OpenCV实现车牌定位(C++)
最近开始接触 C++ 了,就拿一个 OpenCV 小项目来练练手。在车牌自动识别系统中,从汽车图像的获取到车牌字符处理是一个复杂的过程,本文就以一个简单的方法来处理车牌定位。
我国的汽车牌照一般由七个字符和一个点组成,车牌字符的高度和宽度是固定的,分别为90mm和45mm,七个字符之间的距离也是固定的12mm,点分割符的直径是10mm。
使用的图片是从百度上随便找的(侵删),展示一下原图和灰度图:
#include <iostream>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/imgproc/types_c.h>
using namespace std;
using namespace cv;
int main() {
// 读入原图
Mat img = imread("license.jpg");
Mat gray_img;
// 生成灰度图像
cvtColor(img, gray_img, CV_BGR2GRAY);
// 在窗口中显示游戏原画
imshow("原图", img);
imshow("灰度图", gray_img);
waitKey(0);
return 0;
}


灰度图像的每一个像素都是由一个数字量化的,而彩色图像的每一个像素都是由三个数字组成的向量量化的,使用灰度图像会更方便后续的处理。
图像降噪
每一副图像都包含某种程度的噪声,在大多数情况下,需要平滑技术(也常称为滤波或者降噪技术)进行抑制或者去除,这些技术包括基于二维离散卷积的高斯平滑、均值平滑、基于统计学方法的中值平滑等。这里采用基于二维离散卷积的高斯平滑对灰度图像进行降噪处理,处理后的图像效果如下:

形态学处理
完成了高斯去噪以后,为了后面更加准确的提取车牌的轮廓,我们需要对图像进行形态学处理,在这里,我们对它进行开运算,处理后如下所示:

开运算呢就是先进行 erode 再进行 dilate 的过程就是开运算,它具有消除亮度较高的细小区域、在纤细点处分离物体,对于较大物体,可以在不明显改变其面积的情况下平滑其边界等作用。
erode 操作也就是腐蚀操作,类似于卷积,也是一种邻域运算,但计算的不是加权求和,而是对邻域中的像素点按灰度值进行排序,然后选择该组的最小值作为输出的灰度值。
dilate 操作就是膨胀操作,与腐蚀操作类似,膨胀是取每一个位置邻域内的最大值。既然是取邻域内的最大值,那么显然膨胀后的输出图像的总体亮度的平均值比起原图会有所上升,而图像中较亮物体的尺寸会变大;相反,较暗物体的尺寸会减小,甚至消失。
阈值分割
完成初步的形态学处理以后,我们需要对图像进行阈值分割,我们在这里采用了 Otsu 阈值处理,处理后的效果如下所示:

对图像进行数字处理时,我们需要把图像分成若干个特定的、具有独特性质的区域,每一个区域代表一个像素的集合,每一个集合又代表一个物体,而完成该过程的技术通常称为图像分割,它是从图像处理到图像分析的关键步骤。其实这个过程不难理解,就好比我们人类看景物一样,我们所看到的世界是由许许多多的物体组合而成的,就像教室是由人、桌子、书本、黑板等等组成。我们通过阈值处理,就是希望能够从背景中分离出我们的研究对象。
边缘检测
经过Otsu阈值分割以后,我们要对图像进行边缘检测,我们这里采用的是Canny边缘检测,处理后的结果如下:
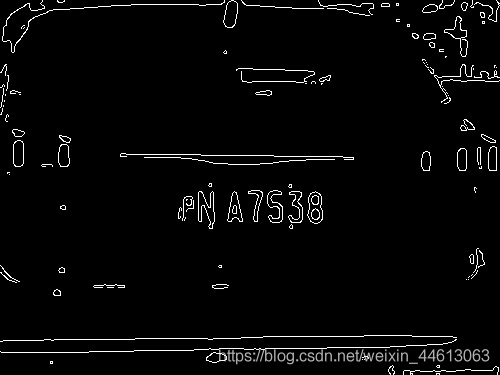
接下来再进行一次闭运算和开运算,填充白色物体内细小黑色空洞的区域并平滑其边界,处理后的效果如下:

这个时候,车牌的轮廓已经初步被选出来了,只是还有一些白色块在干扰。
上述过程的代码:
// 得出轮廓
bool contour(Mat image, vector<vector<Point>> &contours, vector<Vec4i> &hierarchy) {
Mat img_gau, img_open, img_seg, img_edge;
// 高斯模糊
GaussianBlur(image, img_gau, Size(7, 7), 0, 0);
// 开运算
Mat element = getStructuringElement(MORPH_RECT, Size(23, 23));
morphologyEx(img_gau, img_open, MORPH_OPEN, element);
addWeighted(img_gau, 1, img_open, -1, 0, img_open);
// 阈值分割
threshold(img_open, img_seg, 0, 255, THRESH_BINARY + THRESH_OTSU);
// 边缘检测
Canny(img_seg, img_edge, 200, 100);
element = getStructuringElement(MORPH_RECT, Size(22, 22));
morphologyEx(img_edge, img_edge, MORPH_CLOSE, element);
morphologyEx(img_edge, img_edge, MORPH_OPEN, element);
findContours(img_edge, contours, hierarchy, RETR_TREE, CHAIN_APPROX_SIMPLE, Point());
return true;
}
选取轮廓
现在我们已经有了轮廓,我们需要筛选出车牌所在的那个轮廓,由于车牌宽和高的比例是固定的,依据这个几何特征,我们进行筛选,效果如图:


代码如下:
// 车牌轮廓点
Point2f(*choose_contour(vector<vector<Point>> contours))[2] {
int size = (int)contours.size();
int i_init = 0;
Point2f (*contours_result)[2] = new Point2f[size][2];
for (int i = 0; i < size; i++){
// 获取边框数据
RotatedRect number_rect = minAreaRect(contours[i]);
Point2f rect_point[4];
number_rect.points(rect_point);
float width = rect_point[0].x - rect_point[1].x;
float height = rect_point[0].y - rect_point[3].y;
// 用宽高比筛选
if (width < height) {
float temp = width;
width= height;
height = temp;
}
float ratio = width / height;
if (2.5 < ratio && ratio < 5.5) {
contours_result[i_init][0] = rect_point[0];
contours_result[i_init][1] = rect_point[2];
i_init++;
}
}
return contours_result;
}
// 截取车牌区域
int license_gain(Point2f (*choose_license)[2], Mat img) {
int size = (int)(_msize(choose_license) / sizeof(choose_license[0]));
// 绘制方框
for (int i = 0; i < size; i++) {
if ((int)choose_license[i][0].x > 1 && (int)choose_license[i][0].y > 1) {
int x = (int)choose_license[i][1].x;
int y = (int)choose_license[i][1].y;
int width = (int)(choose_license[i][0].x) - (int)(choose_license[i][1].x);
int height = (int)(choose_license[i][0].y) - (int)(choose_license[i][1].y);
Rect choose_rect(x, y, width, height);
Mat number_img = img(choose_rect);
rectangle(img, choose_license[i][0], choose_license[i][1], Scalar(0, 0, 255), 2, 1, 0);
imshow("车牌单独显示" + to_string(i), number_img);
}
}
imshow("绘制方框", img);
return 0;
}
最后的 main 函数:
int main() {
// 读入原图
Mat img = imread("license.jpg");
Mat gray_img;
// 生成灰度图像
cvtColor(img, gray_img, CV_BGR2GRAY);
// 得出轮廓
vector<vector<Point>> contours;
vector<Vec4i> hierarchy;
contour(gray_img, contours, hierarchy);
// 截取车牌
Point2f (*choose_license)[2] = choose_contour(contours);
license_gain(choose_license, img);
delete [] choose_license;
waitKey(0);
return 0;
}
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

