一篇文章彻底搞懂jdk8线程池
这可能是最简短的线程池分析文章了。
顶层设计,定义执行接口
Interface Executor(){
void execute(Runnable command);
}
ExecutorService,定义控制接口
interface ExecutorService extends Executor{
}

抽象实现ExecutorService中的大部分方法
abstract class AbstractExecutorService implements ExecutorService{ //此处把ExecutorService中的提交方法都实现了
}

我们看下提交中的核心
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) { // ①
//核心线程数没有满就继续添加核心线程
if (addWorker(command, true)) // ②
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) { // ③
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))// ④
reject(command); //⑦
else if (workerCountOf(recheck) == 0) // ⑤
//如果worker为0,则添加一个非核心worker,所以线程池里至少有一个线程
addWorker(null, false);// ⑥
}
//队列满了以后,添加非核心线程
else if (!addWorker(command, false))// ⑧
reject(command);//⑦
}

这里就会有几道常见的面试题
1,什么时候用核心线程,什么时候启用非核心线程?
添加任务时优先使用核心线程,核心线程满了以后,任务放入队列中。只要队列不填满,就一直使用核心线程执行任务(代码①②)。
当队列满了以后开始使用增加非核心线程来执行队列中的任务(代码⑧)。
2,0个核心线程,2个非核心线程,队列100,添加99个任务是否会执行?
会执行,添加队列成功后,如果worker的数量为0,会添加非核心线程执行任务(见代码⑤⑥)
3,队列满了会怎么样?
队列满了,会优先启用非核心线程执行任务,如果非核心线程也满了,那就执行拒绝策略。
4,submit 和execute的区别是?
submit将执行任务包装成了RunnableFuture,最终返回了Future,executor 方法执行无返回值。
addworker实现
ThreadPoolExecutor extends AbstractExecutorService{
//保存所有的执行线程(worker)
HashSet<Worker> workers = new HashSet<Worker>();
//存放待执行的任务,这块具体由指定的队列实现
BlockingQueue<Runnable> workQueue;
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler){
}
//添加执行worker
private boolean addWorker(Runnable firstTask, boolean core) {
//这里每次都会基础校验和cas校验,防止并发无法创建线程,
retry:
for(;;){
for(;;){
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
}
}
try{
//创建一个worker
w = new Worker(firstTask);
final Thread t = w.thread;
try{
//加锁校验,添加到workers集合中
workers.add(w);
}
//添加成功,将对应的线程启动,执行任务
t.start();
}finally{
//失败执行进行释放资源
addWorkerFailed(Worker w)
}
}
//Worker 是对任务和线程的封装
