这一次搞懂Spring的XML解析原理说明
前言
Spring已经是我们Java Web开发必不可少的一个框架,其大大简化了我们的开发,提高了开发者的效率。同时,其源码对于开发者来说也是宝藏,从中我们可以学习到非常优秀的设计思想以及优雅的命名规范,但因其体系庞大、设计复杂对于刚开始阅读源码的人来说是非常困难的。所以在此之前首先你得下定决心,不管有多困难都得坚持下去;其次,最好先把设计模式掌握熟练;然后在开始阅读源码时一定要多画UML类图和时序图,多问自己为什么要这么设计?这样设计的好处是什么?还有没有更好的设计?当然,晕车是难免的,但还是那句话,一定要持之以恒(PS:源码版本5.1.3.RELEASE)。
正文
熟悉IOC体系结构
要学习Spring源码,我们首先得要找准入口,那这个入口怎么找呢?我们不妨先思考一下,在Spring项目启动时,Spring做了哪些事情。这里我以最原始的xml配置方式来分析,那么在项目启动时,首先肯定要先定位——找到xml配置文件,定位之后肯定是加载——将我们的配置加载到内存,最后才是根据我们的配置实例化(本篇文章只讲前两个过程)。那么Spring是如何定位和加载xml文件的呢?涉及到哪些类呢?我们先来看张类图:
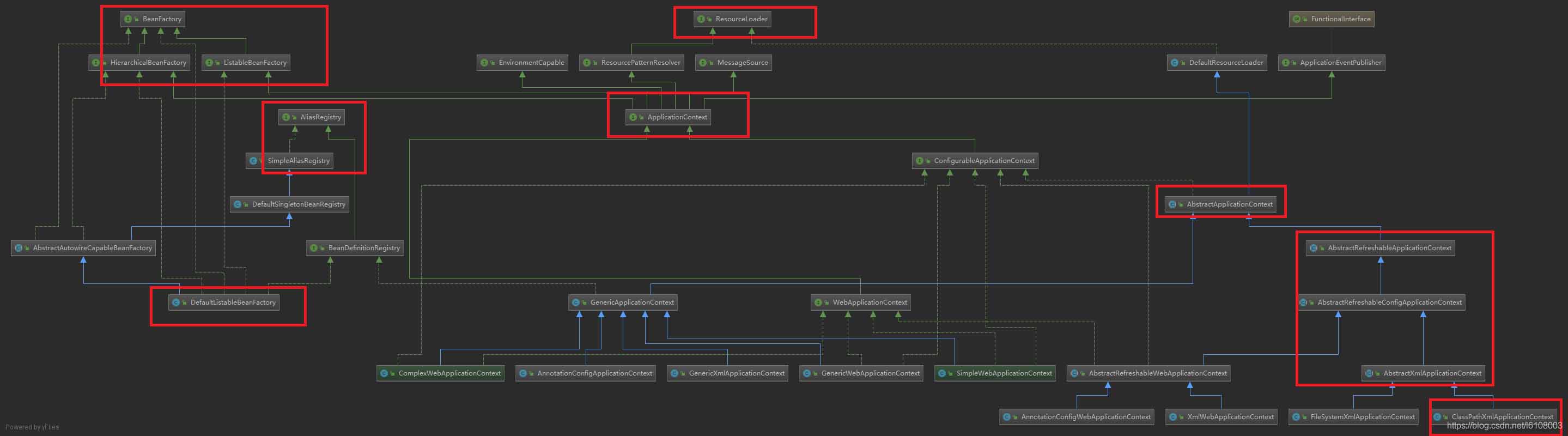
该图是IOC的体系图,整体上你需要有一个大概的印象,可以看到所有的IOC都是有继承关系的,这样设计的好处就是任何一个子类IOC可以直接使用父类IOC加载的Bean,有点像JVM类加载的双亲委派机制;而红色方框圈起来的是本篇涉及到的重要类,需要着重记忆它们的关系。
图中最重要的两个类是BeanFactory和ApplicationContext,这是所有IOC的父接口。其中BeanFactory提供了最基本的对bean的操作:

而ApplicationContex继承了BeanFactory,同时还继承了MessageSource、ResourceLoader、ApplicationEventPublisher等接口以提供国际化、资源加载、事件发布等高级功能。我们应该想到平时Spring加载xml文件应该是ApplicationContext的子类,从图中我们可以看到一个叫ClassPathXmlApplicationContext的类,联想到我们平时都会 将xml放到classPath下,所以我们直接从这个类开始就行,这就是优秀命名的好处。
探究配置加载的过程
在ClassPathXmlApplicationContext中有很多构造方法,其中有一个是传入一个字符串的(即配置文件的相对路径),但最终是调用的下面这个构造:
public ClassPathXmlApplicationContext(
String[] configLocations, boolean refresh, @Nullable ApplicationContext parent)
throws BeansException {
super(parent);
//创建解析器,解析configLocations
setConfigLocations(configLocations);
if (refresh) {
refresh();
}
}
首先调用父类构造器设置环境:
public AbstractApplicationContext(@Nullable ApplicationContext parent) {
this();
setParent(parent);
}
public void setParent(@Nullable ApplicationContext parent) {
this.parent = parent;
if (parent != null) {
Environment parentEnvironment = parent.getEnvironment();
if (parentEnvironment instanceof ConfigurableEnvironment) {
getEnvironment().merge((ConfigurableEnvironment) parentEnvironment);
