C++浮点型的存储方式详解
目录
- 浮点型及其存储方式
- 一、IEEE浮点标准
- 二、存储方式
- IEEE 754对有效数字M和指数E的规定。
- 重点:
- 根据指数域不同取值分为一下三种情况:
- 总结
浮点型及其存储方式
有些时候需要变量能存储带小数点的数,或者能存储极大数或极小数。这类数可以用浮点(因小数点是“浮动的”而得名)格式进行存储。C语言提供了3种浮点类型,对应三种不同的浮点格式。
当精度要求不严格时(小数点后少于六位),float类型是很适合的类型。double提供更高的精度, 对绝大多数程序来说够用了。longdouble支持极高精度的要求,很少会用到。
C标准没有说明float、double和long double类型提供的的精度到底是多少,因为不同计算机可以用不同方法存储浮点数。大多数现代计算机遵循IEEE754标准(即IEC 60559) 的规范,所以这里也将它作为一个示例。
一、IEEE浮点标准
由IEEE开发的IEEE标准提供了两种主要的浮点数格式:单精度(32位) 和双精度(64位)。数值以科学记数法的形式存储,每一个数都由三部分组成:符号、指数和小数。指数部分的位数说明了数值的可能大小程度,而小数部分的位数说明了精度。单精度格式中,指数长度为8位,而小数部分占了23位。因此,单精度数可以表示的最大值大约是3.40×1038,其中精度是6个十进制数字。
IEEE标准还描述了另外两种格式:单扩展精度和双扩展精度。标准没有指明这些格式中的位数,但要求单扩展精度类型至少为43位,而双扩展精度类型至少为79位。
| 类型 | 最小值 | 最大值 | 精度 | 备注 |
|---|---|---|---|---|
| ●float | 1.175 49×10-38 | 3.402 82×1038 | 小数点后6位 | 单精度32位 |
| ●double | 2.225 07×10-308 | 1.797 69×10308 | 小数点后15位 | 双精度64位 |
上表给出了根据IEEE标准实现的浮点类型特征。[表中给出了规范化的最小正值, 非规范化的数可以更小。] long double类型没有显示在此表中, 因为它的长度随着机器的不同而变化,而最常见的大小是80位和128位。
二、存储方式
对于浮点型数据,首先我们需要明白的一点是:浮点数和整型数的编码方式是不一样的,IEEE浮点标准采用如下形式来标识一个浮点数。
V = (-1)S M 2E
- (-1)S 表示符号位,当S=0时,表示正数,当S=1时,表示负数。
- M 表示有效数字,是一个二进制小数,其值大于等于1,小于2。
- 2E 表示指数位。
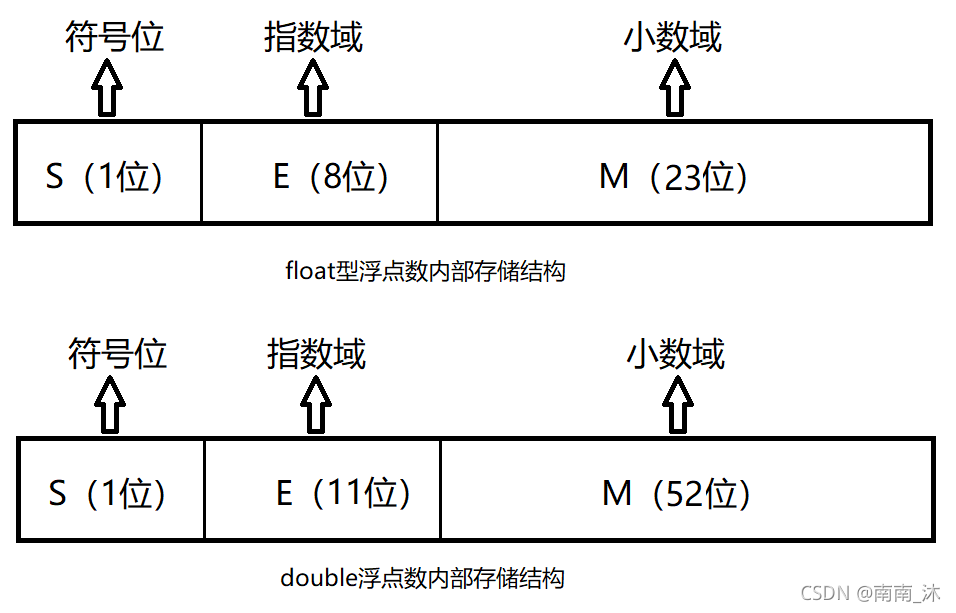
下面,我将用float作为例子,double道理也是一样的,只是位数有所不同。
例如:十进制数:88.8125 —> 二进制为:101 1000.1101
然后将101 1000.1101化成上述公式M的形式,其范围是[1,2),所以将小数点左移6位,得到1.0110001101×26(这里不懂的话对比十进制,小数点左移一位乘以10,二进制则乘以2)。
最后得到S = 0、M = 1.0110001101、E = 6,但是事情并没有那么简单,我们接着往下看。
IEEE 754对有效数字M和指数E的规定。
1、有效数字M:
1<=M<2,也就是说,M写成1.xxx……的形式,其中xxx……表示小数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存小数部分。比如保存1.0110001101时,只保存0110001101,后面的位数补0就可以了,等到读取的时候,再把第一位的1补上去。
2、指数E:
首先,E为一个无符号整数(unsigned int)
如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。但是,我们知道,科学计数法是可以出现负数的,所以IEEE 754规定,存入内存的E是真实值加上一个中间数,对于8位的E,中间数是127,对于11位的E,中间数是1023。比如,26 的E是6,所以保存为32位浮点数时,必须保存为6+127=133,即10000101。
重点:
结合上述补充的信息完善例子
float:
十进制数:88.8125 二进制为:101 1000.1101 == 1.0110001101×26
- 符号位:0
- 指数位:6+127=133 二进制为:1000 0101
- 小数位:1.0110001101去掉最高位1则为:0110001101
因此浮点数88.8125的IEEE浮点表示为:
----0----1000 0101----011 0001 1010 0000 0000 0000
符号位- -指数域- - - - - - - - - - -小数域
根据指数域不同取值分为一下三种情况:
1)E不全为0或不全为1(规格化值)
