mAP计算目标检测精确度实现源码
目录
- GITHUB代码下载
- 1、IOU的概念
- 2、TP TN FP FN的概念
- 3、precision(精确度)和recall(召回率)
- 4、概念举例
- 5、单个指标的局限性
- 什么是AP
好多人都想算一下目标检测的精确度,mAP的概念虽然不好理解,但是理解了就很懂。
GITHUB代码下载
这个是用来绘制mAP曲线的
这个是用来获取绘制mAP曲线所需的txt的
1、IOU的概念
IOU的概念应该比较简单,就是衡量预测框和真实框的重合程度。下图是一个示例:图中绿色框为实际框(好像不是很绿……),红色框为预测框,当我们需要判断两个框之间的关系时,主要就是判断两个框的重合程度。

计算IOU的公式为:
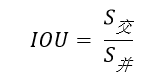
可以看到IOU是一个比值,即交并比。
在分子部分,值为预测框和实际框之间的重叠区域;
在分母部分,值为预测框和实际框所占有的总区域。


交区域和并区域的比值,就是IOU。
2、TP TN FP FN的概念
TP TN FP FN里面一共出现了4个字母,分别是T F P N。
T是True;
F是False;
P是Positive;
N是Negative。
T或者F代表的是该样本 是否被正确分类。
P或者N代表的是该样本 被预测成了正样本还是负样本。
TP(True Positives)意思就是被分为了正样本,而且分对了。
TN(True Negatives)意思就是被分为了负样本,而且分对了,
FP(False Positives)意思就是被分为了正样本,但是分错了(事实上这个样本是负样本)。
FN(False Negatives)意思就是被分为了负样本,但是分错了(事实上这个样本是这样本)。
在mAP计算的过程中主要用到了,TP、FP、FN这三个概念。
3、precision(精确度)和recall(召回率)

TP是分类器认为是正样本而且确实是正样本的例子,FP是分类器认为是正样本但实际上不是正样本的例子,Precision翻译成中文就是“分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例”。

TP是分类器认为是正样本而且确实是正样本的例子,FN是分类器认为是负样本但实际上不是负样本的例子,Recall翻译成中文就是“分类器认为是正类并且确实是正类的部分占所有确实是正类的比例”。
4、概念举例

如图所示,蓝色的框是 真实框。绿色和红色的框是 预测框,绿色的框是正样本,红色的框是负样本。一般来讲,当预测框和真实框IOU>=0.5时,被认为是正样本。
因此对于这幅图来讲。
真实框一共有3个,正样本一共有2个,负样本一共有2个。
此时

5、单个指标的局限性
在目标检测算法里面有一个非常重要的概念是置信度,如果置信度设置的高的话,预测的结果和实际情况就很符合,如果置信度低的话,就会有很多误检测。
假设一幅图里面总共有3个正样本,目标检测对这幅图的预测结果有10个,其中3个实际上是正样本,7个实际上是负样本。对应置信度如下。

如果我们将可以接受的置信度设置为0.95的话,那么目标检测算法就会将序号为1的样本作为正样本,其它的都是负样本。此时TP = 1,FP = 0,FN = 2。
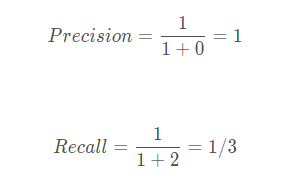
此时Precision非常高,但是事实上我们只检测出一个正样本,还有两个没有检测出来,因此只用Precision就不合适。
这个时候如果我们将可以接受的置信度设置为0.35的话,那么目标检测算法就会将序号为1的样本作为正样本,其它的都是负样本。此时TP = 3,FP = 3,FN = 0。
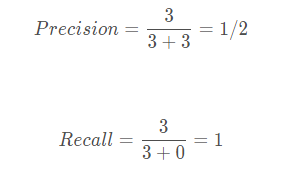
此时Recall非常高,但是事实上目标检测算法认为是正样本的样本里面,有3个样本确实是正样本,但有三个是负样本,存在非常严重的误检测,因此只用Recall就不合适。
二者进行结合才是评价的正确方法。
什么是AP
AP事实上指的是,利用不同的Precision和Recall的点的组合,画出来的曲线下面的面积。如下面这幅图所示。
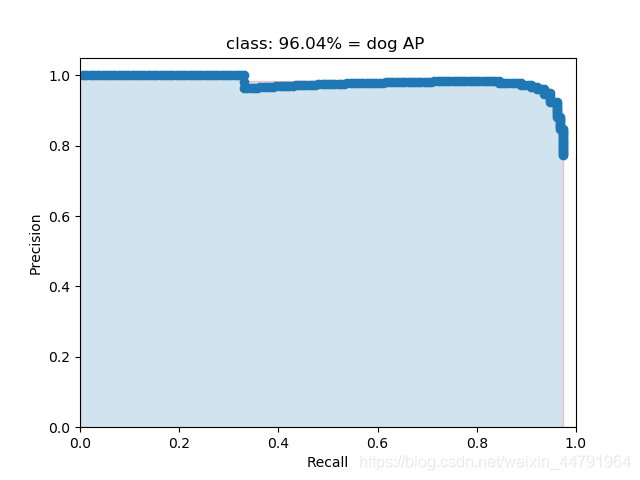
当我们取不同的置信度,可以获得不同的Precision和不同的Recall,当我们取得置信度够密集的时候,就可以获得非常多的Precision和Recall。
此时Precision和Recall可以在图片上画出一条线,这条线下部分的面积就是某个类的AP值。
mAP就是所有的类的AP值求平均。
绘制mAP
我们首先在下载绘制mAP所需的代码。
在这个代码中,如果想要绘制mAP则需要三个内容。分别是:
detection-results:指的是预测结果的txt。