}
}
}
然后解析传入的相对路径保存到configLocations变量中,最后再调用父类AbstractApplicationContext的refresh方法刷新容器(启动容器都会调用该方法),我们着重来看这个方法:
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
//为容器初始化做准备
prepareRefresh();
// 解析xml
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
这个方法是一个典型的模板方法模式的实现,第一步是准备初始化容器环境,这一步不重要,重点是第二步,创建BeanFactory对象、加载解析xml并封装成BeanDefinition对象都是在这一步完成的。
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {
refreshBeanFactory();
return getBeanFactory();
}
点进去看是调用了refreshBeanFactory方法,但这里有两个实现,应该进哪一个类里面呢?

如果你还记得前面的继承体系,那你就会毫不犹豫的进入AbstractRefreshableApplicationContext类中,所以在阅读源码的过程中一定要记住类的继承体系。
protected final void refreshBeanFactory() throws BeansException {
//如果BeanFactory不为空,则清除BeanFactory和里面的实例
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
//创建DefaultListableBeanFactory
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
//设置是否可以循环依赖 allowCircularReferences
//是否允许使用相同名称重新注册不同的bean实现.
customizeBeanFactory(beanFactory);
//解析xml,并把xml中的标签封装成BeanDefinition对象
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
在这个方法中首先会清除掉上一次创建的BeanFactory和对象实例,然后创建了一个DefaultListableBeanFactory对象并传入到了loadBeanDefinitions方法中,这也是一个模板方法,因为我们的配置不止有xml,还有注解等,所以这里我们应该进入AbstractXmlApplicationContext类中:
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
//创建xml的解析器,这里是一个委托模式
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// Configure the bean definition reader with this context's
// resource loading environment.
beanDefinitionReader.setEnvironment(this.getEnvironment());
//这里传一个this进去,因为ApplicationContext是实现了ResourceLoader接口的
beanDefinitionReader.setResourceLoader(this);
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// Allow a subclass to provide custom initialization of the reader,
// then proceed with actually loading the bean definitions.
