springboot cloud使用eureka整合分布式事务组件Seata 的方法
前言
近期一直在忙项目,我也是打工仔。不多说,我们开始玩一玩seata。
正文
什么都不说,我们按照惯例,先上一个图(图里不规范的使用请忽略):
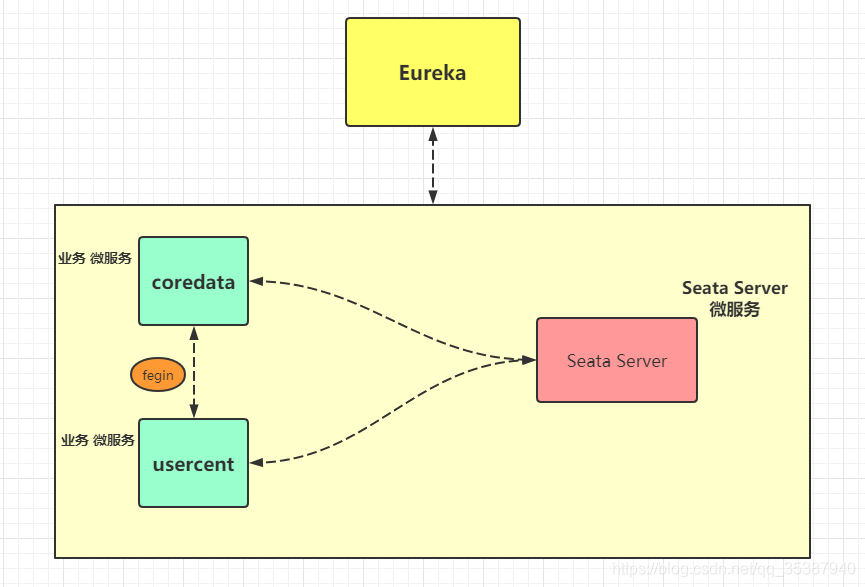
简单一眼就看出来, 比我们平时用的东西,多了 Seata Server 微服务 。
同样这个 Seata Server 微服务 ,也是需要注册到eureka上面去的。
那么我们首先就搞一搞这个 seata server ,那么剩下的就是一些原本的业务服务整合配置了。
该篇用的 seata server 版本,用的是1.4.1 , 可以去git下载下。当然,我也是给你们备了的:
seata server 1.4.1 某度网盘分享地址:
链接: https://pan.baidu.com/s/1Oj1NkKwU4jeLjJ3Pu9hT2Q
提取码: 9at6
第一步,下载下来解压 :

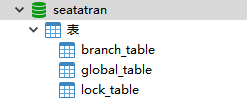
第二步,创个 seata server 用的数据库 :
CREATE TABLE `branch_table` ( `branch_id` bigint(20) NOT NULL, `xid` varchar(128) NOT NULL, `transaction_id` bigint(20) DEFAULT NULL, `resource_group_id` varchar(32) DEFAULT NULL, `resource_id` varchar(256) DEFAULT NULL, `branch_type` varchar(8) DEFAULT NULL, `status` tinyint(4) DEFAULT NULL, `client_id` varchar(64) DEFAULT NULL, `application_data` varchar(2000) DEFAULT NULL, `gmt_create` datetime DEFAULT NULL, `gmt_modified` datetime DEFAULT NULL, PRIMARY KEY (`branch_id`), KEY `idx_xid` (`xid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `global_table` ( `xid` varchar(128) NOT NULL, `transaction_id` bigint(20) DEFAULT NULL, `status` tinyint(4) NOT NULL, `application_id` varchar(32) DEFAULT NULL, `transaction_service_group` varchar(32) DEFAULT NULL, `transaction_name` varchar(128) DEFAULT NULL, `timeout` int(11) DEFAULT NULL, `begin_time` bigint(20) DEFAULT NULL, `application_data` varchar(2000) DEFAULT NULL, `gmt_create` datetime DEFAULT NULL, `gmt_modified` datetime DEFAULT NULL, PRIMARY KEY (`xid`), KEY `idx_gmt_modified_status` (`gmt_modified`,`status`), KEY `idx_transaction_id` (`transaction_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `lock_table` ( `row_key` varchar(128) NOT NULL, `xid` varchar(96) DEFAULT NULL, `transaction_id` bigint(20) DEFAULT NULL, `branch_id` bigint(20) NOT NULL, `resource_id` varchar(256) DEFAULT NULL, `table_name` varchar(32) DEFAULT NULL, `pk` varchar(36) DEFAULT NULL, `gmt_create` datetime DEFAULT NULL, `gmt_modified` datetime DEFAULT NULL, PRIMARY KEY (`row_key`), KEY `idx_branch_id` (`branch_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
创建完后:
第三步,修改下 \seata-1.4.1\seata-server-1.4.1\seata\conf 里的配置文件一些信息 :
1. registry.conf



