R语言基本运算的示例代码
1.基本运算
1.1 加、减、乘、除 + - * /

在赋值中可以使用=,也可以使用<-.
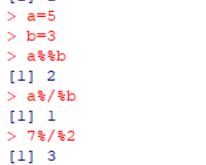
1.2余数、整除 %% %/%
1.3 取绝对值 abs() 判断正负号sign()

1.4幂指数 ^ 平方根sqart ()

1.5 以二为底的对数:log2()
以十为底的对数:log10()
自定义底的对数:log(c,base=)
自然常数e的对数:log(a,base=exp(1))

2、向量运算
向量是有相同基本类型的元素序列,一维数组,定义向量的最常用办法是使用函数c(),它把若干个数值或字符串组合为一个向量。
2. 1.R语言向量的产生方法

2.2.向量加减乘除都是对其对应元素进行的,例如下面

注:向量的整数除法是%/%,取余是%%。
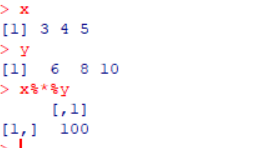
2.3.向量的内积,有两种方法。
第一种方法:%*%
第二种方法:crossprod(x,y).

2.4.向量的外积 ,有三种方法。
第一种方法:%o%

第二种方法:tcrossprod(x,y)

第三种方法:outer(x,y)

