python 判断字符串当中是否包含字符(str.contain)
有一个ssqdatav2数据,要找到其中的深圳,并且替换成圳。
因为收集到的数据出现了错误,本来只有省份简写的地方却出现了深圳。
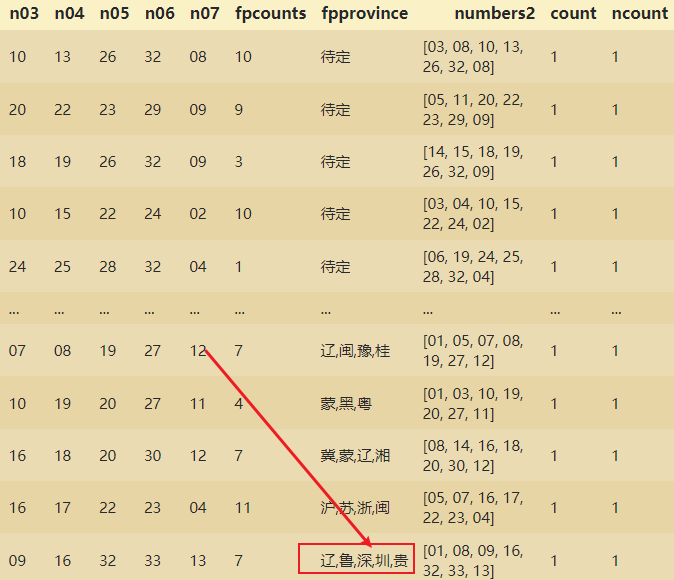
如何找到DF中包含深圳的数据?
cond=ssqdatav2['first'].str.contains('深圳')
ssqdatav2.loc[cond]

此时就找到first当中包含深圳的数据。
1、在first当中找到汉字
# 为分解firstprize定义函数
def fpp(x):
if len(x)<=2: # 判断是否只有汉字,还是也有数字
return "待定" # 没有汉字的用待定表示
else: # 使用正则表达式获取中文
pattern="[\u4e00-\u9fa5]" # 汉字专用字符ASCII区间
pat=re.compile(pattern)
return ','.join(pat.findall(x)) # 使用逗号作为每个省份的分隔符
#使用fp()
ssqdatav2['fpprovince']=ssqdatav2['first'].apply(lambda x:fpp(x))
ssqdatav2.head()

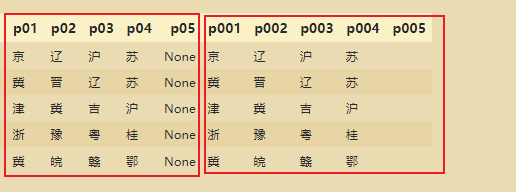
将每个省份单独形成1列:
fpnames=['p01','p02','p03','p04','p05']
ssqdatav3[fpnames]=ssqdatav3['fpprovince'].str.split(',',expand=True)
ssqdatav3

去除掉None值,是None的地方变成空值:
# 逐个分割
ssqdatav3['p001']=ssqdatav3['fpprovince'].apply(lambda x:x if x.count(',')==0 else x.split(',')[0])
ssqdatav3['p002']=ssqdatav3['fpprovince'].apply(lambda x:x.split(',')[1] if x.count(',')>=1 else '')
ssqdatav3['p003']=ssqdatav3['fpprovince'].apply(lambda x:x.split(',')[2] if x.count(',')>=2 else '')
ssqdatav3['p004']=ssqdatav3['fpprovince'].apply(lambda x:x.split(',')[3] if x.count(',')>=3 else '')
ssqdatav3['p005']=ssqdatav3['fpprovince'].apply(lambda x:x.split(',')[4] if x.count(',')>=4 else '')
ssqdatav3.to_excel('ssqdatav3p05.xlsx',index=False)
ssqdatav3.head()
# 让双色球的期号ID成为订单号,7个号码都有对应的订单号,即每个期号都有7个订单号且分成不同的行
import numpy as np
ssqdatav3['province2']=ssqdatav3['fpprovince'].apply(lambda x:x.split(','))
ssqdatav3
province2=ssqdatav3['province2'].to_list()
province2
rs=[len(r) for r in province2]
rs
a=np.repeat(ssqdatav3['id'],rs)
a
ssqdataprov=pd.DataFrame(np.column_stack((a,np.concatenate(province2))),columns=['ID','PROVINCE'])
# ssqdataprov=ssqdataprov[(ssqdataprov['PROVINCE']!='深')] # 等价
# ssqdataprov=ssqdataprov[~(ssqdataprov['PROVINCE']=='深')] # 等价
ssqdataprov=ssqdataprov[~(ssqdataprov['PROVINCE'].str.contains('深'))]
ssqdataprov
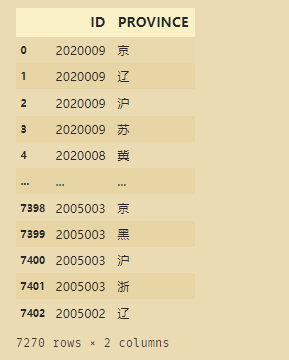
按照每个字段来划分,并且删去含有深的字段,这样就只保留圳字了
到此这篇关于python 判断字符串当中是否包含字符(str.contain)的文章就介绍到这了,更多相关python 判断字符串当中是否包含字符内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python如何判断字符串是否仅包含数字
