tensorflow入门:tfrecord 和tf.data.TFRecordDataset的使用
1.创建tfrecord
tfrecord支持写入三种格式的数据:string,int64,float32,以列表的形式分别通过tf.train.BytesList、tf.train.Int64List、tf.train.FloatList写入tf.train.Feature,如下所示:
tf.train.Feature(bytes_list=tf.train.BytesList(value=[feature.tostring()])) #feature一般是多维数组,要先转为list tf.train.Feature(int64_list=tf.train.Int64List(value=list(feature.shape))) #tostring函数后feature的形状信息会丢失,把shape也写入 tf.train.Feature(float_list=tf.train.FloatList(value=[label]))
通过上述操作,以dict的形式把要写入的数据汇总,并构建tf.train.Features,然后构建tf.train.Example,如下:
def get_tfrecords_example(feature, label):
tfrecords_features = {}
feat_shape = feature.shape
tfrecords_features['feature'] = tf.train.Feature(bytes_list=tf.train.BytesList(value=[feature.tostring()]))
tfrecords_features['shape'] = tf.train.Feature(int64_list=tf.train.Int64List(value=list(feat_shape)))
tfrecords_features['label'] = tf.train.Feature(float_list=tf.train.FloatList(value=label))
return tf.train.Example(features=tf.train.Features(feature=tfrecords_features))
把创建的tf.train.Example序列化下,便可通过tf.python_io.TFRecordWriter写入tfrecord文件,如下:
tfrecord_wrt = tf.python_io.TFRecordWriter('xxx.tfrecord') #创建tfrecord的writer,文件名为xxx
exmp = get_tfrecords_example(feats[inx], labels[inx]) #把数据写入Example
exmp_serial = exmp.SerializeToString() #Example序列化
tfrecord_wrt.write(exmp_serial) #写入tfrecord文件
tfrecord_wrt.close() #写完后关闭tfrecord的writer
代码汇总:
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets
mnist = read_data_sets("MNIST_data/", one_hot=True)
#把数据写入Example
def get_tfrecords_example(feature, label):
tfrecords_features = {}
feat_shape = feature.shape
tfrecords_features['feature'] = tf.train.Feature(bytes_list=tf.train.BytesList(value=[feature.tostring()]))
tfrecords_features['shape'] = tf.train.Feature(int64_list=tf.train.Int64List(value=list(feat_shape)))
tfrecords_features['label'] = tf.train.Feature(float_list=tf.train.FloatList(value=label))
return tf.train.Example(features=tf.train.Features(feature=tfrecords_features))
#把所有数据写入tfrecord文件
def make_tfrecord(data, outf_nm='mnist-train'):
feats, labels = data
outf_nm += '.tfrecord'
tfrecord_wrt = tf.python_io.TFRecordWriter(outf_nm)
ndatas = len(labels)
for inx in range(ndatas):
exmp = get_tfrecords_example(feats[inx], labels[inx])
exmp_serial = exmp.SerializeToString()
tfrecord_wrt.write(exmp_serial)
tfrecord_wrt.close()
import random
nDatas = len(mnist.train.labels)
inx_lst = range(nDatas)
random.shuffle(inx_lst)
random.shuffle(inx_lst)
ntrains = int(0.85*nDatas)
# make training set
data = ([mnist.train.images[i] for i in inx_lst[:ntrains]], \
[mnist.train.labels[i] for i in inx_lst[:ntrains]])
make_tfrecord(data, outf_nm='mnist-train')
# make validation set
data = ([mnist.train.images[i] for i in inx_lst[ntrains:]], \
[mnist.train.labels[i] for i in inx_lst[ntrains:]])
make_tfrecord(data, outf_nm='mnist-val')