initBeanDefinitionReader(beanDefinitionReader);
//主要看这个方法
loadBeanDefinitions(beanDefinitionReader);
}
首先创建了一个XmlBeanDefinitionReader对象,见名知意,这个就是解析xml的类,需要注意的是该类的构造方法接收的是BeanDefinitionRegistry对象,而这里将DefaultListableBeanFactory对象传入了进去(别忘记了这个对象是实现了BeanDefinitionRegistry类的),如果你足够敏感,应该可以想到后面会委托给该类去注册。注册什么呢?自然是注册BeanDefintion。记住这个猜想,我们稍后来验证是不是这么回事。
接着进入loadBeanDefinitions方法获取之前保存的xml配置文件路径,并委托给XmlBeanDefinitionReader对象解析加载:
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
Resource[] configResources = getConfigResources();
if (configResources != null) {
reader.loadBeanDefinitions(configResources);
}
//获取需要加载的xml配置文件
String[] configLocations = getConfigLocations();
if (configLocations != null) {
reader.loadBeanDefinitions(configLocations);
}
}
最后会进入到抽象父类AbstractBeanDefinitionReader中:
public int loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources) throws BeanDefinitionStoreException {
// 这里获取到的依然是DefaultListableBeanFactory对象
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader == null) {
throw new BeanDefinitionStoreException(
"Cannot load bean definitions from location [" + location + "]: no ResourceLoader available");
}
if (resourceLoader instanceof ResourcePatternResolver) {
// Resource pattern matching available.
try {
//把字符串类型的xml文件路径,形如:classpath*:user/**/*-context.xml,转换成Resource对象类型,其实就是用流
//的方式加载配置文件,然后封装成Resource对象
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
//主要看这个方法
int count = loadBeanDefinitions(resources);
if (actualResources != null) {
Collections.addAll(actualResources, resources);
}
if (logger.isTraceEnabled()) {
logger.trace("Loaded " + count + " bean definitions from location pattern [" + location + "]");
}
return count;
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"Could not resolve bean definition resource pattern [" + location + "]", ex);
}
}
else {
// Can only load single resources by absolute URL.
Resource resource = resourceLoader.getResource(location);
int count = loadBeanDefinitions(resource);
if (actualResources != null) {
actualResources.add(resource);
}
if (logger.isTraceEnabled()) {
logger.trace("Loaded " + count + " bean definitions from location [" + location + "]");
}
return count;
}
}
这个方法中主要将xml配置加载到存中并封装成为Resource对象,这一步不重要,可以略过,主要的还是loadBeanDefinitions方法,最终还是调用到子类XmlBeanDefinitionReader的方法:
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
try {
//获取Resource对象中的xml文件流对象
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
//InputSource是jdk中的sax xml文件解析对象
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
//主要看这个方法
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
}
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
//把inputSource 封装成Document文件对象,这是jdk的API
Document doc = doLoadDocument(inputSource, resource);
//主要看这个方法,根据解析出来的document对象,拿到里面的标签元素封装成BeanDefinition
int count = registerBeanDefinitions(doc, resource);
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + count + " bean definitions from " + resource);
}
return count;
}
}
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
// 创建DefaultBeanDefinitionDocumentReader对象,并委托其做解析注册工作
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
//主要看这个方法,需要注意createReaderContext方法中创建的几个对象
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}
public XmlReaderContext createReaderContext(Resource resource) {
// XmlReaderContext对象中保存了XmlBeanDefinitionReader对象和DefaultNamespaceHandlerResolver对象的引用,在后面会用到
return new XmlReaderContext(resource, this.problemReporter, this.eventListener,
this.sourceExtractor, this, getNamespaceHandlerResolver());
}
接着看看DefaultBeanDefinitionDocumentReader中是如何解析的:
protected void doRegisterBeanDefinitions(Element root) {
// 创建了BeanDefinitionParserDelegate对象
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
// 如果是Spring原生命名空间,首先解析 profile标签,这里不重要
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
// We cannot use Profiles.of(...) since profile expressions are not supported
// in XML config. See SPR-12458 for details.
