Python爬取OPGG上英雄联盟英雄胜率及选取率信息的操作
本次爬取网站为opgg,网址为:” http://www.op.gg/champion/statistics”

由网站界面可以看出,右侧有英雄的详细信息,以Garen为例,胜率为53.84%,选取率为16.99%,常用位置为上单
现对网页源代码进行分析(右键鼠标在菜单中即可找到查看网页源代码)。通过查找“53.84%”快速定位Garen所在位置

由代码可看出,英雄名、胜率及选取率都在td标签中,而每一个英雄信息在一个tr标签中,td父标签为tr标签,tr父标签为tbody标签。
对tbody标签进行查找

代码中共有5个tbody标签(tbody标签开头结尾均有”tbody”,故共有10个”tbody”),对字段内容分析,分别为上单、打野、中单、ADC、辅助信息




以上单这部分英雄为例,我们需要首先找到tbody标签,然后从中找到tr标签(每一条tr标签就是一个英雄的信息),再从子标签td标签中获取英雄的详细信息
二、爬取步骤
爬取网站内容->提取所需信息->输出英雄数据
getHTMLText(url)->fillHeroInformation(hlist,html)->printHeroInformation(hlist)
getHTMLText(url)函数是返回url链接中的html内容
fillHeroInformation(hlist,html)函数是将html中所需信息提取出存入hlist列表中
printHeroInformation(hlist)函数是输出hlist列表中的英雄信息
三、代码实现
1、getHTMLText(url)函数
def getHTMLText(url): #返回html文档信息
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text #返回html内容
except:
return ""
2、fillHeroInformation(hlist,html)函数

以一个tr标签为例,tr标签内有7个td标签,第4个td标签内属性值为"champion-index-table__name"的div标签内容为英雄名,第5个td标签内容为胜率,第6个td标签内容为选取率,将这些信息存入hlist列表中
def fillHeroInformation(hlist,html): #将英雄信息存入hlist列表
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children: #遍历上单tbody标签的儿子标签
if isinstance(tr,bs4.element.Tag): #判断tr是否为标签类型,去除空行
tds = tr('td') #查找tr标签下的td标签
heroName = tds[3].find(attrs = "champion-index-table__name").string #英雄名
winRate = tds[4].string #胜率
pickRate = tds[5].string #选取率
hlist.append([heroName,winRate,pickRate]) #将英雄信息添加到hlist列表中
3、printHeroInformation(hlist)函数
def printHeroInformation(hlist): #输出hlist列表信息
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format("英雄名","胜率","选取率","位置"))
for i in range(len(hlist)):
i = hlist[i]
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format(i[0],i[1],i[2],"上单"))
4、main()函数
网站地址赋值给url,新建一个hlist列表,调用getHTMLText(url)函数获得html文档信息,使用fillHeroInformation(hlist,html)函数将英雄信息存入hlist列表,再使用printHeroInformation(hlist)函数输出信息
def main():
url = "http://www.op.gg/champion/statistics"
hlist = []
html = getHTMLText(url) #获得html文档信息
fillHeroInformation(hlist,html) #将英雄信息写入hlist列表
printHeroInformation(hlist) #输出信息
四、结果演示
1、网站界面信息