# make test set
data = (mnist.test.images, mnist.test.labels)
make_tfrecord(data, outf_nm='mnist-test')
2.tfrecord文件的使用:tf.data.TFRecordDataset
从tfrecord文件创建TFRecordDataset:
dataset = tf.data.TFRecordDataset('xxx.tfrecord')
解析tfrecord文件的每条记录,即序列化后的tf.train.Example;使用tf.parse_single_example来解析:
feats = tf.parse_single_example(serial_exmp, features=data_dict)
其中,data_dict是一个dict,包含的key是写入tfrecord文件时用的key,相应的value则是tf.FixedLenFeature([], tf.string)、tf.FixedLenFeature([], tf.int64)、tf.FixedLenFeature([], tf.float32),分别对应不同的数据类型,汇总即有:
def parse_exmp(serial_exmp): #label中[10]是因为一个label是一个有10个元素的列表,shape中的[x]为shape的长度
feats = tf.parse_single_example(serial_exmp, features={'feature':tf.FixedLenFeature([], tf.string),\
'label':tf.FixedLenFeature([10],tf.float32), 'shape':tf.FixedLenFeature([x], tf.int64)})
image = tf.decode_raw(feats['feature'], tf.float32)
label = feats['label']
shape = tf.cast(feats['shape'], tf.int32)
return image, label, shape
解析tfrecord文件中的所有记录,使用dataset的map方法,如下:
dataset = dataset.map(parse_exmp)
map方法可以接受任意函数以对dataset中的数据进行处理;另外,可使用repeat、shuffle、batch方法对dataset进行重复、混洗、分批;用repeat复制dataset以进行多个epoch;如下:
dataset = dataset.repeat(epochs).shuffle(buffer_size).batch(batch_size)
解析完数据后,便可以取出数据进行使用,通过创建iterator来进行,如下:
iterator = dataset.make_one_shot_iterator() batch_image, batch_label, batch_shape = iterator.get_next()
要把不同dataset的数据feed进行模型,则需要先创建iterator handle,即iterator placeholder,如下:
handle = tf.placeholder(tf.string, shape=[]) iterator = tf.data.Iterator.from_string_handle(handle, \ dataset_train.output_types, dataset_train.output_shapes) image, label, shape = iterator.get_next()
然后为各个dataset创建handle,以feed_dict传入placeholder,如下:
with tf.Session() as sess:
handle_train, handle_val, handle_test = sess.run(\
[x.string_handle() for x in [iter_train, iter_val, iter_test]])
sess.run([loss, train_op], feed_dict={handle: handle_train}
汇总:
import tensorflow as tf
train_f, val_f, test_f = ['mnist-%s.tfrecord'%i for i in ['train', 'val', 'test']]
def parse_exmp(serial_exmp):
feats = tf.parse_single_example(serial_exmp, features={'feature':tf.FixedLenFeature([], tf.string),\
'label':tf.FixedLenFeature([10],tf.float32), 'shape':tf.FixedLenFeature([], tf.int64)})
image = tf.decode_raw(feats['feature'], tf.float32)
label = feats['label']
shape = tf.cast(feats['shape'], tf.int32)
return image, label, shape
def get_dataset(fname):
dataset = tf.data.TFRecordDataset(fname)
return dataset.map(parse_exmp) # use padded_batch method if padding needed
epochs = 16
batch_size = 50 # when batch_size can't be divided by nDatas, like 56,
# there will be a batch data with nums less than batch_size
# training dataset
nDatasTrain = 46750
dataset_train = get_dataset(train_f)
dataset_train = dataset_train.repeat(epochs).shuffle(1000).batch(batch_size) # make sure repeat is ahead batch
