python挖掘蛋卷基金投资组合数据分析
目录
- 一、网页分析
- 1、打开网页
- 2、查看json
- 二、数据获取
- 1、观察json的结构
- 三、代码实现
- 1、基本操作
- 2、写一个可以重复使用的函数
- 3、完整代码
一、网页分析
1、打开网页
我们随意打开一个蛋卷基金上投资组合的网页,例如:
链接: https://danjuanapp.com/strategy/CSI1033

这里以Microsoft Edge浏览器为例 。
点击下载查看详图
2、查看json
选择“XHR”,发现有一个以基金编号命名的文件,单击它,查看请求标头。
点击下载查看详图
GET /djapi/plan/CSI1033 HTTP/1.1 Host: danjuanapp.com Connection: keep-alive sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="90", "Microsoft Edge";v="90" Accept: application/json, text/plain, */* sec-ch-ua-mobile: ?0 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36 Edg/90.0.818.62 elastic-apm-traceparent: 00-25105e3e8908ba33898b0f6cd57b8a73-c782a0e5122abe33-01 Sec-Fetch-Site: same-origin Sec-Fetch-Mode: cors Sec-Fetch-Dest: empty Referer: https://danjuanapp.com/strategy/CSI1033 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6 Cookie: device_id=web_Skhu79T_v; acw_tc=2760774a16215745204941604e9286878fd10c566d03eedbbb0eb93c40e0f5; channel=undefined; xq_a_token=ccd9918c5b2c091c2d0dacb2e264963ba5fb7539; Hm_lvt_b53ede02df3afea0608038748f4c9f36=1621307606,1621428116,1621514481,1621574521; Hm_lpvt_b53ede02df3afea0608038748f4c9f36=1621574634; timestamp=1621574634698
发现好像没什么特别的,说不定没有反爬的机制 ,不如试着直接点开这个链接。
点击下载查看详图
原来这里面存的就是基金基本信息的json!
我们观察这个地址:
https://danjuanapp.com/djapi/plan/CSI1033
发现只要更改最后的编号,就可以获得各个基金的基本信息。
二、数据获取
1、观察json的结构
我们观察一下这个json的结构,这里只截取部分片段。
{
"data": {
"plan_code": "CSI1033",
"plan_name": "螺丝钉主动优选组合",
"yield": "65.93",
"yield_name": "成立以来收益",
"yield_middle": "48.03",
"yield_name_middle": "成立以来年化",
……
"found_date": "2020-02-03",
"manager_xq_id": "3079173340",
"manager_name": "银行螺丝钉",
"manager_profile_photo": "https://danjuan.aiganggu.com/o2020021580801637267.png",
"invest_time_type": 2,
"invest_time_name": "持有3年以上",
"invest_money_type": 4,
"invest_money_name": "积极增值",
"found_days": 473,
"min_buy_amount": "200",
"plan_derived": {
"end_date": "2021-05-20",
"nav_grtd": "-0.03",
"nav_grl1w": "2.38",
……
