Python通过正则库爬取淘宝商品信息代码实例
使用正则库爬取淘宝商品的商品信息,首先我们需要确定想要爬取的对象
我们在淘宝里搜索“python”,出来的结果
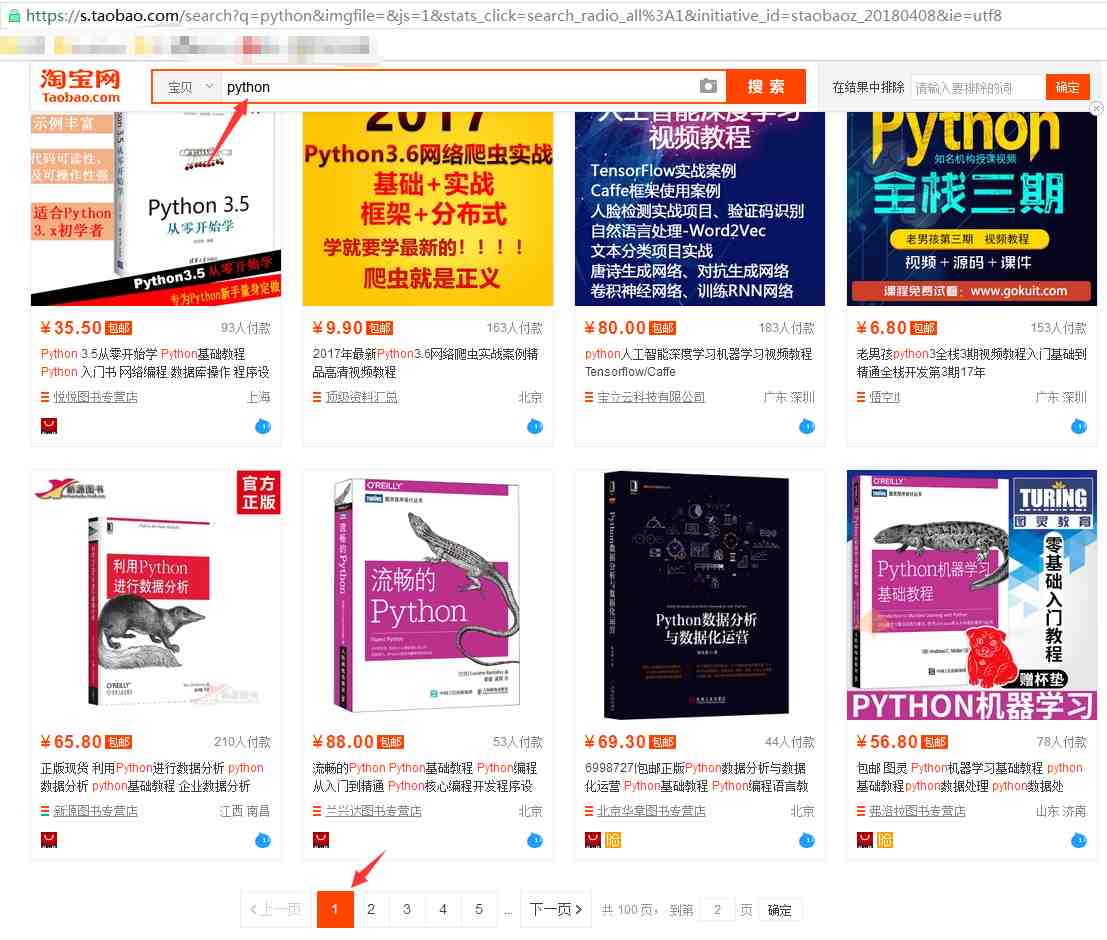
从url连接中可以得到搜索商品的关键字是“q=”,所以我们要用的起始url为:https://s.taobao.com/search?q=python
然后翻页,经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44)
所以可以根据关键字“s=”,来设置爬取的深度(爬取多少页)
右键查看源码,商品名称可能的关键字是“title”和“raw_title”,进一步多看几个商品的名称,发现选取“raw_title”比较合适;商品价格自然就是“view_price”(通过比对淘宝商品展示页面);所以商品名称和商品价格分别是以"raw_title":"名称"和"view_price":"价格",这样的键/值对的形式展示的。
# coding:utf-8 import requests import re goods = '水杯' url = 'https://s.taobao.com/search?q=' + goods r = requests.get(url=url, timeout=10) html = r.text tlist = re.findall(r'\"raw_title\"\:\".*?\"', html) # 正则提取商品名称 plist = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) # 正则提示商品价格 print(tlist) print(plist) print(type(plist)) # 正则表达式提取出的商品名称和商品价格都是以列表形式存储数据的
利用for循环,把每个商品的名称和价格组成一个列表,然后把这写列表再追加到一个大列表中:
goodlist = []
for i in range(len(tlist)):
title = eval(tlist[i].split(':')[1]) # eval()函数简单说就是用于去掉字符串的引号
price = eval(plist[i].split(':')[1])
goodlist.append([title, price]) # 把每个商品的名称和价格组成一个小列表,然后把所有商品组成的列表追加到一个大列表中
print(goodlist)
大概的思路就是这样的。
def get_html(url):
"""获取源码html"""
try:
r = requests.get(url=url, timeout=10)
r.encoding = r.apparent_encoding
return r.text
except:
print("获取失败")
def get_data(html, goodlist):
"""使用re库解析商品名称和价格
tlist:商品名称列表
plist:商品价格列表"""
tlist = re.findall(r'\"raw_title\"\:\".*?\"', html)
plist = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
for i in range(len(tlist)):
title = eval(tlist[i].split(':')[1]) # eval()函数简单说就是用于去掉字符串的引号
price = eval(plist[i].split(':')[1])
goodlist.append([title, price])
def write_data(list, num):
# with open('E:/Crawler/case/taob2.txt', 'a') as data:
# print(list, file=data)
for i in range(num): # num控制把爬取到的商品写进多少到文本中
