python实现logistic分类算法代码
最近在看吴恩达的机器学习课程,自己用python实现了其中的logistic算法,并用梯度下降获取最优值。
logistic分类是一个二分类问题,而我们的线性回归函数

的取值在负无穷到正无穷之间,对于分类问题而言,我们希望假设函数的取值在0~1之间,因此logistic函数的假设函数需要改造一下

由上面的公式可以看出,0 < h(x) < 1,这样,我们可以以1/2为分界线
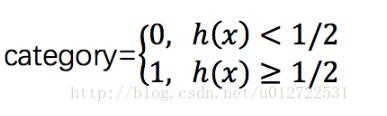
cost function可以这样定义
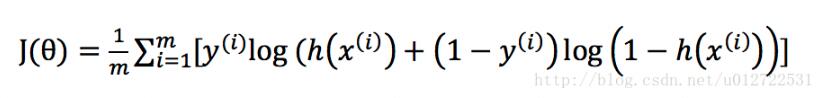
其中,m是样本的数量,初始时θ可以随机给定一个初始值,算出一个初始的J(θ)值,再执行梯度下降算法迭代,直到达到最优值,我们知道,迭代的公式主要是每次减少一个偏导量

如果将J(θ)代入化简之后,我们发现可以得到和线性回归相同的迭代函数

按照这个迭代函数不断调整θ的值,直到两次J(θ)的值差值不超过某个极小的值之后,即认为已经达到最优解,这其实只是一个相对较优的解,并不是真正的最优解。 其中,α是学习速率,学习速率越大,就能越快达到最优解,但是学习速率过大可能会让惩罚函数最终无法收敛,整个过程python的实现如下
import math
ALPHA = 0.3
DIFF = 0.00001
def predict(theta, data):
results = []
for i in range(0, data.__len__()):
temp = 0
for j in range(1, theta.__len__()):
temp += theta[j] * data[i][j - 1]
temp = 1 / (1 + math.e ** (-1 * (temp + theta[0])))
results.append(temp)
return results
def training(training_data):
size = training_data.__len__()
dimension = training_data[0].__len__()
hxs = []
theta = []
for i in range(0, dimension):
theta.append(1)
initial = 0
for i in range(0, size):
hx = theta[0]
for j in range(1, dimension):
hx += theta[j] * training_data[i][j]
hx = 1 / (1 + math.e ** (-1 * hx))
hxs.append(hx)
initial += (-1 * (training_data[i][0] * math.log(hx) + (1 - training_data[i][0]) * math.log(1 - hx)))
initial /= size
iteration = initial
initial = 0
counts = 1
while abs(iteration - initial) > DIFF:
print("第", counts, "次迭代, diff=", abs(iteration - initial))
initial = iteration
gap = 0
for j in range(0, size):
gap += (hxs[j] - training_data[j][0])
theta[0] = theta[0] - ALPHA * gap / size
for i in range(1, dimension):
gap = 0
for j in range(0, size):
gap += (hxs[j] - training_data[j][0]) * training_data[j][i]
theta[i] = theta[i] - ALPHA * gap / size
for m in range(0, size):
hx = theta[0]
for j in range(1, dimension):
hx += theta[j] * training_data[i][j]
hx = 1 / (1 + math.e ** (-1 * hx))
hxs[i] = hx
iteration += -1 * (training_data[i][0] * math.log(hx) + (1 - training_data[i][0]) * math.log(1 - hx))
iteration /= size
counts += 1
print('training done,theta=', theta)
return theta
if __name__ == '__main__':
training_data = [[1, 1, 1, 1, 0, 0], [1, 1, 0, 1, 0, 0], [1, 0, 1, 0, 0, 0], [0, 0, 0, 0, 1, 1], [0, 1, 0, 0, 0, 1],
[0, 0, 0, 0, 1, 1]]
test_data = [[0, 1, 0, 0, 0], [0, 0, 0, 0, 1]]
theta = training(training_data)
res = predict(theta, test_data)
print(res)
运行结果如下

以上这篇python实现logistic分类算法代码就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python利用逻辑回归分类实现模板
Logistic Regression Classifier逻辑回归主要思想就是用最大似然概率方法构建出方程,为最大化方程,利用牛顿梯度上升求解方程参数. 优点:计算代价不高,易于理解和实现. 缺点:容易欠拟合,分类精度可能不高. 使用数据类型:数值型和标称型数据. 好了,下面开始正文. 算法的思路我就不说了,我就提供一个万能模板,适用于任何纬度数据集. 虽然代码类似于梯度下降,但他是个分类算法 定义sigmoid函数 def sigmoid(x): return 1/(1+np.exp(-x)
-
python sklearn包——混淆矩阵、分类报告等自动生成方式
preface:做着最近的任务,对数据处理,做些简单的提特征,用机器学习算法跑下程序得出结果,看看哪些特征的组合较好,这一系列流程必然要用到很多函数,故将自己常用函数记录上.应该说这些函数基本上都会用到,像是数据预处理,处理完了后特征提取.降维.训练预测.通过混淆矩阵看分类效果,得出报告. 1.输入 从数据集开始,提取特征转化为有标签的数据集,转为向量.拆分成训练集和测试集,这里不多讲,在上一篇博客中谈到用StratifiedKFold()函数即可.在训练集中有data和target开始. 2.
-
python实现logistic分类算法代码
最近在看吴恩达的机器学习课程,自己用python实现了其中的logistic算法,并用梯度下降获取最优值. logistic分类是一个二分类问题,而我们的线性回归函数 的取值在负无穷到正无穷之间,对于分类问题而言,我们希望假设函数的取值在0~1之间,因此logistic函数的假设函数需要改造一下 由上面的公式可以看出,0 < h(x) < 1,这样,我们可以以1/2为分界线 cost function可以这样定义 其中,m是样本的数量,初始时θ可以随机给定一个初始值,算出一个初始的J(θ)值,
-

