SQL Server批量插入数据案例详解
在SQL Server 中插入一条数据使用Insert语句,但是如果想要批量插入一堆数据的话,循环使用Insert不仅效率低,而且会导致SQL一系统性能问题。下面介绍SQL Server支持的两种批量数据插入方法:Bulk和表值参数(Table-Valued Parameters),高效插入数据。
新建数据库:
--Create DataBase create database BulkTestDB; go use BulkTestDB; go --Create Table Create table BulkTestTable( Id int primary key, UserName nvarchar(32), Pwd varchar(16)) go
一.传统的INSERT方式
先看下传统的INSERT方式:一条一条的插入(性能消耗越来越大,速度越来越慢)
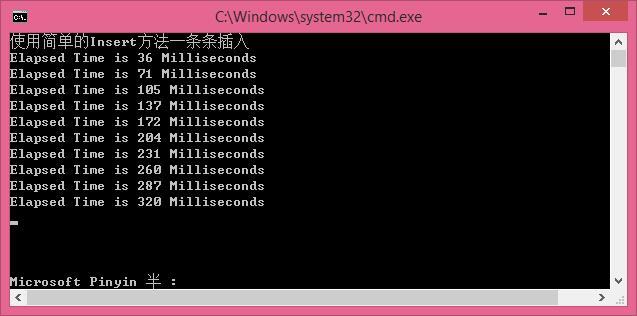
//使用简单的Insert方法一条条插入 [慢]
#region [ simpleInsert ]
static void simpleInsert()
{
Console.WriteLine("使用简单的Insert方法一条条插入");
Stopwatch sw = new Stopwatch();
SqlConnection sqlconn = new SqlConnection("server=.;database=BulkTestDB;user=sa;password=123456;");
SqlCommand sqlcmd = new SqlCommand();
sqlcmd.CommandText = string.Format("insert into BulkTestTable(Id,UserName,Pwd)values(@p0,@p1,@p2)");
sqlcmd.Parameters.Add("@p0", SqlDbType.Int);
sqlcmd.Parameters.Add("@p1", SqlDbType.NVarChar);
sqlcmd.Parameters.Add("@p2", SqlDbType.NVarChar);
sqlcmd.CommandType = CommandType.Text;
sqlcmd.Connection = sqlconn;
sqlconn.Open();
try
{
//循环插入1000条数据,每次插入100条,插入10次。
for (int multiply = 0; multiply < 10; multiply++)
{
for (int count = multiply * 100; count < (multiply + 1) * 100; count++)
{
sqlcmd.Parameters["@p0"].Value = count;
sqlcmd.Parameters["@p1"].Value = string.Format("User-{0}", count * multiply);
sqlcmd.Parameters["@p2"].Value = string.Format("Pwd-{0}", count * multiply);
sw.Start();
sqlcmd.ExecuteNonQuery();
sw.Stop();
}
//每插入10万条数据后,显示此次插入所用时间
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
Console.ReadKey();
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
}
#endregion
循环插入1000条数据,每次插入100条,插入10次,效率是越来越慢。
二.较快速的Bulk插入方式:
使用使用Bulk插入[ 较快 ]
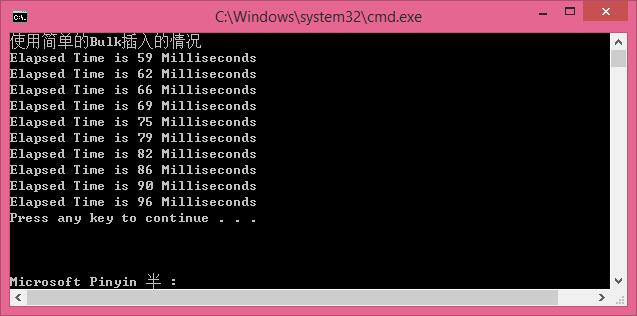
//使用Bulk插入的情况 [ 较快 ]
#region [ 使用Bulk插入的情况 ]
static void BulkToDB(DataTable dt)
{
Stopwatch sw = new Stopwatch();
SqlConnection sqlconn = new SqlConnection("server=.;database=BulkTestDB;user=sa;password=123456;");
SqlBulkCopy bulkCopy = new SqlBulkCopy(sqlconn);
bulkCopy.DestinationTableName = "BulkTestTable";
bulkCopy.BatchSize = dt.Rows.Count;
try
{
sqlconn.Open();
if (dt != null && dt.Rows.Count != 0)
{
