利用python实现逐步回归
逐步回归的基本思想是将变量逐个引入模型,每引入一个解释变量后都要进行F检验,并对已经选入的解释变量逐个进行t检验,当原来引入的解释变量由于后面解释变量的引入变得不再显著时,则将其删除。以确保每次引入新的变量之前回归方程中只包含显著性变量。这是一个反复的过程,直到既没有显著的解释变量选入回归方程,也没有不显著的解释变量从回归方程中剔除为止。以保证最后所得到的解释变量集是最优的。
本例的逐步回归则有所变化,没有对已经引入的变量进行t检验,只判断变量是否引入和变量是否剔除,“双重检验”逐步回归,简称逐步回归。例子的链接:(原链接已经失效),4项自变量,1项因变量。下文不再进行数学推理,进对计算过程进行说明,对数学理论不明白的可以参考《现代中长期水文预报方法及其应用》汤成友,官学文,张世明著;论文《逐步回归模型在大坝预测中的应用》王晓蕾等;
逐步回归的计算步骤:
1.计算第零步增广矩阵。第零步增广矩阵是由预测因子和预测对象两两之间的相关系数构成的。
2.引进因子。在增广矩阵的基础上,计算每个因子的方差贡献,挑选出没有进入方程的因子中方差贡献最大者对应的因子,计算该因子的方差比,查F分布表确定该因子是否引入方程。
3.剔除因子。计算此时方程中已经引入的因子的方差贡献,挑选出方差贡献最小的因子,计算该因子的方差比,查F分布表确定该因子是否从方程中剔除。
4.矩阵变换。将第零步矩阵按照引入方程的因子序号进行矩阵变换,变换后的矩阵再次进行引进因子和剔除因子的步骤,直到无因子可以引进,也无因子可以剔除为止,终止逐步回归分析计算。
a.以下代码实现了数据的读取,相关系数的计算子程序和生成第零步增广矩阵的子程序。
注意:pandas库读取csv的数据结构为DataFrame结构,此处转化为numpy中的(n-dimension array,ndarray)数组进行计算
import numpy as np
import pandas as pd
#数据读取
#利用pandas读取csv,读取的数据为DataFrame对象
data = pd.read_csv('sn.csv')
# 将DataFrame对象转化为数组,数组的最后一列为预报对象
data= data.values.copy()
# print(data)
# 计算回归系数,参数
def get_regre_coef(X,Y):
S_xy=0
S_xx=0
S_yy=0
# 计算预报因子和预报对象的均值
X_mean = np.mean(X)
Y_mean = np.mean(Y)
for i in range(len(X)):
S_xy += (X[i] - X_mean) * (Y[i] - Y_mean)
S_xx += pow(X[i] - X_mean, 2)
S_yy += pow(Y[i] - Y_mean, 2)
return S_xy/pow(S_xx*S_yy,0.5)
#构建原始增广矩阵
def get_original_matrix():
# 创建一个数组存储相关系数,data.shape几行(维)几列,结果用一个tuple表示
# print(data.shape[1])
col=data.shape[1]
# print(col)
r=np.ones((col,col))#np.ones参数为一个元组(tuple)
# print(np.ones((col,col)))
# for row in data.T:#运用数组的迭代,只能迭代行,迭代转置后的数组,结果再进行转置就相当于迭代了每一列
# print(row.T)
for i in range(col):
for j in range(col):
r[i,j]=get_regre_coef(data[:,i],data[:,j])
return r
b.第二部分主要是计算公差贡献和方差比。
def get_vari_contri(r):
col = data.shape[1]
#创建一个矩阵来存储方差贡献值
v=np.ones((1,col-1))
# print(v)
for i in range(col-1):
# v[0,i]=pow(r[i,col-1],2)/r[i,i]
v[0, i] = pow(r[i, col - 1], 2) / r[i, i]
return v
#选择因子是否进入方程,
#参数说明:r为增广矩阵,v为方差贡献值,k为方差贡献值最大的因子下标,p为当前进入方程的因子数
def select_factor(r,v,k,p):
row=data.shape[0]#样本容量
col=data.shape[1]-1#预报因子数
#计算方差比
f=(row-p-2)*v[0,k-1]/(r[col,col]-v[0,k-1])
# print(calc_vari_contri(r))
return f
c.第三部分调用定义的函数计算方差贡献值
