Python使用chrome配置selenium操作详解
目录
- 1.下载chrome浏览器驱动程序
- 2.文件解压放置
- 3.配置环境变量
- 总结
1.下载chrome浏览器驱动程序
驱动程序网址http://chromedriver.storage.googleapis.com/index.html根据chrome对应的版本下载适合的驱动程序
查询chrome版本方法:
点击浏览器红圈处,点击帮助,关于chrome

下载对应版本的驱动程序:
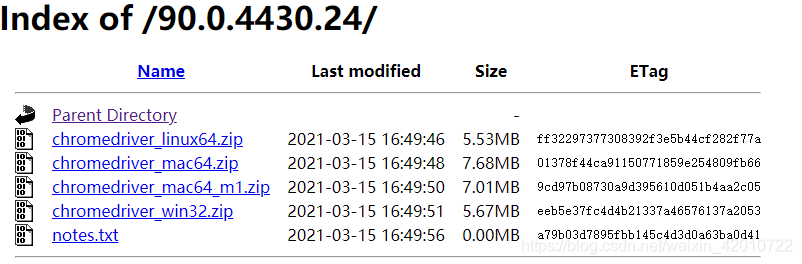
2.文件解压放置
将下载后的文件解压到对应chrome的安装目录,也是就chrome浏览器对应的文件位置,通常为C:\Program Files\Google\Chrome\Application之后将文件中chromedriver.exe也只有这一个文件,放到上面这个目录下
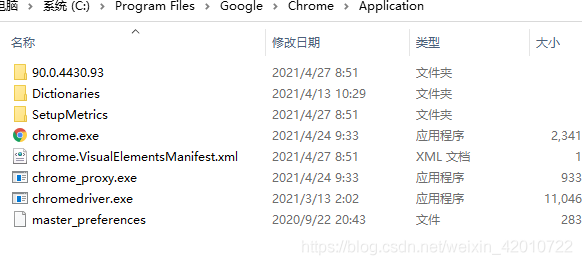
3.配置环境变量
将第二步对应的路径配置到系统变量中
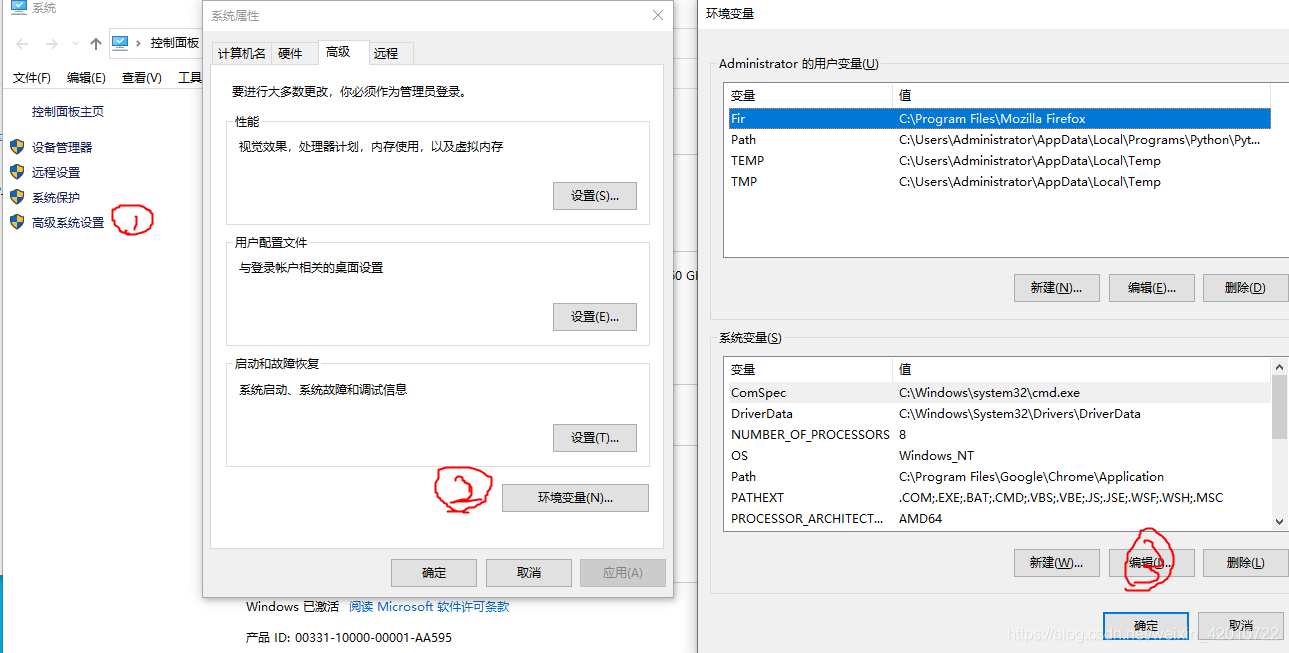
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
Selenium chrome配置代理Python版的方法
环境: windows 7 + Python 3.5.2 + Selenium 3.4.2 + Chrome Driver 2.29 + Chrome 58.0.3029.110 (64-bit) Selenium官方给的Firefox代理配置方式并不起效,也没看到合适的配置方式,对于Chrome Selenium官方没有告知如何配置,但以下两种方式是有效的: 1. 连接无用户名密码认证的代理 chromeOptions = webdriver.ChromeOptions() chromeOpt
-

详解Python+Selenium+ChromeDriver的配置和问题解决
安装前的准备 1.python的安装和配置 在Window下:在开始菜单中找到运行输入cmd或直接搜索cmd点击进入,输入python,如果出现下图中的>>>则证明Python安装成功. 检测Chrome的版本号安装Chromedriver 记录版本号: 87.0.4280.88 打开ChromeDirver网址:http://chromedriver.storage.googleapis.com/index.html 选择对应版本号的文件夹并打开 ChromeDriver的环境配置 C
-
selenium+python配置chrome浏览器的选项的实现
1. 背景 在使用selenium浏览器渲染技术,爬取网站信息时,默认情况下就是一个普通的纯净的chrome浏览器,而我们平时在使用浏览器时,经常就添加一些插件,扩展,代理之类的应用.相对应的,当我们用chrome浏览器爬取网站时,可能需要对这个chrome做一些特殊的配置,以满足爬虫的行为. 常用的行为有: 禁止图片和视频的加载:提升网页加载速度. 添加代理:用于翻墙访问某些页面,或者应对IP访问频率限制的反爬技术. 使用移动头:访问移动端的站点,一般这种站点的反爬技术比较薄弱. 添加扩展:像
-
Selenium启动Chrome时配置选项详解
