Python+pandas编写命令行脚本操作excel的tips详情
目录
- 一、python logging日志模块简单封装
- 二、pandas编写命令行脚本操作excel的小tips
- 1、tips
- 1.1使用说明格式
- 1.2接收操作目录方法
- 1.3检测并读取目录下的excel,并限制当前目录只能放一个excel
- 1.4备份excel
- 1.5报错暂停,并显示异常信息
- 1.6判断excel是否包含某列,不包含就新建
- 1.7进度展示与阶段保存
一、python logging日志模块简单封装
项目根目录创建 utils/logUtil.py
import logging
from logging.handlers import TimedRotatingFileHandler
from logging.handlers import RotatingFileHandler
class Log(object):
STAND = "stand" # 输出到控制台
FILE = "file" # 输出到文件
ALL = "all" # 输出到控制台和文件
def __init__(self, mode=STAND):
self.LOG_FORMAT = "%(asctime)s - %(levelname)s - %(message)s"
self.logger = logging.getLogger()
self.init(mode)
def debug(self, msg):
self.logger.debug(msg)
def info(self, msg):
self.logger.info(msg)
def warning(self, msg):
self.logger.warning(msg)
def error(self, msg):
self.logger.error(msg)
def init(self, mode):
self.logger.setLevel(logging.DEBUG)
if mode == "stand":
# 输出到控制台 ------
self.stand_mode()
elif mode == "file":
# 输出到文件 --------
self.file_mode()
elif mode == "all":
# 输出到控制台和文件
self.stand_mode()
self.file_mode()
def stand_mode(self):
stand_handler = logging.StreamHandler()
stand_handler.setLevel(logging.DEBUG)
stand_handler.setFormatter(logging.Formatter(self.LOG_FORMAT))
self.logger.addHandler(stand_handler)
def file_mode(self):
'''
filename:日志文件名的prefix;
when:是一个字符串,用于描述滚动周期的基本单位,字符串的值及意义如下:
“S”: Seconds
“M”: Minutes
“H”: Hours
“D”: Days
“W”: Week day (0=Monday)
“midnight”: Roll over at midnight
interval: 滚动周期,单位有when指定,比如:when='D',interval=1,表示每天产生一个日志文件;
backupCount: 表示日志文件的保留个数;
'''
# 输出到文件 -----------------------------------------------------------
# 按文件大小输出
# file_handler = RotatingFileHandler(filename="my1.log", mode='a', maxBytes=1024 * 1024 * 5, backupCount=10, encoding='utf-8') # 使用RotatingFileHandler类,滚动备份日志
# 按时间输出
file_handler = TimedRotatingFileHandler(filename="my.log", when="D", interval=1, backupCount=10,
encoding='utf-8')
file_handler.setLevel(logging.DEBUG)
file_handler.setFormatter(logging.Formatter(self.LOG_FORMAT))
self.logger.addHandler(file_handler)
log = Log(mode=Log.STAND)
使用方法:
from utils.logUtil import log
if __name__ == '__main__':
log.debug("debug msg")
log.info("info msg")
log.warning("warning msg")
log.error("error msg")
跑一下测试结果:
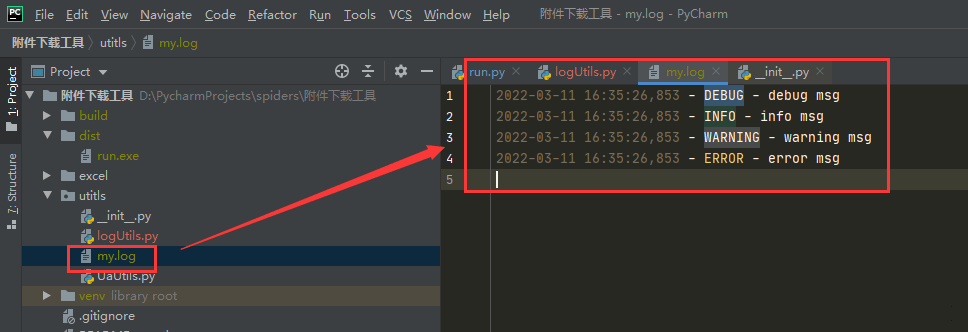
二、pandas编写命令行脚本操作excel的小tips
这里用上面日志小工具
如果不想用这个,可以把日志输出的代码换成 print() 或者删掉
1、tips
1.1使用说明格式
# 使用说明 -----------------------------------
time.sleep(1)
print('===========================================================')
print('简单说明:使用正则表达式拆分excel表中不规范的作者,初步提取对应需求字段')
print('PS:')
print('1.文件夹下需要有一个excel(只放一个,名称随意),其中一列“作者”保存着待拆分的作者')
print('2.拆分后的excel将新增几列拆分结果列,以 <作者>[拆分] 作为列名标记')
print('===========================================================')
time.sleep(1)
# ------------------------------------------
1.2接收操作目录方法
# 输入操作路径 ----------------------------------------------------------------
operate_dir = input('请输入excel目录(旺柴):') # D:\PycharmProjects\spiders\图片下载工具\excel
operate_dir = os.path.abspath(operate_dir)
# operate_dir = os.path.abspath(r'C:\Users\cxstar46\Desktop\正则表达式题名拆分测试')
# -----------------------------------------------------------------------------
1.3检测并读取目录下的excel,并限制当前目录只能放一个excel
# 检测excel数量,只能放一个,当只有一个excel时,提取它的路径excel_path -------
log.info('检查路径下的文件格式...')
