pandas创建DataFrame的方式小结
如果你是一个pandas初学者,那么不知道你会不会像我一样。在学用列表或者数组创建DataFrame时理不清怎样用数据生成以及想要形状的的Dataframe,那么,现在,你不用自己琢磨了,我这里给你整理了一下,现在我们就来看看这三种生成Dataframe的方式。
1.用传入列表或者数组创建DataFrame 采用列表创建DataFrame
nums = [[i for i in range(3)] for _ in range(10)] nums

colu = [f'col_{i}' for i in range(3)] # 用来做列名
inde = [f'row_{i}' for i in range(10)] # 用来做索引
pd.DataFrame(data=nums,index=inde,columns=colu)
# 参数解释:data是要传入的数据,index是索引(不指定会自动产生自增长的索引),
# columns为指定的列名,按照顺序装在一个列表中
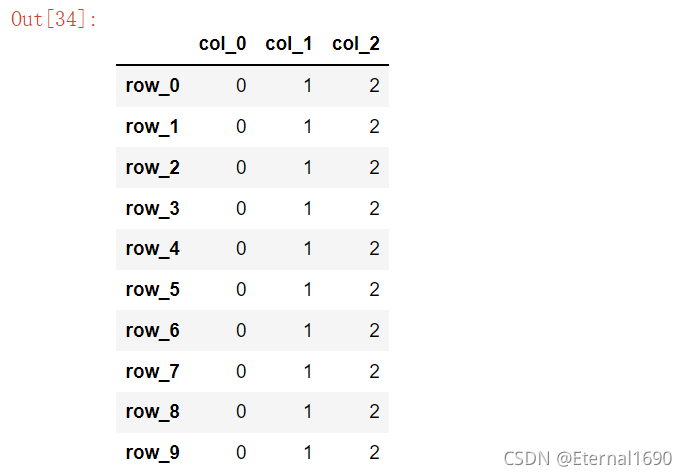
不知道你发现没有,生成的DataFrame形状和前面的列表'长相‘是一样的,所以,以后要用这种方式创建DataFrame的话是不是只要先把列表生成好形状,就不用再调整DataFrame形状了。
当然用数组创建DataFrame其实是一样的道理,所以我不演示了,我这里给一段代码,需要请自行调试。
用列表创建DataFrame
import numpy as np
import pandas as pd
nums = np.array([i for i in range(1,31)]).reshape(10,3)
colu = [f'col_{i}' for i in range(3)]
inde = [f'row_{i}' for i in range(10)]
pd.DataFrame(data=nums,index=inde,columns=colu)

实际上这两种方式我们并不推荐,我们更推荐用下面这种data参数给字典的方式来创建DataFrame
2.传入字典形式参数创建DataFrame
import numpy as np
import pandas as pd
hight = np.random.randint(158,180,10)
weight = np.random.randint(49,75,10)
pd.DataFrame(data={
'hight':hight,
'weight':weight,}
) # 这里没有设置索引,会自动生成

