很轻 MobileNet模型是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想便是depthwise separable convolution. 对于一个卷积点而言: 假设有一个3×3大小的卷积层,其输入通道为16.输出通道为32.具体为,32个3×3大小的卷积核会遍历
-
python神经网络MobileNetV2模型的复现详解
目录 什么是MobileNetV2模型 MobileNetV2网络部分实现代码 图片预测 什么是MobileNetV2模型 MobileNet它哥MobileNetV2也是很不错的呢 MobileNet模型是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想便是depthwise separable convolution. MobileNetV2是MobileNet的升级版,它具有两个特征点: 1.Inverted residuals,在ResNet50里我们认识
-
python神经网络Keras GhostNet模型的实现
目录 什么是GhostNet模型 GhostNet模型的实现思路 1.Ghost Module 2.Ghost Bottlenecks 3.Ghostnet的构建 GhostNet的代码构建 1.模型代码的构建 2.Yolov4上的应用 什么是GhostNet模型 GhostNet是华为诺亚方舟实验室提出来的一个非常有趣的网络,我们一起来学习一下. 2020年,华为新出了一个轻量级网络,命名为GhostNet. 在优秀CNN模型中,特征图存在冗余是非常重要的.如图所示,这个是对ResNet-50
-
python神经网络Xception模型复现详解
目录 什么是Xception模型 Xception网络部分实现代码 图片预测 Xception是继Inception后提出的对Inception v3的另一种改进,学一学总是好的 什么是Xception模型 Xception是谷歌公司继Inception后,提出的InceptionV3的一种改进模型,其改进的主要内容为采用depthwise separable convolution来替换原来Inception v3中的多尺寸卷积核特征响应操作. 在讲Xception模型之前,首先要讲一下什么是
-
python神经网络InceptionV3模型复现详解
目录 神经网络学习小记录21——InceptionV3模型的复现详解 学习前言什么是InceptionV3模型InceptionV3网络部分实现代码图片预测 学习前言 Inception系列的结构和其它的前向神经网络的结构不太一样,每一层的内容不是直直向下的,而是分了很多的块. 什么是InceptionV3模型 InceptionV3模型是谷歌Inception系列里面的第三代模型,其模型结构与InceptionV2模型放在了同一篇论文里,其实二者模型结构差距不大,相比于其它神经网络模型,Inc
-
python神经网络Densenet模型复现详解
目录 什么是Densenet Densenet 1.Densenet的整体结构 2.DenseBlock 3.Transition Layer 网络实现代码 什么是Densenet 据说Densenet比Resnet还要厉害,我决定好好学一下. ResNet模型的出现使得深度学习神经网络可以变得更深,进而实现了更高的准确度. ResNet模型的核心是通过建立前面层与后面层之间的短路连接(shortcuts),这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络. DenseNet模型,
-
python神经网络ShuffleNetV2模型复现详解
目录 什么是ShuffleNetV2 ShuffleNetV2 1.所用模块 2.网络整体结构 网络实现代码 什么是ShuffleNetV2 据说ShuffleNetV2比Mobilenet还要厉害,我决定好好学一下 这篇是ECCV2018关于轻量级模型的文章. 目前大部分的轻量级模型在对比模型速度时用的指标是FLOPs,这个指标主要衡量的就是卷积层的乘法操作. 但是实际运用中会发现,同一个FLOPS的网络运算速度却不同,只用FLOPS去进行衡量的话并不能完全代表模型速度. 通过如下图所示对比,