这是最常见情况,取出内存中的数时,指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第一位的1。
2)E全为0(非规格化值)
这时,浮点数的指数E等于1-127(或1-1023)即为真实值,有效数字M不再加上第一位的1,而是还原为0.xxxxxxx的小数。这样做是为了表示正负零,以及接近于0的很小的数字。
举个例子:编码为如下情形:
0 0000 0000 000 0000 0000 0000 0000 0001
即2(-23)×2(-126)=2(-149),转成10进制大约等于1.4×10(-45),这就是单精度所能表达最小的正数了。
3)E全为1(特殊数值)
当指数域全为1时属于这种情形。此时,如果小数域全为0且符号域S=0,则表示正无穷,如果小数域全为0且符号域S=1,则表示负无穷。如果小数域不全为0时,浮点数将被解释为NaN, 即不是一个数(Not a Number) 。比如计算负数平方根或处理未初始化数据时。
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
详解C++中的自动存储
C++有3种管理数据内存的方式即自动存储(栈存储).静态存储和动态存储(堆存储).在不同的方式下,内存的分配形式和存在时间的长短都不同. 下面对自动存储进行说明. 自动存储(栈存储) 对于函数的形参.内部声明的变量及结构变量等,编译器将在函数执行时为形参自动分配存储空间,在执行到变量和结构变量等的声明语句时为其自动分配存储空间,因此称其为自动变量(Automatic Variable),有的教科书也称其为局部变量,在函数执行完毕返回时,这些变量将被撤销,对应的内存空间将被释放. 事实上,自动变量
-
C/C++的浮点数在内存中的存储方式分析及实例
C/C++的浮点数在内存中的存储方式分析 任何数据在内存中都是以二进制的形式存储的,例如一个short型数据1156,其二进制表示形式为00000100 10000100.则在Intel CPU架构的系统中,存放方式为 10000100(低地址单元) 00000100(高地址单元),因为Intel CPU的架构是小端模式.但是对于浮点数在内存是如何存储的?目前所有的C/C++编译器都是采用IEEE所制定的标准浮点格式,即二进制科学表示法. 在二进制科学表示法中,S=M*2^N 主要由三部分构成
-
C++实现线性表链式存储(单链)
本文实例为大家分享了C++实现线性表链式存储的具体代码,供大家参考,具体内容如下 实现的功能: 1.定义了三中传入不同参数的构造函数,用于初始化创建不同的链表: 2.能实现增.删.查等基本功能: 存在的问题: 当创建一个已知大小的空链表后,链表中的数据并不为空,见下图: 下面是代码及测试结果: singlelinklist.h #pragma once #include "iostream" #include "exception" #include "s
-
深入C/C++浮点数在内存中的存储方式详解
任何数据在内存中都是以二进制的形式存储的,例如一个short型数据1156,其二进制表示形式为00000100 10000100.则在Intel CPU架构的系统中,存放方式为 10000100(低地址单元) 00000100(高地址单元),因为Intel CPU的架构是小端模式.但是对于浮点数在内存是如何存储的?目前所有的C/C++编译器都是采用IEEE所制定的标准浮点格式,即二进制科学表示法.在二进制科学表示法中,S=M*2^N 主要由三部分构成:符号位+阶码(N)+尾数(M).对于flo
-
C++ 自由存储区是否等价于堆你知道吗
目录 free store" VS "heap" 问题的来源 结论 free store" VS "heap" 当我问你C++的内存布局时,你大概会回答: "在C++中,内存区分为5个区,分别是堆.栈.自由存储区.全局/静态存储区.常量存储区". 如果我接着问你自由存储区与堆有什么区别,你或许这样回答: "malloc在堆上分配的内存块,使用free释放内存,而new所申请的内存则是在自由存储区上,使用delete来
-

C++浮点型的存储方式详解
目录 浮点型及其存储方式 一.IEEE浮点标准 二.存储方式 IEEE 754对有效数字M和指数E的规定. 重点: 根据指数域不同取值分为一下三种情况: 总结 浮点型及其存储方式 有些时候需要变量能存储带小数点的数,或者能存储极大数或极小数.这类数可以用浮点(因小数点是"浮动的"而得名)格式进行存储.C语言提供了3种浮点类型,对应三种不同的浮点格式. 当精度要求不严格时(小数点后少于六位),float类型是很适合的类型.double提供更高的精度, 对绝大多数程序来说够用了.longd
-
Android 文件存储与SharedPreferences存储方式详解用法