Selenium操作浏览器是不加载任何配置的,网上找了半天,关于Firefox加载配置的多点,Chrome资料很少,下面是关于加载Chrome配置的方法: 一.加载所有Chrome配置 用Chrome地址栏输入chrome://version/,查看自己的"个人资料路径",然后在浏览器启动时,调用这个配置文件,代码如下: #coding=utf-8 from selenium import webdriver option = webdriver.ChromeOptions() opt
-
Python使用chrome配置selenium操作详解
目录 1.下载chrome浏览器驱动程序 2.文件解压放置 3.配置环境变量 总结 1.下载chrome浏览器驱动程序 驱动程序网址http://chromedriver.storage.googleapis.com/index.html根据chrome对应的版本下载适合的驱动程序 查询chrome版本方法: 点击浏览器红圈处,点击帮助,关于chrome 下载对应版本的驱动程序: 2.文件解压放置 将下载后的文件解压到对应chrome的安装目录,也是就chrome浏览器对应的文件位置,通常为C:
-
python数据类型_字符串常用操作(详解)
这次主要介绍字符串常用操作方法及例子 1.python字符串 在python中声明一个字符串,通常有三种方法:在它的两边加上单引号.双引号或者三引号,如下: name = 'hello' name1 = "hello bei jing " name2 = '''hello shang hai haha''' python中的字符串一旦声明,是不能进行更改的,如下: #字符串为不可变变量,即不能通过对某一位置重新赋值改变内容 name = 'hello' name[0] = 'k' #通
-
Python Pandas学习之基本数据操作详解
目录 1索引操作 1.1直接使用行列索引(先列后行) 1.2结合loc或者iloc使用索引 1.3使用ix组合索引 2赋值操作 3排序 3.1DataFrame排序 3.2Series排序 为了更好的理解这些基本操作,下面会通过读取一个股票数据,来进行Pandas基本数据操作的语法介绍. # 读取文件(读取保存文件后面会专门进行讲解,这里先直接调用下api) data = pd.read_csv("./data/stock_day.csv") # 读取当前目录下一个csv文件 # 删
-
Python读写JSON文件的操作详解
目录 JSON JSON 起源 JSON 样例 Python 原生支持 JSON 序列化 JSON 简单的序列化示例 JSON 反序列化 简单的反序列化示例 应用案例 编码和解码 JSON JSON 起源 JSON 全称 JavaScript Object Notation .是处理对象文字语法的 JavaScript 编程语言的一个子集.JSON 早已成为与语言无关的语言,并作为自己的标准存在. JSON 样例 { "data":[ { "id": "1
-
Python实现数据的序列化操作详解
目录 Json 模块 dumps()函数 dump()函数 loads()函数 load()函数 Pickle 模块 dumps()函数 dump()函数 loads()函数 load()函数 总结 在日常开发中,对数据进行序列化和反序列化是常见的数据操作,Python提供了两个模块方便开发者实现数据的序列化操作,即 json 模块和 pickle 模块.这两个模块主要区别如下: json 是一个文本序列化格式,而 pickle 是一个二进制序列化格式: json 是我们可以直观阅读的,而 p
