python基础之贪婪模式与非贪婪模式

# 贪婪模式 默认的匹配规则
# 在满足条件的情况下 尽可能多的去匹配到字符串
import re
rs = re.match('\d{6,9}', '111222333')
print(rs.group())
# 非贪婪模式 在满足条件的情况下尽可能少的去匹配
rs = re.match('\d{6,9}?', '111222333')
print(rs.group())

import re
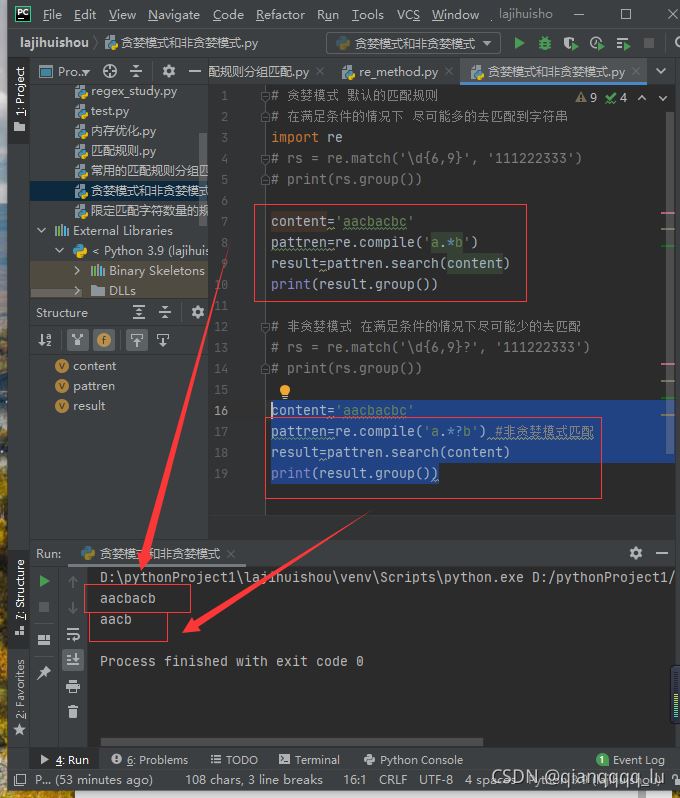
content='aacbacbc'
pattren=re.compile('a.*b')
result=pattren.search(content)
print(result.group())
content='aacbacbc'
pattren=re.compile('a.*?b') #非贪婪模式匹配
result=pattren.search(content)
print(result.group())






课后作业
import re
# 1.'save your heart for someone who cares' 请使用正则将文本中的
# “s” 替换成S 请写python代码完成匹配替换
data='save your heart for someone who cares'
res=re.sub('s','S',data)
print(res)
# 2.'<span>三生三世,十里桃花
# </span><span>莫斯科行动</span><span>九州海上牧云记</span>'
# 请使用正则将<span>标签中的全部内容匹配出来 用python代码实现
data='<span>三生三世,十里桃花</span>' \
'<span>莫斯科行动</span><span>' \
'九州海上牧云记</span>'
res=re.compile(r'<span>(.*)</span><span>(.*)</span><span>(.*)</span>')
result=res.findall(data)
print(result)

# 2.'<span>三生三世,十里桃花
# </span><span>莫斯科行动</span><span>九州海上牧云记</span>'
# 请使用正则将<span>标签中的全部内容匹配出来 用python代码实现
data='<span>三生三世,十里桃花</span>' \
'<span>莫斯科行动</span><span>' \
'九州海上牧云记</span>'
patternNick=r'<(?P<A>\w*)>(.*)</(?P=A)><(?P=A)>(.*)</(?P=A)><(?P=A)>(.*)</(?P=A)>'
res=re.compile(patternNick)
# res=re.compile(r'<span>(.*)</span><span>(.*)</span><span>(.*)</span>')
result=res.findall(data)
print(result)