bulkCopy.WriteToServer(dt);
}
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
finally
{
sqlconn.Close();
if (bulkCopy != null)
{
bulkCopy.Close();
}
}
}
static DataTable GetTableSchema()
{
DataTable dt = new DataTable();
dt.Columns.AddRange(new DataColumn[] {
new DataColumn("Id",typeof(int)),
new DataColumn("UserName",typeof(string)),
new DataColumn("Pwd",typeof(string))
});
return dt;
}
static void BulkInsert()
{
Console.WriteLine("使用简单的Bulk插入的情况");
Stopwatch sw = new Stopwatch();
for (int multiply = 0; multiply < 10; multiply++)
{
DataTable dt = GetTableSchema();
for (int count = multiply * 100; count < (multiply + 1) * 100; count++)
{
DataRow r = dt.NewRow();
r[0] = count;
r[1] = string.Format("User-{0}", count * multiply);
r[2] = string.Format("Pwd-{0}", count * multiply);
dt.Rows.Add(r);
}
sw.Start();
BulkToDB(dt);
sw.Stop();
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
}
#endregion
循环插入1000条数据,每次插入100条,插入10次,效率快了很多。
三.使用简称TVPs插入数据
打开sqlserrver,执行以下脚本:
--Create Table Valued CREATE TYPE BulkUdt AS TABLE (Id int, UserName nvarchar(32), Pwd varchar(16))
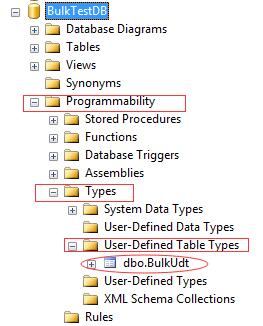
成功后在数据库中发现多了BulkUdt的缓存表。
使用简称TVPs插入数据
//使用简称TVPs插入数据 [最快]
#region [ 使用简称TVPs插入数据 ]
static void TbaleValuedToDB(DataTable dt)
{
Stopwatch sw = new Stopwatch();
SqlConnection sqlconn = new SqlConnection("server=.;database=BulkTestDB;user=sa;password=123456;");
const string TSqlStatement =
"insert into BulkTestTable (Id,UserName,Pwd)" +
" SELECT nc.Id, nc.UserName,nc.Pwd" +
" FROM @NewBulkTestTvp AS nc";
SqlCommand cmd = new SqlCommand(TSqlStatement, sqlconn);
SqlParameter catParam = cmd.Parameters.AddWithValue("@NewBulkTestTvp", dt);
catParam.SqlDbType = SqlDbType.Structured;
catParam.TypeName = "dbo.BulkUdt";
try
{
sqlconn.Open();
if (dt != null && dt.Rows.Count != 0)
{
cmd.ExecuteNonQuery();
}
}
catch (Exception ex)
{
Console.WriteLine("error>" + ex.Message);
}
finally
{
sqlconn.Close();
}
}
static void TVPsInsert()
{
Console.WriteLine("使用简称TVPs插入数据");
Stopwatch sw = new Stopwatch();
for (int multiply = 0; multiply < 10; multiply++)
{
DataTable dt = GetTableSchema();
for (int count = multiply * 100; count < (multiply + 1) * 100; count++)
