分享我的第一次java Selenium自动化测试框架开发过程
由于公司的开发团队偏向于使用Java技术,而且公司倡导学习开源技术,所以我选择用Java语言来进行Selenium WebDriver的自动化框架开发。由于本人没有Java开发经验,以前虽然学过QTP但从没有接触过Selenium,正好通过这个机会能学习一下自动化测试,同时也学习一下基本的Java开发过程。
一、首先是搭建框架开发环境
按照网上的方法部署eclipse,建立TestAction工程,并Import引用JDK和Selenium-2.44完整包
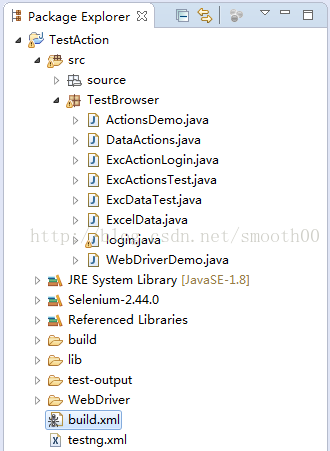
二、继续引用和安装相关jar包
1、首先是要满足数据驱动(场景用例和动作用例、数据用例都需要放到excel表上),就需要引用jxl.rar包(实现调用和操作excel);
2、需要实现自动化框架(有测试套件、测试层)就需要通过eclipse安装TestNg(网上有相关教程);
三、构建框架的样例代码
1、实现能够对excel用例数据的调用(通过jxl的引用),创建ExcelData.java类文件(专门用于对excel的调用),以下截取部分代码样例:
/**
* @param fileName excel文件名
* @param caseName sheet名
*/
public ExcelData(String fileName, String caseName) {
super();
this.fileName = fileName;
this.caseName = caseName;
}
/**
* 获得excel表中的数据
*/
public Object[][] getExcelData() throws BiffException, IOException {
workbook = Workbook.getWorkbook(new File(getPath()));
sheet = workbook.getSheet(caseName);
rows = sheet.getRows();
columns = sheet.getColumns();
// 为了返回值是Object[][],定义一个多行单列的二维数组
@SuppressWarnings("unchecked")
HashMap<String, String>[][] arrmap = new HashMap[rows - 1][1];
// 对数组中所有元素hashmap进行初始化
if (rows > 1) {
for (int i = 0; i < rows - 1; i++) {
arrmap[i][0] = new HashMap<String, String>();
}
} else {
System.out.println("excel中没有数据");
}
// 获得首行的列名,作为hashmap的key值
for (int c = 0; c < columns; c++) {
String cellvalue = sheet.getCell(c, 0).getContents();
arrkey.add(cellvalue);
}
// 遍历所有的单元格的值添加到hashmap中
for (int r = 1; r < rows; r++) {
for (int c = 0; c < columns; c++) {
String cellvalue = sheet.getCell(c, r).getContents();
arrmap[r - 1][0].put(arrkey.get(c), cellvalue);
}
}
return arrmap;
}
/**
* 获得excel文件的路径
* @return
* @throws IOException
*/
public String getPath() throws IOException {
File directory = new File(".");
sourceFile = directory.getCanonicalPath() + "\\src\\source\\"
+ fileName + ".xls";
return sourceFile;
}
2、实现对浏览器的调用,考虑到兼容性,需要同时满足对Chrome、FireFox、IE三大浏览器的调用,我们需要准备相关驱动chromedriver.exe、IEDriverServer.exe,这两驱动都是谷歌和IE官方提供的,可以从网上下载到;而FireFox不需要下载驱动,只要安装浏览器就可调用(Selenium和FireFox属于一个团队开发出来的,待遇就是不一样)。
有了浏览器驱动后(我们把驱动放到工程目录的WebDriver文件夹下,方便按相对路径统一调用),我们就需要一个能调用浏览器的类,以下提供核心代码样例:
public static WebDriver getChromeDriver(String url) {