python实现决策树分类算法代码示例
目录 前置信息 1.决策树 2.样本数据 策树分类算法 1.构建数据集 2.数据集信息熵 3.信息增益 4.构造决策树 5.实例化构造决策树 6.测试样本分类 后置信息:绘制决策树代码 总结 前置信息 1.决策树 决策树是一种十分常用的分类算法,属于监督学习:也就是给出一批样本,每个样本都有一组属性和一个分类结果.算法通过学习这些样本,得到一个决策树,这个决策树能够对新的数据给出合适的分类 2.样本数据 假设现有用户14名,其个人属性及是否购买某一产品的数据如下: 编号 年龄 收入范围 工作性质
-
python实现决策树分类算法
本文实例为大家分享了python实现决策树分类算法的具体代码,供大家参考,具体内容如下 1.概述 决策树(decision tree)--是一种被广泛使用的分类算法. 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现,决策树更加适用. 2.算法思想 通俗来说,决策树分类的思想类似于找对象.现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿:多大年纪了? 母亲:26. 女儿:长的帅不帅? 母亲:挺帅的. 女儿:收入高不?
-
原生python实现knn分类算法
一.题目要求 用原生Python实现knn分类算法. 二.题目分析 数据来源:鸢尾花数据集(见附录Iris.txt) 数据集包含150个数据集,分为3类,分别是:Iris Setosa(山鸢尾).Iris Versicolour(杂色鸢尾)和Iris Virginica(维吉尼亚鸢尾).每类有50个数据,每个数据包含四个属性,分别是:Sepal.Length(花萼长度).Sepal.Width(花萼宽度).Petal.Length(花瓣长度)和Petal.Width(花瓣宽度). 将得到的数据集
-
python sklearn常用分类算法模型的调用
本文实例为大家分享了python sklearn分类算法模型调用的具体代码,供大家参考,具体内容如下 实现对'NB', 'KNN', 'LR', 'RF', 'DT', 'SVM','SVMCV', 'GBDT'模型的简单调用. # coding=gbk import time from sklearn import metrics import pickle as pickle import pandas as pd # Multinomial Naive Bayes Classifier d
-
python实现KNN分类算法
一.KNN算法简介 邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表. kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别. kNN方法在类别决策时,只与极少量的相邻样本有
-
使用python实现kNN分类算法
k-近邻算法是基本的机器学习算法,算法的原理非常简单: 输入样本数据后,计算输入样本和参考样本之间的距离,找出离输入样本距离最近的k个样本,找出这k个样本中出现频率最高的类标签作为输入样本的类标签,很直观也很简单,就是和参考样本集中的样本做对比.下面讲一讲用python实现kNN算法的方法,这里主要用了python中常用的numpy模块,采用的数据集是来自UCI的一个数据集,总共包含1055个样本,每个样本有41个real的属性和一个类标签,包含两类(RB和NRB).我选取800条样本作为参考样
-
用Python实现KNN分类算法
本文实例为大家分享了Python KNN分类算法的具体代码,供大家参考,具体内容如下 KNN分类算法应该算得上是机器学习中最简单的分类算法了,所谓KNN即为K-NearestNeighbor(K个最邻近样本节点).在进行分类之前KNN分类器会读取较多数量带有分类标签的样本数据作为分类的参照数据,当它对类别未知的样本进行分类时,会计算当前样本与所有参照样本的差异大小:该差异大小是通过数据点在样本特征的多维度空间中的距离来进行衡量的,也就是说,如果两个样本点在在其特征数据多维度空间中的距离越近,则这
-
基于python实现KNN分类算法
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别. kNN方法在类别决策时,只与极少量的相邻样本有关.由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合. 通俗简单的说,就是将这个样本进行分类,怎么分类,就是用该样本的
-
python实现K最近邻算法
KNN核心算法函数,具体内容如下 #! /usr/bin/env python3 # -*- coding: utf-8 -*- # fileName : KNNdistance.py # author : zoujiameng@aliyun.com.cn import math def getMaxLocate(target): # 查找target中最大值的locate maxValue = float("-inFinIty") for i in range(len(target)