ok,registry.conf 这文件就修改这些配置项。
2. file.conf :
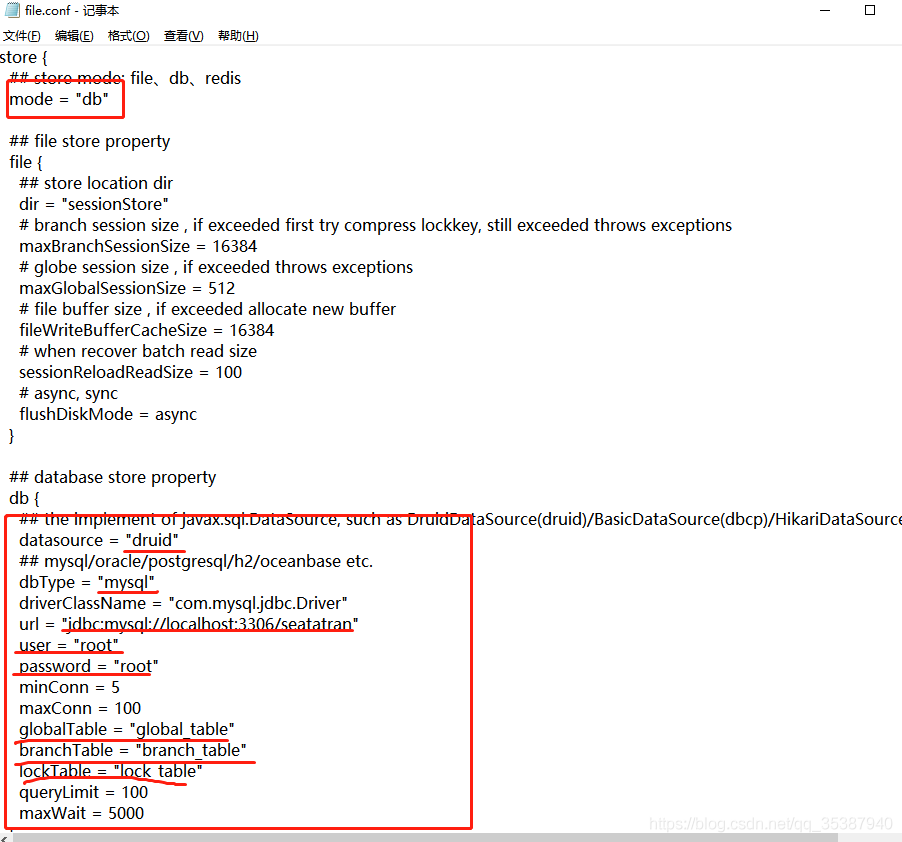
以上两个文件配置完(记得保存), 我们先把我们的注册中心 eureka服务跑起来,然后点击启动 seata server:

可以看到启动成功(前提是eureka已经启动):

第三步 ,配置我们需要用到 分布式事务 seata组件的 微服务 :
我这里的示例实践,需要用到的有2个微服务 :
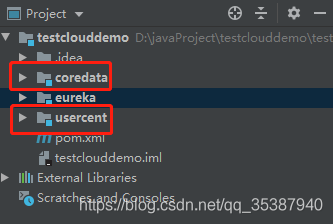
那么我们这两个微服务都需要做点什么呢?
1. 在对应的微服务的对应的不同数据库里(只要你想用上seata的), 都加上undo_log 这个表:

SQL语句:
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for undo_log -- ---------------------------- DROP TABLE IF EXISTS `undo_log`; CREATE TABLE `undo_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime(0) NULL, `log_modified` datetime(0) NULL, PRIMARY KEY (`id`) USING BTREE, UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1;
2. 关键步骤了 , 导入jar包 (需要用到seata组件都服务都需要导入)
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-seata</artifactId> <version>2.1.0.RELEASE</version> <exclusions> <exclusion> <artifactId>seata-all</artifactId> <groupId>io.seata</groupId> </exclusion> </exclusions> </dependency> <dependency> <artifactId>seata-all</artifactId> <groupId>io.seata</groupId> <version>1.4.1</version> </dependency>
3.更加关键了,就是做配置
先总得了解下,需要用到seata的 微服务需要做些什么配置 ?
1. 在resources 下 新增2个配置文件 , file.conf 和 registry.conf
2.yml 新增配置seata 事务组参数
3.代码调整数据源代理,交给seata代理
1. registry.conf

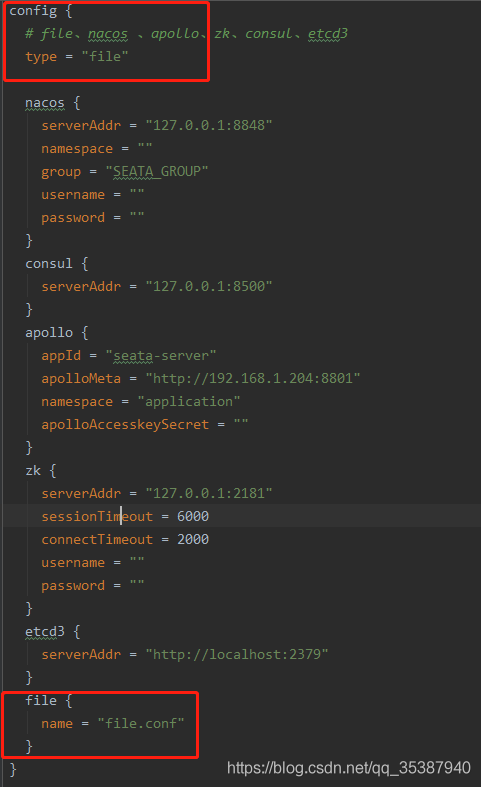
以上是业务微服务里的registry.conf 需要改动的配置信息 ,给出一份该篇文章使用的:
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "eureka"
loadBalance = "RandomLoadBalance"
loadBalanceVirtualNodes = 10
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "SEATA_GROUP"
namespace = ""
cluster = "default"
username = ""
password = ""
}
eureka {
serviceUrl = "http://localhost:8761/eureka/"
application = "seata-server"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = 0
password = ""
cluster = "default"
timeout = 0
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
sessionTimeout = 6000
connectTimeout = 2000
username = ""
password = ""
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "file"
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = ""
password = ""
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
appId = "seata-server"
apolloMeta = "http://192.168.1.204:8801"
namespace = "application"
apolloAccesskeySecret = ""
}
zk {
serverAddr = "127.0.0.1:2181"
sessionTimeout = 6000
connectTimeout = 2000
username = ""
password = ""
}
etcd3 {
serverAddr = "http://localhost:2379"
}
file {
name = "file.conf"
}
}
file.conf

给出一份该篇使用的完整的:
transport {
# tcp udt unix-domain-socket
type = "TCP"
#NIO NATIVE
server = "NIO"
#enable heartbeat
heartbeat = true
# the client batch send request enable
enableClientBatchSendRequest = true
#thread factory for netty
threadFactory {
bossThreadPrefix = "NettyBoss"
workerThreadPrefix = "NettyServerNIOWorker"
serverExecutorThread-prefix = "NettyServerBizHandler"
shareBossWorker = false
clientSelectorThreadPrefix = "NettyClientSelector"
clientSelectorThreadSize = 1
clientWorkerThreadPrefix = "NettyClientWorkerThread"
# netty boss thread size,will not be used for UDT
bossThreadSize = 1
#auto default pin or 8
workerThreadSize = "default"
}
shutdown {
# when destroy server, wait seconds
wait = 3
}
serialization = "seata"
compressor = "none"
}
service {
#这里注意,等号前后都是配置,前面是yml里配置的事务组,后面是register.conf里定义的seata-server
vgroupMapping.test_tx_group = "seata-server"
#only support when registry.type=file, please don't set multiple addresses
seata_tc_server.grouplist = "127.0.0.1:8091"
#degrade, current not support
enableDegrade = false
#disable seata
disableGlobalTransaction = false
}
client {
rm {
asyncCommitBufferLimit = 10000
lock {
retryInterval = 10
retryTimes = 30
retryPolicyBranchRollbackOnConflict = true
}
reportRetryCount = 5
tableMetaCheckEnable = false
reportSuccessEnable = false
}
tm {
commitRetryCount = 5
rollbackRetryCount = 5
}
undo {
dataValidation = true
logSerialization = "jackson"
logTable = "undo_log"
}
log {
exceptionRate = 100
}
}
2. 需要在yml配置文件加上配置项,指明当前服务使用了 seata分布式事务组件,且需要加入的分布式事务组是哪个:

spring:
cloud:
alibaba:
seata.tx-service-group: test_tx_group
3.然后是需要将数据源交给seata去代理:
去掉默认自动加载数据源
配置dao层扫描位置
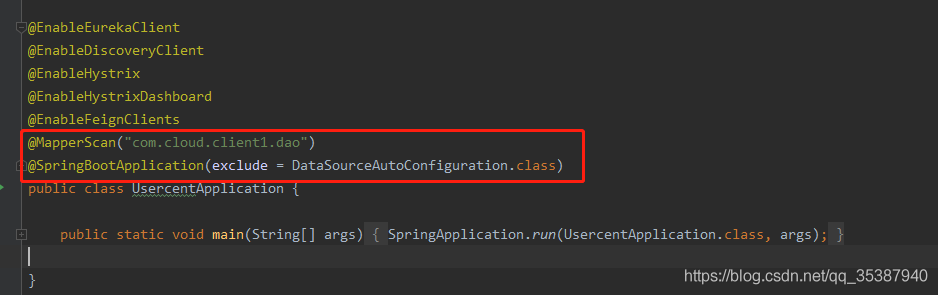
@MapperScan("com.cloud.client1.dao")
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
然后是seata代理数据源(红色标注的地方需要注意下,都是实打实踩出来的坑。导入类的来源以及扫描的mapper的xml位置):
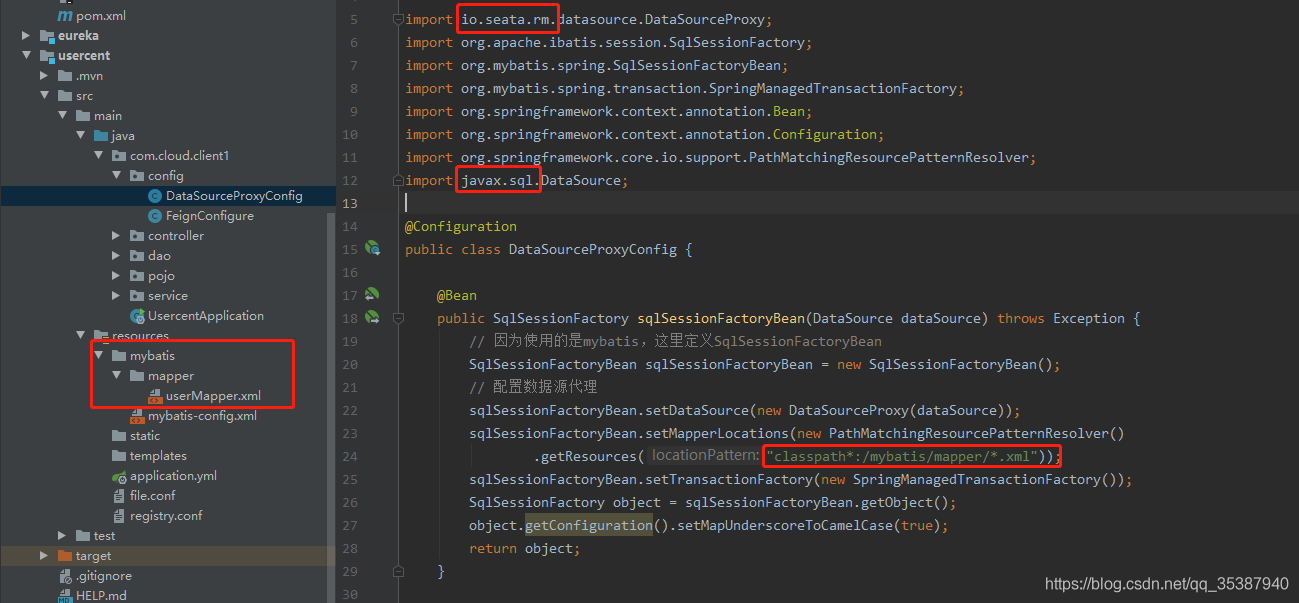
ok,到这里一个微服务 usercent的 整合 seata 分布式组件算是完成了。
同样,我们继续对 另外一个微服务 coredata 做seata 分布式组件 整合 。
也是第一步,file.conf 和 registry.conf (其实我们现在就是让这两个微服务在同一个分布式事务组,我们直接把刚才在usercent那边的两个文件直接粘贴过来就好)。
然后第二步就是修改yml配置:

第三步就是新增seata数据源代理、application上的注解排除自动加载数据源和扫描dao层地址,yml上面的配置项:
完事,两个业务微服务都整合了 分布式事务组件 seata ,而且都设置在同个分布式事务组里 (test_tx_group).
那么到这其实已经完事了, 接下来玩下 分布式事务回滚场景 的例子 (怎么去使用)。
我该篇就不弄太多服务了,就弄了2个分布式服务。
展示的例子内容 :
1. 上游服务 出错, 触发分布式事务, 上下游服务都会事务回滚;
2.下游服务 出错,触发分布式事务, 上下游服务都会事务回滚;(某种程度上讲,下游出错如果只有一个下游,其实不需分布式事务,通过错误传递单个回滚也是可以的。但是如果服务调用链很长,中游服务出错,需要整个链上的服务都事务回滚,那么就有必要都使用seata )

我们开始模拟:
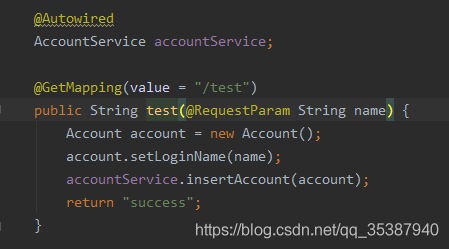
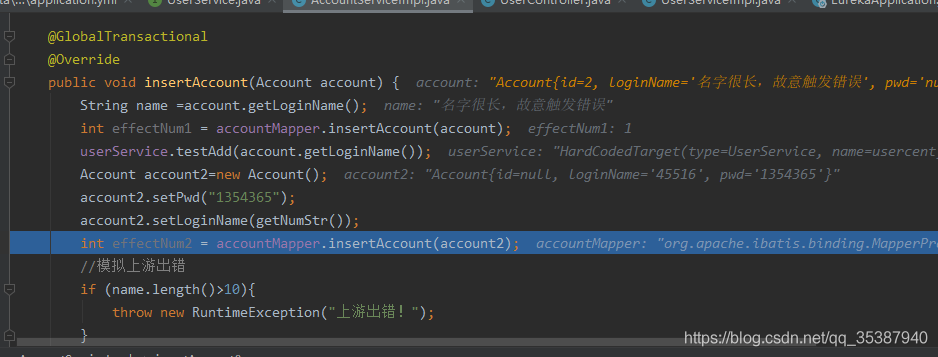
第一个场景 上游服务 coredata 使用seata全局事务注解@GlobalTransactional 标记方法,先插入一个Account数据 ;然后调用下游服务 usercent 插入一条数据;
然后 上游服务 coredata继续执行业务逻辑,继续插入数据;
接着模拟上游服务coredata开始报错(我们通过name长度故意触发错误);
期望结果: 上下游两个服务 在当前方法事务下插入的数据都回滚!
上游服务 coredata 方法:

通过fegin调用下游服务 usercent 方法:
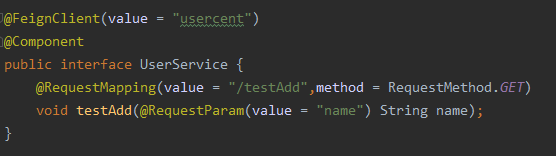
下游服务 usercent 的插入方法:

开始模拟:
1.先把eureka跑起来:

暂时就注册中心自己,没有别的服务:

2.把seata server 服务跑起来,注册到eureka上去:
我是window环境,执行.bat
可以看到已经成功注册到eureka上了:

3. 把上游微服务 coredata 和 下游服务 usercent 都跑起来:

然后看下seata server上,也可以看到 两个服务 都成功‘注册'到了 seata server上了,而且都在同一个事务组 test_tx_group里面:

接下来,就是开始调用一下我们模拟的场景代码就完事了(不过我会加点图来给大家简单分析下):
一开始,都是没有数据的:

调用上游服务coredata接口触发一下整个流程:
调用开始:
我们打断点到 上游已经插入过一次数据,下游也插入过一次数据,
可以看到上游服务和下游服务的数据库里面的undo_log表出现了 事务记录,有关当前事务的 branch_id和 所在事务 xid,而且可以看到在两个服务内的undo_log表中记录的xid都是一致的,代表他们都在一个事务中:


然后我们继续往下执行,故意让上游报错:
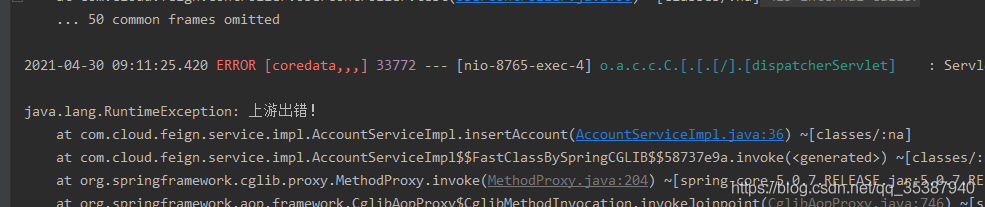
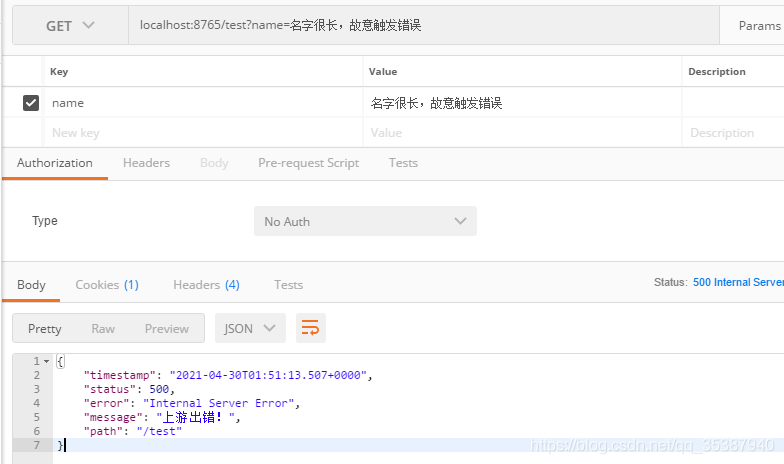
这时候,接口调用完毕结束:我们看到seata server里面的信息,可以看到全局事务 xid为22080结尾,回滚成功:

回滚成功后,undo_log表中的记录会删除掉:

当然我们两个服务里面也是没有数据的,因为回滚了:
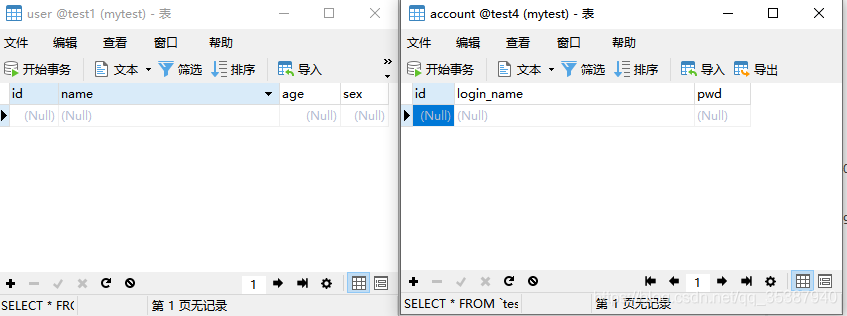
这里可能有人会想,你查一下是空就能证明是回滚了么?
这时候我们也可以利用主键自增当前值可以看到确实发生了数据回滚的场景:

第一个场景就到此吧。
接下来我们模拟第二个场景:
上游服务 coredata 使用seata全局事务注解@GlobalTransactional 标记方法,先插入一个Account数据 ;然后调用下游服务 usercent 插入一条数据;
然后下游服务 直接模拟出错, 这样触发事务回滚。 期望结果: 上下游两个服务 在当前方法事务下插入的数据都回滚!
也就是说我们需要对下游服务的插入方法里面做手脚,故意抛出错误:

快速调用一下:
可以看到下游出错了:

看下我们的seata server怎么说,已出发分布式事务,回滚成功:

数据库里面的数据也是回滚了,空的:
好了,该篇springboot cloud使用eureka整合 分布式事务组件 Seata 就到此吧。
ps: 最近比较忙,每篇文章其实都是用一些零碎时间拼凑出来的。不过我会坚持我的文章的初衷,能让大家跟着实践,能搞懂,能学会。我...只是个散工。
到此这篇关于SpringCloud 整合分布式事务组件 Seata的文章就介绍到这了,更多相关SpringCloud 整合分布式内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Springcloud seata分布式事务实现代码解析
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务.本篇不涉及其原理,只用代码构建项目简单试用一下其回滚的机制. 大致上seata分为TC,TM,RM三大构建成整体.它们之间的包含关系如下.即一(xid主键编码,记录信息)带三(TC,TM,RM) 下面之间构建项目进行测试. 1.下载seata并解压,然后改动配置文件. http://seata.io/zh-cn/blog/download.html官网下载. 解压之后到conf中修改file和registry
-
Springcloud seata nacos环境搭建过程图解
最近学习了一下seata,由于nacos现在也挺火,于是学习了seata注册到nacos,然后集成springcloud 1.nacos配置(自行上官网下载) 将nacos/conf/nacos-mysql.sql导入自己的数据库 2.配置修改nacos/conf/application.properties spring.datasource.platform=mysql db.num=1 db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?character
-
SpringCloud之分布式配置中心Spring Cloud Config高可用配置实例代码
一.简介 当要将配置中心部署到生产环境中时,与服务注册中心一样,我们也希望它是一个高可用的应用.Spring Cloud Config实现服务端的高可用非常简单,主要有以下两种方式. 传统模式:不需要为这些服务端做任何额外的配置,只需要遵守一个配置规则,将所有的Config Server都指向同一个Git仓库,这样所有的配置内容就通过统一的共享文件系统来维护.而客户端在指定Config Server位置时,只需要配置Config Server上层的负载均衡设备地址即可, 就如下图所示的结构. 服
-
SpringCloud整合分布式服务跟踪zipkin的实现
1.zipkin zipkin是Twitter的一个开源项目,它基于Google Dapper实现.我们可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的REST API接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源.除了面向开发的API接口之外,它也提供了方便的UI组件来帮助我们直观的搜索跟踪信息和分析请求链路明细,比如:可以查询某段时间内各用户请求的处理时间等. zipkin的架构图如下: 由上面的架构图可以
-
seata-1.4.0安装及在springcloud中使用详解
seata-1.4.0安装及使用 1.简介 Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务.Seata 将为用户提供了 AT.TCC.SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案. 详见官方文档:https://seata.io/zh-cn/docs/overview/what-is-seata.html 网上的多是0.9.0版本的安装方式,这里记录安装seata-1.4.0版本的方式,在win10环境下安装,centos7与此相同. 下
-
springboot cloud使用eureka整合分布式事务组件Seata 的方法
前言 近期一直在忙项目,我也是打工仔.不多说,我们开始玩一玩seata. 正文 什么都不说,我们按照惯例,先上一个图(图里不规范的使用请忽略): 简单一眼就看出来, 比我们平时用的东西,多了 Seata Server 微服务 . 同样这个 Seata Server 微服务 ,也是需要注册到eureka上面去的. 那么我们首先就搞一搞这个 seata server ,那么剩下的就是一些原本的业务服务整合配置了. 该篇用的 seata server 版本,用的是1.4.1 , 可以去git下载下.当
-
Spring Cloud + Nacos + Seata整合过程(分布式事务解决方案)
目录 一.简介 二.seata-server部署 1.官网下载 2.解压到本地 3.修改配置文件 4.seata数据库初始化 5.业务数据库 6.启动seata-server 三.微服务项目集成Seata 1.引入依赖 2.配置文件 一.简介 Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务. 2019 年 1 月,阿里巴巴中间件团队发起了开源项目 Fescar(Fast & EaSy Commit And Rollback),和社区