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isDebugEnabled()) {
logger.debug("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
preProcessXml(root);
//主要看这个方法,标签具体解析过程
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
}
在这个方法中重点关注preProcessXml、parseBeanDefinitions、postProcessXml三个方法,其中preProcessXml和postProcessXml都是空方法,意思是在解析标签前后我们自己可以扩展需要执行的操作,也是一个模板方法模式,体现了Spring的高扩展性。然后进入parseBeanDefinitions方法看具体是怎么解析标签的:
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
//默认标签解析
parseDefaultElement(ele, delegate);
}
else {
//自定义标签解析
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
这里有两种标签的解析:Spring原生标签和自定义标签。怎么区分这两种标签呢?
// 自定义标签 <context:component-scan/> // 默认标签 <bean:/>
如上,带前缀的就是自定义标签,否则就是Spring默认标签,无论哪种标签在使用前都需要在Spring的xml配置文件里声明Namespace URI,这样在解析标签时才能通过Namespace URI找到对应的NamespaceHandler。
xmlns:context="http://www.springframework.org/schema/context"
http://www.springframework.org/schema/beans
isDefaultNamespace判断是不是默认标签,点进去看看是不是跟我上面说的一致:
public boolean isDefaultNamespace(Node node) {
return isDefaultNamespace(getNamespaceURI(node));
}
public static final String BEANS_NAMESPACE_URI = "http://www.springframework.org/schema/beans";
public boolean isDefaultNamespace(@Nullable String namespaceUri) {
return (!StringUtils.hasLength(namespaceUri) || BEANS_NAMESPACE_URI.equals(namespaceUri));
}
可以看到http://www.springframework.org/schema/beans所对应的就是默认标签。接着,我们进入parseDefaultElement方法:
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
//import标签解析
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
//alias标签解析
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
//bean标签
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}
这里面主要是对import、alias、bean标签的解析以及beans的字标签的递归解析,主要看看bean标签的解析:
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
// 解析elment封装为BeanDefinitionHolder对象
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
// 该方法功能不重要,主要理解设计思想:装饰者设计模式以及SPI设计思想
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// 完成document到BeanDefinition对象转换后,对BeanDefinition对象进行缓存注册
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {
// 获取id和name属性
String id = ele.getAttribute(ID_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
// 获取别名属性,多个别名可用,;隔开
List<String> aliases = new ArrayList<>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isTraceEnabled()) {
logger.trace("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
//检查beanName是否重复
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
// 具体的解析封装过程还在这个方法里
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
if (!StringUtils.hasText(beanName)) {
try {
if (containingBean != null) {
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
} else {
beanName = this.readerContext.generateBeanName(beanDefinition);
// Register an alias for the plain bean class name, if still possible,
// if the generator returned the class name plus a suffix.
// This is expected for Spring 1.2/2.0 backwards compatibility.
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
if (logger.isTraceEnabled()) {
logger.trace("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
} catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}
// bean的解析
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, @Nullable BeanDefinition containingBean) {
this.parseState.push(new BeanEntry(beanName));
// 获取class名称和父类名称
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
try {
// 创建GenericBeanDefinition对象
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
// 解析bean标签的属性,并把解析出来的属性设置到BeanDefinition对象中
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
//解析bean中的meta标签
parseMetaElements(ele, bd);
//解析bean中的lookup-method标签
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
//解析bean中的replaced-method标签
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
//解析bean中的constructor-arg标签
parseConstructorArgElements(ele, bd);
//解析bean中的property标签