//加载Google驱动
//System.setProperty("webdriver.chrome.driver","D:\\java\\chromedriver.exe");
System.setProperty("webdriver.chrome.driver",System.getProperties().getProperty("user.dir")+"\\WebDriver\\chromedriver.exe");
ChromeOptions options = new ChromeOptions();
//通过配置参数禁止data;的出现
options.addArguments("--user-data-dir="+System.getProperties().getProperty("user.home")+"/AppData/Local/Google/Chrome/User Data/Default");
//通过配置参数删除“您使用的是不受支持的命令行标记:--ignore-certificate-errors。稳定性和安全性会有所下降。”提示
options.addArguments("--start-maximized","allow-running-insecure-content", "--test-type");
WebDriver driver = new ChromeDriver(options);
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
driver.navigate().to(url);
return driver;
}
public static WebDriver getFireFoxDriver(String url){
System.setProperty("webdriver.firefox.bin", "D:\\Program Files\\Mozilla Firefox\\firefox.exe");
// TODO Auto-generated method stub
WebDriver driver = new FirefoxDriver();
//Puts a Implicit wait, Will wait for 10 seconds before throwing exception
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
//Launch website
driver.navigate().to(url);
return driver;
}
public static WebDriver getIEDriver(String url){
//System.setProperty("webdriver.ie.driver", "D:\\java\\IE64\\IEDriverServer.exe");
System.setProperty("webdriver.ie.driver", System.getProperties().getProperty("user.dir")+"\\WebDriver\\IE32\\IEDriverServer.exe");
DesiredCapabilities capabilities = DesiredCapabilities.internetExplorer();
capabilities.setCapability(InternetExplorerDriver.INTRODUCE_FLAKINESS_BY_IGNORING_SECURITY_DOMAINS,true);
capabilities.setPlatform(Platform.WINDOWS);
capabilities.setCapability("silent", true);
// TODO Auto-generated method stub
WebDriver driver = new InternetExplorerDriver(capabilities);
//Puts a Implicit wait, Will wait for 10 seconds before throwing exception
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
//Launch website
driver.navigate().to(url);
return driver;
}
3、写一个以数据驱动的场景类,来进行单个事务的用例跑测
(1)首行我们需要用TesgNg提供的数据驱动方法(@DataProvider),来获取一个场景的用例表数据,这个场景从excel的第一个附表获取

通过action名,调取用例表(用例表是以action名命名的附表),用例表如下所示(ExpectedObject表示用例校验对象的页面Element标签,用;分隔,分号前面的表示ID,分号后面的表示xpath):