#计算第零步增广矩阵 r=get_original_matrix() # print(r) #计算方差贡献值 v=get_vari_contri(r) print(v) #计算方差比
计算结果: 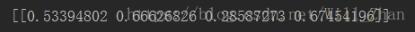
此处没有编写判断方差贡献最大的子程序,因为在其他计算中我还需要变量的具体物理含义所以不能单纯的由计算决定对变量的取舍,此处看出第四个变量的方查贡献最大
# #计算方差比 # print(data.shape[0]) f=select_factor(r,v,4,0) print(f) #######输出########## 22.79852020138227
计算第四个预测因子的方差比(粘贴在了代码中),并查F分布表3.280进行比对,22.8>3.28,引入第四个预报因子。(前三次不进行剔除椅子的计算)
d.第四部分进行矩阵的变换。
#逐步回归分析与计算
#通过矩阵转换公式来计算各部分增广矩阵的元素值
def convert_matrix(r,k):
col=data.shape[1]
k=k-1#从第零行开始计数
#第k行的元素单不属于k列的元素
r1 = np.ones((col, col)) # np.ones参数为一个元组(tuple)
for i in range(col):
for j in range(col):
if (i==k and j!=k):
r1[i,j]=r[k,j]/r[k,k]
elif (i!=k and j!=k):
r1[i,j]=r[i,j]-r[i,k]*r[k,j]/r[k,k]
elif (i!= k and j== k):
r1[i,j] = -r[i,k]/r[k,k]
else:
r1[i,j] = 1/r[k,k]
return r1
e.进行完矩阵变换就循环上面步骤进行因子的引入和剔除
再次计算各因子的方差贡献 
前三个未引入方程的方差因子进行排序,得到第一个因子的方差贡献最大,计算第一个预报因子的F检验值,大于临界值引入第一个预报因子进入方程。
#矩阵转换,计算第一步矩阵 r=convert_matrix(r,4) # print(r) #计算第一步方差贡献值 v=get_vari_contri(r) #print(v) f=select_factor(r,v,1,1) print(f) #########输出##### 108.22390933074443
进行矩阵变换,计算方差贡献 
可以看出还没有引入方程的因子2和3,方差贡献较大的是因子2,计算因子2的f检验值5.026>3.28,故引入预报因子2
f=select_factor(r,v,2,2) print(f) ##########输出######### 5.025864648951804
继续进行矩阵转换,计算方差贡献 
这一步需要考虑剔除因子了,有方差贡献可以知道,已引入方程的因子中方差贡献最小的是因子4,分别计算因子3的引进f检验值0.0183
和因子4的剔除f检验值1.863,均小于3.28(查F分布表)因子3不能引入,因子4需要剔除,此时方程中引入的因子数为2
#选择是否剔除因子, #参数说明:r为增广矩阵,v为方差贡献值,k为方差贡献值最大的因子下标,t为当前进入方程的因子数 def delete_factor(r,v,k,t): row = data.shape[0] # 样本容量 col = data.shape[1] - 1 # 预报因子数 # 计算方差比 f = (row - t - 1) * v[0, k - 1] / r[col, col] # print(calc_vari_contri(r)) return f #因子3的引进检验值0.018233473487350636 f=select_factor(r,v,3,3) print(f) #因子4的剔除检验值1.863262422188088 f=delete_factor(r,v,4,3) print(f)
在此对矩阵进行变换,计算方差贡献 ,已引入因子(因子1和2)方差贡献最小的是因子1,为引入因子方差贡献最大的是因子4,计算这两者的引进f检验值和剔除f检验值
,已引入因子(因子1和2)方差贡献最小的是因子1,为引入因子方差贡献最大的是因子4,计算这两者的引进f检验值和剔除f检验值
#因子4的引进检验值1.8632624221880876,小于3.28不能引进 f=select_factor(r,v,4,2) print(f) #因子1的剔除检验值146.52265486251397,大于3.28不能剔除 f=delete_factor(r,v,1,2) print(f)
不能剔除也不能引进变量,此时停止逐步回归的计算。引进方程的因子为预报因子1和预报因子2,借助上一篇博客写的多元回归。对进入方程的预报因子和预报对象进行多元回归。输出多元回归的预测结果,一次为常数项,第一个因子的预测系数,第二个因子的预测系数。