private final class Worker extends AbstractQueuedSynchronizer implements Runnable{
//线程启动后会循环执行任务
public void run() {
runWorker(this);
}
}
//循环执行
final void runWorker(Worker w) {
try{
while (task != null || (task = getTask()) != null) {
//执行前的可扩展点
beforeExecute(wt, task);
try{
//执行任务
task.run();
}finally{
//执行后的可扩展点,这块也把异常给吃了
afterExecute(task, thrown);
}
}
//这里会对执行的任务进行统计
}finally{
//异常或者是循环退出都会走这里
processWorkerExit(w, completedAbruptly);
}
}
//获取执行任务,此处决定runWorker的状态
private Runnable getTask() {
//worker的淘汰策略:允许超时或者工作线程>核心线程
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//满足淘汰策略且...,就返回null,交由processWorkerExit去处理线程
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
// 满足淘汰策略,就等一定的时间poll(),不满足,就一直等待take()
Runnable r = timed ?workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :workQueue.take();
}
//处理任务退出(循环获取不到任务的时候)
private void processWorkerExit(Worker w, boolean completedAbruptly) {
//异常退出的,不能调整线程数的
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
//不管成功或失败,都执行以下逻辑
//1,计数,2,减去一个线程
completedTaskCount += w.completedTasks;
//将线程移除,并不关心是否非核心
workers.remove(w);
//如果是还是运行状态
if (!completedAbruptly) {
//正常终止的,处理逻辑
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
//核心线程为0 ,最小值也是1
if (min == 0 && ! workQueue.isEmpty())
min = 1;
//总线程数大于min就不再添加
if (workerCountOf(c) >= min)
return; // replacement not needed
} //异常退出一定还会添加worker,正常退出一般不会再添加线程,除非核心线程数为0
addWorker(null, false);
}
}
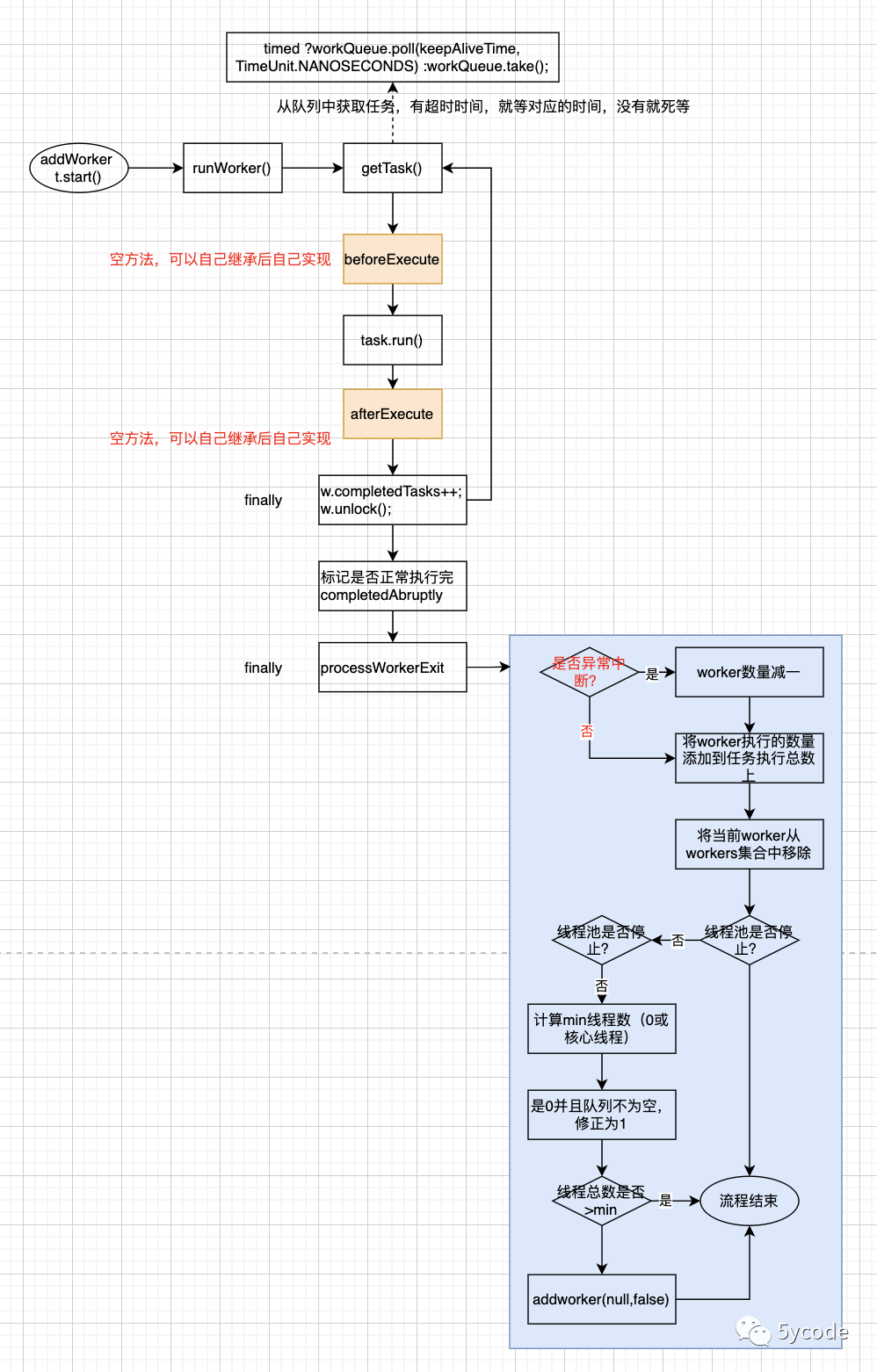
这里涉及到几个点:
1,任务异常以后虽然有throw异常,但是外面有好几个finally代码;
2,在finally中,进行了任务的统计以及worker移除;
3,如果还有等待处理的任务,最少添加一个worker(不管核心线程数是否为0)
这里会引申出来几个面试题:
1, 线程池中核心线程数如何设置?
cpu密集型:一般为核心线程数+1,尽可能减少cpu的并行;
IO密集型:可以设置核心线程数稍微多些,将IO等待期间的空闲cpu充分利用起来。
2,线程池使用队列的意义?
a)线程的资源是有限的,且线程的创建成本比较高;
b) 要保证cpu资源的合理利用(不能直接给cpu提一堆任务,cpu处理不过来,大家都慢了)
c) 利用了削峰填谷的思想(保证任务执行的可用性);
d) 队列过大也会把内存撑爆。
3,为什么要用阻塞队列?而不是非阻塞队列?
