Python猫眼电影最近上映的电影票房信息
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
基本环境配置
- python 3.6
- pycharm
- requests
- csv
相关模块pip安装即可
目标网站
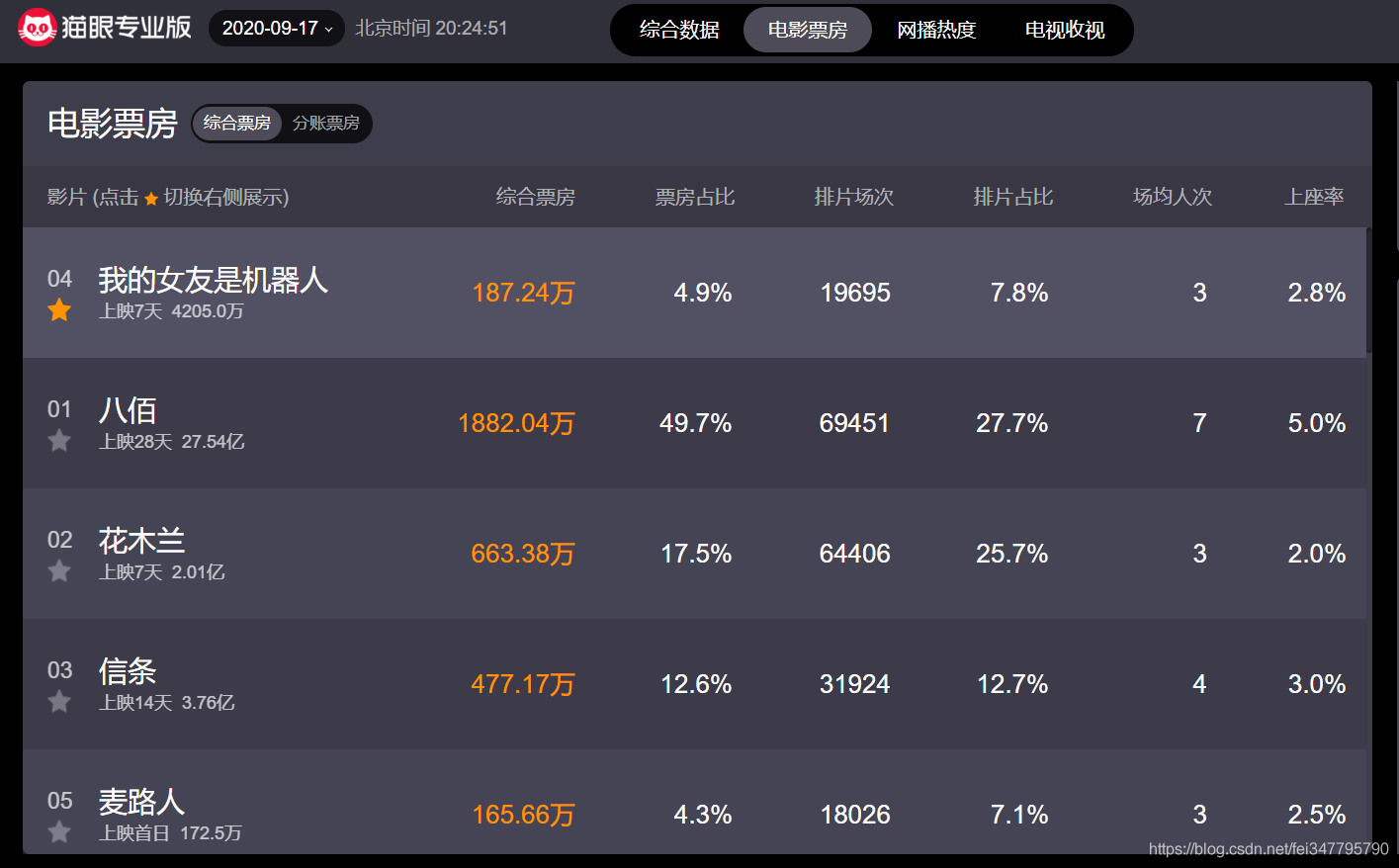
数据接口
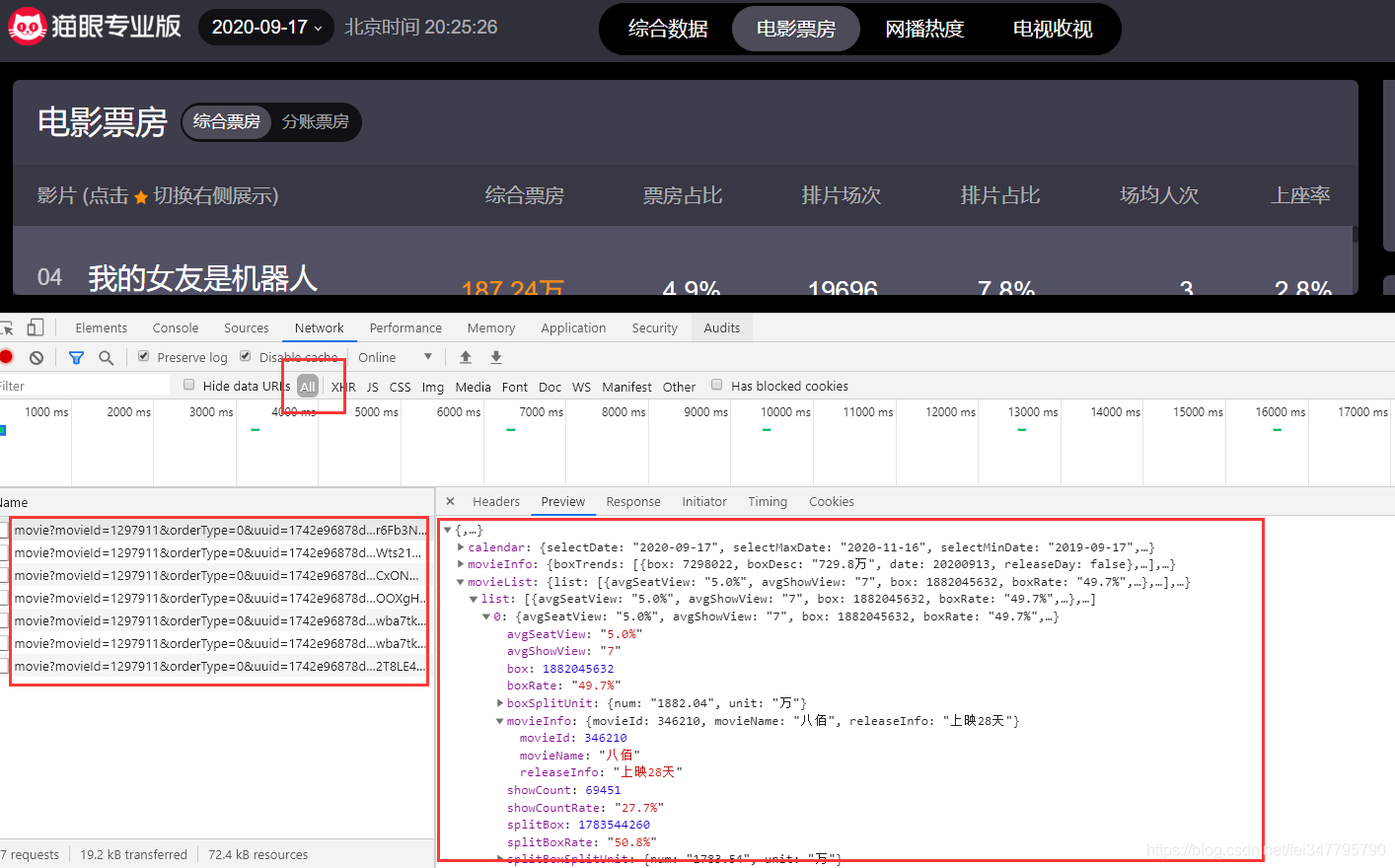
请求网页获取数据
import requests
url = 'http://piaofang.maoyan.com/dashboard-ajax/movie'
params = {
}
cookies = {
}
headers = {
}
response = requests.get(url=url, params=params, headers=headers, cookies=cookies)
html_data = response.json()
pprint.pprint(html_data)
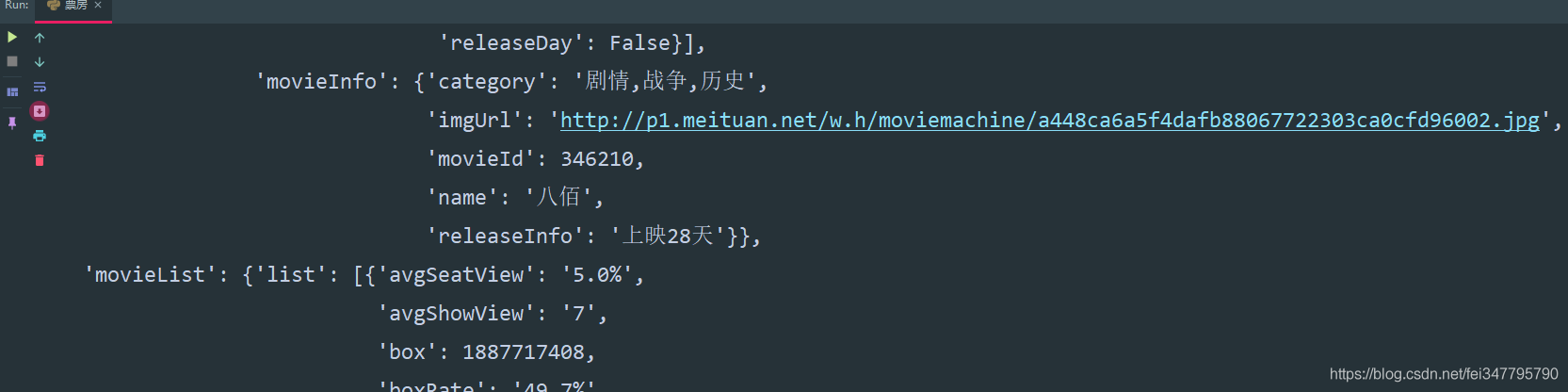
解析数据
movieList = html_data['movieList']['list']
dit = {}
for i in movieList:
dit['电影名'] = i['movieInfo']['movieName']
dit['票房'] = i['sumBoxDesc']
dit['票房占比'] = i['boxRate']
dit['排片占比'] = i['showCountRate']
dit['上映周期'] = i['movieInfo']['releaseInfo']
pprint.pprint(dit)

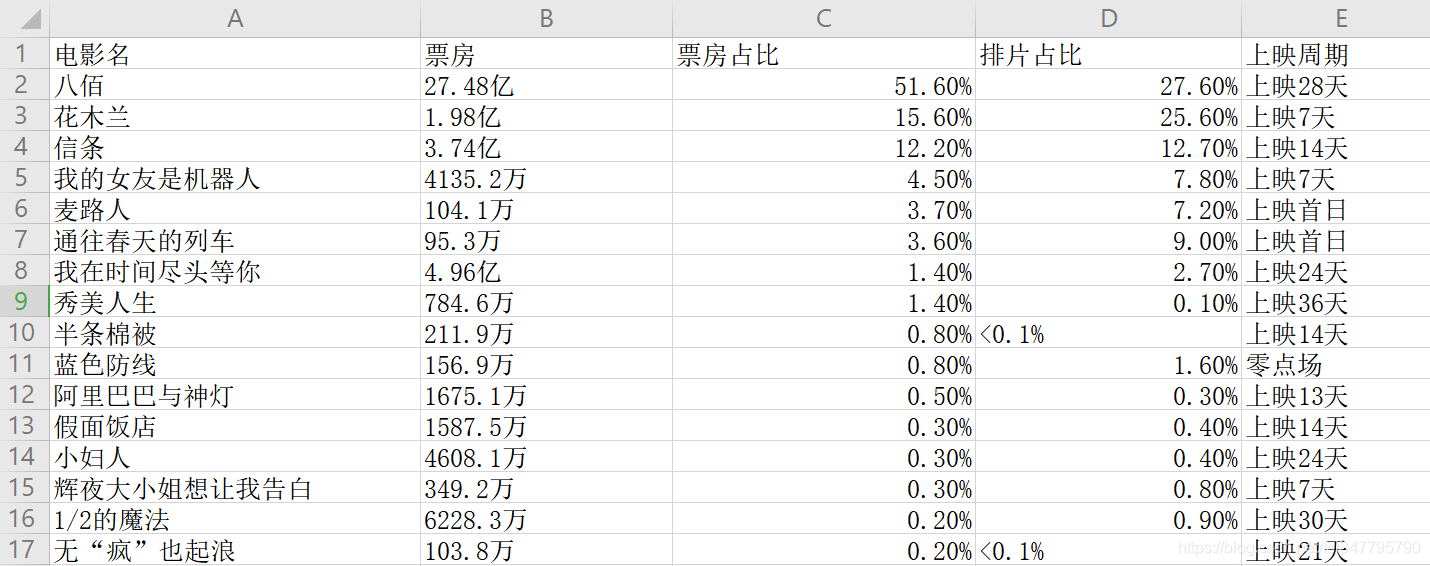
保存数据
import csv
f = open('data.csv', mode='a', encoding='utf-8', newline='')
csv_write = csv.DictWriter(f, fieldnames=['电影名', '票房', '票房占比', '排片占比', '上映周期'])