parsePropertyElements(ele, bd);
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}
return null;
}
bean标签的解析步骤仔细理解并不复杂,就是将一个个标签属性的值装入到了BeanDefinition对象中,这里需要注意parseConstructorArgElements和parsePropertyElements方法,分别是对constructor-arg和property标签的解析,解析完成后分别装入了BeanDefinition对象的constructorArgumentValues和propertyValues中,而这两个属性在接下来c和p标签的解析中还会用到,而且还涉及一个很重要的设计思想——装饰器模式。
Bean标签解析完成后将生成的BeanDefinition对象、bean的名称以及别名一起封装到了BeanDefinitionHolder对象并返回,然后调用了decorateBeanDefinitionIfRequired进行装饰:
public BeanDefinitionHolder decorateBeanDefinitionIfRequired(
Element ele, BeanDefinitionHolder definitionHolder, @Nullable BeanDefinition containingBd) {
BeanDefinitionHolder finalDefinition = definitionHolder;
//根据bean标签属性装饰BeanDefinitionHolder,比如<bean class="xx" p:username="dark"/>
NamedNodeMap attributes = ele.getAttributes();
for (int i = 0; i < attributes.getLength(); i++) {
Node node = attributes.item(i);
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
//根据bean标签子元素装饰BeanDefinitionHolder\
NodeList children = ele.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node node = children.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
}
return finalDefinition;
}
在这个方法中分别对Bean标签的属性和子标签迭代,获取其中的自定义标签进行解析,并装饰之前创建的BeanDefinition对象,如同下面的c和p:
// c:和p:表示通过构造器和属性的setter方法给属性赋值,是constructor-arg和property的简化写法
<bean class="com.dark.bean.Student" id="student" p:username="Dark" p:password="111" c:age="12" c:sex="1"/>
两个步骤是一样的,我们点进decorateIfRequired方法中:
public BeanDefinitionHolder decorateIfRequired(
Node node, BeanDefinitionHolder originalDef, @Nullable BeanDefinition containingBd) {
//根据node获取到node的命名空间,形如:http://www.springframework.org/schema/p
String namespaceUri = getNamespaceURI(node);
if (namespaceUri != null && !isDefaultNamespace(namespaceUri)) {
// 根据配置文件获取namespaceUri对应的处理类,SPI思想
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler != null) {
//调用NamespaceHandler处理类的decorate方法,开始具体装饰过程,并返回装饰完的对象
BeanDefinitionHolder decorated =
handler.decorate(node, originalDef, new ParserContext(this.readerContext, this, containingBd));
if (decorated != null) {
return decorated;
}
}
else if (namespaceUri.startsWith("http://www.springframework.org/")) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", node);
}
else {
// A custom namespace, not to be handled by Spring - maybe "xml:...".
if (logger.isDebugEnabled()) {
logger.debug("No Spring NamespaceHandler found for XML schema namespace [" + namespaceUri + "]");
}
}
}
return originalDef;
}
这里也和我们之前说的一样,首先获取到标签对应的namespaceUri,然后通过这个Uri去获取到对应的NamespceHandler,最后再调用NamespceHandler的decorate方法进行装饰。我们先来看看获取NamespceHandler的过程,这涉及到一个非常重要的高扩展性的思想——SPI(有关SPI,在我之前的文章Dubbo——SPI及自适应扩展原理中已经详细讲解过,这里不再赘述):
public NamespaceHandler resolve(String namespaceUri) {
// 获取spring中所有jar包里面的 "META-INF/spring.handlers"文件,并且建立映射关系
Map<String, Object> handlerMappings = getHandlerMappings();
//根据namespaceUri:http://www.springframework.org/schema/p,获取到这个命名空间的处理类
Object handlerOrClassName = handlerMappings.get(namespaceUri);
if (handlerOrClassName == null) {
return null;
}
else if (handlerOrClassName instanceof NamespaceHandler) {
return (NamespaceHandler) handlerOrClassName;
}
else {
String className = (String) handlerOrClassName;
try {
Class<?> handlerClass = ClassUtils.forName(className, this.classLoader);
if (!NamespaceHandler.class.isAssignableFrom(handlerClass)) {
throw new FatalBeanException("Class [" + className + "] for namespace [" + namespaceUri +
"] does not implement the [" + NamespaceHandler.class.getName() + "] interface");
}
NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass);
//调用处理类的init方法,在init方法中完成标签元素解析类的注册
namespaceHandler.init();
handlerMappings.put(namespaceUri, namespaceHandler);
return namespaceHandler;
}
}
}
// AOP标签对应的NamespaceHandler,可以发现NamespaceHandler的作用就是管理和注册与自己相关的标签解析器
public void init() {
// In 2.0 XSD as well as in 2.1 XSD.
