Python正则表达式保姆式教学详细教程
目录
- 一、re模块
- 1.导入re模块
- 2.findall()的语法:
- 二、正则表达式
- 1.普通字符
- 2.元字符
- (二)正则的使用
- 1.编译正则
- 2.正则对象的使用方法
- 3.Match object 的操作方法
- 4.re模块的函数
正则作为处理字符串的一个实用工具,在Python中经常会用到,比如爬虫爬取数据时常用正则来检索字符串等等。正则表达式已经内嵌在Python中,通过导入re模块就可以使用,作为刚学Python的新手大多数都听说”正则“这个术语。
今天来给大家分享一份关于比较详细的Python正则表达式宝典,学会之后你将对正则表达式达到精通的状态。

一、re模块
在讲正则表达式之前,我们首先得知道哪里用得到正则表达式。正则表达式是用在findall()方法当中,大多数的字符串检索都可以通过findall()来完成。
1.导入re模块
在使用正则表达式之前,需要导入re模块。
import re
2.findall()的语法:
导入了re模块之后就可以使用findall()方法了,那么我们必须要清楚findall()的语法是怎么规定的。
findall(正则表达式,目标字符串)
不难看出findall()的是由正则表达式和目标字符串组成,目标字符串就是你要检索的东西,那么如何检索则是通过正则表达式来进行操作,也就是我们今天的重点。
使用findall()之后返回的结果是一个列表,列表中是符合正则要求的字符串
二、正则表达式
(一).字符串的匹配
1.普通字符
大多数的字母和字符都可以进行自身匹配。
import re
a = "abc123+-*"
b = re.findall('abc',a)
print(b)
输出结果:
['abc']
2.元字符
元字符指的是. ^ $ ? + {} \ []之类的特殊字符,通过它们我们可以对目标字符串进行个性化检索,返回我们要的结果。
这里我给大家介绍10个常用的元字符以及它们的用法,这里我先给大家做1个简单的汇总,便于记忆,下面会挨个讲解每一个元字符的使用。
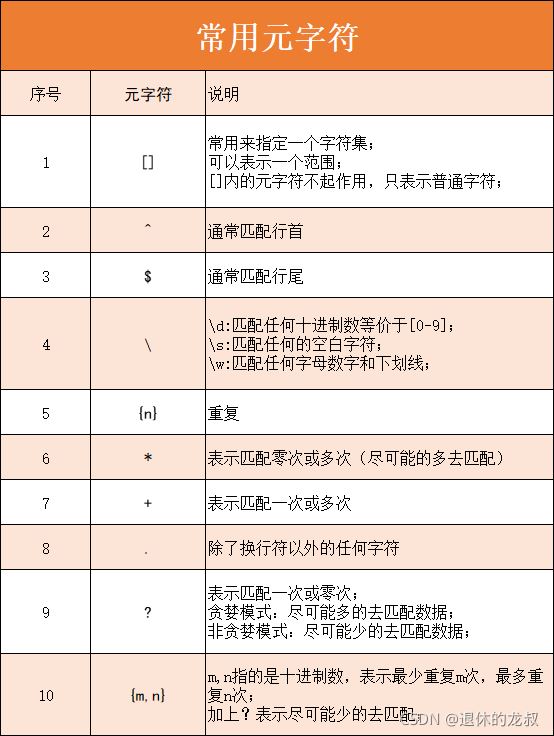
(1) []
[] 的使用方式主要有以下三种:
常用来指定一个字符集。
s = "a123456b" rule = "a[0-9][1-6][1-6][1-6][1-6][1-6]b" #这里暂时先用这种麻烦点的方法,后面有更容易的,不用敲这么多[1-6] l = re.findall(rule,s) print(l)
输出结果为:
['a123456b']
可以表示一个范围。
例如要在字符串"abcabcaccaac"中选出abc元素:
s = "abcabcaccaac" rule = "a[a,b,c]c" # rule = "a[a-z0-9][a-z0-9][a-z0-9][a-z0-9]c" l = re.findall(rule, s) print(l)
输出结果为:
['abc', 'abc', 'acc', 'aac']
[] 内的元字符不起作用,只表示普通字符。
例如要在字符串“caabcabcaabc”中选出“caa”:
print(re.findall("caa[a,^]", "caa^bcabcaabc"))
输出结果为:
['caa^']
注意点:当在[]的第一个位置时,表示除了a以外的都进行匹配,例如把[]中的和a换一下位置:
print(re.findall("caa[^,a]", "caa^bcabcaabc"))
输出:
['caa^', 'caab']
(2)^
^ 通常用来匹配行首,例如:
print(re.findall("^abca", "abcabcabc"))
输出结果:
['abca']