csv_write.writeheader()
f.close()
到此这篇关于Python猫眼电影最近上映的电影票房信息的文章就介绍到这了,更多相关Python猫眼电影电影票房信息内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫爬取电影票房数据及图表展示操作示例
本文实例讲述了Python爬虫爬取电影票房数据及图表展示操作.分享给大家供大家参考,具体如下: 爬虫电影历史票房排行榜 http://www.cbooo.cn/BoxOffice/getInland?pIndex=1&t=0 Python爬取历史电影票房纪录 解析Json数据 横向条形图展示 面向对象思想 导入相关库 import requests import re from matplotlib import pyplot as plt from matplotlib import font
-
python正则表达式爬取猫眼电影top100
用正则表达式爬取猫眼电影top100,具体内容如下 #!/usr/bin/python # -*- coding: utf-8 -*- import json # 快速导入此模块:鼠标先点到要导入的函数处,再Alt + Enter进行选择 from multiprocessing.pool import Pool #引入进程池 import requests import re import csv from requests.exceptions import RequestException
-
python爬虫开发之使用Python爬虫库requests多线程抓取猫眼电影TOP100实例
使用Python爬虫库requests多线程抓取猫眼电影TOP100思路: 查看网页源代码 抓取单页内容 正则表达式提取信息 猫眼TOP100所有信息写入文件 多线程抓取 运行平台:windows Python版本:Python 3.7. IDE:Sublime Text 浏览器:Chrome浏览器 1.查看猫眼电影TOP100网页原代码 按F12查看网页源代码发现每一个电影的信息都在"<dd></dd>"标签之中. 点开之后,信息如下: 2.抓取单页内容 在浏
-
python爬虫 猫眼电影和电影天堂数据csv和mysql存储过程解析