android端使用openCV实现车牌检测
现在,汽车的踪影无处不在,公路上疾驰,大街边临停,小区中停靠,车库里停泊.管理监控如此庞大数量的汽车是个头疼的问题.精明的人们把目光放在车牌上,因为车牌是汽车的"身份证".所以车牌识别成为了焦点,而车牌检测是车牌识别的基础和前提.本篇文章,主要讨论使用openCV实现车牌检测. openCV是开源计算机视觉库,基于计算机视觉与机器学习,提供强大的图像处理能力.我们可以快速集成openCV库到android端,其中一种方式是直接安装openCV Manager,按需使用:启动服务去动态加
-
OpenCV+Python识别车牌和字符分割的实现
本篇文章主要基于python语言和OpenCV库(cv2)进行车牌区域识别和字符分割,开篇之前针对在python中安装opencv的环境这里不做介绍,可以自行安装配置! 车牌号检测需要大致分为四个部分: 1.车辆图像获取 2.车牌定位. 3.车牌字符分割 4.车牌字符识别 具体介绍 车牌定位需要用到的是图片二值化为黑白后进canny边缘检测后多次进行开运算与闭运算用于消除小块的区域,保留大块的区域,后用cv2.rectangle选取矩形框,从而定位车牌位置 车牌字符的分割前需要准备的是只保留车牌
-
OpenCV实现车牌字符分割(C++)
之前的车牌定位中已经获取到了车牌的位置,并且对车牌进行了提取.我们最终的目的是进行车牌识别,在这之前需要将字符进行分割,方便对每一个字符进行识别,最后将其拼接后便是完整的车牌号码.关于车牌定位可以看这篇文章: OpenCV车牌定位(C++),本文使用的图片也是来自这里. 先来看一看原图: 最左边的汉字本来是 沪,截取时只获得了右边一点点的部分,这与原图和获取方法都有关,对于 川.沪- 这一类左右分开的字会经常发生这类问题,对方法进行优化后可以解决,这里暂时不进行讨论. 后面的字都是完整的,字符分
-
Python+OpenCV实现车牌字符分割和识别
最近做一个车牌识别项目,入门级别的,十分简单. 车牌识别总体分成两个大的步骤: 一.车牌定位:从照片中圈出车牌 二.车牌字符识别 这里只说第二个步骤,字符识别包括两个步骤: 1.图像处理 原本的图像每个像素点都是RGB定义的,或者称为有R/G/B三个通道.在这种情况下,很难区分谁是背景,谁是字符,所以需要对图像进行一些处理,把每个RGB定义的像素点都转化成一个bit位(即0-1代码),具体方法如下: ①将图片灰度化 名字拗口,但是意思很好理解,就是把每个像素的RGB都变成灰色的RGB值,而灰色的
-
python+opencv实现车牌定位功能(实例代码)
写在前面 HIT大三上学期视听觉信号处理课程中视觉部分的实验三,经过和学长们实验的对比发现每一级实验要求都不一样,因此这里标明了是2019年秋季学期的视觉实验三. 由于时间紧张,代码没有进行任何优化,实验算法仅供参考. 实验要求 对给定的车牌进行车牌识别 实验代码 代码首先贴在这里,仅供参考 源代码 实验代码如下: import cv2 import numpy as np def lpr(filename): img = cv2.imread(filename) # 预处理,包括灰度处理,高斯
-
python+OpenCV实现车牌号码识别
基于python+OpenCV的车牌号码识别,供大家参考,具体内容如下 车牌识别行业已具备一定的市场规模,在电子警察.公路卡口.停车场.商业管理.汽修服务等领域已取得了部分应用.一个典型的车辆牌照识别系统一般包括以下4个部分:车辆图像获取.车牌定位.车牌字符分割和车牌字符识别 1.车牌定位的主要工作是从获取的车辆图像中找到汽车牌照所在位置,并把车牌从该区域中准确地分割出来 这里所采用的是利用车牌的颜色(黄色.蓝色.绿色) 来进行定位 #定位车牌 def color_position(img,ou
-
OpenCV实现车牌定位(C++)
最近开始接触 C++ 了,就拿一个 OpenCV 小项目来练练手.在车牌自动识别系统中,从汽车图像的获取到车牌字符处理是一个复杂的过程,本文就以一个简单的方法来处理车牌定位. 我国的汽车牌照一般由七个字符和一个点组成,车牌字符的高度和宽度是固定的,分别为90mm和45mm,七个字符之间的距离也是固定的12mm,点分割符的直径是10mm. 使用的图片是从百度上随便找的(侵删),展示一下原图和灰度图: #include <iostream> #include <opencv2/highgui
-
c++ 基于opencv 识别、定位二维码
前言 因工作需要,需要定位图片中的二维码:我遂查阅了相关资料,也学习了opencv开源库.通过一番努力,终于很好的实现了二维码定位.本文将讲解如何使用opencv定位二维码. 定位二维码不仅仅是为了识别二维码:还可以通过二维码对图像进行水平纠正以及相邻区域定位.定位二维码,不仅需要图像处理相关知识,还需要分析二维码的特性,本文先从二维码的特性讲起. 1 二维码特性 二维码在设计之初就考虑到了识别问题,所以二维码有一些特征是非常明显的. 二维码有三个"回""字形图案,这一点非常
-
Opencv创建车牌图片识别系统方法详解
目录 前言 包含功能 软件版本 软件架构 参考文档 效果图展示 车牌检测过程 图片车牌文字识别过程 部分核心代码 前言 这是一个基于spring boot + maven + opencv 实现的图像识别及训练的Demo项目 包含车牌识别.人脸识别等功能,贯穿样本处理.模型训练.图像处理.对象检测.对象识别等技术点 java语言的深度学习项目,在整个开源社区来说都相对较少: 拥有完整的训练过程.检测.识别过程的开源项目更是少之又少!! 包含功能 蓝.绿.黄车牌检测及车牌号码识别 网上常见的轮廓提
-
opencv实现车牌识别
本文实例为大家分享了opencv实现车牌识别的具体代码,供大家参考,具体内容如下 (1)提取车牌位置,将车牌从图中分割出来:(2)车牌字符的分割:(3)通过模版匹配识别字符:(4)将结果绘制在图片上显示出来. import cv2 from matplotlib import pyplot as plt import os import numpy as np # plt显示彩色图片 def plt_show0(img): # cv2与plt的图像通道不同:cv2为[b,g,r];plt