(3) $
$ 通常用来匹配行尾,例如:
print(re.findall("abc$", "accabcabc"))
输出结果:
['abc']

(4)\
反斜杠后面可以加不同的字符表示不同的特殊含义,常见的有以下3种。
\d:匹配任何十进制数等价于[0-9]
print(re.findall("c\d\d\da", "abc123abc"))
输出结果为:
['c123a']
\可以转义成普通字符,例如:
print(re.findall("\^abc", "^abc^abc"))
输出结果:
['^abc', '^abc']
s
匹配任何的空白字符例如:
print(re.findall("\s\s", "a c"))
输出结果:
[' ', ' ']
\w
匹配任何字母数字和下划线,等价于[a-zA-Z0-9_],例如:
print(re.findall("\w\w\w", "abc12_"))
输出:
['abc', '12_']

(5){n}
{n}可以避免重复写,比如前面我们用\w时写了3次\w,而这里我们这需要用用上{n}就可以,n表示匹配的次数,例如:
print(re.findall("\w{2}", "abc12_"))
输出结果:
['ab', 'c1', '2_']
(6)*
*表示匹配零次或多次(尽可能的多去匹配),例如:
print(re.findall("010-\d*", "010-123456789"))
输出:
['010-123456789']
**(7) + **
+表示匹配一次或多次,例如
print(re.findall("010-\d+", "010-123456789"))
输出:
['010-123456789']
(8) .
.是个点,这里不是很明显,它用来操作除了换行符以外的任何字符,例如:
print(re.findall(".", "010\n?!"))
输出:
['0', '1', '0', '?', '!']
(9) ?
?表示匹配一次或零次
print(re.findall("010-\d?", "010-123456789"))
输出:
['010-1']
这里要注意一下贪婪模式和非贪婪模式。
贪婪模式:尽可能多的去匹配数据,表现为\d后面加某个元字符,例如\d*:
print(re.findall("010-\d*", "010-123456789"))
输出:
['010-123456789']
非贪婪模式:尽可能少的去匹配数据,表现为\d后面加?,例如\d?
print(re.findall("010-\d*?", "010-123456789"))
输出为:
['010-']
(10){m,n}
m,n指的是十进制数,表示最少重复m次,最多重复n次,例如:
print(re.findall("010-\d{3,5}", "010-123456789"))
输出:
['010-12345']
加上?表示尽可能少的去匹配
print(re.findall("010-\d{3,5}?", "010-123456789"))
输出:
['010-123']
{m,n}还有其他的一些灵活的写法,比如:
- {1,} 相当于前面提过的 + 的效果
- {0,1} 相当于前面提过的 ? 的效果
- {0,} 相当于前面提过的 * 的效果

关于常用的元字符以及使用方法就先到这里,我们再来看看正则的其他知识。
(二)正则的使用
1.编译正则
在Python中,re模块可通过compile() 方法来编译正则,re.compile(正则表达式),例如:
s = "010-123456789" rule = "010-\d*" rule_compile = re.compile(rule) #返回一个对象 # print(rule_compile) s_compile = rule_compile.findall(s) print(s_compile) #打印compile()返回的对象是什么
输出结果:
['010-123456789']
2.正则对象的使用方法
正则对象的使用方法不仅仅是通过我们前面所介绍的 findall() 来使用,还可以通过其他的方法进行使用,效果是不一样的,这里我做个简单的总结:
(1)findall()
找到re匹配的所有字符串,返回一个列表
(2)search()
扫描字符串,找到这个re匹配的位置(仅仅是第一个查到的)
(3)match()
决定re是否在字符串刚开始的位置(匹配行首)
就拿上面的 compile()编译正则之后返回的对象来做举例,我们这里不用 findall() ,用 match() 来看一下结果如何:
s = "010-123456789" rule = "010-\d*" rule_compile = re.compile(rule) # 返回一个对象 # print(rule_compile) s_compile = rule_compile.match(s) print(s_compile) # 打印compile()返回的对象是什么
输出:
<re.Match object; span=(0, 13), match='010-123456789'>
可以看出结果是1个match 对象,开始下标位置为0~13,match为 010-123456789 。既然返回的是对象,那么接下来我们来讲讲这个match 对象的一些操作方法。

