Pandas索引排序 df.sort_index()的实现
df.sort_index()实现按索引排序,默认以从小到大的升序方式排列,如希望按降序排列,传入ascending = False
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# 索引降序
res1 = df.sort_index(ascending=False)
# 按列索引名排序:
# 在索引方向上排序
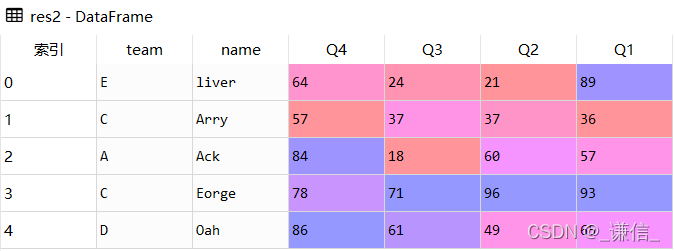
res2 = df.sort_index(axis=1, ascending=False)
结果展示
df
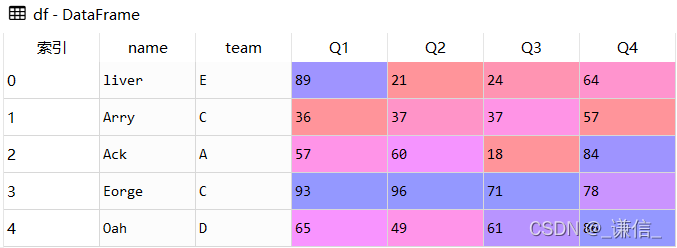
res1

res2
扩展
# 更多方法如下: s.sort_index() # 升序排列 df.sort_index() # df也是按索引进行排序 df.team.sort_index() s.sort_index(ascending=False) # 降序排列 s.sort_index(inplace=True) # 排序后生效,改变原数据 # 索引重新0-(n-1)排,可以得到它的排序号 s.sort_index(ignore_index=True) s.sort_index(na_position='first') # 空值在前,另'last'表示空值在后 s.sort_index(level=1) # 如果多层,排一级 s.sort_index(level=1, sort_remaining=False) # 这层不排 # 行索引排序,表头排序 df.sort_index(axis=1) # 会把列按列名顺序排序
df.reindex()指定自己定义顺序的索引,实现行和列的顺序重新定义
import pandas as pd
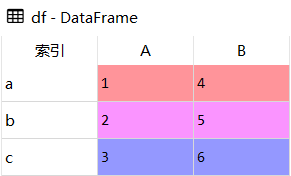
df = pd.DataFrame({
'A':[1,2,3],
'B':[4,5,6]
},index=['a','b','c'])
# 按要求重新指定索引顺序
res1 = df.reindex(['c','b','a'])
# 指定列顺序
res2 = df.reindex(['B','A'], axis=1)
结果展示
df
res1

res2

到此这篇关于Pandas索引排序 df.sort_index()的实现的文章就介绍到这了,更多相关Pandas索引排序 df.sort_index()内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pandas多层索引的创建和取值以及排序的实现
多层索引的创建 普通-多个index创建 在创建数据的时候加入一个index列表,这个index列表里面是多个索引列表 Series多层索引的创建方法 import pandas as pd s = pd.Series([1,2,3,4,5,6],index=[['张三','张三','李四','李四','王五','王五'], ['期中','期末','期中','期末','期中','期末']]) # print(s) s 张三 期中 1 期末 2 李四 期中 3
-
pandas通过索引进行排序的示例
如下所示: import pandas as pd df = pd.DataFrame([1, 2, 3, 4, 5], index=[10, 52, 24, 158, 112], columns=['S']) df.sort_index(inplace=True) print df 以上这篇pandas通过索引进行排序的示例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
浅谈Pandas 排序之后索引的问题
如下所示: In [1]: import pandas as pd ...: df=pd.DataFrame({"a":[1,2,3,4,5],"b":[5,4,3,2,1]}) In [2]: df Out[2]: a b 0 1 5 1 2 4 2 3 3 3 4 2 4 5 1 In [3]: df=df.sort_values(by="b") # 按照b列排序 In [4]: df Out[4]: a b 4 5 1 3 4 2 2 3
-
pandas数据清洗,排序,索引设置,数据选取方法
此教程适合有pandas基础的童鞋来看,很多知识点会一笔带过,不做详细解释 Pandas数据格式 Series DataFrame:每个column就是一个Series 基础属性shape,index,columns,values,dtypes,describe(),head(),tail() 统计属性Series: count(),value_counts(),前者是统计总数,后者统计各自value的总数 df.isnull() df的空值为True df.notnull() df的非空值为T
-

