Python接口测试结果集实现封装比较
引言
接口测试执行完后,我们需要进行断言,断言的主要目的是用代码来判断实际结果和预期结果是否一致,这跟手工测试中用肉眼去判断是一样的思路。既然这样,我们可以将已知的预期结果和未知的实际结果简单的封装成一个类,然后写一个比较的函数来判断,最后得到结果。
知识点预热
在讲代码之前,先了解一下python的运算符is和==。可能有些人经常用,但是却不知道是什么意思,知其然而不知其所以然。
python对象包括三个基本要素:id(身份标识)、type(数据类型)和value(值)。
1、"is" 是身份运算符,判断两个对象是否相同,是判断id是否相同,也就是内存地址是否相同。
2、"=="是比较运算符,判断两个对象的值是否相同,也就是value。
示例:
# 数值型

# 字符串

# 元组
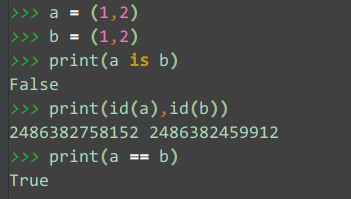
# 列表
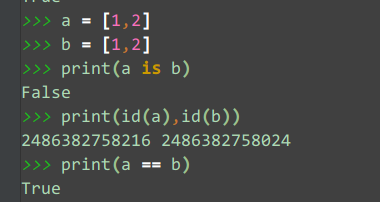
# 字典

# 集合

结论:通过上面几个例子可以看出,两个对象只有int和str的时候,a is b才为True。而当a和b是tuple,list,dict或set型时,a is b为False。
封装
上面已经介绍了如何比较两个对象是否相同,那么我们在比较两个结果,实际结果和预期结果是否相同也可以用这种方法,但是一定要记住是比较value还是内存地址。现在我简单对判断测试结果进行封装,不过这里我用的是包含,当然你可以用"=="。
具体代码:
__author__ = 'Leo'
class CompareStr(object):
def is_contains(self,str1,str2):
"""
判断预期结果与实际结果是否相同
:param str1: 预期结果
:param str2: 实际结果
:return flag: 标记
"""
self.flag = None
if str1 in str2:
self.flag = True
else:
flag = False
return self.flag
if __name__ == '__main__':
cs = CompareStr()
print(cs.is_contains('123','123456'))
运行结果:

总结
以上内容是一个简单的知识点,简单进行封装。小知识点容易被忽略,记一记总是好的。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python接口调用已训练好的caffe模型测试分类方法
训练好了model后,可以通过python调用caffe的模型,然后进行模型测试的输出. 本次测试主要依靠的模型是在caffe模型里面自带训练好的结构参数:~/caffe/models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel,以及结构参数 :~/caffe/models/bvlc_reference_caffenet/deploy.prototxt相结合,用python接口进行调用. 训练的源代码以及相应的注释如下所示
-
python实现接口并发测试脚本
常用的网站性能测试指标有:并发数.响应时间.吞吐量.性能计数器等. 1.并发数 并发数是指系统同时能处理的请求数量,这个也是反应了系统的负载能力. 2.响应时间 响应时间是一个系统最重要的指标之一,它的数值大小直接反应了系统的快慢.响应时间是指执行一个请求从开始到最后收到响应数据所花费的总体时间. 3.吞吐量 吞吐量是指单位时间内系统能处理的请求数量,体现系统处理请求的能力,这是目前最常用的性能测试指标. QPS(每秒查询数).TPS(每秒事务数)是吞吐量的常用量化指标,另外还有HPS(每秒HT
-