-
springboot整合shardingsphere和seata实现分布式事务的实践
各个框架版本信息 springboot: 2.1.3 springcloud: Greenwich.RELEASE seata: 1.0.0 shardingsphere:4.0.1 maven 依赖 <dependency> <!--<groupId>io.shardingsphere</groupId>--> <groupId>org.apache.shardingsphere</group
-
springboot整合rocketmq实现分布式事务
1 执行流程 (1) 发送方向 MQ 服务端发送消息. (2) MQ Server 将消息持久化成功之后,向发送方 ACK 确认消息已经发送成功,此时消息为半消息. (3) 发送方开始执行本地事务逻辑. (4) 发送方根据本地事务执行结果向 MQ Server 提交二次确认(Commit 或是 Rollback),MQ Server 收到Commit 状态则将半消息标记为可投递,订阅方最终将收到该消息:MQ Server 收到 Rollback 状态则删除半消息,订阅方将不会接受该消息. (5)
-
详解SpringBoot基于Dubbo和Seata的分布式事务解决方案
1. 分布式事务初探 一般来说,目前市面上的数据库都支持本地事务,也就是在你的应用程序中,在一个数据库连接下的操作,可以很容易的实现事务的操作. 但是目前,基于SOA的思想,大部分项目都采用微服务架构后,就会出现了跨服务间的事务需求,这就称为分布式事务. 本文假设你已经了解了事务的运行机制,如果你不了解事务,那么我建议先去看下事务相关的文章,再来阅读本文. 1.1 什么是分布式事务 对于传统的单体应用而言,实现本地事务可以依赖Spring的@Transactional注解标识方法,实现事务非常简
-
java SpringBoot 分布式事务的解决方案(JTA+Atomic+多数据源)
目录 前言 一.项目依赖 二.数据源配置 三.数据源的注册 四.配置数据源对应的sqlSessionFactory 五.测试接口 六.建立JtaTestContoller.java 七.在test.ftl中增加一个按钮来测试 八.启动服务,验证结果 前言 首先,到底啥是分布式事务呢,比如我们在执行一个业务逻辑的时候有两步分别操作A数据源和B数据源,当我们在A数据源执行数据更改后,在B数据源执行时出现运行时异常,那么我们必须要让B数据源的操作回滚,并回滚对A数据源的操作:这种情况在支付业务时常常出
-
spring整合atomikos实现分布式事务的方法示例
前言 Atomikos 是一个为Java平台提供增值服务的并且开源类事务管理器,主要用于处理跨数据库事务,比如某个指令在A库和B库都有写操作,业务上要求A库和B库的写操作要具有原子性,这时候就可以用到atomikos.笔者这里整合了一个spring和atomikos的demo,并且通过案例演示说明atomikos的作用. 准备工作 开发工具:idea 数据库:mysql , oracle 正文 源码地址: https://github.com/qw870602/atomikos 演示原理:通过在
-
SpringBoot+Dubbo+Seata分布式事务实战详解
前言 Seata 是 阿里巴巴开源的分布式事务中间件,以高效并且对业务0侵入的方式,解决微服务场景下面临的分布式事务问题. 事实上,官方在GitHub已经给出了多种环境下的Seata应用示例项目,地址:https://github.com/seata/seata-samples. 为什么笔者要重新写一遍呢,主要原因有两点: 官网代码示例中,依赖太多,分不清哪些有什么作用 Seata相关资料较少,笔者在搭建的过程中,遇到了一些坑,记录一下 一.环境准备 本文涉及软件环境如下: SpringBoot
-
详解IDEA中SpringBoot整合Servlet三大组件的过程
Spring MVC整合 SpringBoot提供为整合MVC框架提供的功能特性 内置两个视图解析器:ContentNegotiatingViewResolver和BeanNameViewResolver 支持静态资源以及WebJars 自动注册了转换器和格式化器 支持Http消息转换器 自动注册了消息代码解析器 支持静态项目首页index.html 支持定制应用图标favicon.ico 自动初始化Web数据绑定器:ConfigurableWebBindingInitializer Sprin
-
Spring Cloud引入Eureka组件,完善服务治理
简介 Netflix Eureka 是一款由 Netflix 开源的基于 REST 服务的注册中心,用于提供服务发现功能.Spring Cloud Eureka 是 Spring Cloud Netflix 微服务套件的一部分,基于 Netflix Eureka 进行了二次封装,主要负责完成微服务架构中的服务治理功能. Spring Cloud Eureka 是一个基于 REST 的服务,并提供了基于 Java 的客户端组件,能够非常方便的将服务注册到 Spring Cloud Eureka 中