MySQL初学者可以告别分组聚合查询的困扰了
目录
- 1.分组查询的原理图
- 2.group by关键字语法详解
- 3.一个简单的分组查询的案例
- 4.分组前筛选和分组后筛选
- 1)原始表和结果集的概念
- 2)黄同学支大招
- 3)案例讲解
- 5.分组查询(按函数分组)
- 6.分组查询(按多个字段分组)
- 7.group by和order by,一对老搭档
- 8.分组查询的总结
1.分组查询的原理图

对上述原始数据,按照DEPARTMENT_ID(员工id)分组统计SALARY(薪水)的平均值。

上述原理写成代码,应该怎么写呢?
select department_id,avg(salary) from test group by department_id;
可以清楚地看到,使用department_id进行分组后,系统默认将department_id相同的号所在的行,分配在一起,你有几个不同的department_id,就会分为几组,每个组中的数据行数,不一定都要相同。
当自动分配完成后,会根据你所写的分组函数,进行组内运算。
也就是说,你使用的是sum()函数,就会组内求和;当你使用的是avg()函数,就会组内求平均值;当你使用的是count()函数,就会进行组内计数;当你使用的是max()函数,就会进行组内求最大值;你使用的是min()函数,就会进行组内求最小值。
2.group by关键字语法详解
有些小白在学习MySQL的过程中,很多都是在group by关键字这个地方卡壳。于是我希望自己能够用白话图文的方式,让你真正搞明白这个关键字的含义。

group by是用于分组查询的关键字,一般是配合sum(),avg(),count(),max(),min()聚合函数使用的。也就是说SQL语句中只要有group by,那么在select后面的展示字段中一般会有聚合函数(5个聚合函数)中的一个或多个函数出现。观察上图,有一点你需要记住,你用表中的字段A进行分组后,一般就需要对表中的其它字段,使用聚合函数,这样意义更大,而不是还对字段A使用聚合函数,没啥太大意义。
我们再思考下面这个问题!
当SQL语句中使用了group by后,在select后面一定有一个字段使用了聚合函数(5个聚合函数)。但是除了这个聚合函数,select后面还可以添加其他什么字段吗?
答案肯定是可以的!但是该字段有一定的限制,并不是什么字段都可以。也就是说,当SQL语句中使用了group by关键字后,select后面除了聚合函数,就只能是group by后面出现的字段。也就是图中的字段A,select后面只能存在group by后面的字段。
3.一个简单的分组查询的案例
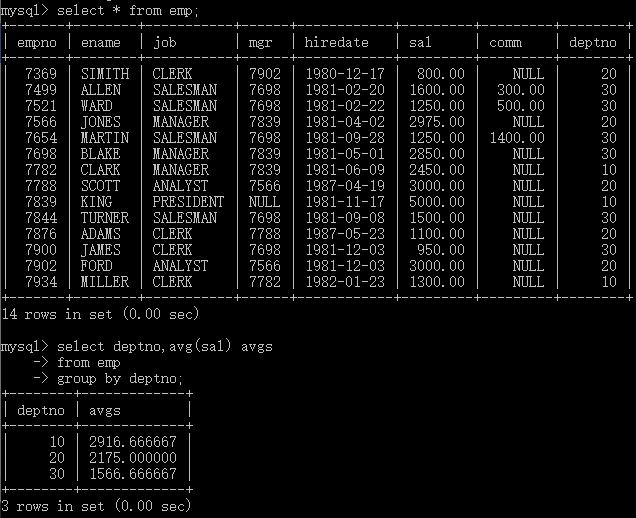
案例 :按照部门编号deptno分组,统计每个部门的平均工资。
select
deptno,avg(sal) avgs
from
emp
group by
deptno
结果如下:
4.分组前筛选和分组后筛选
这个知识点就是要带着大家理解一下,什么使用该用where筛选?什么时候该用having筛选?这个知识点对于学习MySQL的小白来说,也是一个棘手的事儿。不用担心,跟着黄同学学MySQL,没有学不会的。
1)原始表和结果集的概念
原始表指的是数据库中真正存在的那个表,使用【select * from 表名】查询出来的就是原始表信息。结果集指的是在SQL语句中,添加其它任何一个限制条件,最终展示给我们表,都是结果集。添加不同的限制条件,查询出来的结果集也是不同的。原始表只有一个,结果集却是各种各样的。
2)黄同学支大招
只要是需求中,涉及到聚合函数做条件的情况,一定是分组后的筛选。能用分组前筛选的,就优先考虑分组前的筛选。(考虑到性能问题)

3)案例讲解
原始数据集如下:

① 分组前筛选
习题一:查询姓名中包含S字符的,每个部门的工资之和。

习题二:查询工资大于2000的,不同部门的平均工资。

② 分组后筛选
习题一:查询部门员工个数大于3的部门编号和员工个数。

习题二:查询每个部门最高工资大于3000的部门编号和最高工资。

③ 分组前筛选和分组后筛选合用
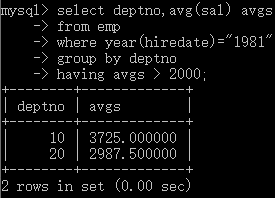
习题:查询1981年入职的,不同部门间工资的平均值大于2000的部门编号和平均值。
5.分组查询(按函数分组)
习题:按员工姓名的长度分组,查询每一组的员工个数,筛选员工个数>3的有哪些?
select length(ename) len,count(*) counts from emp group by len having counts > 3;
结果如下:

6.分组查询(按多个字段分组)
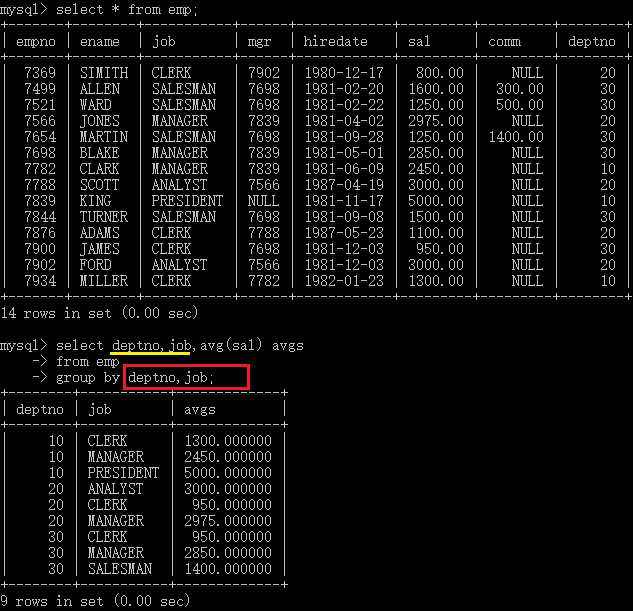
习题:查询每个部门每个工种的员工的平均工资。
7.group by和order by,一对老搭档
习题一:查询每个部门的员工的平均工资,按照平均工资降序。

习题二:查询每个部门的员工的平均工资,按照平均工资升序。

8.分组查询的总结
1)分组函数做条件,肯定是放在having子句中。
2)能用分组前筛选的,就优先考虑使用分组前筛选。(where筛选)
3)group by子句支持单个字段分组,多个字段分组(多个字段之间用逗号隔开没有顺序要求),还支持函数分组(用的较少)。
以上就是MySQL初学者可以告别分组聚合查询的困扰了的详细内容,更多关于MySQL分组聚合查询的资料请关注我们其它相关文章!
相关推荐
-
MySQL单表查询操作实例详解【语法、约束、分组、聚合、过滤、排序等】
本文实例讲述了MySQL单表查询操作.分享给大家供大家参考,具体如下: 语法 一.单表查询的语法 SELECT 字段1,字段2... FROM 表名 WHERE 条件 GROUP BY field HAVING 筛选 ORDER BY field LIMIT 限制条数 二.关键字的执行优先级(重点) 重点中的重点:关键
-
MySQL数据库分组查询group by语句详解
一:分组函数的语句顺序 1 SELECT ... 2 FROM ... 3 WHERE ... 4 GROUP BY ... 5 HAVING ... 6 ORDER BY ... 二:WHERE和HAVING筛选条件的区别 数据源 位置 关键字 WHERE 原始表 ORDER BY语句之前 WHERE HAVING 分组后的结果集 ORDER BY语句之后 HAVING 三:举例说明 #1.查询每个班学生的最大年龄 SELECT MAX(age),class FROM STU_CLASS GR
-
MySQL 分组查询和聚合函数
概述 相信我们经常会遇到这样的场景:想要了解双十一天猫购买化妆品的人员中平均消费额度是多少(这可能有利于对商品价格区间的定位):或者不同年龄段的化妆品消费占比是多少(这可能有助于对商品备货量的预估). 这个时候就要用到分组查询,分组查询的目的是为了把数据分成多个逻辑组(购买化妆品的人员是一个组,不同年龄段购买化妆品的人员也是组),并对每个组进行聚合计算的过程:. 分组查询的语法格式如下: select cname, group_fun,... from tname [where conditio
-