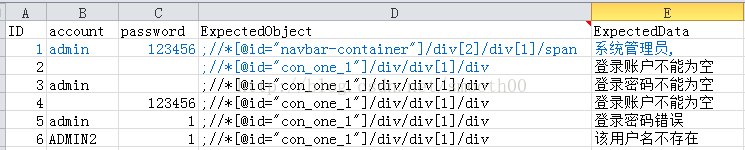
以下为用例表数据获取的代码:
@DataProvider(name="action")
public Object[][] Numbers() throws BiffException, IOException{
getActionString = actionData.getActionStr(1);//获取第一个场景的broswer、url、action名
ExcelData e=new ExcelData("testdata", getActionString.get(2));
return e.getExcelData();
}
然后通过Java的反射机制,实现动态的获取具体事务类和执行相关操作(每个事务的类名和方法名都与action场景名一致),以下截选相关场景的部分调用代码:
@Test(dataProvider="action")
public void testAction(HashMap<String, String> data) throws BiffException, IOException {
try {
Class<?> MyClass = Class.forName(packageName+"."+getActionString.get(2));
Method method = MyClass.getMethod(getActionString.get(2),WebDriver.class);
@SuppressWarnings("unused")
String [] results = (String []) method.invoke(null,driver);
String ExpObject=data.get("ExpectedObject");
String ExpObject_by=ExpObject.split(";")[0].toString();
String ExpObject_Desc=ExpObject.split(";")[1].toString();
if(ExpObject_by.length()>0){
Assert.assertEquals(driver.findElement(By.id(ExpObject_by)).getText(),data.get("ExpectedData"), getActionString.get(2)+data.get("ID")+"验证结果:");
}
else if(ExpObject_Desc.length()>0){
Assert.assertEquals(driver.findElement(By.xpath(ExpObject_Desc)).getText(),data.get("ExpectedData"), getActionString.get(2)+data.get("ID")+"验证结果:");
}
WebDriverDemo.WebSleep(500);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
另外说明的是,调用浏览器的方法,需要明确是放在@BeforeMethod中,还是在@BeforeClass中,如果是登录校验测试,就要保证每次执行测试方法都要打开一次浏览器和关闭一次浏览器,那么我们就要把调用浏览器,和关闭浏览器的方法放到@BeforeMethod中和@AfterMethod中。其他业务测试,只要在一个套件类中打开一次浏览器和关闭一次浏览器就可以,所以用到的是@BeforeClass和@AfterClass。
4、我们需要再写一个以动作(关键词)驱动的场景类
同样,调用第二个场景的用例表,样例代码如下:
@DataProvider(name="action")
public Object[][] Numbers() throws BiffException, IOException{
getActionString = actionData.getActionStr(2);//获取第二个场景的broswer、url、action名
ExcelData e=new ExcelData("testdata", getActionString.get(2));
return e.getExcelData();
}
然后在测试方法中,动态的调用具体操作动作,获取WebElement标签的方法,包括通过By ID或者By xpath,操作动作以最常见的两个为例(sendKeys、click),以下为样例代码节选:
@Test(dataProvider="action")
public void testAction(HashMap<String, String> data) throws BiffException, IOException {