{
DataRow r = dt.NewRow();
r[0] = count;
r[1] = string.Format("User-{0}", count * multiply);
r[2] = string.Format("Pwd-{0}", count * multiply);
dt.Rows.Add(r);
}
sw.Start();
TbaleValuedToDB(dt);
sw.Stop();
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
Console.ReadLine();
}
#endregion
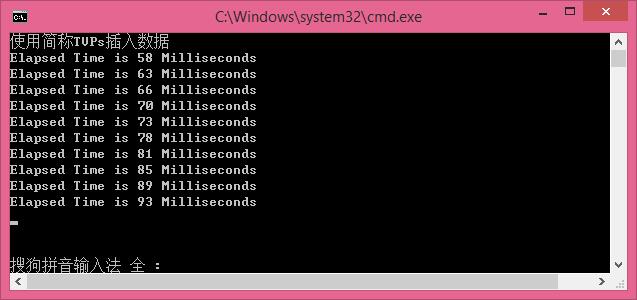
循环插入1000条数据,每次插入100条,插入10次,效率是越来越慢,后面测试,将每次插入的数据量增大,会更大的体现TPVS插入的效率。
到此这篇关于SQL Server批量插入数据案例详解的文章就介绍到这了,更多相关SQL Server批量插入数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SQLServer中防止并发插入重复数据的方法详解
SQLServer中防止并发插入重复数据,大致有以下几种方法: 1.使用Primary Key,Unique Key等在数据库层面让重复数据无法插入. 2.插入时使用条件 insert into Table(****) select **** where not exists(select 1 from Table where ****); 3.使用SERIALIZABLE隔离级别,并且使用updlock或者xlock锁提示(等效于在默认隔离级别下使用(updlock,holdlock)或(xl
-
Python实现读取SQLServer数据并插入到MongoDB数据库的方法示例
本文实例讲述了Python实现读取SQLServer数据并插入到MongoDB数据库的方法.分享给大家供大家参考,具体如下: # -*- coding: utf-8 -*- import pyodbc import os import csv import pymongo from pymongo import ASCENDING, DESCENDING from pymongo import MongoClient import binascii '''连接mongoDB数据库''' clie
-

SQL Server 批量插入数据的完美解决方案
一.Sql Server插入方案介绍 关于 SqlServer 批量插入的方式,有三种比较常用的插入方式,Insert.BatchInsert.SqlBulkCopy,下面我们对比以下三种方案的速度 1.普通的Insert插入方法 public static void Insert(IEnumerable<Person> persons) { using (var con = new SqlConnection("Server=.;Database=DemoDataBase;User
-
详解C#批量插入数据到Sqlserver中的四种方式
本篇,我将来讲解一下在Sqlserver中批量插入数据. 先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表中重新查询上一条记录的ID的值然后再进行加1运算要少.而如果存在索引的情况下,每次插入记录都会进行索引重建,这是非常耗性能的.如果表中无可避免的存在索引,我们可以通过先删除索引,然后批量插入,最后再重建索引的方式来提高效率. create database C
-
SQLServer2008存储过程实现数据插入与更新
存储过程的功能非常强大,在某种程度上甚至可以替代业务逻辑层, 接下来就一个小例子来说明,用存储过程插入或更新语句. 1.数据库表结构 所用数据库为Sql Server2008. 2.创建存储过程 (1)实现功能:1)有相同的数据,直接返回(返回值:0): 2)有主键相同,但是数据不同的数据,进行更新处理(返回值:2): 3)没有数据,进行插入数据处理(返回值:1). 根据不同的情况设置存储过程的返回值,调用存储过程的时候,根据不同的返回值,进行相关的处理. (2)下面编码只是实现的基本的功能,具
-
SQL Server批量插入数据案例详解
在SQL Server 中插入一条数据使用Insert语句,但是如果想要批量插入一堆数据的话,循环使用Insert不仅效率低,而且会导致SQL一系统性能问题.下面介绍SQL Server支持的两种批量数据插入方法:Bulk和表值参数(Table-Valued Parameters),高效插入数据. 新建数据库: --Create DataBase create database BulkTestDB; go use BulkTestDB; go --Create Table Create tab
