C++深入探究引用的使用
目录
- 一. 引用的概念
- 二. 引用特性
- 三. 常引用
- 四. 使用场景
- 1. 做参数
- 2. 做返回值
- 3. 做返回值需要注意的问题
- 五. 传值传引用效率对比
- 1. 值和引用传参时的效率比较
- 2. 值和引用的作为返回值类型的性能比较
- 六. 引用和指针
一. 引用的概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
类型& 引用变量名(对象名) = 引用实体;
如下:
void TestRef()
{
int a = 10;
int& ra = a;//<====定义引用类型
printf("%p\n", &a);
printf("%p\n", &ra);
}
注意:引用类型必须和引用实体是同种类型的
二. 引用特性
1. 引用在定义时必须初始化
2. 一个变量可以有多个引用
3. 引用一旦引用一个实体,再不能引用其他实体
如下:
void TestRef()
{
int a = 10;
int a2 = 20;
//a的多个引用
int& b = a;
int& c = a;
int& d = b;
int& ra;//该条语句编译时会出错,未初始化
int &ra = a2;//报错,引用了其他实体
printf("%p %p %p %p\n", &a, &b, &c, &d);
}

三. 常引用
void TestConstRef()
{
const int a = 10;
//int& ra = a; // 该语句编译时会出错,a为常量
const int& ra = a;
// int& b = 10; // 该语句编译时会出错,b为常量
const int& b = 10;
double d = 12.34;
//int& rd = d; // 该语句编译时会出错,类型不同
const int& rd = d;
//int& c = 100; // 该语句编译时会出错,常量是只读的
const int& c = 100;
}
注意:
引用取别名原则:对原引用变量,读写权限只能缩小,不能放大
const int a = 10;
int& ra = a;
编译不通过,因为放大了权限,原引用本来是只读,但是引用以后却变成了可读可写
int& b = 10;
const int& b = 10;
编译可以通过,因为缩小了权限,原引用本来是可读可写,引用后变成了只读
double d = 12.34;
int& rd = d;
编译不通过,这里比较特殊,看起来是因为类型不同而报错,其实不然,报错是因为权限放大了,为什么?
int类型要引用double类型,double类型转化到int类型属于隐式类型转换会舍弃小数位,隐式类型转换会产生临时变量,double类型到int类型会创建一个临时变量存储double变成了int类型的值,这里需要注意,这个临时变量具有常性是只读的,rd其实是引用了这个临时变量,因为临时变量是只读的,引用了临时变量的rd也应该是只读的,所以这就是为什么const int& rd = d 可以编译通过。
int& c = 100;
编译通过,因为常量本来就是只读的,不加const代表引用后变成了可读可写,权限放大。
四. 使用场景
1. 做参数
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
- 输出型参数
- 减少拷贝,提高效率
2. 做返回值
int& Count()
{
static int n = 0;
n++;
// ...
return n;
}
减少拷贝
(传值返回需要拷贝数据,传引用返回直接返回变量的别名)
3. 做返回值需要注意的问题
首先,我们要知道当函数返回一个值时,会生成一个临时变量,而函数的返回类型就是这个临时变量的类型
int Add(int a, int b)
{
return a + b;
}
int Count()
{
static int n = 0;
n++;
return n;
}
int main()
{
int temp = Add(2, 3);
int tmp = Count();
return 0;
}
以上代码将a+b(n)的值赋值给临时变量,临时变量再赋值给temp(tmp),为什么要设置这个临时变量?
其实很简单,在这个代码里是会有问题的,出了函数作用域a+b的值就已经被销毁了,需要一个临时变量去储存这个返回值,再去访问那块空间是非法的,而被static修饰的n由于它的生命周期变长了,即使出了函数也不会被销毁
那么问题来了,以下代码是正确的吗?
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
return 0;
}
很明显是有问题的!这里将c的引用返回 ,而一旦出了函数c就被销毁了,这块空间也被操作系统收回,再将c的引用赋值给ret就变成了非法访问了,就变成了由引用造成的野指针
由上面的问题可以衍生出以下代码:
这里的ret是什么?