ground-truth:指的是真实框的txt。
image-optional:指的是图片,有这个可以可视化,但是这个可以没有。
我们需要生成这三个内容,此时下载第二个库,这个是我拿我制作的ssd代码写的一个可以生成对应txt的例子。
点击下载
我们首先将整个VOC的数据集放到VOCdevikit中

然后修改voc2ssd.py里面的trainval_percent,一般用数据集的10%或者更少用于测试。如果大家放进VOCdevikit的数据集不是全部数据,而是已经筛选好的测试数据集的话,那么就把trainval_percent设置成0,表示全部的数据都用于测试。

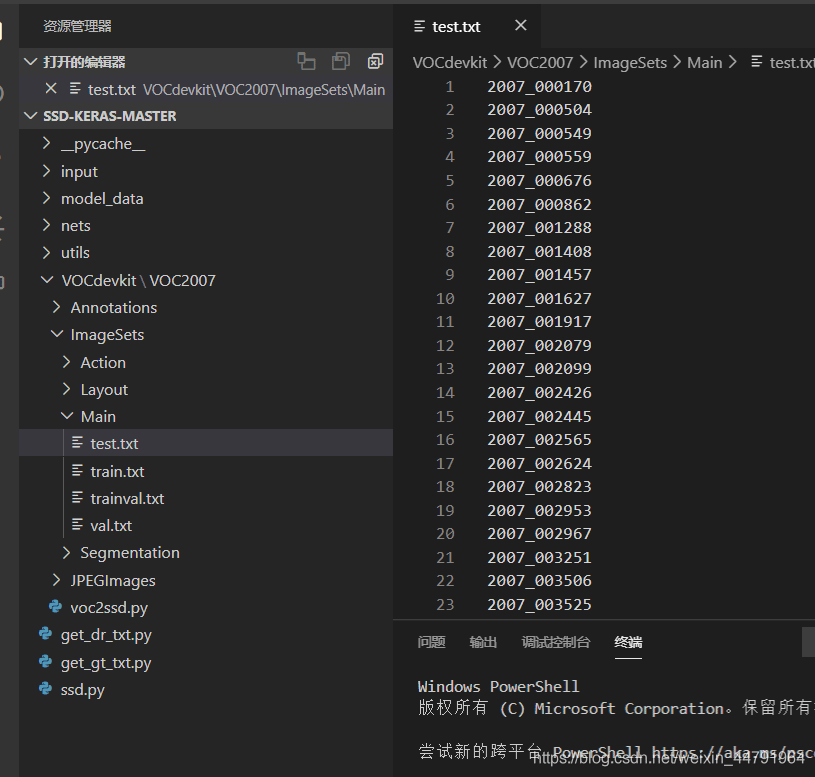
然后运行voc2ssd.py。此时会生成test.txt,存放用于测试的图片的名字。
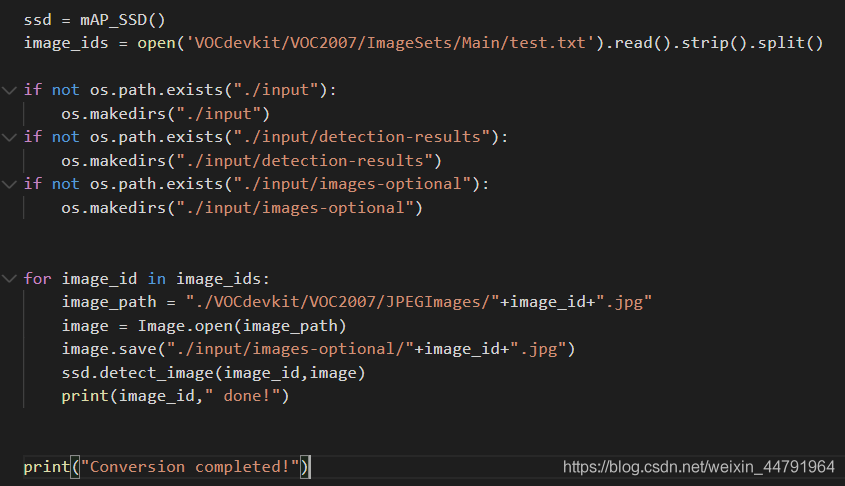
然后依次运行主目录下的get_dr_txt.py和get_gt_txt.py获得预测框对应的txt和真实框对应的txt。get_dr_txt.py是用来检测测试集里面的图片的,然后会生成每一个图片的检测结果,我重写了detect_image代码,用于生成预测框的txt。利用for循环检测所有的图片。
get_dr_txt.py是用来获取测试集中的xml,然后根据每个xml的结果生成真实框的txt。利用for循环检测所有的xml。