a) 利用阻塞的特性,在没有任务时阻塞一定的时间,防止资源被释放(getTask和processWorkExit);
b) 阻塞队列在阻塞时,CPU状态是wait,等有任务时,会被唤醒,不会占用太多的资源;
线程池有两个地方:
1,在execute方法中(提交任务时),只要工作线程为0,就至少添加一个Worker;
2,在processWorkerExit中(正常或异常结束时),只要有待处理的任务,就会增加Worker
所以正常情况下线程池一定会保证所有任务的执行。
我们在看下ThreadPoolExecutor中以下几个方法
public boolean prestartCoreThread() {
return workerCountOf(ctl.get()) < corePoolSize &&
addWorker(null, true);
}
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
if (wc < corePoolSize)
addWorker(null, true);
else if (wc == 0)
addWorker(null, false);
}
public int prestartAllCoreThreads() {
int n = 0;
while (addWorker(null, true))
++n;
return n;
}
确保了核心线程数必须是满的,这些方法特别是在批处理的时候,或者动态调整核心线程数的大小时很有用。
我们再看下Executors中常见的创建线程池的方法:
一、newFixedThreadPool 与newSingleThreadExecutor
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
特点:
1,核心线程数和最大线程数大小一样(唯一不同的是,一个是1,一个是自定义);
2,队列用的是LinkedBlockingQueue(长度是Integer.Max_VALUE)
当任务的生产速度大于消费速度后,很容易将系统内存撑爆。
二、 newCachedThreadPool 和
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
特点:最大线程数为Integer.MAX_VALUE
当任务提交过多时,线程创建过多容易导致无法创建
三、 newWorkStealingPool
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
这个主要是并行度,默认为cpu的核数。
四、newScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
封装起来的要么最大线程数不可控,要么队列长度不可控,所以阿里规约里也不建议使用Executors方法创建线程池。
ps:
生产上使用线程池,最好是将关键任务和非关键任务分开设立线程池,非关键业务影响关键业务的执行。
总结
到此这篇关于jdk8线程池的文章就介绍到这了,更多相关jdk8线程池内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
jdk自带线程池实例详解
二.简介 多线程技术主要解决处理器单元内多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力,但频繁的创建线程的开销是很大的,那么如何来减少这部分的开销了,那么就要考虑使用线程池了.线程池就是一个线程的容器,每次只执行额定数量的线程,线程池就是用来管理这些额定数量的线程. 三.涉及线程池的类结构图 其中供我们使用的,主要是ThreadPoolExecutor类. 四.如何创建线程池 我们创建线程池一般有以下几种方法: 1.使用Executors工厂类 Executor
-
JDK线程池和Spring线程池的使用实例解析
这篇文章主要介绍了JDK线程池和Spring线程池的使用实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 JDK线程池和Spring线程池实例,异步调用,可以直接使用 (1)JDK线程池的使用,此处采用单例的方式提供,见示例: public class ThreadPoolUtil { private static int corePoolSize = 5; private static int maximumPoolSize = 10;
-

一篇文章彻底搞懂jdk8线程池
这可能是最简短的线程池分析文章了. 顶层设计,定义执行接口 Interface Executor(){ void execute(Runnable command); } ExecutorService,定义控制接口 interface ExecutorService extends Executor{ } 抽象实现ExecutorService中的大部分方法 abstract class AbstractExecutorService implements ExecutorService{ /
-
一篇文章带你搞懂Java线程池实现原理
目录 1. 为什么要使用线程池 2. 线程池的使用 3. 线程池核心参数 4. 线程池工作原理 5. 线程池源码剖析 5.1 线程池的属性 5.2 线程池状态 5.3 execute源码 5.4 worker源码 5.5 runWorker源码 1. 为什么要使用线程池 使用线程池通常由以下两个原因: 频繁创建销毁线程需要消耗系统资源,使用线程池可以复用线程. 使用线程池可以更容易管理线程,线程池可以动态管理线程个数.具有阻塞队列.定时周期执行任务.环境隔离等. 2. 线程池的使用 /** *
-
一篇文章彻底搞懂Python切片操作
目录 引言 一.Python可切片对象的索引方式 二.Python切片操作的一般方式 三.Python切片操作详细例子 1.切取单个值 2.切取完整对象 3.start_index和end_index全为正(+)索引的情况 4.start_index和end_index全为负(-)索引的情况 5.start_index和end_index正(+)负(-)混合索引的情况 6.连续切片操作 7.切片操作的三个参数可以用表达式 8.其他对象的切片操作 四.Python常用切片操作 1.取偶数位置 2.
