对Tensorflow中tensorboard日志的生成与显示详解
TensorBoard是TensorFlow下的一个可视化的工具,能够帮助我们在训练大规模神经网络过程中出现的复杂且不好理解的运算。TensorBoard能展示你训练过程中绘制的图像、网络结构等。
1. 构建简单的TensorBoard日志输出
import tensorflow as tf
input1 = tf.constant([1.0, 2.0, 3.0], name="input1")
input2 = tf.Variable(tf.random_uniform([3], name="input2"))
output = tf.add_n([input1, input2], name="add")
writer = tf.summary.FileWriter("./log", tf.get_default_graph())
writer.close()
"./log":TensorBoard日志信息文件保存的位置,本代码中表示:把文件保存把在当前目录下的"log"文件夹下。

2.查看TensorBoard视图
(1)激活tensorflow使用命令:activate tensorflow
进入cmd命令提示符,然后输入activate tensorflow 激活tensorflow


(2)进入tensorboard信息文件存储的存储目录
1.切换所在的磁盘号 E:

2. 进入路径文件所在的上一级目录下
cd E:\wokespace\pycharm\可视化 “E:\wokespace\pycharm\可视化”:文件所在上一级目录的路径

(3)输入tensorboard --logdir=log,启动TensorBoard
“=log” : log为tensorboard文件所在的文件夹
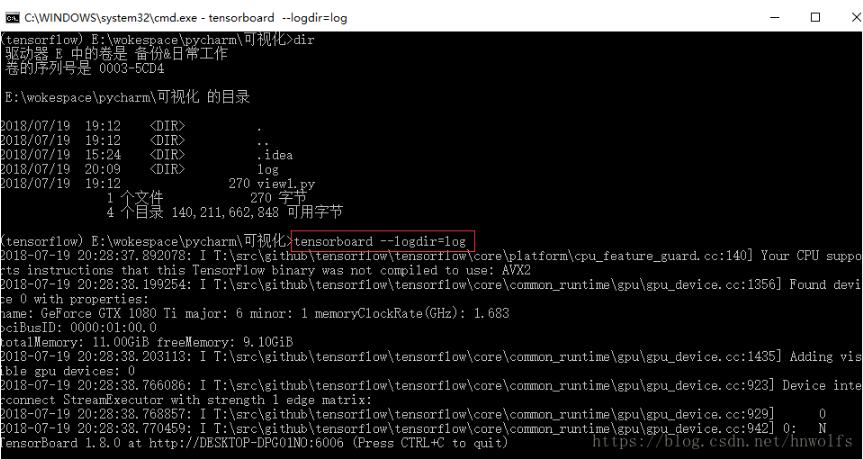
(4)复制” http://DESKTOP-DPG01NO:6006”链接,并在google浏览器中打开链接