3、矩阵的运算
3.1矩阵的产生方式

其中第一个3表示的是行数,第二个3表示的列数。 故产生一个3*3的矩阵。这里是将1到9按列排列,如果想按行排列,那么如下代码
3.2.矩阵对应元素的运算

3.3 矩阵的转置

3.4.矩阵乘法

3.5求矩阵的行列式、对称矩阵的特征值、特征向量

求特征值

到此这篇关于R语言基本运算的示例代码的文章就介绍到这了,更多相关R语言基本运算内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解R语言中的PCA分析与可视化
1. 常用术语 (1)标准化(Scale) 如果不对数据进行scale处理,本身数值大的基因对主成分的贡献会大.如果关注的是变量的相对大小对样品分类的贡献,则应SCALE,以防数值高的变量导入的大方差引入的偏见.但是定标(scale)可能会有一些负面效果,因为定标后变量之间的权重就是变得相同.如果我们的变量中有噪音的话,我们就在无形中把噪音和信息的权重变得相同,但PCA本身无法区分信号和噪音.在这样的情形下,我们就不必做定标. (2)特征值 (eigen value) 特征值与特征向量均为矩阵分
-
R语言如何将大型Excel文件转为dta格式详解
本文以2000年度我国工业企业数据库为例,该文件后缀名为xlsx,包含约16万条记录,文件有88M这么大.直接使用Excel打开都费劲:等待时间久,电脑风扇呼呼呼作响.如果尝试用Stata打开该xlsx文件,则会出现提示报错. 报错原因在于,Stata无法读取超过40M的Excel文件. 这就好比瓜迪奥拉的传控足球固然美丽,但是面对摆大巴的球队无能为力. 破大巴需要攻城锤,这把锤子的名字就是R语言.万事开头难啊,正憧憬着数据清洗和花式选取变量建模呢,可不能连数据们长啥模样都没见着啊.R语言适时挺
-
R语言的下载安装图文教程讲解
什么是R语言 R语言是一个开源的数据分析环境,起初是由数位统计学家建立起来,以更好的进行统计计算和绘图,这篇wiki中包含了一些基本情况的介绍.由于R可以通过安装扩展包(Packages)而得到增强,所以其功能已经远远不限于统计分析,如果感兴趣的话可以到官方网站了解关于其功能的更多信息. 至于R语言名称的由来则是根据两位主要作者的首字母(Robert Gentleman and Ross Ihaka),但过于简短的关键词也造成在搜索引擎中很不容易找到相关的资料.不过这个专门的搜索网站可以帮到你.
-
R语言多元Logistic逻辑回归应用实例
可以使用逐步过程确定多元逻辑回归.此函数选择模型以最小化AIC. 如何进行多元逻辑回归 可以使用阶梯函数通过逐步过程确定多元逻辑回归.此函数选择模型以最小化AIC. 通常建议不要盲目地遵循逐步程序,而是要使用拟合统计(AIC,AICc,BIC)比较模型,或者根据生物学或科学上合理的可用变量建立模型. 多元相关是研究潜在自变量之间关系的一种工具.例如,如果两个独立变量彼此相关,可能在最终模型中都不需要这两个变量,但可能有理由选择一个变量而不是另一个变量. 多元相关 创建数值变量的数据框 Data.
-
R语言判断语句的使用详解
判断结构要求程序员指定一个或多个要评估或测试的条件,以及条件为真时要执行的语句(必需的)和条件为假时要执行的语句(可选的). 下面是大多数编程语言中典型的判断结构的一般形式: R 语言提供了以下类型的判断语句: if 语句 if...else 语句 switch 语句 if 语句 一个 if 语句 由一个布尔表达式后跟一个或多个语句组成. 语法格式如下: if(boolean_expression) { // 布尔表达式为真将执行的语句 } 如果布尔表达式 boolean_expression
-
R语言dplyr包之高效数据处理函数(filter、group_by、mutate、summarise)详解
R语言dplyr包的数据整理.分析函数用法文章连载NO.01 在日常数据处理过程中难免会遇到些难处理的,选取更适合的函数分割.筛选.合并等实在是大快人心! 利用dplyr包中的函数更高效的数据清洗.数据分析,及为后续数据建模创造环境:本篇涉及到的函数为filter.filter_all().filter_if().filter_at().mutate.group_by.select.summarise. 1.数据筛选函数: #可使用filter()函数筛选/查找特定条件的行或者样本 #filte
-
大数据分析R语言RStudio使用超详细教程
RStudio是用于R编程的开源工具.如果您对使用R编程感兴趣,则值得了解RStudio的功能.它是一种灵活的工具,可帮助您创建可读的分析,并将您的代码,图像,注释和图解保持在一起. 在此大数据分析R语言RStudio使用教程文章中,我们将介绍RStudio免费版本的一些最佳功能:RStudio Desktop.我们收集了一些RStudio的重要技巧,窍门和快捷方式,可快速将您变成RStudio高级用户! 1.在窗口窗格之间快速导航 RStudio窗格可让您访问有关项目的重要信息.知道如何在窗格
-
R语言 出现矩阵/缺失值的解决方案
缺失值处理一般包括三步: 1. 识别缺失数据: 2. 检查导致数据缺失的原因: 3. 删除包含缺失值的实例或用合理的数值代替(插补)缺失值. 1.判断缺失值 函数is.na().is.nan()和is.infinite()可分别用来识别缺失值.不可能值和无穷值.每个返回结果都是 TRUE或FALSE na表示缺失值 nan表示NOT A NUMBER infinite表示+-Inf 一定要亲手试x = 0/0,以及x = 1/0 >x <- NA > is.na(x) [1] TRUE
-
如何用R语言绘制饼图和条形图
R 语言提供来大量的库来实现绘图功能. 饼图,或称饼状图,是一个划分为几个扇形的圆形统计图表,用于描述量.频率或百分比之间的相对关系. R 语言使用 pie() 函数来实现饼图,语法格式如下: pie(x, labels = names(x), edges = 200, radius = 0.8, clockwise = FALSE, init.angle = if(clockwise) 90 else 0, density = NULL, angle = 45, col = NULL, bor