registerBeanDefinitionParser("config", new ConfigBeanDefinitionParser());
registerBeanDefinitionParser("aspectj-autoproxy", new AspectJAutoProxyBeanDefinitionParser());
registerBeanDefinitionDecorator("scoped-proxy", new ScopedProxyBeanDefinitionDecorator());
// Only in 2.0 XSD: moved to context namespace as of 2.1
registerBeanDefinitionParser("spring-configured", new SpringConfiguredBeanDefinitionParser());
}
看到这里我们应该就清楚了Spring是如何解析xml里的标签了以及我们如果要扩展自己的标签该怎么做。只需要创建一个我们的自定义标签和解析类,并指定它的命名空间以及NamespaceHandler,最后在META-INF/spring.handlers文件中指定命名空间和NamespaceHandler的映射关系即可,就像Spring的c和p标签一样:
http\://www.springframework.org/schema/c=org.springframework.beans.factory.xml.SimpleConstructorNamespaceHandler
http\://www.springframework.org/schema/p=org.springframework.beans.factory.xml.SimplePropertyNamespaceHandler
像这样使用SPI的思想设计我们的项目的话,当需要扩展时,不需要改动任何的代码,非常的方便优雅。
接着,我们回到handler的decorate方法,这里有三个默认的实现类:NamespaceHandlerSupport、SimpleConstructorNamespaceHandler、SimplePropertyNamespaceHandler。第一个是一个抽象类,与我们这里的流程无关,感兴趣的可自行了解,第二个和第三个则分别是c和p标签对应的NamespaceHandler,两个装饰的处理逻辑基本上是一样的,我这里进入的是SimpleConstructorNamespaceHandler类:
public BeanDefinitionHolder decorate(Node node, BeanDefinitionHolder definition, ParserContext parserContext) {
if (node instanceof Attr) {
Attr attr = (Attr) node;
String argName = StringUtils.trimWhitespace(parserContext.getDelegate().getLocalName(attr));
String argValue = StringUtils.trimWhitespace(attr.getValue());
ConstructorArgumentValues cvs = definition.getBeanDefinition().getConstructorArgumentValues();
boolean ref = false;
// handle -ref arguments
if (argName.endsWith(REF_SUFFIX)) {
ref = true;
argName = argName.substring(0, argName.length() - REF_SUFFIX.length());
}
ValueHolder valueHolder = new ValueHolder(ref ? new RuntimeBeanReference(argValue) : argValue);
valueHolder.setSource(parserContext.getReaderContext().extractSource(attr));
// handle "escaped"/"_" arguments
if (argName.startsWith(DELIMITER_PREFIX)) {
String arg = argName.substring(1).trim();
// fast default check
if (!StringUtils.hasText(arg)) {
cvs.addGenericArgumentValue(valueHolder);
}
// assume an index otherwise
else {
int index = -1;
try {
index = Integer.parseInt(arg);
}
catch (NumberFormatException ex) {
parserContext.getReaderContext().error(
"Constructor argument '" + argName + "' specifies an invalid integer", attr);
}
if (index < 0) {
parserContext.getReaderContext().error(
"Constructor argument '" + argName + "' specifies a negative index", attr);
}
if (cvs.hasIndexedArgumentValue(index)) {
parserContext.getReaderContext().error(
"Constructor argument '" + argName + "' with index "+ index+" already defined using <constructor-arg>." +
" Only one approach may be used per argument.", attr);
}
cvs.addIndexedArgumentValue(index, valueHolder);
}
}
// no escaping -> ctr name
else {
String name = Conventions.attributeNameToPropertyName(argName);
if (containsArgWithName(name, cvs)) {
parserContext.getReaderContext().error(
"Constructor argument '" + argName + "' already defined using <constructor-arg>." +
" Only one approach may be used per argument.", attr);
}
valueHolder.setName(Conventions.attributeNameToPropertyName(argName));
cvs.addGenericArgumentValue(valueHolder);
}
}
return definition;
}
很简单,拿到c标签对应的值,封装成ValueHolder,再添加到BeanDefinition的ConstructorArgumentValues属性中去,这样就装饰完成了。
讲到这里你可能会觉得,这和平时看到装饰器模式不太一样。其实,设计模式真正想要表达的是各种模式所代表的思想,而不是死搬硬套的实现,只有灵活的运用其思想才算是真正的掌握了设计模式,而装饰器模式的精髓就是动态的将属性、功能、责任附加到对象上,这样你再看这里是否是运用了装饰器的思想呢?