Pandas索引排序 df.sort_index()的实现
df.sort_index()实现按索引排序,默认以从小到大的升序方式排列,如希望按降序排列,传入ascending = False import pandas as pd df = pd.DataFrame([['liver','E',89,21,24,64], ['Arry','C',36,37,37,57], ['Ack','A',57,60,18,84], ['Eorge','C',93,96,71,78], ['Oah','D',65,49,61,86] ], columns = ['
-
Python数据分析Pandas Dataframe排序操作
目录 1.索引的排序 2.值的排序 前言: 数据的排序是比较常用的操作,DataFrame 的排序分为两种,一种是对索引进行排序,另一种是对值进行排序,接下来就分别介绍一下. 1.索引的排序 DataFrame 提供了sort_index()方法来进行索引的排序,通过axis参数指定对行索引排序还是对列索引排序,默认为0,表示对行索引排序,设置为1表示对列索引进行排序:ascending参数指定升序还是降序,默认为True表示升序,设置为False表示降序, 具体使用方法如下: 对行索引进行降序
-
python pandas 数据排序的几种常用方法
前言: pandas中排序的几种常用方法,主要包括sort_index和sort_values. 基础数据: import pandas as pd import numpy as np data = { 'brand':['Python', 'C', 'C++', 'C#', 'Java'], 'B':[4,6,8,12,10], 'A':[10,2,5,20,16], 'D':[6,18,14,6,12], 'years':[4,1,1,30,30], 'C':[8,12,18,8,2] }
-
Python学习笔记之pandas索引列、过滤、分组、求和功能示例
本文实例讲述了Python学习笔记之pandas索引列.过滤.分组.求和功能.分享给大家供大家参考,具体如下: 解析html内容,保存为csv文件 //www.jb51.net/article/162401.htm 前面我们已经把519961(基金编码)这种基金的历史净值明细表html内容抓取到了本地,现在我们还是需要 解析html,取出相关的值,然后保存为csv文件以便pandas来统计分析. from bs4 import BeautifulSoup import os import csv
-
Pandas之排序函数sort_values()的实现
一.sort_values()函数用途 pandas中的sort_values()函数原理类似于SQL中的order by,可以将数据集依照某个字段中的数据进行排序,该函数即可根据指定列数据也可根据指定行的数据排序. 二.sort_values()函数的具体参数 用法: DataFrame.sort_values(by='##',axis=0,ascending=True, inplace=False, na_position='last') 参数说明 参数 说明 by 指定列名(axis=0或
-
Python 中pandas索引切片读取数据缺失数据处理问题
引入 numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢? numpy能够帮我们处理处理数值型数据,但是这还不够 很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等 比如:我们通过爬虫获取到了存储在数据库中的数据 比如:之前youtube的例子中除了数值之外还有国家的信息,视频的分类(tag)信息,标题信息等 所以,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我
-
pandas分组排序 如何获取第二大的数据
Python用来做数据分析很方便,网上很多关于找数据中第二大的方法,但是大多数都是关于SQL的,于是我挑战一下用Python来做这件事(主要是SQL写的不好>_<),上代码. 1.数据我是自己编的 在实际工作中应该从数据库中导入数据,如何从数据库导出数据,我之后会补充. import pandas as pd df = pd.DataFrame([ {"class": 1, "name": "aa", "english&qu
-
Python pandas索引的设置和修改方法
目录 前言 创建索引 pd.Index pd.IntervalIndex pd.CategoricalIndex pd.DatetimeIndex pd.PeriodIndex pd.TimedeltaIndex 读取数据 set_index reset_index set_axis 操作行索引 操作列索引 rename 字典形式 函数形式 使用案例 按日统计总消费 按日.性别统计小费均值,消费总和 笨方法 总结 前言 本文主要是介绍Pandas中行和列索引的4个函数操作: set_index
-
Pandas数值排序 sort_values()的使用
参数解释 DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', # last,first:默认是last ignore_index=False, key=None) 参数的具体解释为: by:表示根据什么字段或者索引进行排序,可以是一个或多个 axis:排序是在横轴还是纵轴,默认是纵轴axis=0 ascending:排序结果是升序还是降序,默认