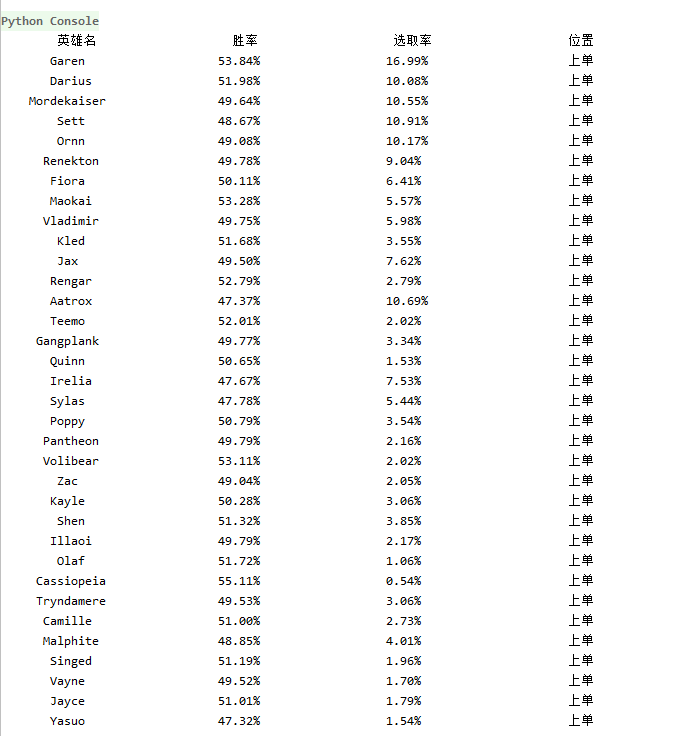
2、爬取结果

五、完整代码
import requests #导入requests库
import bs4 #导入bs4库
from bs4 import BeautifulSoup #导入BeautifulSoup库
def getHTMLText(url): #返回html文档信息
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text #返回html内容
except:
return ""
def fillHeroInformation(hlist,html): #将英雄信息存入hlist列表
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children: #遍历上单tbody标签的儿子标签
if isinstance(tr,bs4.element.Tag): #判断tr是否为标签类型,去除空行
tds = tr('td') #查找tr标签下的td标签
heroName = tds[3].find(attrs = "champion-index-table__name").string #英雄名
winRate = tds[4].string #胜率
pickRate = tds[5].string #选取率
hlist.append([heroName,winRate,pickRate]) #将英雄信息添加到hlist列表中
def printHeroInformation(hlist): #输出hlist列表信息
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format("英雄名","胜率","选取率","位置"))
for i in range(len(hlist)):
i = hlist[i]
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format(i[0],i[1],i[2],"上单"))
def main():
url = "http://www.op.gg/champion/statistics"
hlist = []
html = getHTMLText(url) #获得html文档信息
fillHeroInformation(hlist,html) #将英雄信息写入hlist列表
printHeroInformation(hlist) #输出信息
main()
如果需要爬取打野、中单、ADC或者辅助信息,只需要修改
fillHeroInformation(hlist,html)
函数中的
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children语句
将attrs属性值修改为
"tabItem champion-trend-tier-JUNGLE"
"tabItem champion-trend-tier-MID"
"tabItem champion-trend-tier-ADC"
"tabItem champion-trend-tier-SUPPORT"
等即可!
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
python爬虫爬取网页数据并解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 只要浏览器能够做的事情,原则上,爬虫都能够做到. 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等. 有时,我们比较喜欢的新闻网站可能有几个,每次都要分别
-
实例讲解Python爬取网页数据
一.利用webbrowser.open()打开一个网站: >>> import webbrowser >>> webbrowser.open('http://i.firefoxchina.cn/?from=worldindex') True 实例:使用脚本打开一个网页. 所有Python程序的第一行都应以#!python开头,它告诉计算机想让Python来执行这个程序.(我没带这行试了试,也可以,可能这是一种规范吧) 1.从sys.argv读取命令行参数:打开一个新的文
-