怎么样,这样是不是超级简单呢?
将直接读取数据文件生成DataFrame
但实际上以上创建DataFrame的方式都不是日常工作中最常用的,很多时候,其实我们是直接读取以个文件,然后将文件中的数据放入DataFrame中进行数据分析。
那么,接下来我们看一下用pandas读取excel文件或者csv文件
当我们输入代码pd.read_然后按tab键我们发现
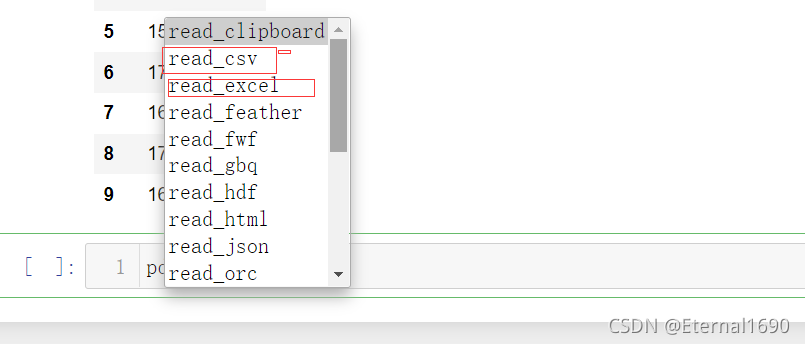
因此我们发现,其实不仅仅是csv和excel文件,实际上还可以读取很多种类型的文件,但这里我们只演示读取excel和csv文件
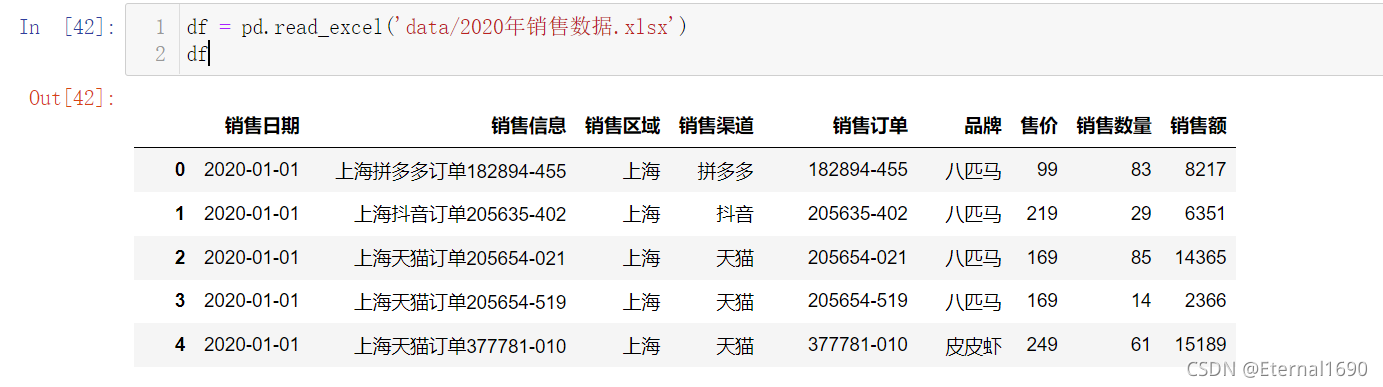
读取excel
df = pd.read_excel('data/2020年销售数据.xlsx')
df
读取csv
df = pd.read_csv('data/2018年北京积分落户数据.csv',encoding='utf-8') # encoding参数指定数据的编码方式为utf-8
df

好了,创建DataFrame就先分享到这里,下篇文章见。
到此这篇关于pandas创建DataFrame的方式小结的文章就介绍到这了,更多相关pandas创建DataFrame内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
从列表或字典创建Pandas的DataFrame对象的方法
介绍 每当我使用pandas进行分析时,我的第一个目标是使用众多可用选项中的一个将数据导入Pandas的DataFrame . 对于绝大多数情况下,我使用的 read_excel , read_csv 或 read_sql . 但是,有些情况下我只需要几行数据或包含这些数据里的一些计算. 在这些情况下,了解如何从标准python列表或字典创建DataFrames会很有帮助. 基本过程并不困难,但因为有几种不同的选择,所以有助于理解每种方法的工作原理. 我永远记不住我是否应该使用 from_dic
-
利用Pandas 创建空的DataFrame方法
平时写pyhton的时候习惯初始化一些list啊,tuple啊,dict啊这样的.一用到Pandas的DataFrame数据结构也就总想着初始化一个空的DataFrame,虽然没什么太大的用处,不过还是记录一下: # 创建一个空的 DataFrame df_empty = pd.DataFrame(columns=['A', 'B', 'C', 'D']) 上面创建的DataFrame有4列,每一行没有成员是空的. 输出一下结果: Empty DataFrame Columns: [A, B,
-
pandas DataFrame创建方法的方式
在pandas里,DataFrame是最经常用的数据结构,这里总结生成和添加数据的方法: ①.把其他格式的数据整理到DataFrame中: ②在已有的DataFrame中插入N列或者N行. 1. 字典类型读取到DataFrame(dict to DataFrame) 假如我们在做实验的时候得到的数据是dict类型,为了方便之后的数据统计和计算,我们想把它转换为DataFrame,存在很多写法,这里简单介绍常用的几种: 方法一:直接使用pd.DataFrame(data=test_dict)即可,
-
python中pandas.DataFrame的简单操作方法(创建、索引、增添与删除)
前言 最近在网上搜了许多关于pandas.DataFrame的操作说明,都是一些基础的操作,但是这些操作组合起来还是比较费时间去正确操作DataFrame,花了我挺长时间去调整BUG的.我在这里做一些总结,方便你我他.感兴趣的朋友们一起来看看吧. 一.创建DataFrame的简单操作: 1.根据字典创造: In [1]: import pandas as pd In [3]: aa={'one':[1,2,3],'two':[2,3,4],'three':[3,4,5]} In [4]: bb=
-
Python中pandas模块DataFrame创建方法示例
本文实例讲述了Python中pandas模块DataFrame创建方法.分享给大家供大家参考,具体如下: DataFrame创建 1. 通过列表创建DataFrame 2. 通过字典创建DataFrame 3. 通过Numpy数组创建DataFrame DataFrame这种列表式的数据结构和Excel工作表非常类似,其设计初衷是讲Series的使用场景由一维扩展到多维. DataFrame由按一定顺序的多列数据组成,各列的数据类型可以有所不同(数值.字符串.布尔值). Series对象的Ind
-
pandas创建新Dataframe并添加多行的实例
处理数据的时候,偶然遇到要把一个Dataframe中的某些行添加至一个空白的Dataframe中的问题. 最先想到的方法是创建Dataframe,从原有的Dataframe中逐行筛选出指定的行(类型为pandas的Series),并使用append方法进行添加.这种方法速度很慢,而且添加之后总会出现奇怪的问题,数据类型也不对. 较快的方法为,首先创建空的list,对原有的Dataframe进行逐行筛选,筛选出的行转化为dict类型,append进list中.全部添加完毕后,再将整个list转化为
-