# this is different from dataset.shuffle(1000).batch(batch_size).repeat(epochs)
# the latter means that there will be a batch data with nums less than batch_size for each epoch
# if when batch_size can't be divided by nDatas.
nBatchs = nDatasTrain*epochs//batch_size
# evalation dataset
nDatasVal = 8250
dataset_val = get_dataset(val_f)
dataset_val = dataset_val.batch(nDatasVal).repeat(nBatchs//100*2)
# test dataset
nDatasTest = 10000
dataset_test = get_dataset(test_f)
dataset_test = dataset_test.batch(nDatasTest)
# make dataset iterator
iter_train = dataset_train.make_one_shot_iterator()
iter_val = dataset_val.make_one_shot_iterator()
iter_test = dataset_test.make_one_shot_iterator()
# make feedable iterator
handle = tf.placeholder(tf.string, shape=[])
iterator = tf.data.Iterator.from_string_handle(handle, \
dataset_train.output_types, dataset_train.output_shapes)
x, y_, _ = iterator.get_next()
train_op, loss, eval_op = model(x, y_)
init = tf.initialize_all_variables()
# summary
logdir = './logs/m4d2a'
def summary_op(datapart='train'):
tf.summary.scalar(datapart + '-loss', loss)
tf.summary.scalar(datapart + '-eval', eval_op)
return tf.summary.merge_all()
summary_op_train = summary_op()
summary_op_test = summary_op('val')
with tf.Session() as sess:
sess.run(init)
handle_train, handle_val, handle_test = sess.run(\
[x.string_handle() for x in [iter_train, iter_val, iter_test]])
_, cur_loss, cur_train_eval, summary = sess.run([train_op, loss, eval_op, summary_op_train], \
feed_dict={handle: handle_train, keep_prob: 0.5} )
cur_val_loss, cur_val_eval, summary = sess.run([loss, eval_op, summary_op_test], \
feed_dict={handle: handle_val, keep_prob: 1.0})
3.mnist实验
import tensorflow as tf
train_f, val_f, test_f = ['mnist-%s.tfrecord'%i for i in ['train', 'val', 'test']]
def parse_exmp(serial_exmp):
feats = tf.parse_single_example(serial_exmp, features={'feature':tf.FixedLenFeature([], tf.string),\
'label':tf.FixedLenFeature([10],tf.float32), 'shape':tf.FixedLenFeature([], tf.int64)})
image = tf.decode_raw(feats['feature'], tf.float32)
label = feats['label']
shape = tf.cast(feats['shape'], tf.int32)
return image, label, shape
def get_dataset(fname):
dataset = tf.data.TFRecordDataset(fname)
return dataset.map(parse_exmp) # use padded_batch method if padding needed
epochs = 16
batch_size = 50 # when batch_size can't be divided by nDatas, like 56,
# there will be a batch data with nums less than batch_size
# training dataset
nDatasTrain = 46750
dataset_train = get_dataset(train_f)
dataset_train = dataset_train.repeat(epochs).shuffle(1000).batch(batch_size) # make sure repeat is ahead batch
# this is different from dataset.shuffle(1000).batch(batch_size).repeat(epochs)
# the latter means that there will be a batch data with nums less than batch_size for each epoch
# if when batch_size can't be divided by nDatas.
nBatchs = nDatasTrain*epochs//batch_size
# evalation dataset
nDatasVal = 8250
dataset_val = get_dataset(val_f)
dataset_val = dataset_val.batch(nDatasVal).repeat(nBatchs//100*2)
# test dataset
nDatasTest = 10000
dataset_test = get_dataset(test_f)
dataset_test = dataset_test.batch(nDatasTest)
# make dataset iterator
iter_train = dataset_train.make_one_shot_iterator()
iter_val = dataset_val.make_one_shot_iterator()
iter_test = dataset_test.make_one_shot_iterator()
# make feedable iterator, i.e. iterator placeholder
handle = tf.placeholder(tf.string, shape=[])
iterator = tf.data.Iterator.from_string_handle(handle, \
dataset_train.output_types, dataset_train.output_shapes)
x, y_, _ = iterator.get_next()
# cnn
x_image = tf.reshape(x, [-1,28,28,1])
w_init = tf.truncated_normal_initializer(stddev=0.1, seed=9)
b_init = tf.constant_initializer(0.1)
cnn1 = tf.layers.conv2d(x_image, 32, (5,5), padding='same', activation=tf.nn.relu, \
kernel_initializer=w_init, bias_initializer=b_init)
mxpl1 = tf.layers.max_pooling2d(cnn1, 2, strides=2, padding='same')
cnn2 = tf.layers.conv2d(mxpl1, 64, (5,5), padding='same', activation=tf.nn.relu, \
kernel_initializer=w_init, bias_initializer=b_init)
mxpl2 = tf.layers.max_pooling2d(cnn2, 2, strides=2, padding='same')
mxpl2_flat = tf.reshape(mxpl2, [-1,7*7*64])
fc1 = tf.layers.dense(mxpl2_flat, 1024, activation=tf.nn.relu, \
kernel_initializer=w_init, bias_initializer=b_init)
keep_prob = tf.placeholder('float')
fc1_drop = tf.nn.dropout(fc1, keep_prob)
logits = tf.layers.dense(fc1_drop, 10, kernel_initializer=w_init, bias_initializer=b_init)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y_))
optmz = tf.train.AdamOptimizer(1e-4)
train_op = optmz.minimize(loss)
def get_eval_op(logits, labels):
corr_prd = tf.equal(tf.argmax(logits,1), tf.argmax(labels,1))
return tf.reduce_mean(tf.cast(corr_prd, 'float'))
eval_op = get_eval_op(logits, y_)
init = tf.initialize_all_variables()
# summary
logdir = './logs/m4d2a'
def summary_op(datapart='train'):
tf.summary.scalar(datapart + '-loss', loss)
tf.summary.scalar(datapart + '-eval', eval_op)
return tf.summary.merge_all()
summary_op_train = summary_op()
summary_op_val = summary_op('val')
# whether to restore or not
ckpts_dir = 'ckpts/'
ckpt_nm = 'cnn-ckpt'
saver = tf.train.Saver(max_to_keep=50) # defaults to save all variables, using dict {'x':x,...} to save specified ones.