//driver.manage().timeouts().implicitlyWait(5,TimeUnit.SECONDS);//找不到element就再给5秒查找
try {
WebElement TestWebElement = null;
String SetObject=data.get("SetObject").trim();
String SetObject_by=SetObject.split(";")[0].toString();
String SetObject_Desc=SetObject.split(";")[1].toString();
if(SetObject_by.length()>0){
TestWebElement=driver.findElement(By.id(SetObject_by));
}
else if(SetObject_Desc.length()>0){
TestWebElement=driver.findElement(By.xpath(SetObject_Desc));
}
if(data.get("SetOperate").equals("sendKeys")){
TestWebElement.clear();
TestWebElement.sendKeys(data.get("SetValue"));
}else if(data.get("SetOperate").equals("click")){
TestWebElement.click();
}
String ExpObject=data.get("ExpectedObject").trim();
if(ExpObject.length()>0){
String ExpObject_by=ExpObject.split(";")[0].toString();
String ExpObject_Desc=ExpObject.split(";")[1].toString();
if(ExpObject_by.length()>0){
Assert.assertEquals(driver.findElement(By.id(ExpObject_by)).getText(),data.get("ExpectedData"), getActionString.get(2)+data.get("ID")+"验证结果:");
}
else if(ExpObject_Desc.length()>0){
Assert.assertEquals(driver.findElement(By.xpath(ExpObject_Desc)).getText(),data.get("ExpectedData"), getActionString.get(2)+data.get("ID")+"验证结果:");
}
}
WebDriverDemo.WebSleep(500);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
这段方法所调用的用例表如下所示(以登录为例):

5、剩下就是业务扩展类了,所有复杂的事务都可以单独建立测试类和方法(方便扩展维护,只需要在excel场景表中定义后就能调用,利用的是Java反射机制),在这里就不举例了。
四、实现测试套件调用和报告输出
有了以上步骤,一个可扩展的自动化框架已经基本形成,但是还达不到大规模应用测试和脚本方便可移植,这时候我们引入Ant(可以在Eclipse中安装插件,可以直接上网下载后引用),为了能输出漂亮一点的报告格式,我们还引入一个saxon-8.7.jar。
有了Ant后,我们就可以建议build.xml文件,就能一键bulid我们以上的自动化代码,并将执行测试后的结果输出成报告。
1、首先我们需要编辑好测试套件调用的testng.xml,简单举例如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="Suite" parallel="false">
<test verbose="2" name="Test_Action">
<!--<groups>
<run>
<include name="aaa" />
<include name="bbb" />
<include name="ccc" />
</run>
</groups>-->
<classes>
<class name="TestBrowser.ExcActions"/>
<class name="TestBrowser.ExcActions2"/>
</classes>
</test> <!-- Default test -->
</suite> <!-- Default suite -->