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
Add(3, 4);
cout << "Add(1, 2) is :"<< ret <<endl;
return 0;
}
很明显是7,ret是c的引用,由于出了函数以后这块空间的使用权还给了操作系统,由于第二次函数调用仍然是在第一次函数调用的空间进行栈帧的建立,因为ret的地址(ret的地址就是之前那块临时变量的地址)还是之前那个地址,所以由于第二次返回c时建立的临时变量已经变成了7,所以ret也变成了7
但是一定会是7吗?其实不然,我们知道这块空间的使用权还给了操作系统,这块空间也有可能会被其他程序使用了,导致数值变成了不确定性,因为这里是直接马上又调用了这个函数,所以会是7,所以,其实正确答案应该是随机值才对
看下面这个代码就是典型的例子:
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
Add(3, 4);
cout << "Add(1, 2) is :"<< ret <<endl;
cout << "Add(1, 2) is :"<< ret <<endl;
return 0;
}
这里的输出语句其实也是调用了函数,由上面可知第一个是7,那么第二个呢?随机值!因为进行了第一次输出后其实也是进行了函数调用,函数调用会建立栈帧,在上一个输出建立的栈帧处重新建立了栈帧,函数调用前需要先传参,由于上一个输出语句销毁完栈帧以后ret地址处的值被覆盖成随机值,在第二次输出语句中此时就会把这个随机值作为参数传过去给函数,导致输出了随机值,所以传引用返回不是所有情况都可以使用的,像一开始加上了static关键字之类的才可以返回,因为n的生命周期变长了,出了函数作用域没有被销毁,取值都是去静态区取数据。
结论:如果函数返回时,出了函数作用域,如果返回对象还未还给系统,则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。
五. 传值传引用效率对比
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
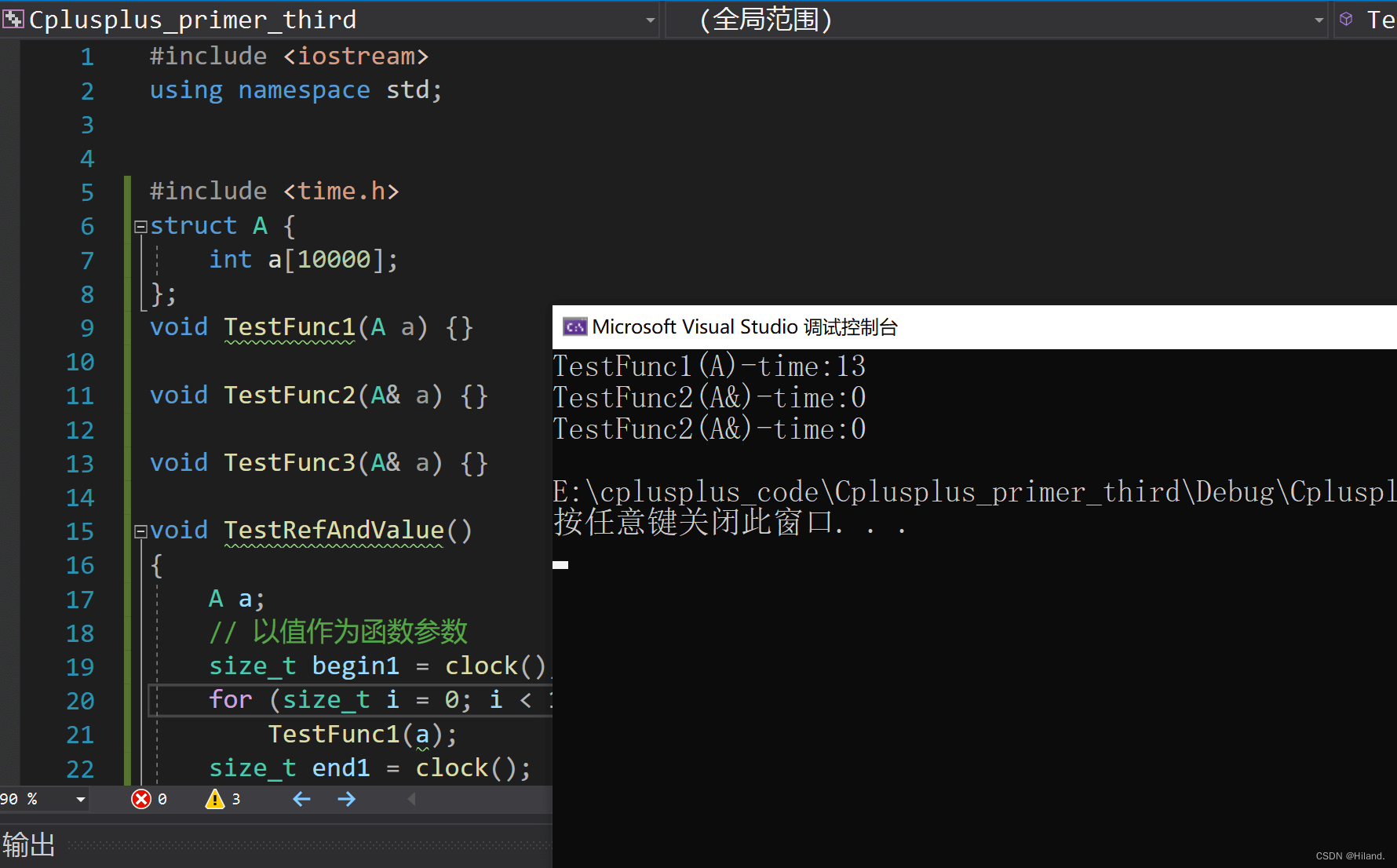
1. 值和引用传参时的效率比较
#include <time.h>
struct A {
int a[10000];
};
void TestFunc1(A a) {}
void TestFunc2(A& a) {}
void TestFunc3(A* a) {}
void TestRefAndValue()
{
A a;
// 以值作为函数参数
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以引用作为函数参数
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 以指针作为参数
size_t begin3 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc3(&a);