总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

python基础之文件的备份以及定位
目录 小型文件备份 备份大型文件 总结 小型文件备份 # 文件的备份 def copyFile(): # 接收用户输入的文件名 old_file=input('请输入要备份的文件名:') file_list=old_file.split('.') # 构造新的文件名.加上备份的后缀 new_file=file_list[0]+'_备份.'+file_list[1] old_f=open(old_file,'r') #打开需要备份的文件 new_f=open(new_file,'w') #以写的模
-
python基础之共有操作
目录 总结 #共有方法 + * in stra='人生苦短' strb='我用python' lista=list(range(10)) listb=list(range(11,20)) print(stra+strb) #将两个字符串组合 print(lista+listb) #复制 * print(stra*3) print(lista*3) #in 对象是否存在 结果是一个布尔类型的值 print('生' in stra) print(22 in lista) 总结 本篇文章就到这里了,希
-
python基础之模块的导入
import导入模块 import time #导入的时模块中的所有内容 print(time.ctime()) #调用模块中的函数 # import 到首次导入模块的时候,会发生如下3步操作 # 1.打开模块文件 # 2.执行模块对应的文件 将执行过程中产生的名字都丢到模块的名称空间 # 3.在程序中会有一个模块[可以取别名的]的名称只想模块的名称空间区 # 4.建立模块时,不要与模块名相同,否则系统会直接就近在文件中查找,而不是导入真正的模块 # 引用格式:模块名:函数名 可以防止不同模块中
-
python基础之序列操作
类似于and操作 类似于or操作 # 类型转换 # sorted li=[2,45,1,67,23,10] li.sort() #list的排序方法 print(li) # sorted li=[2,45,1,67,23,10] # li.sort() #list的排序方法 print(li) # sorted() sorted(li) print(li) # 类型转换 # sorted li=[2,45,1,67,23,10] # li.sort() #list的排序方法 print(li)
-
python基础之类属性和实例属性
属性:类属性和实例属性 类属性:就是类对象所有的属性 小结 '类属性 是可以 被 类对象和实例对象共同访问的 实例属性只能由实例对象访问 class Student: name='黎明' #属于类属性 就是Student类对象所拥有的 def __init__(self,age): self.age=age #实例属性 pass pass lm=Student(17) print(lm.name) #通过实例对象去访问类属性 print(lm.age) class Student: name='
-
python基础之类方法和静态方法
目录 类方法 静态方法 复习 总结 类方法 class People: country='China' # 类方法 用classmethod来修饰 @classmethod #通过标识符来表示下方方法为类方法 def get_country(cls): #习惯性使用cls return cls.country #访问类属性 pass pass print(People.get_country()) #通过类对象去引用 p=People() print('实例对象访问%s'%p.get_count
-
python 正则表达式贪婪模式与非贪婪模式原理、用法实例分析
本文实例讲述了python 正则表达式贪婪模式与非贪婪模式原理.用法.分享给大家供大家参考,具体如下: 之前未接触过正则表达式,今日看python网络爬虫的源码,里面一行正则表达式匹配的代码初看之下,不是很理解,代码如下: myItems = re.findall('<div.*?class="content".*?title="(.*?)">(.*?)</div>',unicodePage,re.S) ".*?"这种匹配
-
详解正则表达式的贪婪模式与非贪婪模式
什么是正则表达式的贪婪与非贪婪匹配 如:String str="abcaxc"; Patter p="ab*c"; 贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配.如上面使用模式p匹配字符串str,结果就是匹配到:abcaxc(ab*c). 非贪婪匹配:就是匹配到结果就好,就少的匹配字符.如上面使用模式p匹配字符串str,结果就是匹配到:abc(ab*c). 下面通过实例代码看下正则表达式的贪婪模式与非贪婪模式,具体内容如下所示: 贪婪模式:能匹配