2、然后我们需要编辑好一个能引用基础jar包、build测试代码、调用testng、输出漂亮报告的build.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project name= "TestAction" basedir= "." default="testoutput"><!--default设置为run表示只执行脚本,设为testoutput表示执行完脚本并输出视图报告-->
<echo message="import libs" />
<property name= "lib.dir" value= "lib" /> <!--<property name="libdir" location="${basedir}/lib" />-->
<!--<property name="testng.output.dir" location="${basedir}/test-output" />-->
<path id= "test.classpath" >
<!-- adding the saxon jar to your classpath -->
<fileset dir= "${lib.dir}" includes= "*.jar" />
<fileset dir="${basedir}/selenium-2.44.0">
<include name="selenium-java-2.44.0.jar" />
<include name="libs/*.jar" />
</fileset>
</path>
<taskdef name="testng" classname="org.testng.TestNGAntTask" classpathref="test.classpath" rel="external nofollow" />
<target name="clean">
<delete dir="build"/>
</target>
<target name="compile" depends="clean">
<echo message="mkdir"/>
<mkdir dir="build/classes"/>
<javac srcdir="src" destdir="build/classes" debug="on" encoding="UTF-8" includeAntRuntime="false">
<classpath refid="test.classpath"/>
</javac>
</target>
<path id="runpath">
<path refid="test.classpath"/>
<pathelement location="build/classes"/>
</path>
<target name="run" depends="compile">
<testng classpathref="runpath" rel="external nofollow" outputDir="test-output">
<xmlfileset dir="${basedir}" includes="testng.xml"/>
<jvmarg value="-ea" />
</testng>
</target>
<target name= "testoutput" depends="run">
<xslt in= "test-output/testng-results.xml" style= "test-output/testng-results.xsl"
out= "test-output/index1.html" >
<!-- you need to specify the directory here again -->
<param name= "testNgXslt.outputDir" expression= "${basedir}/test-output/" />
<param name="testNgXslt.showRuntimeTotals" expression="true" />
<classpath refid= "test.classpath" />
</xslt>
</target>
</project>
3、完成这些后,我们就可以通过Eclipse直接Run As Ant Build我们的自动化脚本了,输出一份还算漂亮的报告:
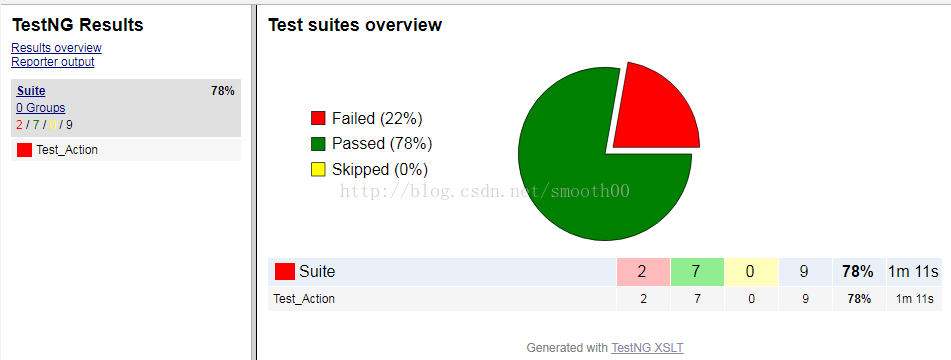
同时,需要在事务操作类中,对实际结果和预期结果进行比较,并将测试结果写入excel的用例表中,如下:
String[] result=new String [2];
result[0] = driver.findElement(By.xpath(pars.get(3).split(";")[1].toString())).getText();
result[1] = pars.get(4);
if(result[0].equals(result[1])){//pars.size()-1
ActionsDemo.modifyExcel(Thread.currentThread().getStackTrace()[1].getMethodName(),k,5,"通过");