restore_step = ''
start_step = 0
train_steps = nBatchs
best_loss = 1e6
best_step = 0
# import os
# os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# config = tf.ConfigProto()
# config.gpu_options.per_process_gpu_memory_fraction = 0.9
# config.gpu_options.allow_growth=True # allocate when needed
# with tf.Session(config=config) as sess:
with tf.Session() as sess:
sess.run(init)
handle_train, handle_val, handle_test = sess.run(\
[x.string_handle() for x in [iter_train, iter_val, iter_test]])
if restore_step:
ckpt = tf.train.get_checkpoint_state(ckpts_dir)
if ckpt and ckpt.model_checkpoint_path: # ckpt.model_checkpoint_path means the latest ckpt
if restore_step == 'latest':
ckpt_f = tf.train.latest_checkpoint(ckpts_dir)
start_step = int(ckpt_f.split('-')[-1]) + 1
else:
ckpt_f = ckpts_dir+ckpt_nm+'-'+restore_step
print('loading wgt file: '+ ckpt_f)
saver.restore(sess, ckpt_f)
summary_wrt = tf.summary.FileWriter(logdir,sess.graph)
if restore_step in ['', 'latest']:
for i in range(start_step, train_steps):
_, cur_loss, cur_train_eval, summary = sess.run([train_op, loss, eval_op, summary_op_train], \
feed_dict={handle: handle_train, keep_prob: 0.5} )
# log to stdout and eval validation set
if i % 100 == 0 or i == train_steps-1:
saver.save(sess, ckpts_dir+ckpt_nm, global_step=i) # save variables
summary_wrt.add_summary(summary, global_step=i)
cur_val_loss, cur_val_eval, summary = sess.run([loss, eval_op, summary_op_val], \
feed_dict={handle: handle_val, keep_prob: 1.0})
if cur_val_loss < best_loss:
best_loss = cur_val_loss
best_step = i
summary_wrt.add_summary(summary, global_step=i)
print 'step %5d: loss %.5f, acc %.5f --- loss val %0.5f, acc val %.5f'%(i, \
cur_loss, cur_train_eval, cur_val_loss, cur_val_eval)
# sess.run(init_train)
with open(ckpts_dir+'best.step','w') as f:
f.write('best step is %d\n'%best_step)
print 'best step is %d'%best_step