u = list[i]
with open('E:/Crawler/case/taob.txt', 'a') as data:
print(u, file=data)
def main():
goods = '水杯'
depth = 3 # 定义爬取深度,即翻页处理
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44 * i) # 因为淘宝显示每页44个商品,第一页i=0,一次递增
html = get_html(url)
get_data(html, infoList)
except:
continue
write_data(infoList, len(infoList))
if __name__ == '__main__':
main()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python使用requests xpath 并开启多线程爬取西刺代理ip实例
我就废话不多说啦,大家还是直接看代码吧! import requests,random from lxml import etree import threading import time angents = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compati
-
Python爬虫程序架构和运行流程原理解析
1 前言 Python开发网络爬虫获取网页数据的基本流程为: 发起请求 通过URL向服务器发起request请求,请求可以包含额外的header信息. 获取响应内容 服务器正常响应,将会收到一个response,即为所请求的网页内容,或许包含HTML,Json字符串或者二进制的数据(视频.图片)等. 解析内容 如果是HTML代码,则可以使用网页解析器进行解析,如果是Json数据,则可以转换成Json对象进行解析,如果是二进制的数据,则可以保存到文件做进一步处理. 保存数据 可以保存到本地文件,也
-
python爬虫开发之Beautiful Soup模块从安装到详细使用方法与实例
python爬虫模块Beautiful Soup简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能.它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序.Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码.你不需要考虑编码方式,除非
-
Python网络爬虫信息提取mooc代码实例
实例一--爬取页面 import requests url="https//itemjd.com/2646846.html" try: r=requests.get(url) r.raise_for_status() r.encoding=r.apparent_encoding print(r.text[:1000]) except: print("爬取失败") 正常页面爬取 实例二--爬取页面 import requests url="https://w
-
Python爬虫实现模拟点击动态页面
动态页面的模拟点击: 以斗鱼直播为例:http://www.douyu.com/directory/all 爬取每页的房间名.直播类型.主播名称.在线人数等数据,然后模拟点击下一页,继续爬取 代码如下 #!/usr/bin/python3 # -*- coding:utf-8 -*- __author__ = 'mayi' """ 动态页面的模拟点击: 模拟点击斗鱼直播:http://www.douyu.com/directory/all 爬取每页房间名.直播类型.主播名称.