在用Python进行数据处理的时候,经常会遇到DataFrame中的某一列本应该是数值类型,但由于数据不规范导致在字段中夹杂了非数值类型.对于这种类型的数据,再进行处理的时候一般都需要先判断该列中的每一个值是否仅包含数字.常用的判断方法如下: str.isdecimal()函数 作用:如果字符串中的所有字符都是十进制字符且该字符串至少有一个字符,则返回 True , 否则返回 False .十进制字符指那些可以用来组成10进制数字的字符,例如 U+0660 ,即阿拉伯字母数字0 . str.
-
Python实现确认字符串是否包含指定字符串的实例
有时候我们需要在某段字符串或者某段语句中去查找确认是否包含我们所需要的字符串信息, 举例子说. 某段变量是:A= "My name is Clay, and you can get my name" A = "My name is Clay, and you can get my name" myName = "Clay" if myName in A: //do what you want to do 而 我们需要查找A中是否包含Clay字段.
-
Python实现判断一个字符串是否包含子串的方法总结
本文实例总结了Python实现判断一个字符串是否包含子串的方法.分享给大家供大家参考,具体如下: 1.使用成员操作符 in >>> s='nihao,shijie' >>> t='nihao' >>> result = t in s >>> print result True 2.使用string模块的find()/rfind()方法 >>> import string >>> s='nihao,s
-
python正则表达式匹配不包含某几个字符的字符串方法
一.匹配目标 文件中所有以https?://开头,以.jpg|.png|.jpeg结尾的字符串 二.尝试过程 1) 自然想到正则表达式r'(https?://.*?.jpg|https?://.*?.png|https?://.*?.jpeg)简化书写为r'(https?://.*?\.(?:jpg|png|jpeg) 匹配结果:['http://sdsdsdadadsdsdsddsdsdawwii,https://sdsdoijcjz.jpg']发现结果并非我们想要的,仔细查看,结果中出现了,
-
python判断字符串是否包含子字符串的方法
本文实例讲述了python判断字符串是否包含子字符串的方法.分享给大家供大家参考.具体如下: python的string对象没有contains方法,不用使用string.contains的方法判断是否包含子字符串,但是python有更简单的方法来替换contains函数. 方法1:使用 in 方法实现contains的功能: site = 'http://www.jb51.net/' if "jb51" in site: print('site contains jb51') 输出结
-
Python查找最长不包含重复字符的子字符串算法示例
本文实例讲述了Python查找最长不包含重复字符的子字符串算法.分享给大家供大家参考,具体如下: 题目描述 请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度.例如在"arabcacfr"中,最长的不包含重复字符的子字符串是"acfr",长度为4 采用字典的方法,最后输出所有最长字符的列表 算法示例: # -*- coding:utf-8 -*- #! python3 class Solution: def __init__(self):
-
Python检测字符串中是否包含某字符集合中的字符
目的 检测字符串中是否包含某字符集合中的字符 方法 最简洁的方法如下,清晰,通用,快速,适用于任何序列和容器 复制代码 代码如下: def containAny(seq,aset): for c in seq: if c in aset: return True return False 第二种适用itertools模块来可以提高一点性能,本质上与前者是同种方法(不过此方法违背了Python的核心观点:简洁,清晰) itertoo
-
python 查找文件名包含指定字符串的方法
编写一个程序,能在当前目录以及当前目录的所有子目录下查找文件名包含指定字符串的文件,并打印出绝对路径. import os class SearchFile(object): def __init__(self,path='.'): self._path=path self.abspath=os.path.abspath(self._path) # 默认当前目录 def findfile(self,keyword,root): filelist=[] for root,dirs,files in
