新手Hadoop安装 环境搭建
目录
- 一. 下载环境
- 二. 创建Hadoop用户
- 1.进入用户,打开终端输入如下命令:
- 2.设置密码
- 三. 进行Hadoop内部环境的搭建
- 四. 安装ssh并配置无密码登陆
- 1.登陆
- 2.设置无密码登陆
- 五.安装Java环境
- 六.安装Hadoop
- 七.Hadoop伪分布配置
- 1.配置文件
- 2.开启NameNode 和 DataNode 守护进程
- 八.Hadoop集群搭建
- 总结
一. 下载环境
Ubuntu 2.x.x 版本
二. 创建Hadoop用户
在虚拟机创建安装完成后。
1.进入用户,打开终端输入如下命令:
sudo useradd -m hadoop -s /bin/bash
则创建好了可以登陆的Hadoop用户
/bin/bash 作为 shell
2.设置密码
在终端输入
sudo passwd hadoop #需输入两次密码 sudo adduser hadoop sudo #给Hadoop添加管理员权限
完成
三. 进行Hadoop内部环境的搭建
更新apt
打开终端输入
sudo apt-get update #更新apt sudo apt-get install vim #下载vim 用于修改配置文件
四. 安装ssh并配置无密码登陆
1.登陆
sudo apt-get install openssh-serve #下载 ssh localhost #登陆 首次登陆输入yes并输入密码登陆完成

2.设置无密码登陆
exit #退出登陆 ssh-keygen -t rsa #出现提示后按回车 cat ./id_rsa.pub >> ./authorized_keys #加入授权 ssh localhost #再次登陆ssh 不需要密码

若出现需要密码登陆但错误,需要将ssh删除,重新下载安装进行配置
rm -rf ~/.ssh #删除ssh
五.安装Java环境
先寻找Java下载的镜像网站
如华为,清华等
再输入相应的代码进行下载
wget https://repo.huaweicloud.com/java/jdk/8u171-b11/jdk-8u171-linux-x64.tar.gz
之后输入以下指令进行解压
cd /usr/lib sudo mkdir jvm #创建/uer/lib/jvm 目录存放JDK文件 cd sudo tar -zxvf ./jdk-8u171-linux-x64.tar.gz -C /usr/lib/jvm #解压到/usr/lib/jvm目录中 cd ~ vim ~/.bashrc #环境变量配置文件
添加以下内容到第一行
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
退出后使命令立即生效
source ~/bashrc java -version #查看是否安装成功
六.安装Hadoop
和安装Java类似,搜索镜像并下载
下载完成后将Hadoop安装至/usr/lib中
sudo tar -zxf ~/下载/hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中 cd /usr/local/ sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop sudo chown -R hadoop ./hadoop # 修改文件权限
cd /usr/local/hadoop ./bin/hadoop version #检查版本信息
七.Hadoop伪分布配置
1.配置文件
cd /usr/loca/hadoop/etc/hadoop/ gedit ./etc/hadoop/core-site.xml #修改core-site.xml的配置
将其中的
<configuration> </configuration>
改为
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同理将hdfs-site.xml中的改为
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置完成后,执行NameNode的格式化:
cd /usr/local/hadoop ./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
2.开启NameNode 和 DataNode 守护进程
cd /usr/local/hadoop ./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
若出现ssh提示,输入yes 出现WARN提示可以忽略启动 Hadoop 时提示 Could not resolve hostname ,输入
vim ~/.bashrc
添加环境变量
export HADOOP_HOME=/usr/local/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
完成后执行
soure ~/.bashrc #使变量生效 ./sbin.start-dfs.sh #启动Hadoop jps #查看是否启动成功,若有NameNode ,DataNode,SecondaryNameNode则成功启动
若DataNode无法启动
cd /usr/local/hadoop ./sbin/stop-dfs.sh # 关闭 rm -r ./tmp # 删除 tmp 文件,注意这会删除 HDFS 中原有的所有数据,慎用 ./bin/hdfs namenode -format # 重新格式化 NameNode ./sbin/start-dfs.sh # 重启
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
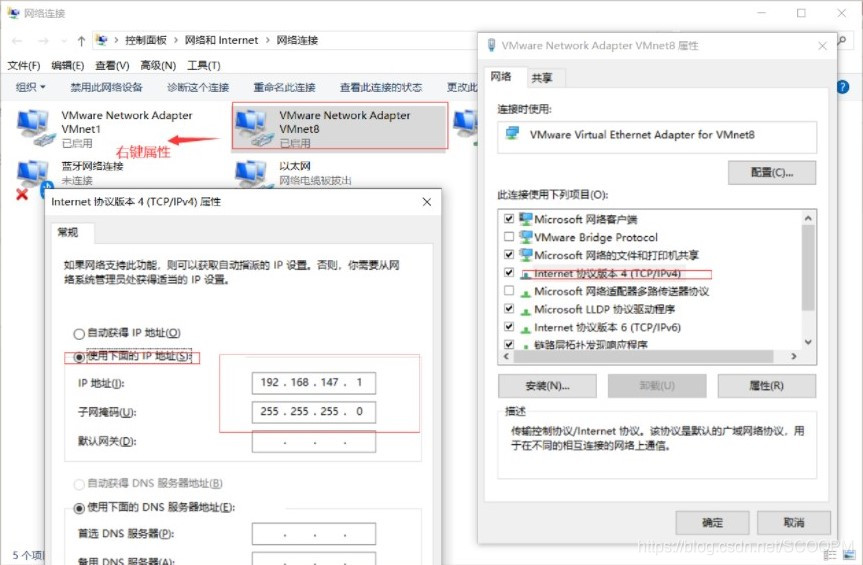
八.Hadoop集群搭建
按图调整网络设置