size_t end3 = clock();
// 分别计算两个函数运行结束后的时间
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
cout << "TestFunc2(A&)-time:" << end3 - begin3 << endl;
}
2. 值和引用的作为返回值类型的性能比较
#include <time.h>
struct A{ int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a;}
// 引用返回
A& TestFunc2(){ return a;}
void TestReturnByRefOrValue()
{
// 以值作为函数的返回值类型
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1();
size_t end1 = clock();
// 以引用作为函数的返回值类型
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2();
size_t end2 = clock();
// 计算两个函数运算完成之后的时间
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
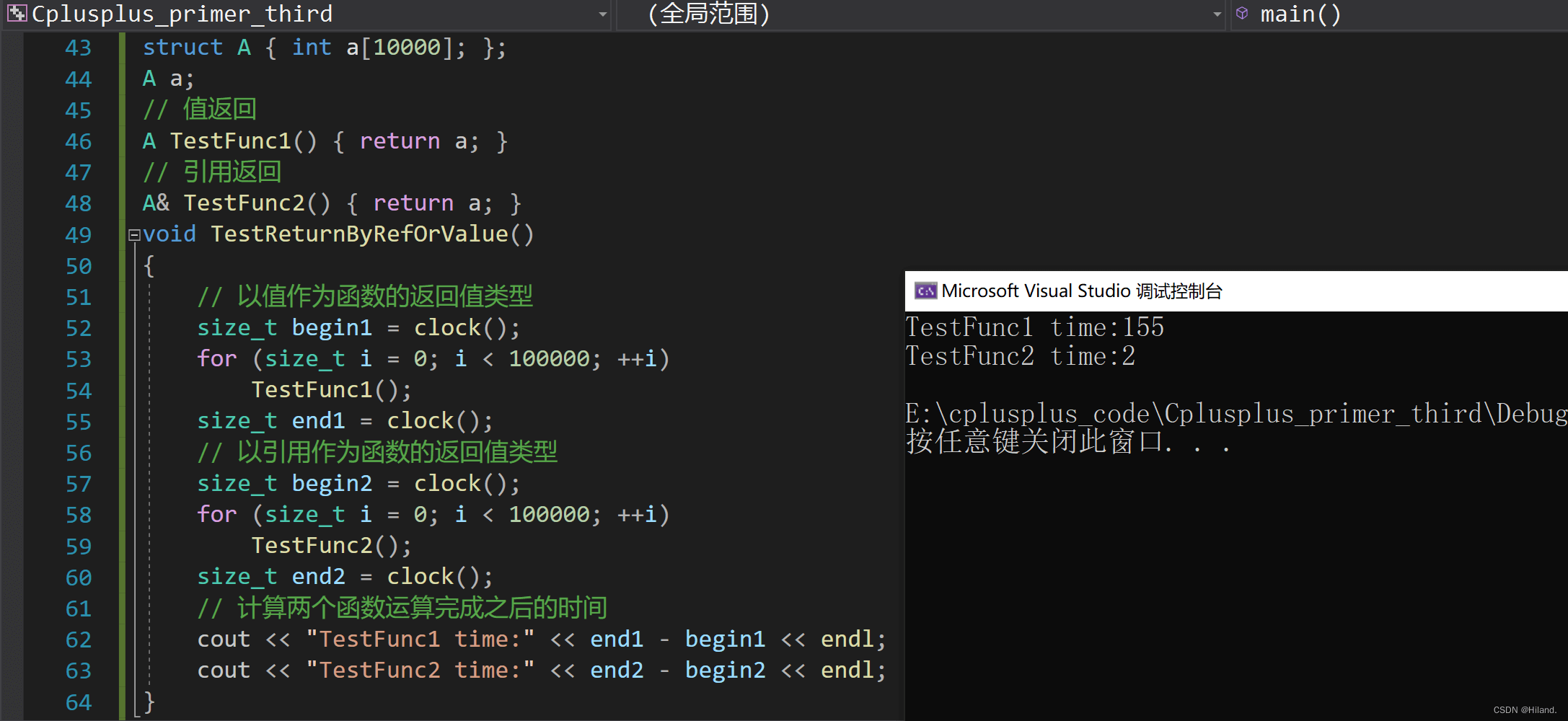
通过上述代码的比较,发现传值和指针在作为传参以及返回值类型上效率相差很大。
六. 引用和指针
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。
int main()
{
int a = 10;
int& ra = a;
cout<<"&a = "<<&a<<endl;
cout<<"&ra = "<<&ra<<endl;
return 0;
}
在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
int main()
{
int a = 10;
int& ra = a;
ra = 20;
int* pa = &a;
*pa = 20;
return 0;
}
我们来看下引用和指针的汇编代码对比:
引用和指针的不同点:
- 引用在定义时必须初始化,指针没有要求(建议初始化)
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占 4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
引用和指针的相同点:
虽然从语法角度来看引用是别名没有额外开空间,但是底层角度来看他们是一样的。
什么是底层角度呢?就是通过编译器处理的结果来看,以下是指针和引用经编译器处理后的结果

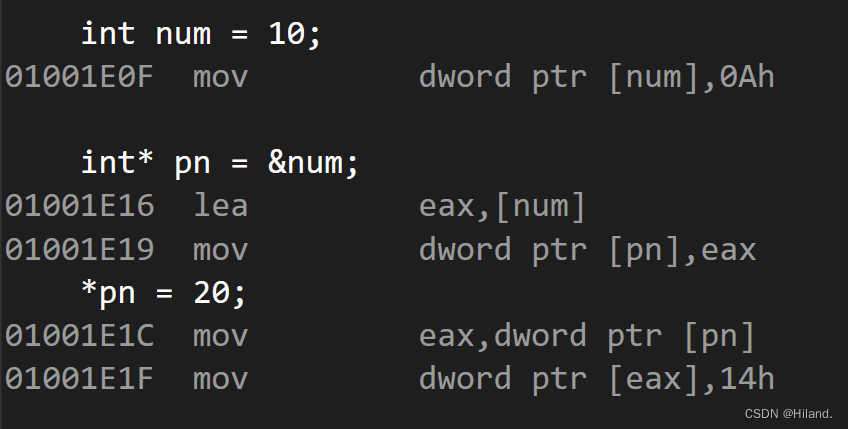
我们会发现汇编指令是一致的,这就说明了从底层角度看这两个实现方式是一样的