excel_name = None
excel_count = 0
file_list = os.listdir(operate_dir)
for file in file_list:
if file.endswith('.xlsx') or file.endswith('.xlx'):
excel_count += 1
excel_name = file
if excel_count == 0:
log.error('文件夹下没有excel')
input('按任意键退出...')
raise Exception(0)
if excel_count > 1:
log.error("无法读取excel,文件夹下有多个excel,或者excel未关闭")
input('按任意键退出...')
raise Exception(0)
# print(excel_name)
# raise Exception(1212)
# ----------------------------------------------------------------------
# print(excel_path)
# print(img_dir)
# 读取excel ----------------------------------------
excel_path = os.path.join(operate_dir, excel_name)
# print(excel_path)
try:
df = pd.read_excel(excel_path)
df = df.where(df.notnull(), None)
except Exception as e:
log.error(e)
log.error('文件不存在或已损坏...')
input('按任意键退出...')
raise Exception(0)
# -------------------------------------------------
# 打印excel行数
print(df.shape[0])
1.4备份excel
# 备份原始excel表 --------------------------------------------------------------
log.info('备份excel...')
bak_dir = '封面上传前的备份' # 备份文件夹的名称
file_list = os.listdir(operate_dir)
if bak_dir not in file_list:
os.makedirs(os.path.join(operate_dir, bak_dir))
bak_excel_path = os.path.join(os.path.join(operate_dir, bak_dir), "{}_{}".format(datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S"), excel_name))
shutil.copyfile(excel_path, bak_excel_path)
# -----------------------------------------------------------------------------
1.5报错暂停,并显示异常信息
try:
raise Exception("执行业务报错")
except Exception as e:
import traceback
log.error(traceback.format_exc()) # 记录异常信息
input('执行完毕,按任意键继续...')
1.6判断excel是否包含某列,不包含就新建
cover_ruid_col_name = "封面ruid"
# 没有封面ruid这一列就创建
if cover_ruid_col_name not in df.columns.values:
df.loc[:, cover_ruid_col_name] = None
1.7进度展示与阶段保存
# 读取excel
excel_path = './封面上传测试.xlsx'
df = pd.read_excel(excel_path)
review_col = "审核结果"
# 没有“审核结果”这一列就创建
if review_col not in df.columns.values:
df.loc[:, review_col] = None
for i in range(df.shape[0]):
# 打印进度 ---------------------------------------------
log.info("----------------------------------")
log.info("当前进度: {} / {}".format(i+1, df.shape[0]))
# ----------------------------------------------------
# 执行表格插入业务
# 判断业务
# 吧啦吧啦
# 业务执行结果插入原表
df.loc[i, "审核结果"] = "好耶"
# 阶段性保存 ----------------------------
save_space = 200 # 每执行两百行保存一次
if i+1 % save_space == 0 and i != 0:
df.to_excel(excel_path, index=0)
log.info("阶段性保存...")