3.Match object 的操作方法
这里先介绍一下方法,后面我再举例,Match对象常见的使用方法有以下几个:
(1)group()
返回re匹配的字符串
(2)start()
返回匹配开始的位置
(3)end()
返回匹配结束的位置
(4)span()
返回一个元组:(开始,结束)的位置
举例:用span()来对search()返回的对象进行操作:
s = "010-123456789" rule = "010-\d*" rule_compile = re.compile(rule) # 返回一个对象 s_compile = rule_compile.match(s) print(s_compile.span()) #用span()处理返回的对象
结果为:
(0, 13)
4.re模块的函数
re模块中除了上面介绍的findall()函数之外,还有其他的函数,来做一个介绍:
(1)findall()
根据正则表达式返回匹配到的所有字符串,这个我就不多说了,前面都是在介绍它。
(2)sub(正则,新字符串,原字符串)
sub() 函数的功能是替换字符串,例如:
s = "abcabcacc" #原字符串
l = re.sub("abc","ddd",s) #通过sub()处理过的字符串
print(l)
输出:
ddddddacc #把abc全部替换成ddd
(3)subn(正则,新字符串,原字符串)
subn()的作用是替换字符串,并返回替换的次数
s = "abcabcacc" #原字符串
l = re.subn("abc","ddd",s) #通过sub()处理过的字符串
print(l)
输出:
('bbbbbbacc', 2)
(4)split()
split()分割字符串,例如:
s = "abcabcacc"
l = re.split("b",s)
print(l)
输出结果:
['a', 'ca', 'cacc']

