Elasticsearches的集群搭建及数据分片过程详解
目录
- Elasticsearch高级之集群搭建,数据分片
- 广播方式
- 单播方式
- 选取主节点
- 什么是脑裂
- 错误识别
Elasticsearch高级之集群搭建,数据分片
es使用两种不同的方式来发现对方:
广播
单播
也可以同时使用两者,但默认的广播,单播需要已知节点列表来完成
广播方式
当es实例启动的时候,它发送了广播的ping请求到地址224.2.2.4:54328。而其他的es实例使用同样的集群名称响应了这个请求。

一般这个默认的集群名称就是上面的cluster_name对应的elasticsearch。通常而言,广播是个很好地方式。想象一下,广播发现就像你大吼一声:别说话了,再说话我就发红包了!然后所有听见的纷纷响应你。
但是,广播也有不好之处,过程不可控。
- 在本地单独的目录中,再复制一份elasticsearch文件
- 分别启动bin目录中的启动文件
- 在浏览器里输入:http://127.0.0.1:9200/_cluster/health?pretty
- 通过number_of_nodes可以看到,目前集群中已经有了两个节点了
单播方式
当节点的ip(想象一下我们的ip地址是不是一直在变)不经常变化的时候,或者es只连接特定的节点。单播发现是个很理想的模式。使用单播时,我们告诉es集群其他节点的ip及(可选的)端口及端口范围。我们在elasticsearch.yml配置文件中设置:
discovery.zen.ping.unicast.hosts: ["10.0.0.1", "10.0.0.3:9300", "10.0.0.6[9300-9400]"]
大家就像交换微信名片一样,相互传传就加群了.....

一般的,我们没必要关闭单播发现,如果你需要广播发现的话,配置文件中的列表保持空白即可。
#现在,我们为这个集群增加一些单播配置,打开各节点内的\config\elasticsearch.yml文件。每个节点的配置如下(原配置文件都被注释了,可以理解为空,我写好各节点的配置,直接粘贴进去,没有动注释的,出现问题了好恢复): #1 elasticsearch2节点,,集群名称是my_es1,集群端口是9300;节点名称是node1,监听本地9200端口,可以有权限成为主节点和读写磁盘(不写就是默认的)。 cluster.name: my_es1 node.name: node1 network.host: 127.0.0.1 http.port: 9200 transport.tcp.port: 9300 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"] # 2 elasticsearch3节点,集群名称是my_es1,集群端口是9302;节点名称是node2,监听本地9202端口,可以有权限成为主节点和读写磁盘。 cluster.name: my_es1 node.name: node2 network.host: 127.0.0.1 http.port: 9202 transport.tcp.port: 9302 node.master: true node.data: true discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"] # 3 elasticsearch3节点,集群名称是my_es1,集群端口是9303;节点名称是node3,监听本地9203端口,可以有权限成为主节点和读写磁盘。 cluster.name: my_es1 node.name: node3 network.host: 127.0.0.1 http.port: 9203 transport.tcp.port: 9303 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"] # 4 elasticsearch4节点,集群名称是my_es1,集群端口是9304;节点名称是node4,监听本地9204端口,仅能读写磁盘而不能被选举为主节点。 cluster.name: my_es1 node.name: node4 network.host: 127.0.0.1 http.port: 9204 transport.tcp.port: 9304 node.master: false node.data: true discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"]
由上例的配置可以看到,各节点有一个共同的名字my_es1,但由于是本地环境,所以各节点的名字不能一致,我们分别启动它们,它们通过单播列表相互介绍,发现彼此,然后组成一个my_es1集群。谁是老大则是要看谁先启动了!