字符串常用方法 # 去掉左右空格 'hello world'.strip() # 'hello world' # 按指定字符切割 'hello world'.split(' ') # ['hello','world'] # 替换指定字符串 'hello world'.replace(' ','#') # 'hello#world' csv模块 作用:将爬取的数据存放到本地的csv文件中 使用流程 导入模块 打开csv文件 初始化写入对象 写入数据(参数为列表) import csv with o
-
Python猫眼电影最近上映的电影票房信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 基本环境配置 python 3.6 pycharm requests csv 相关模块pip安装即可 目标网站 数据接口 请求网页获取数据 import requests url = 'http://piaofang.maoyan.com/dashboard-ajax/movie' params = { } cookie
-

用Python爬取2022春节档电影信息
目录 前提条件 相关介绍 实验环境 具体步骤 目标网站 分析网站 代码实现 输出结果 总结 前提条件 熟悉HTML基础语句 熟悉Xpath基础语句 相关介绍 Python是一种跨平台的计算机程序设计语言.是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言.最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的.大型项目的开发.Requests是一个很实用的Python HTTP客户端库.Pandas是一个Python软件包,提供快速,灵活和
-
python实现根据用户输入从电影网站获取影片信息的方法
本文实例讲述了python实现根据用户输入从电影网站获取影片信息的方法.分享给大家供大家参考.具体如下: 这段python代码主要演示了用户终端输入,正则表达式,网页抓取等 #!/usr/bin/env python27 #Importing the modules from BeautifulSoup import BeautifulSoup import sys import urllib2 import re import json #Ask for movie title title =