关于正则,我就讲这么多了,正则几乎是Python所有方向中是必不可少的一个基础,祝你的Python之旅学有所成!
到此这篇关于Python正则表达式保姆式教学详细教程的文章就介绍到这了,更多相关Python正则表达式内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫教程之利用正则表达式匹配网页内容
前言 Python爬虫,除了使用大家广为使用的scrapy架构外,还有很多包能够实现一些简单的爬虫,如BeautifulSoup.Urllib.requests,在使用这些包时,有的网络因为比较复杂,比较难以找到自己想要的代码,在这个时候,如果能够使用正则表达式,将能很方便地爬取到自己想要的数据. 何为正则表达式 正则表达式是一种描述字符串排列的一种语法规则,通过该规则可以在一个大字符串中匹配出满足规则的子字符串.简单来说,就是给定了一个字符串,在字符串中找到想要的字符串,如一个电话号码,一个I
-
python正则表达式re.match()匹配多个字符方法的实现
1. *表示匹配任意多个字符 \d*表示匹配任意多个数字字符 import re text = "123h1ello world" text1 = "123Hello world456" text2 = "hello world" res = re.match("\d*", text) res1 = re.match("\d*", text1) res2 = re.match("\d*&qu
-
python使用正则表达式匹配txt特定字符串(有换行)
在原txt文件中,我们需要匹配出的字符串为:休闲服务(中间参杂着换行) 直接复制到notebook里进行处理 ①发现需要拿出的字符串都在证卷研究报告前,第一步就把证券报告前面的所有内容全部提出来(包括换行) ②发现需要的字符串在两个换行符(\n)的中间,再对其进行处理 完整代码 import re txt = """ 行业报告 | 行业点评 休闲服务 证券研究报告""" result = re.findall(r"([\s\S]*)证券
-
Python使用正则表达式实现爬虫数据抽取
1. 为什么要使用正则表达式? 首先,大家来看一个例子.一个文本文件里面存储了一些市场职位信息,格式如下所示: Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员 测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员 Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人 测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.
-
python中使用正则表达式将所有符合条件的字段全部提取出来
问题如标题,使用正则表达式匹配字段目前无非就三种,分别是: re.match() re.search() re.findall() 简单介绍一下,re.match()与re.search()非常类似,主要区别就是前者是从目标字符串的开头匹配,而后者则要没有这个要求.而re.findall()则是可以返回匹配的所有结果.但是有时候re.findall()返回的结果和前面两个并不一样,我们来看下面一个例子: 对于句子: 起病以来,患者无腰背痛.颈痛,无咽痛.口腔溃疡,无光过敏.脱发,无口干.眼干,无
-
Python正则表达式保姆式教学详细教程
目录 一.re模块 1.导入re模块 2.findall()的语法: 二.正则表达式 1.普通字符 2.元字符 (二)正则的使用 1.编译正则 2.正则对象的使用方法 3.Match object 的操作方法 4.re模块的函数 正则作为处理字符串的一个实用工具,在Python中经常会用到,比如爬虫爬取数据时常用正则来检索字符串等等.正则表达式已经内嵌在Python中,通过导入re模块就可以使用,作为刚学Python的新手大多数都听说"正则"这个术语. 今天来给大家分享一份关于比较详细
-
用pip给python安装matplotlib库的详细教程
Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形. 1.首先在python里安装pip,打开安装python的文件夹,找到python\scripts查看是否有pip.exe,如果有说明python里已经安装了pip,直接进入下一步.如果没有pip.exe,则需要先安装pip,官网上有详细教程,此处不再介绍.链接https://pip.pypa.io/en/stable/installing/ 2.添加环境变量,右键我的电脑
-
Python中使用ipython的详细教程
ipython简介 ipython他是一个非常流行的python解释器,相比于原生的python解释器,有太多优点和长处,因此几乎是python开发人员的必知必会. 1.ipython相比于原生的python有什么优势 (1) python shell不能在退出保存历史:ipython历史记录自动保存:保存在history.sqlite文件下:可用"_"."__"."___"调用最近三次记录: (2) python shell不支持tab自动补全
-
彻底吃透理解Python基础33个关键字详细教程
目录 1 and.or.not 2 if.elif.else 3 for.while 4 True.False 5 continue.break 6 pass 7 try.except.finally.raise 8 import.from.as 9 def.return 10 class 11 lambda 12 del 13 global.nonlocal 14 in.is 15 None 16 assert 17 with 18 yield 其实前面我已经为大家总结了<Python系统关键
-
全网最全python库selenium自动化使用详细教程
一.安装selenium pip install Selenium 二.初始化浏览器 Chrome 是初始化谷歌浏览器 Firefox 是初始化火狐浏览器 Edge 是初始化IE浏览器 PhantomJS 是一个无界面浏览器. from selenium import webdriver driver = webdriver.Chrome() 三.设置浏览器大小 maximize_window 最大化窗口 set_window_size 自定义窗口大小 from selenium import
-
Python Numpy库的超详细教程
1.Numpy概述 1.1 概念 Python本身含有列表和数组,但对于大数据来说,这些结构是有很多不足的.由于列表的元素可以是任何对象,因此列表中所保存的是对象的指针.对于数值运算来说这种 结构比较浪费内存和CPU资源.至于数组对象,它可以直接保存 数值,和C语言的一维数组比较类似.但是由于它不支持多维,在上面的函数也不多,因此也不适合做数值运算.Numpy提供了两种基本的对象:ndarray(N-dimensional Array Object)和 ufunc(Universal Funct
-
Python Numpy库的超详细教程
1.Numpy概述 1.1 概念 Python本身含有列表和数组,但对于大数据来说,这些结构是有很多不足的.由于列表的元素可以是任何对象,因此列表中所保存的是对象的指针.对于数值运算来说这种 结构比较浪费内存和CPU资源.至于数组对象,它可以直接保存 数值,和C语言的一维数组比较类似.但是由于它不支持多维,在上面的函数也不多,因此也不适合做数值运算.Numpy提供了两种基本的对象:ndarray(N-dimensional Array Object)和 ufunc(Universal Funct
-
Python如何发布程序的详细教程
如何发布一个Python程序: 1.安装一个pyInstaller 在pycharm里点 file -–>setting-–>Project workspace-->Interpreter-->点pip右边的+号,进入下面这个界面: 搜索pyInstaller, 点击左下方Iinstall package安装(出现错误了可以多安装几次) (或者在命令提示符界面 用 pip install pyinstaller命令安装) 2.将.py文件打包成.exe文件 在完成第一步的安装后,就
-
Python读取yaml文件的详细教程
yaml简介 1.yaml [ˈjæməl]: Yet Another Markup Language :另一种标记语言.yaml 是专门用来写配置文件的语言,非常简洁和强大,之前用ini也能写配置文件,看了yaml后,发现这个更直观,更方便,有点类似于json格式.在自动化测试用的相当多所以需要小伙伴们要熟练掌握 2.yaml基本语法规则: 大小写敏感 使用缩进表示层级关系 缩进时不允许使用Tab键,只允许使用空格. 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可 #表示注释,从这个字符
-
python进行图像边缘检测的详细教程
目录 边缘检测 边缘检测算子 1.Roberts算子 2.Prewitt算子 3.Sobel算子 4.Canny算子 5.拉普拉斯算子 效果实验 1. Roberts边缘检测 2.Prewitt 边缘检测 3.Sobel边缘检测 4.Canny边缘检测 5.Laplacian 边缘检测 总结 边缘检测 图像边缘是指图像中表达物体的周围像素灰度发生阶跃变化的那些像素集合. 图像中两个灰度不同的相邻区域的交界处,必然存在灰度的快速过渡或称为跳变,它们与图像中各区域边缘的位置相对应,边缘蕴含了丰富的内