-
python 判断字符串当中是否包含字符(str.contain)
有一个ssqdatav2数据,要找到其中的深圳,并且替换成圳. 因为收集到的数据出现了错误,本来只有省份简写的地方却出现了深圳. 如何找到DF中包含深圳的数据? cond=ssqdatav2['first'].str.contains('深圳') ssqdatav2.loc[cond] 此时就找到first当中包含深圳的数据. 1.在first当中找到汉字 # 为分解firstprize定义函数 def fpp(x): if len(x)<=2: # 判断是否只有汉字,还是也有数字 return
-
java判断字符串中是否包含中文并过滤中文
java判断字符串中是否包含中文并过滤掉中文,具体内容如下 1.判断字符串中是否包含中文方法封装 /** * 判断字符串中是否包含中文 * @param str * 待校验字符串 * @return 是否为中文 * @warn 不能校验是否为中文标点符号 */ public static boolean isContainChinese(String str) { Pattern p = Pattern.compile("[\u4e00-\u9fa5]"); Matcher m = p
-
Python判断字符串是否xx开始或结尾的示例
判断是否xx开始 使用startswith 示例代码: String = "12345 上山打老虎" if str(String).startswith('1'): #判断String是否以"虎"结尾 print("有老虎") else: print("没老虎") 执行结果: 有老虎 判断是否xx结尾 使用endswith 示例代码1: String = "12345 上山打老虎" if str(Strin
-
Python判断字符串是否为字母或者数字(浮点数)的多种方法
str为字符串s为字符串 str.isalnum() 所有字符都是数字或者字母 str.isalpha() 所有字符都是字母 str.isdigit() 所有字符都是数字 str.isspace() 所有字符都是空白字符.t.n.r 检查字符串是数字/浮点数方法 float部分 >> float('Nan') nan >> float('Nan') nan >> float('nan') nan >> float('INF') inf >> fl
-
python判断字符串以什么结尾的实例方法
函数:endswith() 作用:判断字符串是否以指定字符或子字符串结尾,常用于判断文件类型. 相关函数:判断字符串开头 startswith() 函数说明: 语法: string.endswith(str, beg=[0,end=len(string)]) string[beg:end].endswith(str) 参数说明: string: 被检测的字符串 str: 指定的字符或者子字符串(可以使用元组,会逐一匹配) beg: 设置字符串检测的起始位置(可选,从左数起) en
-
python判断字符串是否纯数字的方法
本文实例讲述了python判断字符串是否纯数字的方法.分享给大家供大家参考.具体如下: 判断的代码如下,通过异常判断不能区分前面带正负号的区别,正则表达式可以根据自己需要比较灵活的写,通过isdigit方法用来判断是否是纯数字,测试代码如下 复制代码 代码如下: #!/usr/bin/python # -*- coding: utf-8 -*- a = "1" b = "1.2" c = "a" #通过抛出异常 def is_num_by_exc
-
Java 判断字符串中是否包含中文的实例详解
Java 判断字符串中是否包含中文的实例详解 Java判断一个字符串是否有中文是利用Unicode编码来判断,因为中文的编码区间为:0x4e00--0x9fbb, 不过通用区间来判断中文也不非常精确,因为有些中文的标点符号利用区间判断会得到错误的结果.而且利用区间判断中文效率也并不高,例如:str.substring(i, i + 1).matches("[\\一-\\?]+"),就需要遍历整个字符串,如果字符串太长效率非常低,而且判断标点还会错误.这里提高 一个高效准确的判断方法,使
-
C#实现判断字符串中是否包含中文的方法
本实例展示了C#实现判断字符串中是否包含中文的方法,是一个非常实用的功能,对初学者来说有一定的借鉴学习价值,具体实现方法如下: 主要功能代码如下: /// <summary> /// 判断字符串中是否包含中文 /// </summary> /// <param name="str">需要判断的字符串</param> /// <returns>判断结果</returns> public static bool Has