# -------------------------------------
到此这篇关于Python+pandas编写命令行脚本操作excel的tips详情的文章就介绍到这了,更多相关Python操作excel的tips内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python Pandas多种添加行列数据方法总结
目录 前言 1. 增加列数据 2. 增加行数据 补充:pandas根据现有列新添加一列 总结 前言 发现自己学习python 的各种库老是容易忘记,所有想利用这个平台,记录和分享一下学习时候的知识点,以后也能及时的复习,最近学习pandas,那我们来看看pandas添加数据的一些方法 创建一个dataframe 1. 增加列数据 为dataframe增加一列新数据,需要确保增加列的长度与原数据保持一致 如果是增加一列相同数据可以直接输入 df['level'] = 1 插入的数据是需要通过源数据
-
Python pandas DataFrame基础运算及空值填充详解
目录 前言 数据对齐 fill_value 空值api dropna fillna 总结 前言 今天我们一起来聊聊DataFrame中的索引. 上一篇文章当中我们介绍了DataFrame数据结构当中一些常用的索引的使用方法,比如iloc.loc以及逻辑索引等等.今天的文章我们来看看DataFrame的一些基本运算. 数据对齐 我们可以计算两个DataFrame的加和,pandas会自动将这两个DataFrame进行数据对齐,如果对不上的数据会被置为Nan(not a number). 首先我们来
-
python实现对excel中需要的数据的单元格填充颜色
前言: 一般处理数据使用的是pandas和numpy库,但是填充单元格颜色需要在excel中,使用的是openpyxl库,所以不能直接达到我们的需求,需要进行两个库的链接使用,先说下openpyxl填充色,pandas是直接读取数据,但是openpyxl则不是,必须要sheet处于active状态,而且必须进行sheet选择才可以读取数据 import openpyxl from openpyxl import load_workbook # 比如打开test.xlsx wb = load_wo
-
Python pandas替换指定数据的方法实例
目录 一.构造dataframe 二.替换指定数据(fillna.isin.replace) 1.用"sz"列的同行数据将"bj"列的空值替换掉 2.在1的基础上,将"sz"列为2或者6的数据替换成-4 三.替换函数replace()详解 1.全局替换元素 2.通过指定条件替换元素 3.通过模糊条件替换指定元素 总结 一.构造dataframe import pandas as pd import numpy as np df=pd.DataFr
-
利用python将 Matplotlib 可视化插入到 Excel表格中
目录 数据可视化 图表插入Excel 前言: 在生活中工作中,我们经常使用Excel用于储存数据,Tableau等BI程序处理数据并进行可视化.我们也经常使用R.Python编程进行高质量的数据可视化,生成制作了不少精美优雅的图表. 但是如何将这些“优雅”延续要Excel中呢?Python绘图库有很多,我们就还是拿最基本的Matplotlib为例. 今天就为大家演示一下,如何将Matplotlib绘制的可视化图片,插入到Excel中. 其他可视化库生成的图片,也同样适用 数据可视化 目前Pyth
-
如何利用python将Xmind用例转为Excel用例
目录 1.Xmind用例编写规范 2.转换代码 3.使用 1.Xmind用例编写规范 1:需求大模块 2:大模块中的小模块(需要根据需求来看需要多少层) 3:用例等级和用例名称 用例等级(转换成Excel文件后,1为High, 2 为 Middle, 3为Low) 转换成excel时,用例的名称为(框出来的1-2-3组合而成),意味着在标等级及之前的节点会组合成用例名称 4:步骤 5:期望结果 6:预置条件,转换成excel时相同层级下的用例会为同一个预置条件 2.转换代码 需要安装python
-
浅谈python多进程共享变量Value的使用tips
前言: 在使用tornado的多进程时,需要多个进程共享一个状态变量,于是考虑使用multiprocessing.Value(对于该变量的具体细节请查阅相关资料).在根据网上资料使用Value时,由于共享的是字符串,但网上介绍的都是整数或者字符,于是遇到了很多阻碍,通过查询官方文档得出了解决方案. 一.Value的构造函数: Value的初始化非常简单,直接类似Value('d', 0.0)即可,具体构造方法为: multiprocessing.Value(typecode_or_type, *
-
Python如何利用pandas读取csv数据并绘图
目录 如何利用pandas读取csv数据并绘图 绘制图像 展示结果 pandas画pearson相关系数热力图 pearson相关系数计算函数 如何利用pandas读取csv数据并绘图 导包,常用的numpy和pandas,绘图模块matplotlib, import matplotlib.pyplot as plt import pandas as pd import numpy as np fig = plt.figure() ax = fig.add_subplot(111) 读取csv文
-
Python利用pdfplumber实现读取PDF写入Excel
目录 一.Python操作PDF 13大库对比 二.pdfplumber模块 1.安装 2. 加载PDF 3. pdfplumber.PDF类 4. pdfplumber.Page类 三.实战操作 1. 提取单个PDF全部页数 2. 批量提取多个PDF文件 一.Python操作PDF 13大库对比 PDF(Portable Document Format)是一种便携文档格式,便于跨操作系统传播文档.PDF文档遵循标准格式,因此存在很多可以操作PDF文档的工具,Python自然也不例外. Pyth