装饰完成后返回BeanDefinitionHolder对象并调用BeanDefinitionReaderUtils.registerBeanDefinition方法将该对象缓存起来,等待容器去实例化。这里就是将其缓存到DefaultListableBeanFactory的beanDefinitionMap属性中,自己看看代码也就明白了,我就不贴代码了。至此,Spring的XML解析原理分析完毕,下面是我画的时序图,可以对照看看:

总结
本篇是Spring源码分析的第一篇,只是分析了refresh中的obtainFreshBeanFactory方法,我们可以看到仅仅是对XML的解析和bean定义的注册缓存,Spring就做了这么多事,并考虑到了各个可能会扩展的地方,那我们平时做的项目呢?看似简单的背后是否有深入思考过呢?
以上这篇这一次搞懂Spring的XML解析原理说明就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
这一次搞懂Spring的Bean实例化原理操作
前言 前两篇文章分析了Spring XML和注解的解析原理,并将其封装为BeanDefinition对象存放到IOC容器中,而这些只是refresh方法中的其中一个步骤--obtainFreshBeanFactory,接下来就将围绕着这些BeanDefinition对象进行一系列的处理,如BeanDefinitionRegistryPostProcessor对象方法的调用.BeanFactoryPostProcessor对象方法的调用以及Bean实例的创建都离不开这些BeanDefinition
-
你所不知道的Spring的@Autowired实现细节分析
前言 相信很多Java开发都遇到过一个面试题:Resource和Autowired的区别是什么?这个问题的答案相信基本都清楚,但是这两者在Spring中是如何实现的呢?这就要分析Spring源码才能知道了.友情提示:本篇主要是讲解Autowired的实现原理,不会分析Spring初始化的过程,不熟悉的读者可以先阅读笔者之前的一篇文章<这一次搞懂Spring的Bean实例化原理>. 正文 在Spring Bean的整个创建过程中会调用很多BeanPostProcessor接口的的实现类: 上图是
-
这一次搞懂Spring事务注解的解析方式
前言 事务我们都知道是什么,而Spring事务就是在数据库之上利用AOP提供声明式事务和编程式事务帮助我们简化开发,解耦业务逻辑和系统逻辑.但是Spring事务原理是怎样?事务在方法间是如何传播的?为什么有时候事务会失效?接下来几篇文章将重点分析Spring事务源码,让我们彻底搞懂Spring事务的原理. 正文 XML标签的解析 <tx:annotation-driven transaction-manager="transactionManager"/> 配置过事务的应该
-
这一次搞懂Spring的XML解析原理说明
前言 Spring已经是我们Java Web开发必不可少的一个框架,其大大简化了我们的开发,提高了开发者的效率.同时,其源码对于开发者来说也是宝藏,从中我们可以学习到非常优秀的设计思想以及优雅的命名规范,但因其体系庞大.设计复杂对于刚开始阅读源码的人来说是非常困难的.所以在此之前首先你得下定决心,不管有多困难都得坚持下去:其次,最好先把设计模式掌握熟练:然后在开始阅读源码时一定要多画UML类图和时序图,多问自己为什么要这么设计?这样设计的好处是什么?还有没有更好的设计?当然,晕车是难免的,但还是
-
一文搞懂Spring循环依赖的原理
目录 简介 循环依赖实例 测试 简介 说明 本文用实例来介绍@Autowired解决循环依赖的原理.@Autowired是通过三级缓存来解决循环依赖的. 除了@Autoired,还有其他方案来解决循环依赖的,见:Spring循环依赖的解决方案详解 概述 @Autowired进行属性注入可以解决循环依赖.原理是:Spring控制了bean的生命周期,先实例化bean,后注入bean的属性.Spring中记录了正在创建中的bean(已经实例化但还没初始化完毕的bean),所以可以在注入属性时,从记录