} else {
ActionsDemo.modifyExcel(Thread.currentThread().getStackTrace()[1].getMethodName(),k,5,"失败");
}

五、实现自动化框架脚本的迁移调用
以上的脚本始终是在Eclipse下编译和调用的,如果要实现灵活迁移,随便换任何一台只装了JDK的电脑都能运行,那么我们就要来点改造
1、首行是保证我们写的代码中,所以需要引用文件的地方,都用相对路径的方式,避免代码包迁移后需要改路径。
2、通过批处理调用build文件及用例文件,调用时也是通过批处理自动找到相关路径,避免用绝对路径。
3、需要用环境变量的地方,尽量用批处理的方式实现,甚至最好是不用配置环境变量,直接调用相引用相对命令文件的路径调用
以下举个通过bat批处理调用Ant来执行整个框架代码的build:
@echo off ::先将测试用例文件拷到用户目录下 copy src\source\testdata.xls %UserProfile%\src\source %cd%\org.apache.ant_1.9.6\bin\ant.bat -buildfile build.xml echo 在%cd%\test-output下查看测试报告 pause
六、进一步实现自动化的持续集成
在以上基础上,我们还可以通过jenkins实现对自动化脚本的调用,以及达到每日构建,持续集成开发的要求。
1、首先部署jenkins(网上有相关方法),由于本人公司一直在用jenkins,我就省了搭建部署这一步,直接将以上的自动化框架脚本上传
2、自动化脚本完整目录(包括代码、用例、lib、引用的jar、build.xml文件等)上传到SVN(再自动从SVN下到jenkins所在服务器)
3、在jenkins中新建一个测试项目TestAction,主要配置如下:
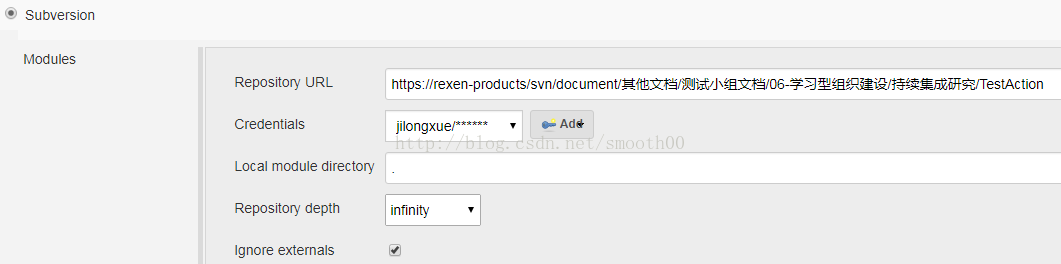
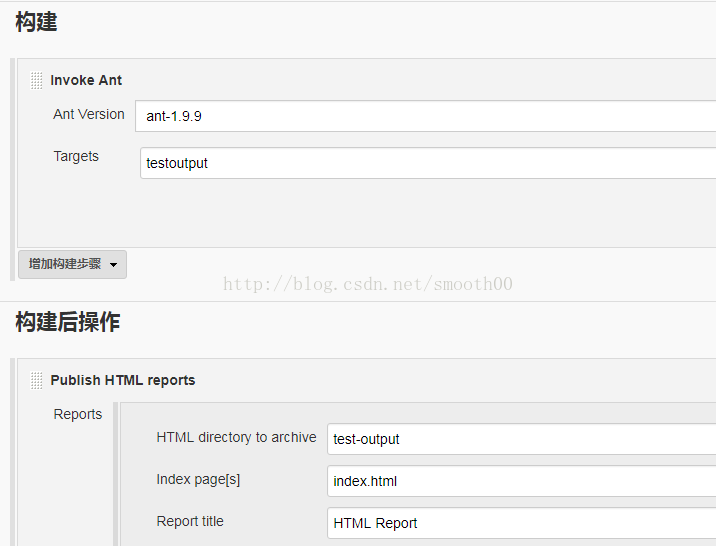
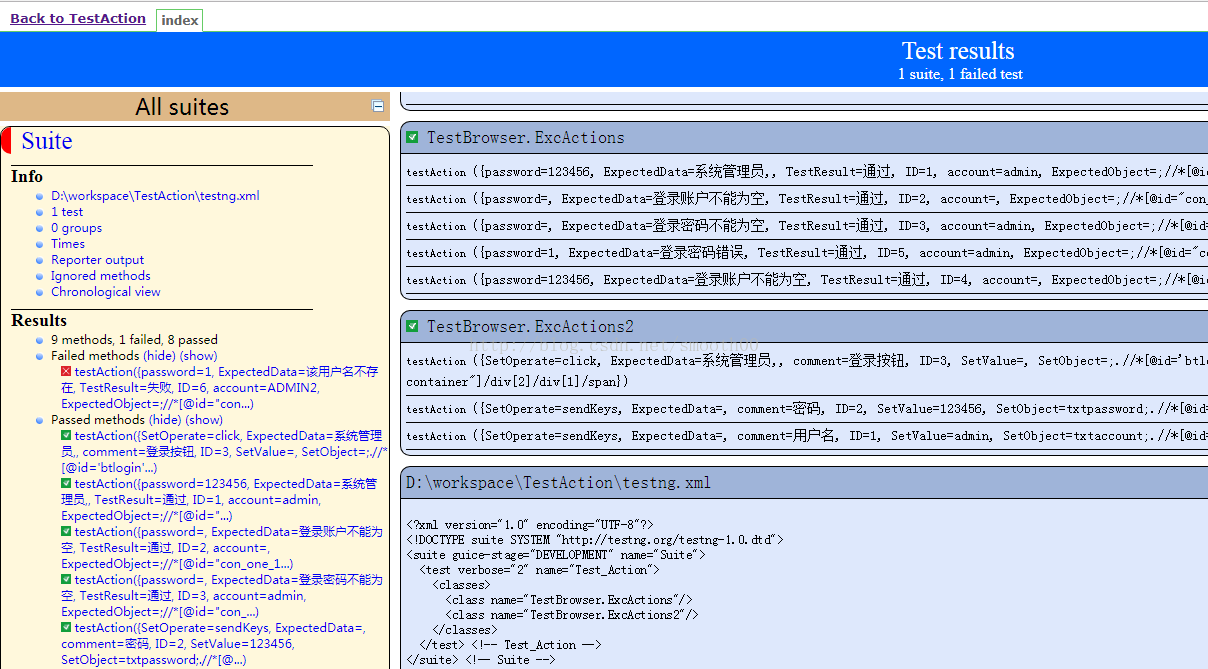
4、配置完后,就可以立即构建(如果碰到相关报错问题,就按输出的提示进行处理),构建成功后,就可以在HTML_Report中看到测试结果:
七、后续处理
到此为止,一个完整的Selenium自动化框架就出来了,要说好用不,不好说,还得经过实践的检验,但是以上这个思考过程和框架的演进过程,应该也是值得借鉴的,毕竟这是我这几天摸索和学习的过程,对于一个没有从事过自动化测试,而且没有做过Java开发的测试人员来说,这只是个开始。
目前来看,这个框架在架构分层上,还是不够清晰,有很多要改进的东西,从技术上来说,我已经实现了我的目标(学习自动化测试),但是在整体架构和代码重构上,还有很多工作没做,以下贴出一份Selenium自动化框架的分层结构,以便后期按照这个标准进行改进:
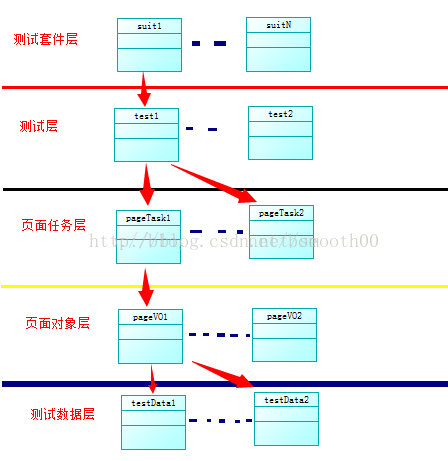
测试数据层:独立封装数据;
页面对象层:封装页面对象,共页面任务层做调用;
页面任务层:实现各个独立页面的操作;
测试层:实现页面测试;
测试套件层:实现测试层的管理调用;
到此这篇关于分享我的第一次java Selenium自动化测试框架开发过程的文章就介绍到这了,更多相关java Selenium自动化测试 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python3+selenium自动化测试框架详解
背景 为了更好的发展自身的测试技能,应对测试行业以及互联网行业的迭代变化.自学python以及自动化测试. 虽然在2017年已经开始接触了selenium,期间是断断续续执行自动化测试,因为还有其他测试任务,培训任务要执行- 前期建议大家能够学习python基本语法(python基础教程) 任务 搭建自动化测试框架,并能有效方便的进行测试,维护成本也要考虑其中. 过程 我的自动化框架可能不成熟,因为是自学的.请多包涵.也请大佬指导~ common 包含:基本的公共方法类,比如HTML报告.Log
-
python+django+selenium搭建简易自动化测试
该平台会集成UI自动化及api自动化,里面也会涉及到一些简单的HTML等前端,当然都是很基础的东西.在以后的博客里,我会一点点的尽量写详细,帮助一些测试小白一起成长,当然我也是个小菜鸡. 第一章 django 搭建平台. 1.1搭建环境 Django 官方网站:https://www.djangoproject.com/ Python 官方仓库下载地址:https://pypi.python.org/pypi/Django 这里我们通过pip来安装django ,这里版本用1.10.3. Pyt
-