-
R语言基本运算的示例代码
1.基本运算 1.1 加.减.乘.除 + - * / 在赋值中可以使用=,也可以使用<-. 1.2余数.整除 %% %/% 1.3 取绝对值 abs() 判断正负号sign() 1.4幂指数 ^ 平方根sqart () 1.5 以二为底的对数:log2() 以十为底的对数:log10() 自定义底的对数:log(c,base=) 自然常数e的对数:log(a,base=exp(1)) 2.向量运算 向量是有相同基本类型的元素序列,一维数组,定义向量的最常用办法是使用函数c(),它把若干个数值或字
-
详解R语言数据合并一行代码搞定
数据的合并 需要的函数 cbind(),rbind(),bind_rows(),merge() 准备数据 我们先构造一组数据,以便下面的演示 > data1<-data.frame( + namea=c("海波","立波","秀波"), + value=c("一波","接","一波") + ) > data1 namea value 1 海波 一波 2 立波 接 3 秀
-
Android多语言适配的示例代码(兼容7.0+)
一.前言 1.安卓系统本身对多语言适配就提供了一套框架和API.我们就直接用就可以了. 2.更换语言必须recreate Activity.目前,没见过可以不重建的方法.常用App,也都是重建的,可以看的到. 3.兼容性问题.现在越来越多设备都是安卓7.0+新手机的安卓版本会更高(安卓8.0+),所以适配是必要的. 4.目前,网上大部分相关文章都是不兼容7.0+的,具体做法一搜一大把. 二.具体做法 1.多语言文件 文件夹命名参考下面博客(网上有很多): 多国语言value文件夹命名 value
-
利用python/R语言绘制圣诞树实例代码
目录 Python R语言 总结 圣诞节快到了,想着用python.r来画画圣诞树玩,就在网络上各种找方法,不喜勿喷哈~~ Python 1. import turtle screen = turtle.Screen() screen.setup(800,600) circle = turtle.Turtle() circle.shape('circle') circle.color('red') circle.speed('fastest') circle.up() square = turt
-
c语言快速排序算法示例代码分享
步骤为:1.从数列中挑出一个元素,称为 "基准"(pivot);2.重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边).在这个分区退出之后,该基准就处于数列的中间位置.这个称为分区(partition)操作.3.递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序.递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了.虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iterat
-
R语言 实现手动设置xy轴刻度的操作
在R中,plot函数作图时会自动给出xy轴的刻度标度,如下图: 有时我们需要自己定义xy轴的刻度,这时我们可以用axis中的at和labels参数来更改. 首先,我们先令plot不要画出xy轴的标度 然后,用axis函数设置xy轴的刻度 这样xy轴的刻度就完全按照我们自己的意愿显示了,也可以设置at参数不是均匀的,总之,用这两个参数就可以完全自己控制xy轴的刻度显示了 补充:R语言自定义坐标轴示例 我就废话不多说了,大家还是直接看代码吧~ x <- c(1:10) y <- x z <-
-
R语言 实现在循环中输出图片的操作
今天在循环导出图片时,遇到了一个问题: 使用R语言导出图片的代码: setwd("E://R") jpeg(file="A.jpeg") print(plot(PEO$X, PEO$Y, pch=PEO$S)) dev.off() 但是若是将此代码运用到循环之中,则只会出来一张图A.jpeg 想了好久原因,发现--..!!!! 命名方法不对啊!!! 只有一个名字!!!当然不行啊!!! 于是搜索如何循环命名- 找到了老朋友paste() yourfilename=pa
-
R语言-如何将list转换为向量
从excel中直接读取的数据为list,如下转换为向量 as.vector(unlist(x)) 补充:R语言基本运算,向量,矩阵,list,数组 1. 基本运算 1.1 加.减.乘.除 赋值可以使用a=数值,亦可以用a<-数值 1.2 余数.整除 1.3 绝对值: abs() .判断正负:sign() .幂.指数:^ .平方根:sqrt() 1.4 以二为底的对数: log2() .以十为底的对数:log10() .自定义底的对数:log(c,base=) .自然常数e的对数:log(a,ba
-
用R语言实现霍夫曼编码的示例代码
可读性极低,而且其实也没必要用R语言写,图个乐罢了 p=c(0.4,0.2,0.2,0.1,0.1)###输入形如c(0.4,0.2,0.2,0.1,0.1)的概率向量,即每个待编码消息的发生概率 p1=p###将概率向量另存,最后计算编码效率要用 mazijuzhen=matrix(,nrow=length(p),ncol=length(p)-1)###码字矩阵:第i行对应向量p的第i个分量所对应的那个待编码消息的编码后的码字 group=matrix(c(1:length(p),rep(NA
-
R语言实现岭回归的示例代码
岭参数的一般选择原则 选择k(或lambda)值,使得: 各回归系数的岭估计基本稳定 用最小二乘估计时符号不合理的回归系数,其岭回归的符号变得合理 回归系数没有不合乎实际意义的绝对值 残差平方和增大的不多 用R语言进行岭回归 这里使用MASS包中的longley数据集,进行岭回归分析(longley数据集中的变量具有显著的多重共线性).从而分析使用岭回归进行多重共线性的解决. 首相将longley数据集中的第一列数据命名为"y",并使用岭回归创建线性模型: 显示当y为因变量,其余各个变