"unit_nav": "1.6593",
"yield_history": [{
"yield": "-12.02",
"name": "近3个月"
}, {
"yield": "7.40",
"name": "近6个月"
}, {
"yield": "42.25",
……
我们发现,所有数据都存在 “data” 下, “data” 里有基金的基本信息,当日净值存在 “plan_derived” 下的 “unit_nav” 里,那么我们只要按照这个顺序从中获取数据即可。
三、代码实现
1、基本操作
a. 需要使用的模块
用requests获取页面,用json库将json文件转化为字典。
import requests import json
b. 随便设置一个请求标头
header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
c. 获取页面信息
这里的code为基金的代码,用requests获取页面以后读出具体的文本内容,存到page里。
code='CSI1033' url='https://danjuanapp.com/djapi/plan/'+code page=requests.get(url,headers=header).text
我们把page输出出来检查一下,发现我们想要的都在里面。
点击下载查看详图
d. 导入json
因为所有数据都在data里,所以我们直接进入data内即可。
items=json.loads(page)
items=items.get("data")
e. 从json中获取需要的信息
基金的名字
name=items.get('plan_name')
基金的当日净值以及净值的记录日期
这些数据在“plan_derived”内。
value=items.get('plan_derived').get("unit_nav")
date=items.get('plan_derived').get("end_date")
2、写一个可以重复使用的函数
我们以code作为传入的参数,把刚才的内容组合起来。
def getfund(code):
url='https://danjuanapp.com/djapi/plan/'+code
page=requests.get(url,headers=header).text
items=json.loads(page)
items=items.get("data")
value=items.get('plan_derived').get("unit_nav")
date=items.get('plan_derived').get("end_date")
name=items.get('plan_name')
print("基金编号:",code,'\n基金名:',name,"\n日期:",date,"净值:",value)
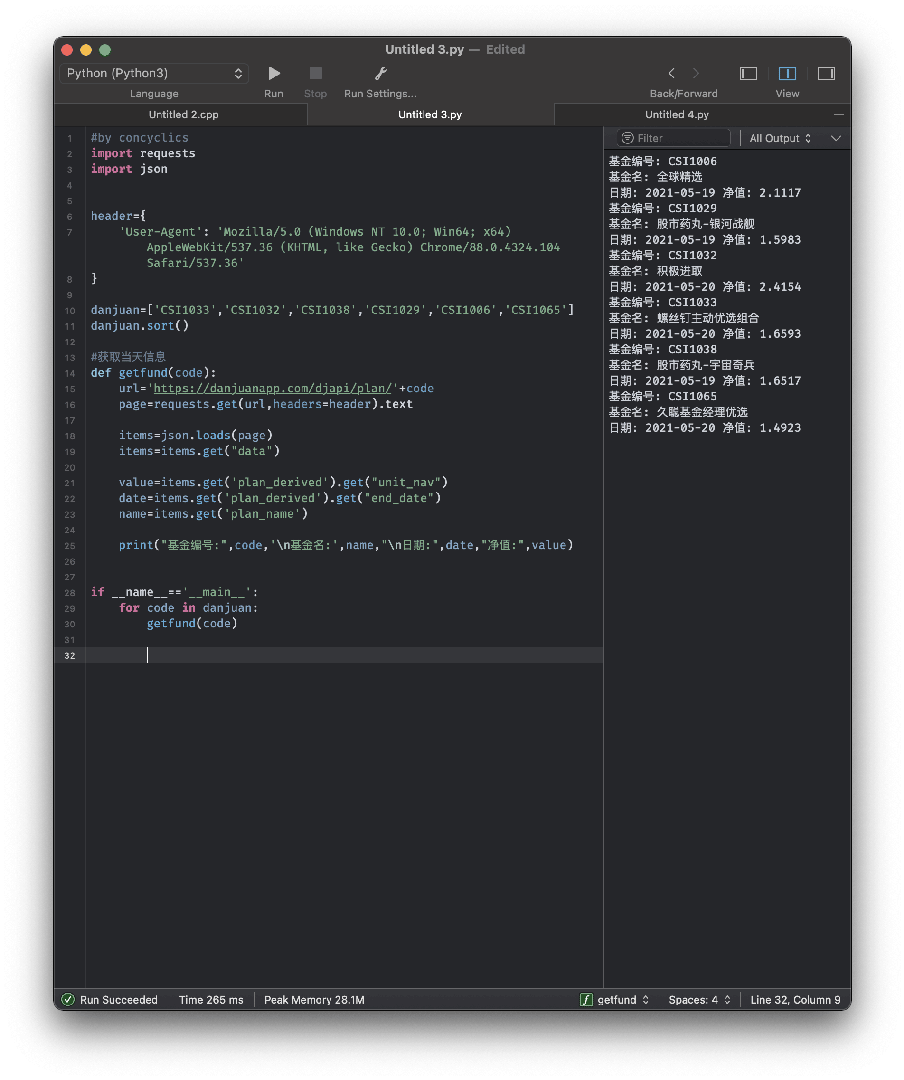
3、完整代码
#by concyclics
import requests
import json
header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
danjuan=['CSI1033','CSI1032','CSI1038','CSI1029','CSI1006','CSI1065']
danjuan.sort()
#获取当天信息
def getfund(code):
url='https://danjuanapp.com/djapi/plan/'+code
page=requests.get(url,headers=header).text
items=json.loads(page)
items=items.get("data")
value=items.get('plan_derived').get("unit_nav")
date=items.get('plan_derived').get("end_date")
name=items.get('plan_name')
print("基金编号:",code,'\n基金名:',name,"\n日期:",date,"净值:",value)
if __name__=='__main__':
for code in danjuan:
getfund(code)
这样,我们的功能就基本实现了,更多关于python挖掘蛋卷基金投资数据的资料请关注我们其它相关文章!