选取主节点
无论是广播发现还是到单播发现,一旦集群中的节点发生变化,它们就会协商谁将成为主节点,elasticsearch认为所有节点都有资格成为主节点。
如果集群中只有一个节点,那么该节点首先会等一段时间,如果还是没有发现其他节点,就会任命自己为主节点。
对于节点数较少的集群,我们可以设置主节点的最小数量,虽然这么设置看上去集群可以拥有多个主节点。
实际上这么设置是告诉集群有多少个节点有资格成为主节点。
怎么设置呢?修改配置文件中的:
discovery.zen.minimum_master_nodes: 3
一般的规则是集群节点数除以2(向下取整)再加一。比如3个节点集群要设置为2。这么着是为了防止脑裂(split brain)问题。
什么是脑裂
脑裂这个词描述的是这样的一个场景:
(通常是在重负荷或网络存在问题时)elasticsearch集群中一个或者多个节点失去和主节点的通信,然后各节点就开始选举新的主节点,继续处理请求。
这个时候,可能有两个不同的集群在相互运行着,这就是脑裂一词的由来,因为单一集群被分成了两部分。
为了防止这种情况的发生,我们就需要设置集群节点的总数,规则就是节点总数除以2再加一(半数以上)。这样,当一个或者多个节点失去通信,小老弟们就无法选举出新的主节点来形成新的集群。因为这些小老弟们无法满足设置的规则数量。
我们通过下图来说明如何防止脑裂。比如现在,有这样一个5个节点的集群,并且都有资格成为主节点:
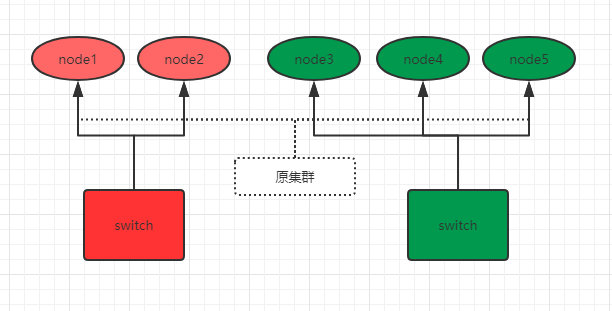
为了防止脑裂,我们对该集群设置参数:
discovery.zen.minimum_master_nodes: 3 # 3=5/2+1
之前原集群的主节点是node1,由于网络和负荷等原因,原集群被分为了两个switch:node1 、2和node3、4、5。
因为minimum_master_nodes参数是3,所以node3、4、5可以组成集群,并且选举出了主节点node3。
而node1、2节点因为不满足minimum_master_nodes条件而无法选举,只能一直寻求加入集群(还记得单播列表吗?),要么网络和负荷恢复正常后加入node3、4、5组成的集群中,要么就是一直处于寻找集群状态,这样就防止了集群的脑裂问题。
除了设置minimum_master_nodes参数,有时候还需要设置node_master参数,比如有两个节点的集群,如果出现脑裂问题,那么它们自己都无法选举,因为都不符合半数以上。
这时我们可以指定node_master,让其中一个节点有资格成为主节点,另外一个节点只能做存储用。当然这是特殊情况。
那么,主节点是如何知道某个节点还活着呢?这就要说到错误识别了。
错误识别
其实错误识别,就是当主节点被确定后,建立起内部的ping机制来确保每个节点在集群中保持活跃和健康,这就是错误识别。
主节点ping集群中的其他节点,而且每个节点也会ping主节点来确认主节点还活着,如果没有响应,则宣布该节点失联。想象一下,老大要时不常的看看(循环)小弟们是否还活着,而小老弟们也要时不常的看看老大还在不在,不在了就赶紧再选举一个出来!

但是,怎么看?多久没联系算是失联?这些细节都是可以设置的,不是一拍脑门子,就说某个小老弟挂了!在配置文件中,可以设置:
discovery.zen.fd.ping_interval: 1 discovery.zen.fd.ping_timeout: 30 discovery_zen.fd.ping_retries: 3
每个节点每隔discovery.zen.fd.ping_interval的时间(默认1秒)发送一个ping请求,等待discovery.zen.fd.ping_timeout的时间(默认30秒),并尝试最多discovery.zen.fd.ping_retries次(默认3次),无果的话,宣布节点失联,并且在需要的时候进行新的分片和主节点选举。
根据开发环境,适当修改这些值。
以上就是Elasticsearches的集群搭建及数据分片过程详解的详细内容,更多关于Elasticsearches集群搭建数据分片的资料请关注我们其它相关文章!