目录 持久化技术简介 文件存储 1. 将数据存储到文件中 2. 从文件中读取数据 SharedPreferences 存储 1. 将数据存储到 SharedPreferences 中 2. 从 SharedPreferences 中读取数据 持久化技术简介 数据持久化就是指将那些内存中的瞬时数据保存到存储设备中,保证即使在手机或计算机关机的情况下,这些数据也不会丢失.保存在内存中的数据是处于瞬时状态的,而保存在存储设备的数据是处于持久状态的.持久化技术提供了一种机制,可以让数据在瞬时状态和持久状
-
Android开发笔记之: 数据存储方式详解
无论是神马平台,神马开发环境,神马软件程序,数据都是核心.对于开发平台来讲,如果对数据的存储有良好的支持,那么对应用程序的开发将会有很大的促进作用.总体的来讲,数据存储方式有三种:一个是文件,一个是数据库,另一个则是网络.其中文件和数据库可能用的稍多一些,文件用起来较为方便,程序可以自己定义格式:数据库用起稍烦锁一些,但它有它的优点,比如在海量数据时性能优越,有查询功能,可以加密,可以加锁,可以跨应用,跨平台等等:网络,则用于比较重要的事情,比如科研,勘探,航空等实时采集到的数据需要马上通过网络
-
5个HTML5的常用本地存储方式详解与介绍
在 HTML5 规范之前,存储主要是用 cookies .但cookies也有缺点: 在请求头上带着数据: 大小是 4k 之内: 主 Domain 污染: cookies 的主要应用:购物车.客户登录. 由于存在这么多缺点,因此我们需要解决以下问题: 解决 4k 的大小问题: 解决请求头常带存储信息的问题: 解决关系型存储的问题: 跨浏览器: HTML5的5种存储方式 1. 本地存储 localstorage 存储方式: 以键值对( Key-Value)的方式存储,永久存储,永不失效,除非手动删
-
Android开发之数据的存储方式详解
在Android中,数据的存储分为两种方式: 1.直接以文件的形式存储在目录中 2.以json格式存储在数据库中 将数据以文件的存储又分为两种方式: 1.生成.txt文件 2.生成xml文件 那么今天就来详细的说一下以文件的形式存储,由于没有讲到数据库,在之后的课程中会讲到json格式存储在数据库中. 一.生成.txt文件 文件的生成无非就是我们Java中学习的输入输出流中的一部分,有Java基础相信都是很容易理解的,因为它真的很简单啦~~ 1.生成目录可以分为两种: 1)本机 2)SD卡 2.
-
基于String变量的两种创建方式(详解)
在java中,有两种创建String类型变量的方式: String str01="abc";//第一种方式 String str02=new String("abc")://第二种方式 第一种方式创建String变量时,首先查找JVM方法区的字符串常量池是否存在存放"abc"的地址,如果存在,则将该变量指向这个地址,不存在,则在方法区创建一个存放字面值"abc"的地址. 第二种方式创建String变量时,在堆中创建一个存放&q
-
EventStore文件存储设计详解
背景 ENode是一个CQRS+Event Sourcing架构的开发框架,Event Sourcing需要持久化事件,事件可以持久化在DB,但是DB由于面向的是CRUD场景,是针对数据会不断修改或删除的场景,所以内部实现会比较复杂,性能也相对比较低.而Event Store实际上对数据只有新增和查询的需求,所以我想为Event Sourcing的场景针对性的实现一个Event Store.看了一下业界的一些实现,感觉都没有达到我的期望,所以想自己动手实现一个.下面是我构思的一个Event St
-
MySQL高级学习笔记(三):Mysql逻辑架构介绍、mysql存储引擎详解
Mysql逻辑架构介绍总体概览 和其它数据库相比,MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用.主要体现在存储引擎的架构上,插件式的存储引擎架构将查询处理和其它的系统任务以及数据的存储提取相分离 . 这种架构可以根据业务的需求和实际需要选择合适的存储引擎. controller层: Connectors:连接层,c .java等连接mysql 业务逻辑处理成: Connection Pool:连接层 c3p0连接池等 Manager Service util:备份.容灾
-
Spring Data Jpa的四种查询方式详解
这篇文章主要介绍了Spring Data Jpa的四种查询方式详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.调用接口的方式 1.基本介绍 通过调用接口里的方法查询,需要我们自定义的接口继承Spring Data Jpa规定的接口 public interface UserDao extends JpaRepository<User, Integer>, JpaSpecificationExecutor<User> 使用这