-
Python基于requests库爬取网站信息
requests库是一个简介且简单的处理HTTP请求的第三方库 get()是获取网页最常用的方式,其基本使用方式如下 使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,这里我们常用的就是beautifulsoup4库,用于解析和处理HTML和XML 下面这段代码便是爬取百度的信息并简单输出百度的界面信息 import requests from bs4 import BeautifulSoup r=requests.get('http://www.bai
-
基于Python爬取爱奇艺资源过程解析
像iqiyi这种视频网站,现在下载视频都需要下载相应的客户端.那么如何不用下载客户端,直接下载非vip视频? 选择你想要爬取的内容 该安装的程序以及运行环境都配置好 下面这段代码就是我在爱奇艺里搜素"英文名",然后出来的视频,共有20页,那么我们便从第一页开始,解析网页,然后分析 分析每一页网址,找出规律就可以直接得到所有页面 然后根据每一个视频的URL的标签,如'class' 'div' 'href'......通过bs4库进行爬取 而其他的信息则是直接循环所爬取到的URL,在每一个
-
Python通过正则库爬取淘宝商品信息代码实例
使用正则库爬取淘宝商品的商品信息,首先我们需要确定想要爬取的对象 我们在淘宝里搜索"python",出来的结果 从url连接中可以得到搜索商品的关键字是"q=",所以我们要用的起始url为:https://s.taobao.com/search?q=python 然后翻页,经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44) 所以可以根据关键字"s=",来设置爬取的深度(爬取多少页)
-
Python进阶之使用selenium爬取淘宝商品信息功能示例
本文实例讲述了Python进阶之使用selenium爬取淘宝商品信息功能.分享给大家供大家参考,具体如下: # encoding=utf-8 __author__ = 'Jonny' __location__ = '西安' __date__ = '2018-05-14' ''' 需要的基本开发库文件: requests,pymongo,pyquery,selenium 开发流程: 搜索关键字:利用selenium驱动浏览器搜索关键字,得到查询后的商品列表 分析页码并翻页:得到商品页码数,模拟翻页
-

Python 爬取淘宝商品信息栏目的实现
一.相关知识点 1.1.Selenium Selenium是一个强大的开源Web功能测试工具系列,可进行读入测试套件.执行测试和记录测试结果,模拟真实用户操作,包括浏览页面.点击链接.输入文字.提交表单.触发鼠标事件等操作,并且能够对页面结果进行种种验证.也就是说,只要在测试用例中把预期的用户行为与结果都描述出来,我们就得到了一个可以自动化运行的功能测试套件. 1.2.ActionChains Actionchains是selenium里面专门处理鼠标相关的操作如:鼠标移动,鼠标按钮操作,按键和
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
python爬虫爬取淘宝商品信息(selenum+phontomjs)
本文实例为大家分享了python爬虫爬取淘宝商品的具体代码,供大家参考,具体内容如下 1.需求目标 : 进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等. 2.结果展示 3.源代码 # encoding: utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time import pandas as pd time1=time.time()
-
python爬取淘宝商品销量信息
python爬取淘宝商品销量的程序,运行程序,输入想要爬取的商品关键词,在代码中的'###'可以进一步约束商品的属性,比如某某作者的书籍,可以在###处输入作者名字,以及时期等等.最后可以得到所要商品的总销量 import requests import bs4 import re import json def open(keywords, page): headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64)
-
Python爬虫实战之爬取某宝男装信息
目录 知识点介绍 实现步骤 1. 分析目标网站 2. 获取单个商品界面 3. 获取多个商品界面 4. 获取商品信息 5. 保存到MySQL数据库 完整代码 知识点介绍 本次爬取用到的知识点有: 1. selenium 2. pymysql 3 pyquery 实现步骤 1. 分析目标网站 1. 打开某宝首页, 输入"男装"后点击"搜索", 则跳转到"男装"的搜索界面. 2. 空白处"右击"再点击"检查"审
-
python爬取淘宝商品详情页数据
在讲爬取淘宝详情页数据之前,先来介绍一款 Chrome 插件:Toggle JavaScript (它可以选择让网页是否显示 js 动态加载的内容),如下图所示: 当这个插件处于关闭状态时,待爬取的页面显示的数据如下: 当这个插件处于打开状态时,待爬取的页面显示的数据如下: 可以看到,页面上很多数据都不显示了,比如商品价格变成了划线价格,而且累计评论也变成了0,说明这些数据都是动态加载的,以下演示真实价格的找法(评论内容找法类似),首先检查页面元素,然后点击Network选项卡,刷新页面,可
-
Python使用Selenium+BeautifulSoup爬取淘宝搜索页
使用Selenium驱动chrome页面,获得淘宝信息并用BeautifulSoup分析得到结果. 使用Selenium时注意页面的加载判断,以及加载超时的异常处理. import json import re from bs4 import BeautifulSoup from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.com
-
Python利用Xpath选择器爬取京东网商品信息
HTML文件其实就是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成标签树:XPath 使用路径表达式在 XML 文档中选取节点.节点是通过沿着路径或者 step 来选取的. 首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求.在这里小编仍以关键词"狗粮"作为搜索对象,之后得到后面这一串网址: https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其中参