完成后我们会在input获得三个文件夹。

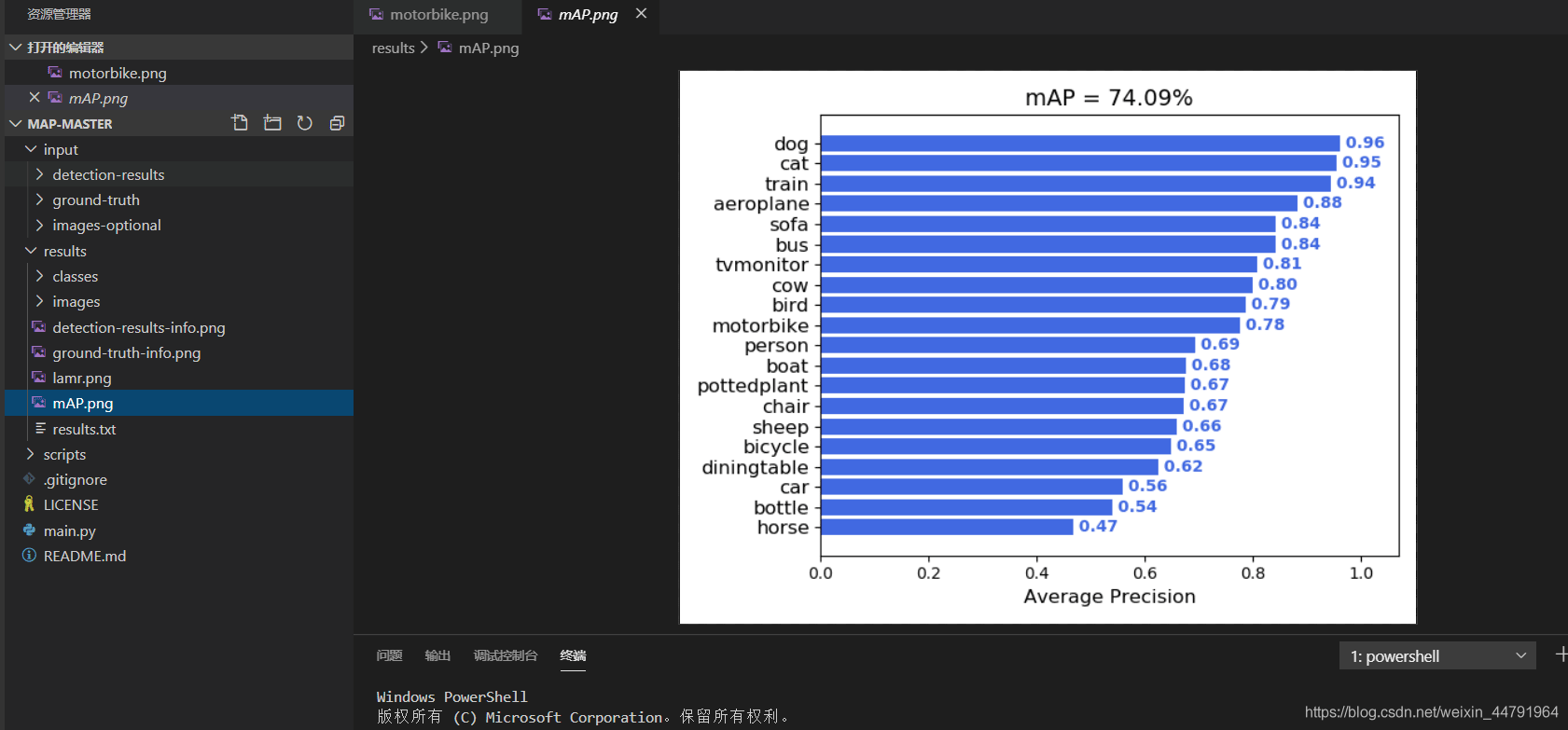
此时把input内部的文件夹复制到mAP的代码中的input文件夹内部就可以了,然后我们运行mAP的代码中的main.py,运行结束后,会生成mAP相关的文件。
结果生成在Result里面。
以上就是mAP计算目标检测精确度实现源码的详细内容,更多关于mAP目标检测的资料请关注我们其它相关文章!
相关推荐
-