相关推荐
-

elasticsearch集群cluster主要功能详细分析
在源码概述中我们分析过,elasticsearch源码从功能上可以分为分布式功能和数据功能,接下来这几篇会就分布式功能展开.这里首先会对cluster作简单概述,然后对cluster所涉及的主要功能详细分析. elasticsearch的集群功能代码在cluster包中,通过ClusterService接口对外暴露. cluster主要包括以下功能: 发现(Discovery),路由(routing),传送功能(transport),集群状态(clusterstates)等. 发现功能功能主要用
-
elasticsearch集群cluster discovery可配式模块示例分析
目录 前言 Discovery模块的概述 cluster节点探测 MasterFaultDetection的启动代码 master连接失败的逻辑 MasterPing的关键代码 前言 elasticsearch cluster实现了自己发现机制zen.Discovery功能主要包括以下几部分内容:master选举,master错误探测,集群中其它节点探测,单播多播ping.本篇会首先概述以下Discovery这一部分的功能,然后介绍节点检测.其它内容会在接下来介绍. Discovery模块的概述
-
java连接ElasticSearch集群操作
我就废话不多说了,大家还是直接看代码吧~ /* *es配置类 * */ @Configuration public class ElasticSearchDataSourceConfigurer { private static final Logger LOG = LogManager.getLogger(ElasticSearchDataSourceConfigurer.class); @Bean public TransportClient getESClient() { //设置集群名称
-
elasticsearch集群发现zendiscovery的Ping机制分析
目录 zenDiscovery实现机制 广播的过程 nodeping处理代码 ping请求的发送策略 总结 zenDiscovery实现机制 ping是集群发现的基本手段,通过在网络上广播或者指定ping某些节点获取集群信息,从而可以找到集群的master加入集群.zenDiscovery实现了两种ping机制:广播与单播.本篇将详细分析一些这MulticastZenPing机制的实现为后面的集群发现和master选举做好铺垫. 广播的过程 首先看一下广播(MulticastZenPing),广
-
elasticsearch集群cluster示例详解
目录 前言 节点DiscoveryNode 集群阻塞 clusterService接口 总结 前言 上一篇通过clusterservice对cluster做了一个简单的概述, 应该能够给大家一个初步认识.本篇将对cluster的代码组成进行详细分析,力求能够对cluster做一个更清晰的描述.cluster作为多个节点的协同工作机制,它需要节点,节点间通信,各个节点的状态及各个节点上的数据(index)状态.因此这一部分代码包括了上述的几个部分. 节点DiscoveryNode 首先是节点(Di
-
关于Java中配置ElasticSearch集群环境账号密码的问题
1.修改主站点的elasticsearch.yml添加一下行: xpack.security.enabled: true 2.生成安全秘钥 切到ES安装目录,执行bin/elasticsearch-certutil ca -out config/elastic-certificates.p12 -pass “” 会在/home/elasticsearch-7.9.3/config目录生成elastic-certificates.p12 3.继续修改ES yml文件 添加以下四行: xpack.s
-
Elasticsearches的集群搭建及数据分片过程详解
目录 Elasticsearch高级之集群搭建,数据分片 广播方式 单播方式 选取主节点 什么是脑裂 错误识别 Elasticsearch高级之集群搭建,数据分片 es使用两种不同的方式来发现对方: 广播 单播 也可以同时使用两者,但默认的广播,单播需要已知节点列表来完成 广播方式 当es实例启动的时候,它发送了广播的ping请求到地址224.2.2.4:54328.而其他的es实例使用同样的集群名称响应了这个请求. 一般这个默认的集群名称就是上面的cluster_name对应的elastics
-
Java 用Prometheus搭建实时监控系统过程详解
上帝之火 本系列讲述的是开源实时监控告警解决方案Prometheus,这个单词很牛逼.每次我都能联想到带来上帝之火的希腊之神,普罗米修斯.而这个开源的logo也是火,个人挺喜欢这个logo的设计. 本系列着重介绍Prometheus以及如何用它和其周边的生态来搭建一套属于自己的实时监控告警平台. 本系列受众对象为初次接触Prometheus的用户,大神勿喷,偏重于操作和实战,但是重要的概念也会精炼出提及下.系列主要分为以下几块 Prometheus各个概念介绍和搭建,如何抓取数据(本次分享内容)