# eval test set
test_loss, test_eval = sess.run([loss, eval_op], feed_dict={handle: handle_test, keep_prob: 1.0})
print 'eval test: loss %.5f, acc %.5f'%(test_loss, test_eval)
实验结果:
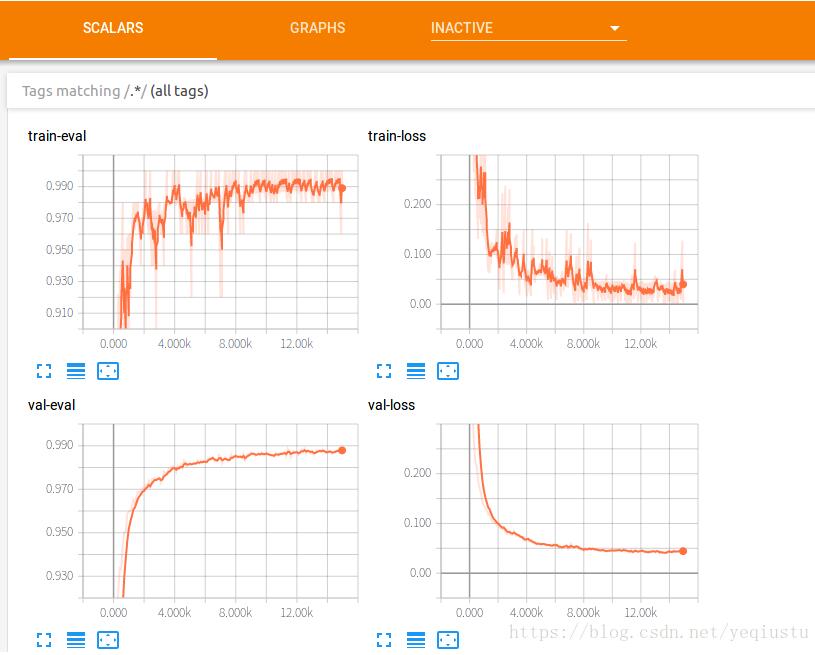
以上这篇tensorflow入门:tfrecord 和tf.data.TFRecordDataset的使用就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
tensorflow入门:TFRecordDataset变长数据的batch读取详解
在上一篇文章tensorflow入门:tfrecord 和tf.data.TFRecordDataset的使用里,讲到了使用如何使用tf.data.TFRecordDatase来对tfrecord文件进行batch读取,即使用dataset的batch方法进行:但如果每条数据的长度不一样(常见于语音.视频.NLP等领域),则不能直接用batch方法获取数据,这时则有两个解决办法: 1.在把数据写入tfrecord时,先把数据pad到统一的长度再写入tfrecord:这个方法的问题在于:若是有大量
-
Tensorflow中使用tfrecord方式读取数据的方法
前言 本博客默认读者对神经网络与Tensorflow有一定了解,对其中的一些术语不再做具体解释.并且本博客主要以图片数据为例进行介绍,如有错误,敬请斧正. 使用Tensorflow训练神经网络时,我们可以用多种方式来读取自己的数据.如果数据集比较小,而且内存足够大,可以选择直接将所有数据读进内存,然后每次取一个batch的数据出来.如果数据较多,可以每次直接从硬盘中进行读取,不过这种方式的读取效率就比较低了.此篇博客就主要讲一下Tensorflow官方推荐的一种较为高效的数据读取方式--tfre
-
tensorflow中tf.slice和tf.gather切片函数的使用
tf.slice(input_, begin, size, name=None):按照指定的下标范围抽取连续区域的子集 tf.gather(params, indices, validate_indices=None, name=None):按照指定的下标集合从axis=0中抽取子集,适合抽取不连续区域的子集 输出: input = [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]], [[5, 5, 5], [6, 6, 6]]] tf.slice(
-
tensorflow入门:tfrecord 和tf.data.TFRecordDataset的使用
1.创建tfrecord tfrecord支持写入三种格式的数据:string,int64,float32,以列表的形式分别通过tf.train.BytesList.tf.train.Int64List.tf.train.FloatList写入tf.train.Feature,如下所示: tf.train.Feature(bytes_list=tf.train.BytesList(value=[feature.tostring()])) #feature一般是多维数组,要先转为list tf.t
-

Tensorflow中TFRecord生成与读取的实现
目录 一.为什么使用TFRecord? 二. 生成TFRecord简单实现方式 三. 生成TFRecord文件完整代码实例 TFRecord读取 四. 读取TFRecord的简单实现方式 五.tf.contrib.slim模块读取TFrecord文件完整代码实例 参考: 一.为什么使用TFRecord? 正常情况下我们训练文件夹经常会生成 train, test 或者val文件夹,这些文件夹内部往往会存着成千上万的图片或文本等文件,这些文件被散列存着,这样不仅占用磁盘空间,并且再被一个个读取的时
-
Tensorflow使用tfrecord输入数据格式