python目标检测SSD算法训练部分源码详解
目录 学习前言 讲解构架 模型训练的流程 1.设置参数 2.读取数据集 3.建立ssd网络. 4.预处理数据集 5.框的编码 6.计算loss值 7.训练模型并保存 开始训练 学习前言 ……又看了很久的SSD算法,今天讲解一下训练部分的代码.预测部分的代码可以参照https://blog.csdn.net/weixin_44791964/article/details/102496765 讲解构架 本次教程的讲解主要是对训练部分的代码进行讲解,该部分讲解主要是对训练函数的执行过程与执行思路进行详
-
目标检测mAP的概念及公式详解
目录 学习前言 什么是TP.TN.FP.FN 什么是Precision和Recall 什么是mAP 1.步骤1: 2.步骤2: 3.步骤3 学习前言 在Github上我们可以看到许多模型,他们都有mAP值的评价指标,如下图所示: 这到底是个啥呢?我查了好久的资料… 什么是TP.TN.FP.FN TP的英文全称为True Positives,其指的是被分配为正样本,而且分配对了的样本,代表的是被正确分类的正样本,. TN的英文全称为,其指的是被分配为负样本,而且分配对了的样本,代表的是被正确分类的
-
python目标检测SSD算法预测部分源码详解
目录 学习前言 什么是SSD算法 ssd_vgg_300主体的源码 学习前言 ……学习了很多有关目标检测的概念呀,咕噜咕噜,可是要怎么才能进行预测呢,我看了好久的SSD源码,将其中的预测部分提取了出来,训练部分我还没看懂 什么是SSD算法 SSD是一种非常优秀的one-stage方法,one-stage算法就是目标检测和分类是同时完成的,其主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度
-
python目标检测IOU的概念与示例
目录 学习前言 什么是IOU IOU的特点 全部代码 学习前言 神经网络的应用还有许多,目标检测就是其中之一,目标检测中有一个很重要的概念便是IOU 什么是IOU IOU是一种评价目标检测器的一种指标. 下图是一个示例:图中绿色框为实际框(好像不是很绿……),红色框为预测框,当我们需要判断两个框之间的关系时,需要用什么指标呢? 此时便需要用到IOU. 计算IOU的公式为: 可以看到IOU是一个比值,即交并比. 在分子部分,值为预测框和实际框之间的重叠区域: 在分母部分,值为预测框和实际框所占有的
-
mAP计算目标检测精确度实现源码
目录 GITHUB代码下载 1.IOU的概念 2.TP TN FP FN的概念 3.precision(精确度)和recall(召回率) 4.概念举例 5.单个指标的局限性 什么是AP 好多人都想算一下目标检测的精确度,mAP的概念虽然不好理解,但是理解了就很懂. GITHUB代码下载 这个是用来绘制mAP曲线的 这个是用来获取绘制mAP曲线所需的txt的 1.IOU的概念 IOU的概念应该比较简单,就是衡量预测框和真实框的重合程度.下图是一个示例:图中绿色框为实际框(好像不是很绿……),红色框
-
Pytorch搭建YoloV4目标检测平台实现源码
目录 什么是YOLOV4 YOLOV4结构解析 1.主干特征提取网络Backbone 2.特征金字塔 3.YoloHead利用获得到的特征进行预测 4.预测结果的解码 5.在原图上进行绘制 YOLOV4的训练 1.YOLOV4的改进训练技巧 a).Mosaic数据增强 b).Label Smoothing平滑 c).CIOU d).学习率余弦退火衰减 2.loss组成 a).计算loss所需参数 b).y_pre是什么 c).y_true是什么. d).loss的计算过程 训练自己的YoloV4
-
Pytorch搭建yolo3目标检测平台实现源码