-
基于docker 搭建Prometheus+Grafana的过程详解
一.介绍Prometheus Prometheus(普罗米修斯)是一套开源的监控&报警&时间序列数据库的组合,起始是由SoundCloud公司开发的.随着发展,越来越多公司和组织接受采用Prometheus,社会也十分活跃,他们便将它独立成开源项目,并且有公司来运作.Google SRE的书内也曾提到跟他们BorgMon监控系统相似的实现是Prometheus.现在最常见的Kubernetes容器管理系统中,通常会搭配Prometheus进行监控. Prometheus基本原理是通过HTT
-
pm2与Verdaccio搭建私有npm库过程详解
目录 前言 一般私有化的npm仓库有以下几种方法实现: 下面对各个方案进行一个粗浅的对比: 为什么选用Verdaccio? 安装 修改配置 配置文件 权限把控 部署 docker部署 pm2部署 管理npm仓库源 npm包发布 注册 登录 发布 删除 前言 最近开会的时候讨论到前端组件库搭建,因为需要多人协作,使用npm link等都比较麻烦,且当业务规模较大了之后,我们一般会有自己的脚手架,自己的全局工具包等等.其中可能包含了自身的业务代码不能公开,因此我们都需要一个私有化的npm仓库. 一般
-
koa TS ESLint搭建服务器重构版过程详解
目录 初始化项目目录 安装项目运行所需要的软件包 修改package.json 从.env中加载环境变量 配置路径别名 用法 目录规范 编码风格规范 Eslint 初始化项目目录 yarn init -y 安装项目运行所需要的软件包 生产依赖 yarn add koa koa-router cross-env module-alias dotenv koa:搭建 Koa 服务的核心软件包. koa-router:Koa 路由软件包. koa-bodyparser:解析 POST 请求参数的软件包
-
Springcould多模块搭建Eureka服务器端口过程详解
这篇文章主要介绍了Springcould多模块搭建Eureka服务器端口过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1创建一个普通父maven 在pom修改为因为spring could依赖spring boot所以首先在父maven <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-star
-
Spring boot @RequestBody数据传递过程详解
这篇文章主要介绍了Spring boot @RequestBody数据传递过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 @RequestBody需要接的参数是一个string化的json @RequestBody,要读取的数据在请求体里,所以要发post请求,还要将Content-Type设置为application/json java的api 参数为JSONObject,获取到的参数处理 @PostMapping("/combine
-
springmvc处理模型数据ModelAndView过程详解
这篇文章主要介绍了springmvc处理模型数据ModelAndView过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 springmvc提供了以下几种途径来输出模型数据: (1)ModelAndView:处理方法返回值类型为ModelAndView时,方法体即可通过该对象添加模型数据. (2)Map及Model:入参为org.springframework.ui.Model.org.springframework.ui.ModelMa
-
SpringBoot服务端数据校验过程详解
这篇文章主要介绍了SpringBoot服务端数据校验过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 对于任何一个应用而言,客户端做的数据有效性验证都不是安全有效的,而数据验证又是一个企业级项目架构上最为基础的功能模块,这时候就要求我们在服务端接收到数据的时候也对数据的有效性进行验证.为什么这么说呢?往往我们在编写程序的时候都会感觉后台的验证无关紧要,毕竟客户端已经做过验证了,后端没必要在浪费资源对数据进行验证了,但恰恰是这种思维最为容易
-
使用vue cli4.x搭建vue项目的过程详解
cli-4.x已经发布好久了,斟酌了好久,还是决定将原来的cli-2.x升级到4.x,详细的升级过程可以戳这里 1.创建项目 vue create vuetest 2.选择配置方式 ? Please pick a preset: (Use arrow keys) ☜(使用箭头键) > default (babel, eslint) ☜(使用默认的配置,会安装babel和eslint) Manually select features ☜(手动配置) 这里我选择的是手动配置(使用↑ ↓箭头切换,E