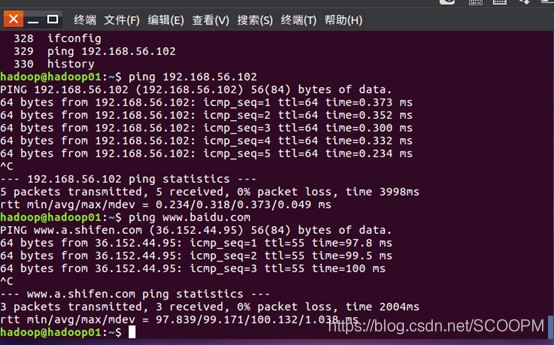
ping 通则说明成功

总结
本篇文章就到这里了,希望能给您带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
VMware虚拟机下hadoop1.x的安装方法
这是Hadoop学习全程记录第1篇,在这篇里我将介绍一下如何在Linux下安装Hadoop1.x. 先说明一下我的开发环境: 虚拟机:VMware8.0: 操作系统:CentOS6.4: 版本:jdk1.8:hadoop1.2.1 ①下载hadoop1.2.1,网盘:链接: https://pan.baidu.com/s/1sl5DMIp 密码: 5p67 下载jdk1.8,网盘:链接: https://pan.baidu.com/s/1boN1gh5 密码: t36h 将 jdk-8u144-
-