-
一篇文章轻松搞懂Java中的自旋锁
前言 锁作为并发共享数据,保证一致性的工具,在JAVA平台有多种实现(如 synchronized 和 ReentrantLock等等 ) .这些已经写好提供的锁为我们开发提供了便利. 在之前的文章<一文彻底搞懂面试中常问的各种"锁" >中介绍了Java中的各种"锁",可能对于不是很了解这些概念的同学来说会觉得有点绕,所以我决定拆分出来,逐步详细的介绍一下这些锁的来龙去脉,那么这篇文章就先来会一会"自旋锁". 正文 出现原因 在我们的
-
搞懂Java线程池
身为程序员我们对线程是再熟悉不过了,多线程并发算是Java进阶的知识,用好多线程不容易有太多的坑.创建线程也算是一个"重"操作.创建线程的语句是new Thread()咋一看好像就是new了一个对象. 没错是new了个对象,但是不仅仅是普通对象那样在堆中分配了一块内存,它还需要调用操作系统内核API,然后操作系统再为线程分配一些资源.所以较普通对象,线程就比较"重了".所以我们要避免频繁的创建和销毁线程,还得控制一下线程的数量.线程池就是用来完成这一项使命的. 所以
-
一篇文章彻底搞懂面试中常被问的各种“锁”
前言 锁,顾名思义就是锁住一些资源,当只有我们拿到钥匙的时候,才能操作锁住的资源.在我们的Java,数据库,还有一些分布式的环境中,总是充斥着各种各样的锁让人头疼,例如"公平锁"."自旋锁"."读写锁"."分布式锁"等等. 其实真实的情况是,锁并没有那么多,很多概念只是从不同的功能特性,设计,以及锁的状态这些不同的侧重点来说明的,因此我们可以根据不同的分类来搞明白为什么会有这些"锁"?坐稳扶好了,准备开车.
-
一篇文章彻底搞懂C++常见容器
目录 1.概述 2.容器详解 2.1vector(向量) 2.2deque(双端队列) 2.3list(列表) 2.4 array(数组) 2.5 string(字符串) 2.6 map(映射) 2.7 set(集合) 3.后记 1.概述 C++容器属于STL(标准模板库)中的一部分(六大组件之一),从字面意思理解,生活中的容器用来存放(容纳)水或者食物,东西,而C++中的容器用来存放各种各样的数据,不同的容器具有不同的特性,下图(思维导图)中列举除了常见的几种C++容器,而这部分C++的容器与
-
一篇文章彻底搞懂Python中可迭代(Iterable)、迭代器(Iterator)与生成器(Generator)的概念
前言 在Python中可迭代(Iterable).迭代器(Iterator)和生成器(Generator)这几个概念是经常用到的,初学时对这几个概念也是经常混淆,现在是时候把这几个概念搞清楚了. 0x00 可迭代(Iterable) 简单的说,一个对象(在Python里面一切都是对象)只要实现了只要实现了__iter__()方法,那么用isinstance()函数检查就是Iterable对象: 例如 class IterObj: def __iter__(self): # 这里简单地返回自身 #
-
一篇文章彻底搞懂python正则表达式
目录 前言 1. 正则表达式的基本概念 2. python的正则表达式re模块 3. 正则表达式语法 (1)匹配单个字符 (2)匹配多个字符 (3)边界匹配 (4)分组匹配 4. re模块相关方法使用 总结 前言 有时候字符串匹配解决不了问题,这个时候就需要正则表达式来处理.因为每一次匹配(比如找以什么开头的,以什么结尾的字符串要写好多个函数)都要单独完成,我们可以给它制定一个规则. 主要应用:爬虫的时候需要爬取各种信息,使用正则表达式可以很方便的处理需要的数据. 1. 正则表达式的基本概念 使
-
一篇文章彻底搞懂Python类属性和方法的调用
目录 一.类.对象概述 二.类的定义与使用 三.类属性和类方法的调用 四.私有成员与公有成员 总结 Python从设计之初就已经是一门面向对象的语言,正因为如此,在Python中创建一个类和对象是很容易的. 一.类.对象概述 在面向对象程序设计中,把数据以及对数据的操作封装在一起,组成一个整体(对象),不同对象之间通过消息机制来通信或者同步.对于相同类型的对象进行分类.抽象后,得出共同的特征而形成了类. 类的抽象具体包括两个方面: 1.数据抽象:描述某类对象共有的属性或状态. 2.过程抽象:描述