到此这篇关于C++深入探究引用的使用的文章就介绍到这了,更多相关C++引用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C++详细分析引用的使用及其底层原理
目录 引用 引用的注意事项 引用做参数 实参传值和传引用的优劣 引用做函数返回值 传引用返回 引用的权限 引用经典笔试题 产生临时变量的情况 关于右值 引用的底层原理 引用 引用不是定义一个新变量,而是给已存在的变量取了一个外号,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间. 举个形象的例子,鲁智深又被叫做"花和尚",这里的花和尚和鲁智深都是同一个人,花和尚就是鲁智深的引用,说白了引用其实就是取外号. 引用的注意事项 1.引用必须初始化 int main() {
-
C++详细分析讲解引用的概念与使用
目录 1.引用的概念 2.引用的格式 3.引用的特性 4.取别名原则 5.引用的使用场景 做参数 做返回值 int&Count()的讲解 传值传引用效率比较 6.引用和指针的不同点 1.引用的概念 引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间. 2.引用的格式 类型 & 引用变量名 ( 对象名 ) = 引用实体: 举例如下: 注意:引用类型必须和引用实体是同种类型的 3.引用的特性 (1). 引用在 定义时必须初
-
C++ 引用与内联函数详情
目录 引用初阶 什么是引用 为何要有引用 引用指向同一块空间 引用的特性 定义时必须初识化 一个变量可以多次引用 引用一旦引用了一个实例,不能在再引用其他的实例 引用进阶 常引用 权限 临时变量具有常属性 引用的场景 做参数 返回值 引用做返回值 引用不会开辟空间 引用和指针比较 内联函数 为何存在 内联函数 展开短小的函数 内联函数的特性 较大的函数编译器不会发生内联 声明定义一起 引用初阶 引用是C++的特性的之一,不过C++没有没有给引用特意出一个关键字,使用了操作符的重载.引用在C++中
-
c++超细致讲解引用
C和C++禁止在函数调用时直接传递数组的内容,而是强制传递数组指针,而对于结构体和对象没有这种限制,调用函数时既可以传递指针,也可以直接传递内容:为了提高效率,我曾建议传递指针,这样做在大部分情况下并没有什么不妥. 但是在 C++ 中,我们有了一种比指针更加便捷的传递聚合类型数据的方式,那就是引用 在 C/C++ 中,我们将 char.int.float 等由语言本身支持的类型称为基本类型,将数组.结构体.类(对象)等由基本类型组合而成的类型称为聚合类型(在讲解结构体时也曾使用复杂类型.构造类型
-
C++深入探究引用的使用
目录 一. 引用的概念 二. 引用特性 三. 常引用 四. 使用场景 1. 做参数 2. 做返回值 3. 做返回值需要注意的问题 五. 传值传引用效率对比 1. 值和引用传参时的效率比较 2. 值和引用的作为返回值类型的性能比较 六. 引用和指针 一. 引用的概念 引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间. 类型& 引用变量名(对象名) = 引用实体: 如下: void TestRef() { int a = 10