-
详解Python爬取并下载《电影天堂》3千多部电影
不知不觉,玩爬虫玩了一个多月了. 我愈发觉得,爬虫其实并不是什么特别高深的技术,它的价值不在于你使用了什么特别牛的框架,用了多么了不起的技术,它不需要.它只是以一种自动化搜集数据的小工具,能够获取到想要的数据,就是它最大的价值. 我的爬虫课老师也常跟我们强调,学习爬虫最重要的,不是学习里面的技术,因为前端技术在不断的发展,爬虫的技术便会随着改变.学习爬虫最重要的是,学习它的原理,万变不离其宗. 爬虫说白了是为了解决需要,方便生活的.如果能够在日常生活中,想到并应用爬虫去解决实际的问题,那么爬虫的
-
Python实现的爬取豆瓣电影信息功能案例
本文实例讲述了Python实现的爬取豆瓣电影信息功能.分享给大家供大家参考,具体如下: 本案例的任务为,爬取豆瓣电影top250的电影信息(包括序号.电影名称.导演和主演.评分以及经典台词),并将信息作为字典形式保存进txt文件.这里只用到requests库,没有用到beautifulsoup库 step1:首先获取每一页的源代码,用requests.get函数获取,为了防止请求错误,使用try...except.. def getpage(url): try: res=requests.get
-
Python爬取爱奇艺电影信息代码实例
这篇文章主要介绍了Python爬取爱奇艺电影信息代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一,使用库 1.requests 2.re 3.json 二,抓取html文件 def get_page(url): response = requests.get(url) if response.status_code == 200: return response.text return None 三,解析html文件 我们需要的电影信
-
Python机器学习NLP自然语言处理基本操作电影影评分析