Python + Requests + Unittest接口自动化测试实例分析
本文实例讲述了Python + Requests + Unittest接口自动化测试.分享给大家供大家参考,具体如下: 1. 介绍下python的requests模块 Python Requests快速入门 :http://cn.python-requests.org/zh_CN/latest/ 想必会Python基础的小伙伴们一看就懂了 2. Requests接口自动化测试: 2.1 如何利用这么利器进行接口测试,请看小demo: # -*- coding:utf-8 -* import re
-
python Django编写接口并用Jmeter测试的方法
一.环境准备 python3.6.7 Pycharm 二.创建项目 我这里是在Django项目中新建了个APP,目录结构如下图所示: 那么怎么在已有的Django项目中新建APP并进行配置呢: 2.1.新建app a.可以在终端输入命令:python manage.py startapp myapp(这里myapp是指你自己app的名称),如下图所示: b.也可以在pycharm中找到Tools-->Run manage.py Task, 在弹出的命令框中输入:startapp myapp(这里
-
对python自动生成接口测试的示例讲解
在python中Template可以将字符串的格式固定下来,重复利用. 同一套测试框架为了可以复用,所以我们可以将用例部分做参数化,然后运用到各个项目中. 代码如下: coding=utf-8 ''' 作者:大石 功能:自动生成pyunit框架下的接口测试用例 环境:python2.7.6 用法:将用户给的参数处理成对应格式,然后调用模块类生成函数,并将参数传入即可 ''' from string import Template #动态生成单个测试用例函数字符串 def singleMethod
-
Python3+Requests+Excel完整接口自动化测试框架的实现
框架整体使用Python3+Requests+Excel:包含对实时token的获取 1.------base -------runmethond.py runmethond:对不同的请求方式进行封装 import json import requests requests.packages.urllib3.disable_warnings() class RunMethod: def post_main(self, url, data, header=None): res = None if
-
Python 保持登录状态进行接口测试的方法示例
记录三种添加cookie保持接口登录状态的方法,方便自己回顾. 1.简单粗暴式. 此方法比较小白,前提是已经通过fiddler抓包等方式拿到了cookie,然后直接塞进去. import requests trainsUrl ='http://XXX.com/trains' headers = { "Content-Type":"application/json;charset=UTF-8", } cookies = { "XXXthor":&q
-
Python接口测试结果集实现封装比较
引言 接口测试执行完后,我们需要进行断言,断言的主要目的是用代码来判断实际结果和预期结果是否一致,这跟手工测试中用肉眼去判断是一样的思路.既然这样,我们可以将已知的预期结果和未知的实际结果简单的封装成一个类,然后写一个比较的函数来判断,最后得到结果. 知识点预热 在讲代码之前,先了解一下python的运算符is和==.可能有些人经常用,但是却不知道是什么意思,知其然而不知其所以然. python对象包括三个基本要素:id(身份标识).type(数据类型)和value(值). 1."is"
-
Python接口自动化浅析logging封装及实战操作
在上一篇Python接口自动化测试系列文章:Python接口自动化浅析logging日志原理及模块操作流程,主要介绍日志相关概念及logging日志模块的操作流程. 而在此之前介绍过yaml封装,数据驱动.配置文件.日志文件等独立的功能,我们将这些串联起来,形成一个完整的接口测试流程. 以下主要介绍将logging常用配置放入yaml配置文件.logging日志封装及结合登录用例讲解日志如何在接口测试中运用. 一.yaml配置文件 将日志中的常用配置,比如日志器名称.日志器等级及格式化放在配置文
-
Python面向对象程序设计类的封装与继承用法示例
本文实例讲述了Python面向对象程序设计类的封装与继承用法.分享给大家供大家参考,具体如下: 访问限制(封装) 1.概念 面向对象语言的三大特征:封装, 继承, 多态. 广义的封装: 类和函数的定义本身就是封装的体现. 狭义的封装:一个类的某些属性,不希望外界直接访问,而是把这个属性私有化[只有当前类持有],然后暴露给外界一个访问的方法. 封装的本质:就是属性私有化的过程. 封装的好处:提供了数据的复用性,保证了数据的安全性. 举例:插排 2.使用 class Person(object):
-
Python测试Kafka集群(pykafka)实例
生产者代码: # -* coding:utf8 *- from pykafka import KafkaClient host = 'IP:9092, IP:9092, IP:9092' client = KafkaClient(hosts = host) print client.topics # 生产者 topicdocu = client.topics['my-topic'] producer = topicdocu.get_producer() for i in range(100):
-
Python 实现训练集、测试集随机划分
随机从列表中取出元素: import random dataSet = [[0], [1], [2], [3], [4], [5], [6], [7], [8], [9], [10]] trainDataSet = random.sample(dataSet, 3) 以下函数,使用于我最近的一个机器学习的项目,将数据集数据按照比例随机划分成训练集数据和测试集数据: import csv import random def getDataSet(proportion): """
-
Python实现对adb命令封装
我就废话不多说了,大家还是直接看代码吧! #!/usr/bin/evn python # -*- coding:utf-8 -*- # FileName adbtools.py # Author: HeyNiu # Created Time: 2016/9/19 """ adb 工具类 """ import os import platform import re import time import utils.timetools class
-
python连接mongodb集群方法详解
简单的测试用例 #!/usr/bin/python # -*- coding: UTF-8 -*- import time from pymongo import MongoClient # 连接单机 # single mongo # c = MongoClient(host="192.168.89.151", port=27017) # 连接集群 c = MongoClient('mongodb://192.168.89.151,192.168.89.152,192.168.89.1
-
python 如何对logging日志封装
作者:做梦的人(小姐姐) 出处:https://www.cnblogs.com/chongyou/ 因为最近在做平台,发现有同事,使用django封装了日志模块,看样子很简单,准备自己单独做了一个日志封装模板,对于python不熟练的我,封装部分参考了多个博主的内容,形成自己的日志模块,内容如下: 封装部分 创建一个logutil2的py文件 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Author: zhangjun # @Date :
-
python 使用paramiko模块进行封装,远程操作linux主机的示例代码
import time import paramiko class HandleParamiko: ''' 定义一个linux处理类 ''' def __init__(self, hostname, password, port=22, username='root'): ''' 构造器 :param hostname: 主机ip,type:str :param password: 密码,type:str :param port: 端口,type:int 默认22 :param username
-
Python面向对象编程之类的封装
目录 1.封装的理解 2.私有类属性.公开类属性.私有实例属性和公开实例属性 2.1 公开类属性 2.2 私有类属性 2.3 公开实例属性 2.4 私有实例属性 2.5 私有属性不一定真的私有 3.私有方法和公开方法 4.类的保留属性 5.类的保留方法 1.封装的理解 封装(Encapsulation):属性和方法的抽象 属性的抽象:对类的属性(变量)进行定义.隔离和保护 分为私有属性和公开属性: 私有属性:只能在类内部访问 公开属性:可以通过类.对象名访问 可以选择公开或隐藏属性,隐藏属性的内