selenium+python自动化测试之环境搭建
最近由于公司有一个向谷歌网站上传文件的需求,需要进行web的自动化测试,选择了selenium这个自动化测试框架,以前没有接触过这门技术,所以研究了一下,使用python来实现自动化脚本,从环境搭建到实现脚本运行. selenium是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等.支持自动录制动作和自动
-
python+Selenium自动化测试——输入,点击操作
这是我的第一个真正意思上的自动化脚本. 1.练习的测试用例为: 打开百度首页,搜索"胡歌",然后检索列表,有无"胡歌的新浪微博"这个链接 2.在写脚本之前,需要明确测试的步骤,具体到每个步骤需要做什么,既拆分测试场景,考虑好之后,再去写脚本. 此测试场景拆分如下: 1)启动Chrome浏览器 2)打开百度首页,https://www.baidu.com 3)定位搜索输入框,输入框元素XPath表达式://*[@id="kw"] 4)定位搜索提交按
-
selenium python 实现基本自动化测试的示例代码
安装selenium 打开命令控制符输入:pip install -U selenium 火狐浏览器安装firebug:www.firebug.com,调试所有网站语言,调试功能 Selenium IDE 是嵌入到Firefox 浏览器中的一个插件,实现简单的浏览器操 作的录制与回放功能,IDE 录制的脚本可以可以转换成多种语言,从而帮助我们快速的开发脚本,下载地址:https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/ 如何使用
-
selenium+python自动化测试环境搭建步骤
相对于自动化测试工具QTP来说,selenium小巧.免费,而且兼容Google.FireFox.IE多种浏览器,越来越多的人开始使用selenium进行自动化测试. 我是使用的python 2.7,下面说一下selenium+Python的自动化测试环境搭建. 安装Python环境,从python官网下载安装包 双击安装包,进行安装 可以选择python的安装目录,按步骤安装,直至完成. 在早期的版本中,需要单独安装setuptools和pip,在新的python安装包版本中已经集成了setu
-
使用Python+selenium实现第一个自动化测试脚本
最近在学web自动化,记录一下学习过程. 此处我选用python3.6+selenium3.0,均用最新版本,以适应未来需求. 环境:windows10,64位 一.安装python python官方下载地址:https://www.python.org/downloads/ 进入页面就有两个版本的下载选择,2.x版本和3.x版本,或者根据系统选择对应版本. 点击Windows,跳转到Windows版本页面: 点选Python3.6.0版本,进入3.6版本页面,拉到页面下方,找到files 选择
-
Selenium自动化测试工具使用方法汇总
1.设置无头浏览器模式 from selenium import webdriver from selenium.webdriver.chrome.options import Options chrome_options = Options() chrome_options.add_argument('- -headless') chrome_options.add_argument('- -disable-gpu') class XX(object): self.driver = webdr
-
python3 selenium自动化测试 强大的CSS定位方法
ccs的优点:css相对xpath语法比xpath简洁,定位速度比xpath快 css的缺点:css不支持用逻辑运算符来定位,而xpath支持.css定位语法形式多样,相对xpath比较难记. css定位建议多用,这个定位方式很强大,定位速度快且准确度高.至于难记,用熟了就好了,对勤快的人来说,这不是问题. CSS_selector常用符号: # 表示id . 表示class > 表示子元素,层级 1.通过id属性定位: find_element_by_css_selector("#id的
-
python+selenium自动化框架搭建的方法步骤
环境及使用软件信息 python 3 selenium 3.13.0 xlrd 1.1.0 chromedriver HTMLTestRunner 说明: selenium/xlrd只需要再python环境下使用pip install 名称即可进行对应的安装. 安装完成后可使用pip list查看自己的安装列表信息. chromedriver:版本需和自己的chrome浏览器对应,百度下载. 作用:对chrome浏览器进行驱动. HTMLTestRunner:HTMLTestRunner是Pyt