-
C++中引用的相关知识点小结
目录 引用的概念 引用特性 常引用 使用场景 引用和指针的区别 总结 引用的概念 引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间. 比如:李逵,在家称为"铁牛",江湖上人称"黑旋风".那么这里的“铁牛”.“黑旋风”就称李逵的引用. 在程序中呢,引用的用法如下: 类型& 引用变量名(对象名) = 引用实体: 举个例子: void TestRef() { int a = 10; int&
-
C++深入探究引用的本质与意义
目录 一.引用的意义 二.特殊的引用 三.引用是否占用存储空间 四.引用的本质 五.引用的注意事项 六.小结 一.引用的意义 引用作为变量别名而存在,因此在一些场合可以代替指针 引用相对于指针来说具有更好的可读性和实用性 下面通过代码来进行说明,在C语言中,可以这么写: #include <stdio.h> void swap(int* a, int* b) { int t = *a; *a = *b; *b = t; } int main() { int a = 1; int b = 2;
-
深入探究Java编程是值传递还是引用传递
目录 1.基本数据类型的参数传递 2.引用数据类型的参数传递 3.原理 文章目的:验证Java语言到底是值传递还是引用传递以及Java参数传递的实现原理. 问题引入: 先阅读代码段: public static void main(String[] args){ Person p=new Person("张三"); f(p); System.out.println("实参:"+p); } public static void f(Person p){ p.name=
-
深入探究node之Transform
本文详细的介绍了node Transform ,分享给大家,希望此文章对各位有所帮助. Transform流特性 在开发中直接接触Transform流的情况不是很多,往往是使用相对成熟的模块或者封装的API来完成流的处理,最为特殊的莫过于through2模块和gulp流操作.那么,Transform流到底有什么特点呢? 从名称上说,Transform意为处理,类似于生产流水线上的每一道工序,每道工序针对到来的产品作相应的处理:从结构上看,Transform是一个双工流,通俗的解释它既可以作为可读
-
iOS面试中如何优雅回答Block导致循环引用的问题
前言 说到循环引用问题,最最最常遇到的,不是在项目中,而是在面试中.如果面试官问你开发中是否遇到过retain cycle,你如果说没遇到过,估计已经很难跟面试官继续友好的沟通下去了. 但是这个问题怎么回答呢,网络上千篇一律的答案-->使用Block的时候遇到过,使用__weakSelf 代替 self 等等,可以说这个答案没啥错,但是所有人都回答的一样,并不能突出我们的逼格,无法让面试官知道我们在这方面有过研究,有闪光点. 对于开发者来说,喜欢探索,喜欢挖掘不懂的知识,在面试官眼里会加分不少.