Tensorflow 提供了一种统一的格式来存储数据,这个格式就是TFRecord,上一篇文章中所提到的方法当数据的来源更复杂,每个样例中的信息更丰富的时候就很难有效的记录输入数据中的信息了,于是Tensorflow提供了TFRecord来统一存储数据,接下来我们就来介绍如何使用TFRecord来同意输入数据的格式. 1. TFRecord格式介绍 TFRecord文件中的数据是通过tf.train.Example Protocol Buffer的格式存储的,下面是tf.train.Exampl
-
python深度学习tensorflow入门基础教程示例
目录 正文 1.编辑器 2.常量 3.变量 4.占位符 5.图(graph) 例子1:hello world 例子2:加法和乘法 例子3: 矩阵乘法 正文 TensorFlow用张量这种数据结构来表示所有的数据. 用一阶张量来表示向量,如:v = [1.2, 2.3, 3.5] ,如二阶张量表示矩阵,如:m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]],可以看成是方括号嵌套的层数. 1.编辑器 编写tensorflow代码,实际上就是编写py文件,最好找一个好用的编辑器
-
tensorflow之变量初始化(tf.Variable)使用详解
默认本系列的的读者已经初步熟悉tensorflow. 我们通过tf.Variable构造一个variable添加进图中,Variable()构造函数需要变量的初始值(是一个任意类型.任意形状的tensor),这个初始值指定variable的类型和形状.通过Variable()构造函数后,此variable的类型和形状固定不能修改了,但值可以用assign方法修改. 如果想修改variable的shape,可以使用一个assign op,令validate_shape=False. 通过Varia
-
TensorFlow的reshape操作 tf.reshape的实现
初学tensorflow,如果写的不对的,请更正,谢谢! tf.reshape(tensor, shape, name=None) 函数的作用是将tensor变换为参数shape的形式. 其中shape为一个列表形式,特殊的一点是列表中可以存在-1.-1代表的含义是不用我们自己指定这一维的大小,函数会自动计算,但列表中只能存在一个-1.(当然如果存在多个-1,就是一个存在多解的方程了) 好了我想说的重点还有一个就是根据shape如何变换矩阵.其实简单的想就是, reshape(t, shape)
-
TensorFlow入门使用 tf.train.Saver()保存模型
关于模型保存的一点心得 saver = tf.train.Saver(max_to_keep=3) 在定义 saver 的时候一般会定义最多保存模型的数量,一般来说,如果模型本身很大,我们需要考虑到硬盘大小.如果你需要在当前训练好的模型的基础上进行 fine-tune,那么尽可能多的保存模型,后继 fine-tune 不一定从最好的 ckpt 进行,因为有可能一下子就过拟合了.但是如果保存太多,硬盘也有压力呀.如果只想保留最好的模型,方法就是每次迭代到一定步数就在验证集上计算一次 accurac
-
tensorflow入门之训练简单的神经网络方法
这几天开始学tensorflow,先来做一下学习记录 一.神经网络解决问题步骤: 1.提取问题中实体的特征向量作为神经网络的输入.也就是说要对数据集进行特征工程,然后知道每个样本的特征维度,以此来定义输入神经元的个数. 2.定义神经网络的结构,并定义如何从神经网络的输入得到输出.也就是说定义输入层,隐藏层以及输出层. 3.通过训练数据来调整神经网络中的参数取值,这是训练神经网络的过程.一般来说要定义模型的损失函数,以及参数优化的方法,如交叉熵损失函数和梯度下降法调优等. 4.利用训练好的模型预测
-
详解Python使用tensorflow入门指南
TensorFlow是Google公司2015年11月开源的第二代深度学习框架,是第一代框架DistBelief的改进版本. TensorFlow支持python和c/c++语言, 可以在cpu或gpu上进行运算, 支持使用virtualenv或docker打包发布. 定义变量 为了使用tensorflow,首先我们需要导入它 import tensorflow as tf 对于符号变量,我们新建一个 x = tf.placeholder(tf.float32, [None, 784]) 这里x