pandas创建DataFrame的方式小结
如果你是一个pandas初学者,那么不知道你会不会像我一样.在学用列表或者数组创建DataFrame时理不清怎样用数据生成以及想要形状的的Dataframe,那么,现在,你不用自己琢磨了,我这里给你整理了一下,现在我们就来看看这三种生成Dataframe的方式. 1.用传入列表或者数组创建DataFrame 采用列表创建DataFrame nums = [[i for i in range(3)] for _ in range(10)] nums colu = [f'col_{i}' for i
-
pandas创建DataFrame的7种方法小结
笔者在学习pandas,在学习过程中总结了一下创建dataframe的方法,通过查阅资料总结遗下几种方法,如果你有其他的方法欢迎留言补充. 练习代码 请点击此处下载 学习环境: 第一种: 用Python中的字典生成 第二种: 利用指定的列内容.索引以及数据 第三种:通过读取文件,可以是json,csv,excel等等. 本文例子就用excel, 上篇博客笔者已经用csv举例了.这里要注意,如果用excel请先安装xlrd这个包 这个文件笔者放在代码同目录 第四种:用numpy中的array生成
-
Pandas中DataFrame基本函数整理(小结)
构造函数 DataFrame([data, index, columns, dtype, copy]) #构造数据框 属性和数据 DataFrame.axes #index: 行标签:columns: 列标签 DataFrame.as_matrix([columns]) #转换为矩阵 DataFrame.dtypes #返回数据的类型 DataFrame.ftypes #返回每一列的 数据类型float64:dense DataFrame.get_dtype_counts() #返回数据框数据类
-
pandas创建DataFrame对象失败的解决方法
目录 报错代码 报错翻译 报错原因 解决方法 创建DataFrame对象的四种方法 1. list列表构建DataFrame 2. dict字典构建DataFrame 3. ndarray创建DataFrame 4. Series创建DataFrame 报错代码 粉丝群一个小伙伴想pandas创建DataFrame对象,但是发生了报错(当时他心里瞬间凉了一大截,跑来找我求助,然后顺利帮助他解决了,顺便记录一下希望可以帮助到更多遇到这个bug不会解决的小伙伴),报错代码如下: import pan
-
Pandas创建DataFrame提示:type object 'object' has no attribute 'dtype'解决方案
目录 发现问题 原因分析: 解决方案: 总结 发现问题 pandas版本0.25.3 import pandas as pd symbol_info_columns = ['1', '持仓方向', '持仓量', '持仓收益率', '持仓收益', '持仓均价', '当前价格', '最大杠杆'] # v3 symbol_config = {'BTC': 'BTC-USDT-210924', 'LTC': 'LTC-USDT-210924', 'EOS': 'EOS-USDT-210924', 'ET
-
python numpy中array与pandas的DataFrame转换方式
目录 numpy array与pandas的DataFrame转换 1.numpy的array转换为pandas的DataFrame 2.pandas的DataFrame转换为numpy的array Pandas DataFrame转换成Numpy中array的三种方法 1.使用DataFrame中的values方法 2.使用DataFrame中的as_matrix()方法 3.使用Numpy中的array方法 numpy array与pandas的DataFrame转换 1.numpy的arr
-
python pandas创建多层索引MultiIndex的6种方式
目录 引言 pd.MultiIndex.from_arrays() pd.MultiIndex.from_tuples() 列表和元组是可以混合使用的 pd.MultiIndex.from_product() pd.MultiIndex.from_frame() groupby() pivot_table() 引言 在上一篇文章中介绍了如何创建Pandas中的单层索引,今天给大家带来的是如何创建Pandas中的多层索引. pd.MultiIndex,即具有多个层次的索引.通过多层次索引,我们就可