-
探究ASP.NET Core Middleware实现方法
概念 ASP.NET Core Middleware是在应用程序处理管道pipeline中用于处理请求和操作响应的组件. 每个组件: 在pipeline中判断是否将请求传递给下一个组件 在处理管道的下个组件执行之前和之后执行一些工作, HttpContxt对象能跨域请求.响应的执行周期 特性和行为 ASP.NET Core处理管道由一系列请求委托组成,一环接一环的被调用, 下面给出自己绘制的Middleware pipeline流程图: 从上图可以看出,请求自进入处理管道,经历了四个中间件,每个
-
Vue源码探究之状态初始化
继续随着核心类的初始化展开探索其他的模块,这一篇来研究一下Vue的状态初始化.这里的状态初始化指的就是在创建实例的时候,在配置对象里定义的属性.数据变量.方法等是如何进行初始处理的.由于随后的数据更新变动都交给观察系统来负责,所以在事先弄明白了数据绑定的原理之后,就只需要将目光集中在这一部分. 来仔细看看在核心类中首先执行的关于 state 部分的源码: initState // 定义并导出initState函数,接收参数vm export function initState (vm: Com
-
探究Java常量本质及三种常量池(小结)
之前从他人的博文,还有一些书籍中了解到 常量是放在常量池 中,细节的内容无从得知,总觉得面前的东西是一个几乎完全的黑盒,总是觉得不舒服,于是就翻阅<深入理解Java虚拟机>,这本书中对常量的介绍更多地偏重于字节码文件的结构,还有在自动内存管理机制中也介绍了运行时常量池, 查阅资料后脑海中有了一定的认识. Java中的常量池分为三种形态:静态常量池,字符串常量池以及运行时常量池. 静态常量池 所谓静态常量池,即*.class文件中的常量池,class文件中的常量池不仅仅包含字符串(数字)字面量,
-
Vue 使用iframe引用html页面实现vue和html页面方法的调用操作
当我们需要在vue中使用其他模块或者其他地方的一些html页面功能时,我们可以使用iframe去引用html页面,实现他们的交互 首先我们可以再vue页面中使用标签引用html页面 <template> <div> <iframe name="iframeMap" id="iframeMapViewComponent" width="100%" height="470px" v-bind:src=
-
JAVA深入探究之Method的Invoke方法
前言 在写代码的时候,发现从父类class通过getDeclaredMethod获取的Method可以调用子类的对象,而子类改写了这个方法,从子类class通过getDeclaredMethod也能获取到Method,这时去调用父类的对象也会报错.虽然这是很符合多态的现象,也符合java的动态绑定规范,但还是想弄懂java是如何实现的,就学习了下Method的源代码. Method的invoke方法 1.先检查 AccessibleObject的override属性是否为true. Access