-
JavaScript正则表达式的贪婪匹配和非贪婪匹配
所谓贪婪匹配就是匹配重复字符是尽可能多的匹配,比如: "aaaaa".match(/a+/); //["aaaaa", index: 0, input: "aaaaa"] 非贪婪匹配就是尽可能少的匹配,用法就是在量词后面加上一个"?",比如: "aaaaa".match(/a+?/); //["a", index: 0, input: "aaaaa"] 但是非贪婪匹配
-
JS中使用正则表达式g模式和非g模式的区别
先给大家说下js正则表达式中的g到底是什么意思 g是global的缩写啊! 就是匹配全部可匹配结果, 如果你不带g,在正则过程中,字符串是从左至右匹配的,如果匹配成功就不再继续向右匹配了,如果你带g,它会重头到尾的把正确匹配的字符串挑选出来 例如: var str = 'aaaaaaaa' var reg1 = /a/ var reg2 = /a/g str.match(reg1) // 结果为:["a", index: 0, input: "aaaaaaaa"]
-
javascript严格模式详解(含严格模式与非严格模式的区别)
严格模式的优缺点 优点: 提高代码解析与运行速度 禁用一些不合理的语法,减少代码的怪异行为 缺点 某些代码在严格模式下会报错,尤其引入公用与第三方模块的时候需要注意 有些严格模式的特性在不同浏览器的支持情况不同,需要注意兼容问题 严格模式与非严格模式的区别 1.禁用with语法,使用将报错 因为解析with语法时作用域的情况会非常复杂,严重影响代码的解析与运行速度 function usualMode() { with({a: 1}) { console.log(a) } } usalMode(
-
python基础之贪婪模式与非贪婪模式
# 贪婪模式 默认的匹配规则 # 在满足条件的情况下 尽可能多的去匹配到字符串 import re rs = re.match('\d{6,9}', '111222333') print(rs.group()) # 非贪婪模式 在满足条件的情况下尽可能少的去匹配 rs = re.match('\d{6,9}?', '111222333') print(rs.group()) import re content='aacbacbc' pattren=re.compile('a.*b') resul
-
python中如何使用正则表达式的非贪婪模式示例
前言 本文主要给大家介绍了关于python使用正则表达式的非贪婪模式的相关内容,分享出来供大家参考学习,下面话不多说了,来一起详细的介绍吧. 在正则表达式里,什么是正则表达式的贪婪与非贪婪匹配 如:String str="abcaxc"; Patter p="ab*c"; 贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配.如上面使用模式p匹配字符串str,结果就是匹配到:abcaxc(ab*c). 非贪婪匹配:就是匹配到结果就好,就少的匹配字符.如上
-
[正则表达式]贪婪模式与非贪婪模式
复制代码 代码如下: /** ** author: site120 ** function : get script part from html document **/ var loadJs = function(str , delayTime) { var delayTime = delayTime || 100; var regExp_scriptTag = new RegExp("<\\s*sc
-
oracle日志操作模式(归档模式和非归档模式的利与弊)
笔者今天就谈谈自己对这两种操作模式的理解,并且给出一些可行的建议,跟大家一起来提高Oracle数据库的安全性. 一.非归档模式的利与弊. 非归档模式是指不保留重做历史的日志操作模式,只能够用于保护例程失败,而不能够保护介质损坏.如果数据库采用的是日志操作模式的话,则进行日志切换时,新的日志会直接覆盖原有日志文件的内容,不会保留原有日志文件中的数据. 这么说听起来可能比较难理解.笔者举一个简单的例子,就会清楚许多.如现在Oracle数据库中有四个日志组,日志序列号分别为11. 12.13.14.当
-
正则表达式之 贪婪与非贪婪模式详解(概述)
1 概述 贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配.非贪婪模式只被部分NFA引擎所支持. 属于贪婪模式的量词,也叫做匹配优先量词,包括: "{m,n}"."{m,}"."?"."*"和"+". 在一些使用NFA引擎的语言中,在匹配优先量词后加上"?",即变成属于非