详解Ubuntu16.04下Hadoop 2.7.3的安装与配置
一.Java环境搭建 (1)下载JDK并解压(当前操作系统为Ubuntu16.04,jdk版本为jdk-8u111-Linux-x64.tar.gz) 新建/usr/java目录,切换到jdk-8u111-linux-x64.tar.gz所在目录,将这个文件解压缩到/usr/java目录下. tar -zxvf jdk-8u101-linux-x64.tar.gz -C /usr/java/ (2)设置环境变量 修改.bashrc,在最后一行写入下列内容. sudo vim ~/.bashrc
-
Hadoop的安装与环境搭建教程图解
一.Hadoop的安装 1. 下载地址:https://archive.apache.org/dist/hadoop/common/我下载的是hadoop-2.7.3.tar.gz版本. 2. 在/usr/local/ 创建文件夹zookeeper mkdir hadoop 3.上传文件到Linux上的/usr/local/source目录下 3.解压缩 运行如下命令: tar -zxvf hadoop-2.7.3.tar.gz-C /usr/local/hadoop 4. 修改配置文件 进入到
-
centos6.5 安装hadoop1.2.1的教程详解【亲测版】
本篇只简单介绍安装步骤 1. 角色分配 10.11.84.4 web-crawler--1.novalocal master/slave 10.11.84.5 web-crawler--2.novalocal slave 10.11.84.6 web-crawler--3.novalocal slave 2.安装目录 /usr/local/hadoop (HADOOP_HOME) 3,创建group hadoop groupadd hadoop 4.创建用户hadoop useradd -d
-
linux环境不使用hadoop安装单机版spark的方法
大数据持续升温, 不熟悉几个大数据组件, 连装逼的口头禅都没有. 最起码, 你要会说个hadoop, hdfs, mapreduce, yarn, kafka, spark, zookeeper, neo4j吧, 这些都是装逼的必备技能. 关于spark的详细介绍, 网上一大堆, 搜搜便是, 下面, 我们来说单机版的spark的安装和简要使用. 0. 安装jdk, 由于我的机器上之前已经有了jdk, 所以这一步我可以省掉. jdk已经是很俗气的老生常谈了, 不多说, 用java/scala的
-
新手Hadoop安装 环境搭建
目录 一. 下载环境 二. 创建Hadoop用户 1.进入用户,打开终端输入如下命令: 2.设置密码 三. 进行Hadoop内部环境的搭建 四. 安装ssh并配置无密码登陆 1.登陆 2.设置无密码登陆 五.安装Java环境 六.安装Hadoop 七.Hadoop伪分布配置 1.配置文件 2.开启NameNode 和 DataNode 守护进程 八.Hadoop集群搭建 总结 一. 下载环境 Ubuntu 2.x.x 版本 二. 创建Hadoop用户 在虚拟机创建安装完成后. 1.进入用户,打开
-
详解Hadoop 运行环境搭建过程
一,集群搭建步骤 1.先在一台虚拟机配置jdk,hadoop 2.克隆 3.修改网络等相关配置 当我们使用虚拟机时,可能自然而然的会想上面的步骤一样先搭建一台虚拟机,做好相关配置,然后进行克隆,继而修改一些网络配置来搭建集群,但是在生产过程中是买好的服务器,不存在克隆这一说,所以在此采用的步骤是: 1.建立一台虚拟机(仅带jdk安装包) 2.克隆 3.修改网络等相关配置 4.配置第一个hadoop节点,编写集群分发脚本使其他虚拟机完成配置 二,具体搭建过程 这里使用三台虚拟机来完成集群搭建,ha
-
hadoop分布式环境搭建过程
1. Java安装与环境配置 Hadoop是基于Java的,所以首先需要安装配置好java环境.从官网下载JDK,我用的是1.8版本. 在Mac下可以在终端下使用scp命令远程拷贝到虚拟机linux中. danieldu@daniels-MacBook-Pro-857 ~/Downloads scp jdk-8u121-linux-x64.tar.gz root@hadoop100:/opt/software root@hadoop100's password: danieldu@daniels
-
windows 32位eclipse远程hadoop开发环境搭建
本文假设hadoop环境在远程机器(如linux服务器上),hadoop版本为2.5.2 注:本文eclipse/intellij idea 远程调试hadoop 2.6.0主要参考了并在其基础上有所调整 由于我喜欢在win7 64位上安装32位的软件,比如32位jdk,32位eclipse,所以虽然本文中的操作系统是win7 64位,但是所有的软件都是32位的. 软件版本: 操作系统:win7 64位 eclipse: eclipse-jee-mars-2-win32 java: 1.8.0_
-
新手必备Python开发环境搭建教程
一.Python解释器 安装 Windows平台 下载地址 https://www.python.org/ftp/python/3.9.5/python-3.9.5-amd64.exe(3.9版本) 安装python3.9 exe安装:注意修改目录.环境变量 安装路径:C:/python39(安装路径可以自定,但注意不要包含中文或空格等特殊字符) 验证 # 按键盘"win+R",输入"cmd" , 在命令行测试 C:\Users\cPenadm>python
-
Java新手环境搭建 Tomcat安装配置教程
安装 Tomcat 之前请一定先安装 Java ,然后才能安装 Tomcat . 安装 Java .环境变量 path 的设置以及 cmd 小技巧请看:Java新手环境搭建 JDK8安装配置教程 下载 Tomcat 首先到 Tomcat 的官方网站下载 Windows 版本的 Tomcat 最新版,根据我们所使用的操作系统,我们下载 64 位 Windows 的 zip 版本.不建议使用 Installer 版本. 我们以 apache-tomcat-9.0.0.M15-windows-x64.
-
使用Maven搭建Hadoop开发环境
关于Maven的使用就不再啰嗦了,网上很多,并且这么多年变化也不大,这里仅介绍怎么搭建Hadoop的开发环境. 1. 首先创建工程 复制代码 代码如下: mvn archetype:generate -DgroupId=my.hadoopstudy -DartifactId=hadoopstudy -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false 2. 然后在pom.xml文件里添加hadoop的依赖
-
Hadoop环境搭建过程中遇到的问题及解决方法
1.启动hadoop之前,ssh免密登录slave主机正常,使用命令start-all.sh启动hadoop时,需要输入slave主机的密码,说明ssh文件权限有问题,需要执行以下操作: 1)进入.ssh目录下查看是否有公钥私钥文件authorized_keys.id_rsa.id_rsa.pub 2)如果没有公钥私钥文件,则执行ssh-keygen -t rsa生成秘钥(master主机和slave主机都需要执行) 3)公钥私钥文件生成完成后,执行cat id_rsa.pub >> auth
-
python环境搭建和pycharm的安装配置及汉化(零基础小白版)
前言:写这篇文章主要是介绍一下python的环境搭建和pycharm的安装配置,适合零基础的同学观看.这篇文章你会学到python的环境搭建和python比较好用的IDE pycharm的安装与基础配置. 运行环境:window 64位操作系统. 没想到这么多的人看这篇文章,并且接连不断给我发邮箱,问问题,这篇文章不是用markdown写的,不好改,我重新写了一份,放在我的博客里面,这里是地址:https://yaoguangju.github.io/2018/12/27/python%E7%8