#因子1和因子2进入方程 #对进入方程的预报因子进行多元回归 # regs=LinearRegression() X=data[:,0:2] Y=data[:,4] X=np.mat(np.c_[np.ones(X.shape[0]),X])#为系数矩阵增加常数项系数 Y=np.mat(Y)#数组转化为矩阵 #print(X) B=np.linalg.inv(X.T*X)*(X.T)*(Y.T) print(B.T)#输出系数,第一项为常数项,其他为回归系数 ###输出## #[[52.57734888 1.46830574 0.66225049]]
以上这篇利用python实现逐步回归就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
sklearn+python:线性回归案例
使用一阶线性方程预测波士顿房价 载入的数据是随sklearn一起发布的,来自boston 1993年之前收集的506个房屋的数据和价格.load_boston()用于载入数据. from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split import time from sklearn.linear_model import LinearRegression bosto
-
Python利用逻辑回归分类实现模板
Logistic Regression Classifier逻辑回归主要思想就是用最大似然概率方法构建出方程,为最大化方程,利用牛顿梯度上升求解方程参数. 优点:计算代价不高,易于理解和实现. 缺点:容易欠拟合,分类精度可能不高. 使用数据类型:数值型和标称型数据. 好了,下面开始正文. 算法的思路我就不说了,我就提供一个万能模板,适用于任何纬度数据集. 虽然代码类似于梯度下降,但他是个分类算法 定义sigmoid函数 def sigmoid(x): return 1/(1+np.exp(-x)
-
python 线性回归分析模型检验标准--拟合优度详解
建立完回归模型后,还需要验证咱们建立的模型是否合适,换句话说,就是咱们建立的模型是否真的能代表现有的因变量与自变量关系,这个验证标准一般就选用拟合优度. 拟合优度是指回归方程对观测值的拟合程度.度量拟合优度的统计量是判定系数R^2.R^2的取值范围是[0,1].R^2的值越接近1,说明回归方程对观测值的拟合程度越好:反之,R^2的值越接近0,说明回归方程对观测值的拟合程度越差. 拟合优度问题目前还没有找到统一的标准说大于多少就代表模型准确,一般默认大于0.8即可 拟合优度的公式:R^2 = 1
-
关于多元线性回归分析——Python&SPSS
原始数据在这里 1.观察数据 首先,用Pandas打开数据,并进行观察. import numpy import pandas as pd import matplotlib.pyplot as plt %matplotlib inline data = pd.read_csv('Folds5x2_pp.csv') data.head() 会看到数据如下所示: 这份数据代表了一个循环发电厂,每个数据有5列,分别是:AT(温度), V(压力), AP(湿度), RH(压强), PE(输出电力).我
-
利用python实现逐步回归
逐步回归的基本思想是将变量逐个引入模型,每引入一个解释变量后都要进行F检验,并对已经选入的解释变量逐个进行t检验,当原来引入的解释变量由于后面解释变量的引入变得不再显著时,则将其删除.以确保每次引入新的变量之前回归方程中只包含显著性变量.这是一个反复的过程,直到既没有显著的解释变量选入回归方程,也没有不显著的解释变量从回归方程中剔除为止.以保证最后所得到的解释变量集是最优的. 本例的逐步回归则有所变化,没有对已经引入的变量进行t检验,只判断变量是否引入和变量是否剔除,"双重检验"逐步回
-

利用Python循环(包括while&for)各种打印九九乘法表的实例
一.for循环打印九九乘法表 #注意:由于缩进在浏览器不好控制,请大家见谅,后续会有图片传入. 1.1 左下角 for i in range(1,10): for j in range(1,i+1): print('%d*%d=%2d\t'%(j,i,i*j),end='') print() 效果图: 1.2 右下角 for i in range(1,10): for k in range(i+1,10): print(end=' ') #此处为返回八个空格,请注意 for j in range
-
MySQL数据库设计之利用Python操作Schema方法详解