MySQL分组查询Group By实现原理详解
由于GROUP BY 实际上也同样会进行排序操作,而且与ORDER BY 相比,GROUP BY 主要只是多了排序之后的分组操作.当然,如果在分组的时候还使用了其他的一些聚合函数,那么还需要一些聚合函数的计算.所以,在GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引. 在MySQL 中,GROUP BY 的实现同样有多种(三种)方式,其中有两种方式会利用现有的索引信息来完成 GROUP BY,另外一种为完全无法使用索引的场景下使用.下面我们分别针对这三种实现方式做一个分
-
MySQL初学者可以告别分组聚合查询的困扰了
目录 1.分组查询的原理图 2.group by关键字语法详解 3.一个简单的分组查询的案例 4.分组前筛选和分组后筛选 1)原始表和结果集的概念 2)黄同学支大招 3)案例讲解 5.分组查询(按函数分组) 6.分组查询(按多个字段分组) 7.group by和order by,一对老搭档 8.分组查询的总结 1.分组查询的原理图 对上述原始数据,按照DEPARTMENT_ID(员工id)分组统计SALARY(薪水)的平均值. 上述原理写成代码,应该怎么写呢? select department
-
Django分组聚合查询实例分享
多表查询 1. 增删改 一对多:先一后多,外键可以为对象或依赖表的主键(publish and book) publish = Publish.objects.create() Book.objects.create(....publish=publish|publish_id=publish.id) 删: 默认存在级联删除 改: book修改外键,外键一定存在 多对多: 关系表的获取(book(主键) and author) book.author 增:book.author.add(作者对象
-
Sequelize中用group by进行分组聚合查询
一.SQL与Sequelize中的分组查询 1.1 SQL中的分组查询 SQL查询中,通GROUP BY语名实现分组查询.GROUP BY子句要和聚合函数配合使用才能完成分组查询,在SELECT查询的字段中,如果没有使用聚合函数就必须出现在ORDER BY子句中.分组查询后,查询结果为一个或多个列分组后的结果集. GROUP BY语法 SELECT 列名, 聚合函数(列名) FROM 表名 WHERE 列名 operator value GROUP BY 列名 [HAVING 条件表达式] [W
-
Elasticsearch聚合查询及排序操作示例
目录 1 es排序 2 match和match的区别 3 分页查询 4 es 组合查询 5 结果过滤展示字端 6 结果高亮展示 7 聚合查询avg.max.min.sum.分组 8 mapping和_template模版 9 ik分词 10 term和match的区别 1 es排序 # 1 排序 GET jeff/doc/_search { "query": { "match": { "from": "gu" } }, &qu
-
MySQL必备基础之分组函数 聚合函数 分组查询详解
目录 一.简单使用 二.搭配DISTINCT去重 三.COUNT()详细介绍 四.分组查询 一.简单使用 SUM:求和(一般用于处理数值型) AVG:平均(一般用于处理数值型) MAX:最大(也可以用于处理字符串和日期) MIN:最小(也可以用于处理字符串和日期) COUNT:数量(统计非空值的数据个数) 以上分组函数都忽略空NULL值的数据 SELECT SUM(salary) AS 和,AVG(salary) AS 平均,MAX(salary) AS 最大,MIN(salary) AS 最小
-
MySQL 数据库聚合查询和联合查询操作
目录 1. 插入被查询的结果 2. 聚合查询 2.1 介绍 2.2 聚合函数 2.3 group by 子句 2.4 having 3. 联合查询 3.1 介绍 3.2 内连接 3.3 外连接 3.4 自连接 3.5 子查询 3.6 合并查询 1. 插入被查询的结果 语法: insert into 要插入的表 [(列1, ..., 列n)] select {* | (列1, ..., 列n)}from 要查询的表 上述语句可以将要查询的表的某些列插入到新的表中对应的某些列 示例1: 将 stud
-
MySQL聚合查询与联合查询操作实例
目录 一.聚合查询 1.聚合函数(count,sum,avg...) 2.GROUPBY子句 3.HAVING 二.联合查询((重点)多表) 1.内连接 2.外连接 3.自连接 4.子查询 5.合并查询 总结 一. 聚合查询 1.聚合函数(count,sum,avg...) 常见的统计总数.计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有: 注意最后面都是可以加上where,order by这些语句的,这些聚合函数会根据这些语句的结果集来进行查询 后面最好不要加上limit,因为MyS
-
MySQL 数据库聚合查询和联合查询操作
目录 1.插入被查询的结果 2.聚合查询 2.1介绍 2.2聚合函数 2.3groupby子句 2.4having 3.联合查询 3.1介绍 3.2内连接 3.3外连接 3.4自连接 3.5子查询 3.6合并查询 1. 插入被查询的结果 语法: insert into 要插入的表 [(列1, ..., 列n)] select {* | (列1, ..., 列n)}from 要查询的表 上述语句可以将要查询的表的某些列插入到新的表中对应的某些列 2. 聚合查询 2.1 介绍 聚合查询:是指对一个数
-
Django ORM 聚合查询和分组查询实现详解
models.py: from django.db import models # 出版社 class Publisher(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=64, null=False, unique=True) def __str__(self): return "<Publisher object: {}>".format(
-
java使用elasticsearch分组进行聚合查询过程解析
这篇文章主要介绍了java使用elasticsearch分组进行聚合查询过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 java连接elasticsearch 进行聚合查询进行相应操作 一:对单个字段进行分组求和 1.表结构图片: 根据任务id分组,分别统计出每个任务id下有多少个文字标题 1.SQL:select id, count(*) as sum from task group by taskid; java ES连接工具类 p