目录 yolo3实现思路 一.预测部分 1.主题网络darknet53介绍 2.从特征获取预测结果 3.预测结果的解码 4.在原图上进行绘制 二.训练部分 1.计算loss所需参数 2.pred是什么 3.target是什么. 4.loss的计算过程 训练自己的YoloV3模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 yolo3实现思路 一起来看看yolo3的Pytorch实现吧,顺便训练一下自己的数据. 源码下载 一.预测部分 1.主题网络darknet53介绍
-
RxJava中map和flatMap的用法区别源码解析
目录 前言: 作用 使用方法: map flatMap 源码分析 map flatMap 结语 前言: RxJava中提供了大量的操作符,这大大提高了了我们的开发效率.其中最基本的两个变换操作符就是map和flatMap.而其他变换操作符的原理基本与map类似. map和flatMap都是接受一个函数作为参数(Func1)并返回一个被观察者Observable Func1的< I,O >I,O模版分别为输入和输出值的类型,实现Func1的call方法对I类型进行处理后返回O类型数据,只是fla
-
内存泄漏检测工具LeakCanary源码解析
目录 前言 使用 源码解析 LeakCanary自动初始化 如何关闭自动初始化 LeakCanary初始化做了什么 ActivityWatcher FragmentAndViewModelWatcher RootViewWatcher ServiceWatcher Leakcanary对象泄漏检查 总结 前言 LeakCanary是一个简单方便的内存泄漏检测工具,它是由大名鼎鼎的Square公司出品并开源的出来的.目前大部分APP在开发阶段都会接入此工具用来检测内存泄漏问题.它让我们开发者可以在
-
python使用正则表达式检测密码强度源码分享
复制代码 代码如下: #encoding=utf-8#-------------------------------------------------------------------------------# Name: 模块1# Purpose:## Author: Administrator## Created: 10-06-2014# Copyright: (c) Administrator 2014# Licence: <your lic
-
ArrayList源码和多线程安全问题分析
1.ArrayList源码和多线程安全问题分析 在分析ArrayList线程安全问题之前,我们线对此类的源码进行分析,找出可能出现线程安全问题的地方,然后代码进行验证和分析. 1.1 数据结构 ArrayList内部是使用数组保存元素的,数据定义如下: transient Object[] elementData; // non-private to simplify nested class access 在ArrayList中此数组即是共享资源,当多线程对此数据进行操作的时候如果不进行同步控
-
Java同步锁Synchronized底层源码和原理剖析(推荐)
目录 1 synchronized场景回顾 2 反汇编寻找锁实现原理 3 synchronized虚拟机源码 3.1 HotSpot源码Monitor生成 3.2 HotSpot源码之Monitor竞争 3.3 HotSpot源码之Monitor等待 3.4 HotSpot源码之Monitor释放 1 synchronized场景回顾 目标:synchronized回顾(锁分类–>多线程)概念synchronized:是Java中的关键字,是一种同步锁.Java中锁分为以下几种:乐观锁.悲观锁(
-
React深入分析更新的创建源码
目录 ReactDom.render setState 与 forceUpdate expirationTime的作用 获取currentTime 不同的expirationTime React 的鲜活生命起源于 ReactDOM.render ,这个过程会为它的一生储备好很多必需品,我们顺着这个线索,一探婴儿般 React 应用诞生之初的悦然. 更新创建的操作我们总结为以下两种场景 ReactDOM.render setState forceUpdate ReactDom.render 串联该