目录 概述 RNN 权重共享 计算过程 LSTM 阶段 代码 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. RNN RNN (Recurrent Neural Network), 即循环神经网络. RNN 相较于 CNN, 可以帮助我们更好的处理序列信息, 挖掘前后信息之间的联系. 对于 NLP 这类的任务, 语料的前后概率有极大的联系. 比如: "明天天气真好&
-
Python机器学习NLP自然语言处理Word2vec电影影评建模
目录 概述 词向量 词向量维度 代码实现 预处理 主程序 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词向量 我们先来说说词向量究竟是什么. 当我们把文本交给算法来处理的时候, 计算机并不能理解我们输入的文本, 词向量就由此而生了. 简单的来说, 词向量就是将词语转换成数字组成的向量. 当我们描述一个人的时候, 我们会使用身高体重等种种指标, 这些指标就可以当做向量. 有了向量
-
用python爬取豆瓣前一百电影
目录 实现代码: 代码分析: 运行结果: 总结 网站爬取的流程图: 实现项目我们需要运用以下几个知识点 一.获取网页1.找网页规律:2.使用 for 循环语句获得网站前4页的网页链接:3.使用 Network 选项卡查找Headers信息:4.使用 requests.get() 函数带着 Headers 请求网页. 二.解析网页1.使用 BeautifulSoup 解析网页:2.使用 BeautifulSoup 对象调用 find_all() 方法定位包含单部电影全部信息的标签:3.使用 Tag
-
python爬虫_微信公众号推送信息爬取的实例
问题描述 利用搜狗的微信搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地. 注意点 搜狗微信获取的地址为临时链接,具有时效性. 公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容是不含推送消息的,这里使用selenium+PhantomJS处理 代码 #! /usr/bin/env python3 from selenium import webdriver from datetime import datetime import bs4, requ