(5)在google浏览器中打开链接回车

以上这篇对Tensorflow中tensorboard日志的生成与显示详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用tensorboard可视化loss和acc的实例
1.用try...except...避免因版本不同出现导入错误问题 try: image_summary = tf.image_summary scalar_summary = tf.scalar_summary histogram_summary = tf.histogram_summary merge_summary = tf.merge_summary SummaryWriter = tf.train.SummaryWriter except: image_summary = tf.sum
-
Tensorflow的可视化工具Tensorboard的初步使用详解
当使用Tensorflow训练大量深层的神经网络时,我们希望去跟踪神经网络的整个训练过程中的信息,比如迭代的过程中每一层参数是如何变化与分布的,比如每次循环参数更新后模型在测试集与训练集上的准确率是如何的,比如损失值的变化情况,等等.如果能在训练的过程中将一些信息加以记录并可视化得表现出来,是不是对我们探索模型有更深的帮助与理解呢? Tensorflow官方推出了可视化工具Tensorboard,可以帮助我们实现以上功能,它可以将模型训练过程中的各种数据汇总起来存在自定义的路径与日志文件中,然后
-
在tensorflow中实现屏蔽输出的log信息
tensorflow中可以通过配置环境变量 'TF_CPP_MIN_LOG_LEVEL' 的值,控制tensorflow是否屏蔽通知信息.警告.报错等输出信息. 使用方法: import os import tensorflow as tf os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # or any {'0', '1', '2'} TF_CPP_MIN_LOG_LEVEL 取值 0 : 0也是默认值,输出所有信息 TF_CPP_MIN_LOG_LEVEL
-
TensorFlow命名空间和TensorBoard图节点实例
一,命名空间函数 tf.variable_scope tf.name_scope 先以下面的代码说明两者的区别 # 命名空间管理函数 ''' 说明tf.variable_scope和tf.name_scope的区别 ''' def manage_namespace(): with tf.variable_scope("foo"): # 在命名空间foo下获取变量"bar",于是得到的变量名称为"foo/bar". a = tf.get_varia
-
对Tensorflow中tensorboard日志的生成与显示详解
TensorBoard是TensorFlow下的一个可视化的工具,能够帮助我们在训练大规模神经网络过程中出现的复杂且不好理解的运算.TensorBoard能展示你训练过程中绘制的图像.网络结构等. 1. 构建简单的TensorBoard日志输出 import tensorflow as tf input1 = tf.constant([1.0, 2.0, 3.0], name="input1") input2 = tf.Variable(tf.random_uniform([3], n
-
对Tensorflow中Device实例的生成和管理详解
1. 关键术语描述 kernel 在神经网络模型中,每个node都定义了自己需要完成的操作,比如要做卷积.矩阵相乘等. 可以将kernel看做是一段能够跑在具体硬件设备上的算法程序,所以即使同样的2D卷积算法,我们有基于gpu的Convolution 2D kernel实例.基于cpu的Convolution 2D kernel实例. device 负责运行kernel的具体硬件设备抽象.每个device实例,对应系统中一个具体的处理器硬件,比如gpu:0 device, gpu:1 devic
-
对tensorflow中cifar-10文档的Read操作详解
前言 在tensorflow的官方文档中得卷积神经网络一章,有一个使用cifar-10图片数据集的实验,搭建卷积神经网络倒不难,但是那个cifar10_input文件着实让我费了一番心思.配合着官方文档也算看的七七八八,但是中间还是有一些不太明白,不明白的mark一下,这次记下一些已经明白的. 研究 cifar10_input.py文件的read操作,主要的就是下面的代码: if not eval_data: filenames = [os.path.join(data_dir, 'data_b
-
CentOS 7中Nginx日志定时拆分实现过程详解
一.编写拆分脚本(splitNginxLog.sh) * 因为本例中设置每天0点进行日志的拆分,所以folder和rq均设置采用昨天的日期进行归档. #!/bin/bash folder=`date -d yesterday +%Y%m` rq=`date -d yesterday +%Y%m%d` # 原始日志路径 logs_path="/var/log/nginx/sitename.com/" # 日志备份路径 logs_backup_path="/var/log/ngi
-
C语言中堆空间的生成与释放详解
堆空间的分配和释放 #include <stdlib.h> malloc.calloc.realloc.free malloc void *malloc(size_t size); 功能:在堆中分配 size 字节的连续空间 参数:size_字节数 返回值:成功返回分配空间的首地址,失败返回 NULL free void free(void *ptr); 功能:释放由 malloc.calloc.realloc 分配的空间 参数:ptr_空间的首地址 返回值:无 注意: 1.每个空间只能释放
-
python3中超级好用的日志模块-loguru模块使用详解
目录 一. 使用logging模块时 二. loguru模块的基础使用 三. logurr详细使用 3.1 add 方法的定义 3.2 基本参数 3.3 删除 sink 3.4 rotation 配置 3.5 retention 配置 3.6 compression 配置 3.7 字符串格式化 3.8 Traceback 记录 一. 使用logging模块时 用python写代码时,logging模块最基本的几行配置,如下: import logging logging.basicConfig(
-

vue中v-model动态生成的实例详解
vue中v-model动态生成的实例详解 前言: 最近在做公司的项目中,有这么一个需求,每一行有一个input和一个select,其中行数是根据服务器返回的json数据动态变化的.那么问题来了,我们要怎样动态生成v-model? 现在项目做完了就整理了一下,直接贴代码了. <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title></title> <
-
在Spring Boot应用程序中使用Apache Kafka的方法步骤详解
第1步:生成我们的项目: Spring Initializr来生成我们的项目.我们的项目将提供Spring MVC / Web支持和Apache Kafka支持. 第2步:发布/读取Kafka主题中的消息: <b>public</b> <b>class</b> User { <b>private</b> String name; <b>private</b> <b>int</b> age
-
Java日志框架之logback使用详解
为什么使用logback 记得前几年工作的时候,公司使用的日志框架还是log4j,大约从16年中到现在,不管是我参与的别人已经搭建好的项目还是我自己主导的项目,日志框架基本都换成了logback,总结一下,logback大约有以下的一些优点: 内核重写.测试充分.初始化内存加载更小,这一切让logback性能和log4j相比有诸多倍的提升 logback非常自然地直接实现了slf4j,这个严格来说算不上优点,只是这样,再理解slf4j的前提下会很容易理解logback,也同时很容易用其他日志框架
-
Python实现日志实时监测的示例详解
目录 介绍 观察者模式类图 观察者模式示例 1.创建订阅者类 2.创建发布者类 3.应用客户端-Map_server_client.py 4.测试 介绍 观察者模式:是一种行为型设计模式.主要关注的是对象的责任,允许你定义一种订阅机制,可在对象事件发生时通知多个"观察"该对象的其他对象.用来处理对象之间彼此交互. 观察者模式也叫发布-订阅模式,定义了对象之间一对多依赖,当一个对象改变状态时,这个对象的所有依赖者都会收到通知并按照自己的方式进行更新. 观察者设计模式是最简单的行为模式之一