-
Python+pandas编写命令行脚本操作excel的tips详情
目录 一.python logging日志模块简单封装 二.pandas编写命令行脚本操作excel的小tips 1.tips 1.1使用说明格式 1.2接收操作目录方法 1.3检测并读取目录下的excel,并限制当前目录只能放一个excel 1.4备份excel 1.5报错暂停,并显示异常信息 1.6判断excel是否包含某列,不包含就新建 1.7进度展示与阶段保存 一.python logging日志模块简单封装 项目根目录创建 utils/logUtil.py import logging
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
Python利用xlrd 与 xlwt 模块操作 Excel
目录 Python 操作 Excel 打开Excel文件读取数据 行的操作 获取所有行数据 列的操作 单元格操作 Python 操作 Excel 本篇博客介绍一种 Python 操作 Excel 的办法,核心用到 xlrd与xlwt模块. xlrd 用于读 excel: xlwt 用于写 excel. 模块安装比较简单: pip install xlrd,xlwt 正式开始前还需要了解一下 Excle 中的三大对象: WorkBook:工作簿对象 Sheet:表对象 Cell:单元格对象 这里
-
python中使用xlrd、xlwt操作excel表格详解
最近遇到一个情景,就是定期生成并发送服务器使用情况报表,按照不同维度统计,涉及python对excel的操作,上网搜罗了一番,大多大同小异,而且不太能满足需求,不过经过一番对源码的"研究"(用此一词让我觉得颇有成就感)之后,基本解决了日常所需.主要记录使用过程的常见问题及解决. python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库.可从这里下载https://pypi.python.org/pypi.下面分别记录python
-
python中pandas常用命令详解
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.pandas提供了大量能使我们快速便捷地处理数据的函数和方法.你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一. 1.pandas pandas 是一个多功能且功能强大的数据科学库. 2.读取数据 pd.read_csv("data.csv") 3.读取指定列 pd.read_csv(&quo
-
通过python调用adb命令对App进行性能测试方式
1 监听启动activity 信息命令adb shell logcat | grep START 可以查看apk包名和Activity名字 =========启动时间============ 2 冷启动(第一次启动)热启动(没有退出,第二次打开)命令 adb shell am start -W -n com.qihoo.appstore/.home.MainActivity 3 停止app命令(冷启动) adb shell am force-stop com.qihoo.appstore (热启
-
python pandas dataframe 行列选择,切片操作方法
SQL中的select是根据列的名称来选取:Pandas则更为灵活,不但可根据列名称选取,还可以根据列所在的position(数字,在第几行第几列,注意pandas行列的position是从0开始)选取.相关函数如下: 1)loc,基于列label,可选取特定行(根据行index): 2)iloc,基于行/列的position: 3)at,根据指定行index及列label,快速定位DataFrame的元素: 4)iat,与at类似,不同的是根据position来定位的: 5)ix,为loc与i
-
python pandas dataframe 按列或者按行合并的方法
concat 与其说是连接,更准确的说是拼接.就是把两个表直接合在一起.于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis . 函数的具体参数是: concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False) objs 是需要拼接的对象集合,一般为列表或者字典 axis=0 是
-
用Python的pandas框架操作Excel文件中的数据教程
引言 本文的目的,是向您展示如何使用pandas来执行一些常见的Excel任务.有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其他地方找到的复杂功能同等重要.作为额外的福利,我将会进行一些模糊字符串匹配,以此来展示一些小花样,以及展示pandas是如何利用完整的Python模块系统去做一些在Python中是简单,但在Excel中却很复杂的事情的. 有道理吧?让我们开始吧. 为某行添加求和项 我要介绍的第一项任务是把某几列相加然后添加一个总和栏. 首先我们将excel 数据 导入到pa
-
Python pandas对excel的操作实现示例
最近经常看到各平台里都有Python的广告,都是对excel的操作,这里明哥收集整理了一下pandas对excel的操作方法和使用过程.本篇介绍 pandas 的 DataFrame 对列 (Column) 的处理方法.示例数据请通过明哥的gitee进行下载. 增加计算列 pandas 的 DataFrame,每一行或每一列都是一个序列 (Series).比如: import pandas as pd df1 = pd.read_excel('./excel-comp-data.xlsx');