-
JDBC连接MySQL数据库批量插入数据过程详解
这篇文章主要介绍了JDBC连接MySQL数据库批量插入数据过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.读取本地json数据 2.jdbc理解数据库 3.批量插入 maven 引入jar包: <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2
-
SQL Server中T-SQL 数据类型转换详解
常用的转换函数是 cast 和 convert,用于把表达式得出的值的类型转换成另一个数据类型,如果转换失败,该函数抛出错误,导致整个事务回滚.在SQL Server 2012版本中,新增两个容错的转换函数:try_cast 和 try_convert,如果转换操作失败,该函数返回null,不会导致整个事务失败,事务继续执行下去. 注意:对于SQL Server显式定义的不合法转换,try_cast 和 try_convert 会失败,抛出错误信息:Explicit conversion fro
-
SQL Server的行级安全性详解
目录 一.前言 二.描述 三.权限 四.安全说明:侧信道攻击 五.跨功能兼容性 六.示例 一.前言 行级别安全性使您能够使用组成员身份或执行上下文来控制对数据库表中行的访问. 行级别安全性 (RLS) 简化了应用程序中的安全性设计和编码.RLS 可帮助您对数据行访问实施限制.例如,您可以确保工作人员仅访问与其部门相关的数据行.另一个示例是将客户的数据访问限制为仅与其公司相关的数据. 访问限制逻辑位于数据库层中,而不是远离另一个应用程序层中的数据.每次尝试从任何层访问数据时,数据库系统都会应用访问
-
SQL Server 2012 FileTable 新特性详解
FileTable是基于FILESTREAM的一个特性.有以下一些功能: •一行表示一个文件或者目录. •每行包含以下信息: • •file_Stream流数据,stream_id标示符(GUID). •用户表示和维护文件及目录层次关系的path_locator和parent_path_locator •有10个文件属性 •支持对文件和文档的全文搜索和语义搜索的类型列. •filetable强制执行某些系统定义的约束和触发器来维护命名空间的语义 •针对非事务访问时,SQL Server配置FIL
-
SQL Server实现全文搜索查询详解
目录 一.概述 二.全文搜索查询 三.将全文搜索查询与 LIKE 谓词进行比较 四.全文搜索体系结构 4.1.SQL Server 进程 4.2.过滤器守护程序主机进程 五.全文搜索处理 5.1.全文索引过程 5.2.全文查询流程 六.全文索引体系结构 6.1.全文索引结构 6.2.全文索引片段 6.3.全文索引和常规 SQL Server 索引之间的差异 总结 一.概述 全文索引在表中包括一个或多个基于字符的列.这些列可以具有以下任何数据类型:char.varchar.nchar.nvarch
-
SQL的各种连接Join案例详解
最常见的 JOIN 类型:SQL INNER JOIN(简单的 JOIN).SQL LEFT JOIN.SQL RIGHT JOIN.SQL FULL JOIN,其中前一种是内连接,后三种是外链接. 假设我们有两张表,Table A是上边的表,Table B是下边的表. Table A id name 1 Google 2 淘宝 3 微博 4 Facebook Table B id address 1 美国 5 中国 3 中国 6 美国 一.INNER JOIN 内连接是最常见的一种连接,只连接
-
postgresql 删除重复数据案例详解
1.建表 /* Navicat Premium Data Transfer Source Server : localhost Source Server Type : PostgreSQL Source Server Version : 110012 Source Host : localhost:5432 Source Catalog : postgres Source Schema : public Target Server Type : PostgreSQL Target Server
-
sql ROW_NUMBER()与OVER()方法案例详解
语法格式:row_number() over(partition by 分组列 order by 排序列 desc) row_number() over()分组排序功能: 在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where .group by. order by 的执行. 例一: 表数据: create table TEST_ROW_NUMBER_OVER( id varchar(10) not null, name varchar(1