-
这一次搞懂Spring自定义标签以及注解解析原理说明
前言 在上一篇文章中分析了Spring是如何解析默认标签的,并封装为BeanDefinition注册到缓存中,这一篇就来看看对于像context这种自定义标签是如何解析的.同时我们常用的注解如:@Service.@Component.@Controller标注的类也是需要在xml中配置<context:component-scan>才能自动注入到IOC容器中,所以本篇也会重点分析注解解析原理. 正文 自定义标签解析原理 在上一篇分析默认标签解析时看到过这个类DefaultBeanDefinit
-

一文搞懂Spring Bean中的作用域和生命周期
目录 一.Spring Bean 作用域 singleton(单例) prototype(原型) 小结 二.Spring Bean生命周期 如何关闭容器 生命周期回调 通过接口设置生命周期 通过xml设置生命周期 一.Spring Bean 作用域 常规的 Spring IoC 容器中Bean的作用域有两种:singleton(单例)和prototype(非单例) 注:基于Web的容器还有其他种作用域,在这就不赘述了. singleton(单例) singleton是Spring默认的作用域.当
-
一文搞懂Spring中Bean的生命周期
目录 一.使用配置生命周期的方法 二.生命周期控制——接口控制(了解) 小结 生命周期:从创建到消亡的完整过程 bean声明周期:bean从创建到销毁的整体过程 bean声明周期控制:在bean创建后到销毁前做一些事情 一.使用配置生命周期的方法 在BookDaoImpl中实现类中创建相应的方法: //表示bean初始化对应的操作 public void init(){ System.out.println("init..."); } //表示bean销毁前对应的操作 public v
-
一文搞懂Spring AOP的五大通知类型
目录 一.通知类型 二.环境准备 添加AOP依赖 创建目标接口和实现类 创建通知类 创建Spring核心配置类 编写运行程序 三.添加通知 普通通知 环绕通知(重点) 一.通知类型 Advice 直译为通知,也有人翻译为 “增强处理”,共有 5 种类型,如下表所示. 通知类型 注解 说明 before(前置通知) @Before 通知方法在目标方法调用之前执行 after(后置通知) @After 通知方法在目标方法返回或异常后调用 after-returning(返回通知) @AfterRet
-
这一次搞懂Spring事务是如何传播的
前言 上一篇分析了事务注解的解析过程,本质上是将事务封装为切面加入到AOP的执行链中,因此会调用到MethodInceptor的实现类的invoke方法,而事务切面的Interceptor就是TransactionInterceptor,所以本篇直接从该类开始. 正文 事务切面的调用过程 public Object invoke(MethodInvocation invocation) throws Throwable { // Work out the target class: may be
-
一文搞懂Spring中的Bean作用域
目录 概述 Singleton prototype request session application 概述 scope用来声明容器中的对象所应该处的限定场景或者说该对象的存活时间,即容器在对象进入其 相应的scope之前,生成并装配这些对象,在该对象不再处于这些scope的限定之后,容器通常会销毁这些对象. Spring容器bean的作用域类型: singleton:Spring IoC 容器的单个对象实例作用域都默认为singleton prototype:针对声明为拥有prototyp