弓在箭要射出之前,低声对箭说道,"你的自由是我的".Schema如箭,弓似Python,选择Python,是Schema最大的自由.而自由应是一个能使自己变得更好的机会. Schema是什么? 不管我们做什么应用,只要和用户输入打交道,就有一个原则--永远不要相信用户的输入数据.意味着我们要对用户输入进行严格的验证,web开发时一般输入数据都以JSON形式发送到后端API,API要对输入数据做验证.一般我都是加很多判断,各种if,导致代码很丑陋,能不能有一种方式比较优雅的验证用户数据呢
-
利用python生成一个导出数据库的bat脚本文件的方法
实例如下: # 环境: python3.x def getExportDbSql(db, index): # 获取导出一个数据库实例的sql语句 sql = 'mysqldump -u%s -p%s -h%s -P%d --default-character-set=utf8 --databases mu_ins_s%s > %s.s%d.mu_ins_%d.sql' %(db['user'], db['pwd'], db['host'], db['port'], index, db['serv
-
利用python微信库itchat实现微信自动回复功能
前言 在论坛上看到了用Python登录微信并实现自动签到,才了解到一个新的Python库: itchat 利用Python 微信库itchat,可以实现自动回复等多种功能,好玩到根本停不下来啊,尤其是调戏调戏不懂计算机的,特别有成就感,哈哈!! 代码如下: #coding=utf8 import requests import itchat KEY = '8edce3ce905a4c1dbb965e6b35c3834d' def get_response(msg): apiUrl = 'http
-
利用Python获取操作系统信息实例
前言 每一位运维人员都应该对自己所管理的机器配置很清楚,因为这对我们快速处理问题很有帮助,比如随着业务增长,突然某些机器负载上涨的厉害,这时候要排查原因,除了从应用程序.架构上分析外,当前硬件性能的分析应该是必不可少的一环,今天我们将不用第三方模块,用python自带模块和系统提供的运行信息来获取我们需要的信息,这个脚本除了硬件外,还抓取了当前系统进程数和网卡流量功能,所以这个版本实现的功能基本对应了之前psutil实现的内容,多的不说了,直接贴代码: #!/usr/bin/env python
-
利用python模拟实现POST请求提交图片的方法
本文主要给大家介绍的是关于利用python模拟实现POST请求提交图片的方法,分享出来供大家参考学习,下面来一看看详细的介绍: 使用requests来模拟HTTP请求本来是一件非常轻松的事情,比如上传图片来说,简单的几行代码即可: import requests files = {'attachment_file': ('1.png', open('1.png', 'rb'), 'image/png', {})} values = {'next':"http://www.xxxx.com/xxx
-
利用Python获取赶集网招聘信息前篇
如何获取一个网站的相关信息,获取赶集网的招聘信息,本文为大家介绍利用python获取赶集网招聘信息的关键代码,供大家参考,具体内容如下 import re import urllib import urllib.request #获取赶集网数据 def begin(url): #要伪装成的浏览器(我这个是用的chrome) headers = ('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,
-
利用Python中的pandas库对cdn日志进行分析详解
前言 最近工作工作中遇到一个需求,是要根据CDN日志过滤一些数据,例如流量.状态码统计,TOP IP.URL.UA.Referer等.以前都是用 bash shell 实现的,但是当日志量较大,日志文件数G.行数达数千万亿级时,通过 shell 处理有些力不从心,处理时间过长.于是研究了下Python pandas这个数据处理库的使用.一千万行日志,处理完成在40s左右. 代码 #!/usr/bin/python # -*- coding: utf-8 -*- # sudo pip instal
-
利用python求相邻数的方法示例
前言 本文主要给大家介绍了关于利用python求相邻数的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍: 什么是相邻数? 比如5,相邻数为4和6,和5相差1的数,连续相差为1的一组数 需求: 遍历inputList 所有数字,取出所有数字,判断是否有相邻数, 不相邻数字 和 相邻数字 都以 "数组"形式 添加到 outputList 中, 并且 每个"数组" 里 第一位 递减 补全两位数,末位 递增 补全两位数, 每一个数不能小于0, 不能大