Python爬虫获取op.gg英雄联盟英雄对位胜率的源码
通过第三方BeautifulSoup库来爬取op.gg网页静态数据 主要思路 op.gg网站 网站以出场率高低排名,并且列出对位胜率,在高出场率的前提下,胜率有很大的参考意义,在counter位很有帮助 通过开发者工具找到对应部位源码,发现数据就在源码中,证明这是一个静态数据,确定使用BeautifulSoup库. 源码 import requests from bs4 import BeautifulSoup championname={'阿卡丽 ':'akali','牛头':'alistar
-
Python大数据之从网页上爬取数据的方法详解
本文实例讲述了Python大数据之从网页上爬取数据的方法.分享给大家供大家参考,具体如下: myspider.py : #!/usr/bin/python # -*- coding:utf-8 -*- from scrapy.spiders import Spider from lxml import etree from jredu.items import JreduItem class JreduSpider(Spider): name = 'tt' #爬虫的名字,必须的,唯一的 all
-
Python爬取OPGG上英雄联盟英雄胜率及选取率信息的操作
本次爬取网站为opgg,网址为:" http://www.op.gg/champion/statistics" 由网站界面可以看出,右侧有英雄的详细信息,以Garen为例,胜率为53.84%,选取率为16.99%,常用位置为上单 现对网页源代码进行分析(右键鼠标在菜单中即可找到查看网页源代码).通过查找"53.84%"快速定位Garen所在位置 由代码可看出,英雄名.胜率及选取率都在td标签中,而每一个英雄信息在一个tr标签中,td父标签为tr标签,tr父标签为tb
-
python 爬取英雄联盟皮肤并下载的示例
爬取结果: 爬取代码 import os import json import requests from tqdm import tqdm def lol_spider(): # 存放英雄信息 heros = [] # 存放英雄皮肤 hero_skins = [] # 获取所有英雄信息 url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js' hero_text = requests.get(url).t
-
python 爬取英雄联盟皮肤图片
一开始都是先去<英雄联盟>官网找到英雄及皮肤图片的网址: URL = r'https://lol.qq.com/data/info-heros.shtml' 从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中.这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典--里面就包含了所有英雄的名字(英文)以及对应的编号(如下图). 但是只有英雄的名字(英文)以及对应的编号并不能找到
-
Python爬取英雄联盟MSI直播间弹幕并生成词云图
一.环境准备 安装相关第三方库 pip install jieba pip install wordcloud 二.数据准备 爬取对象:2021年5月23号,RNG夺冠直播间的弹幕信息 爬取对象路径: 方式1.根据开发者工具(F12),获取请求url.请求头.cookie等信息: 方式2:根据直播地址url,前+字符i 我们这里演示的是,采用方式2. 三.代码如下 import requests, re import jieba, wordcloud """ # 以下是练习代
-
教你用Python爬取英雄联盟皮肤原画
一.推理原理 1.先去<英雄联盟>官网找到英雄及皮肤图片的网址: http://lol.qq.com/data/info-heros.shtml 2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中.这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典--里面就包含了所有英雄的名字(英文)以及对应的编号. 3.但是只有英雄的名字(英文)以及对应的编号并不能找到图片地址,于是
-
用Python爬取英雄联盟的皮肤详细示例
目录 一.推理原理 二.推理代码 第一步:获取js字典 第二步:从 js字典中提取到key值生成url列表 第三步:从 js字典中提取到value值生成name列表 第四步:下载并保存数据 第五步:执行主程序 一.推理原理 1.先去<英雄联盟>官网找到英雄及皮肤图片的网址: lol.qq.com 2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中. 这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.j
-
Python3爬取英雄联盟英雄皮肤大图实例代码
爬虫思路 初步尝试 我先查看了network,并没有发现有可用的API:然后又用bs4去分析英雄列表页,但是请求到html里面,并没有英雄列表,在英雄列表的节点上,只有"正在加载中"这样的字样:同样的方法,分析英雄详情也是这种情况,所以我猜测,这些数据应该是Javascript负责加载的. 继续尝试 然后我就查看了 英雄列表的源代码 ,查看外部引入的js文件,以及行内的js脚本,大概在368行,发现了有处理英雄列表的js注释,然后继续往下读这些代码,发现了第一个彩蛋,也就是他引入了一个
-
用Python爬取LOL所有的英雄信息以及英雄皮肤的示例代码
实现思路:分为两部分,第一部分,获取网页上数据并使用xlwt生成excel(当然你也可以选择保存到数据库),第二部分获取网页数据使用IO流将图片保存到本地 一.爬取所有英雄属性并生成excel 1.代码 import json import requests import xlwt # 设置头部信息,防止被检测出是爬虫 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (
-
python爬取安居客二手房网站数据(实例讲解)
是小打小闹 哈哈,现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧! 在上面这个页面中,我们可以看到一条条的房源信息,从中我们发现了什么,发现了连郑州的二手房都是这么的贵,作为即将毕业的学生狗惹不起啊惹不起 还是正文吧!!!由上可以看到网页一条条的房源信息,点击进去后就会发现: 房源的详细信息.OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说