-
Python YAML文件的读写操作详解
目录 YAML格式 YAML文件 YAML操作 读取 存储 示例 转字典 转列表 YAML是一种数据序列化格式,方便人类阅读,且容易和脚本语言交互.常用于配置文件,也用于数据存储或传输. YAML格式 YAML三种基本数据类型: 1.标量:如字符串.整数和浮点数.日期 布尔值:“true”.“True”.“TRUE”.“yes”.“Yes"和"YES”,“false”.“False”.“FALSE”.“no”.“No"和"NO” 空:null.Null.~或不指定值
-
Python处理键映射值操作详解
目录 1. 问题背景 2. collections 概述 2.1 什么是collections 2.2 Collections 内部结构 2.3 collections 使用方法 3. defaultdict 方法 setdefault(),对字典key值赋默认值 defaultdict(),对字典进行查找取值 4. Counter 方法 总结 作为一个学完Python基础知识的测试,暗喜终于可以像RD们自己写脚本处理任何场景吧,如何优雅地写出来代码,接下来开启进阶版的Python. 本期浅谈一
-
Python学习之字符串常用操作详解
目录 1.查找字符串 2.分割字符串 3.连接字符串 4.替换字符串 5.移除字符串的首尾字符 6.转换字符串的大小写 7.检测字符串(后续还会更新) 1.查找字符串 除了使用index()方法在字符串中查找指定元素,还可以使用find()方法在一个较长的字符串中查找子串.如果找到子串,返回子串所在位置的最左端索引,否则返回-1. 语法格式: str.find(sub[,start[,end]]) 其中,str表示被查找的字符串.sub表示查找的子串.start表示开始索引,缺省时为0.end表
-
Python开发SQLite3数据库相关操作详解【连接,查询,插入,更新,删除,关闭等】
本文实例讲述了Python开发SQLite3数据库相关操作.分享给大家供大家参考,具体如下: '''SQLite数据库是一款非常小巧的嵌入式开源数据库软件,也就是说 没有独立的维护进程,所有的维护都来自于程序本身. 在python中,使用sqlite3创建数据库的连接,当我们指定的数据库文件不存在的时候 连接对象会自动创建数据库文件:如果数据库文件已经存在,则连接对象不会再创建 数据库文件,而是直接打开该数据库文件. 连接对象可以是硬盘上面的数据库文件,也可以是建立在内存中的,在内存中的数据库
-
Python使用Pandas库常见操作详解
本文实例讲述了Python使用Pandas库常见操作.分享给大家供大家参考,具体如下: 1.概述 Pandas 是Python的核心数据分析支持库,提供了快速.灵活.明确的数据结构,旨在简单.直观地处理关系型.标记型数据.Pandas常用于处理带行列标签的矩阵数据.与 SQL 或 Excel 表类似的表格数据,应用于金融.统计.社会科学.工程等领域里的数据整理与清洗.数据分析与建模.数据可视化与制表等工作. 数据类型:Pandas 不改变原始的输入数据,而是复制数据生成新的对象,有普通对象构成的