相关推荐
-

python挖掘蛋卷基金投资组合数据分析
目录 一.网页分析 1.打开网页 2.查看json 二.数据获取 1.观察json的结构 三.代码实现 1.基本操作 2.写一个可以重复使用的函数 3.完整代码 一.网页分析 1.打开网页 我们随意打开一个蛋卷基金上投资组合的网页,例如: 链接: https://danjuanapp.com/strategy/CSI1033 这里以Microsoft Edge浏览器为例 . 点击下载查看详图 2.查看json 选择“XHR”,发现有一个以基金编号命名的文件,单击它,查看请求标头. 点击下载查看详
-
基于Python实现的微信好友数据分析
最近微信迎来了一次重要的更新,允许用户对"发现"页面进行定制.不知道从什么时候开始,微信朋友圈变得越来越复杂,当越来越多的人选择"仅展示最近三天的朋友圈",大概连微信官方都是一脸的无可奈何.逐步泛化的好友关系,让微信从熟人社交逐渐过渡到陌生人社交,而朋友圈里亦真亦幻的状态更新,仿佛在努力证明每一个个体的"有趣". 有人选择在朋友圈里记录生活的点滴,有人选择在朋友圈里展示观点的异同,可归根到底,人们无时无刻不在窥探着别人的生活,唯独怕别人过多地了解
-
使用Python对微信好友进行数据分析
1.准备工作 1.1 库介绍 只有登录微信才能获取到微信好友的信息,本文采用wxpy该第三方库进行微信的登录以及信息的获取. wxpy 在 itchat 的基础上,通过大量接口优化提升了模块的易用性,并进行丰富的功能扩展. wxpy一些常见的场景: •控制路由器.智能家居等具有开放接口的玩意儿 •运行脚本时自动把日志发送到你的微信 •加群主为好友,自动拉进群中 •跨号或跨群转发消息 •自动陪人聊天 •逗人玩 总而言之,可用来实现各种微信个人号的自动化操作. 1.2 wxpy库安装 wxpy 支持
-
Python实现的微信好友数据分析功能示例
本文实例讲述了Python实现的微信好友数据分析功能.分享给大家供大家参考,具体如下: 这里主要利用python对个人微信好友进行分析并把结果输出到一个html文档当中,主要用到的python包为itchat,pandas,pyecharts等 1.安装itchat 微信的python sdk,用来获取个人好友关系.获取的代码 如下: import itchat import pandas as pd from pyecharts import Geo, Bar itchat.login() f
-
Python实现的北京积分落户数据分析示例
本文实例讲述了Python实现的北京积分落户数据分析.分享给大家供大家参考,具体如下: 北京积分落户状况 获取数据(爬虫/文件下载)-> 分析 (维度-指标) 从公司维度分析不同公司对落户人数指标的影响 , 即什么公司落户人数最多也更容易落户 从年龄维度分析不同年龄段对落户人数指标影响 , 即什么年龄段落户人数最多也更容易落户 从百家姓维度分析不同姓对落户人数的指标影响 , 即什么姓的落户人数最多即也更容易落户 不同分数段的占比情况 # 导入库 import numpy as np import
-
用Python 爬取猫眼电影数据分析《无名之辈》
前言 作者: 罗昭成 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef 获取猫眼接口数据 作为一个长期宅在家的程序员,对各种抓包简直是信手拈来.在 Chrome 中查看原代码的模式,可以很清晰地看到接口,接口地址即为:http://m.maoyan.com/mmdb/comments/movie/1208282.json?_v_=yes&o
-
详解python爬取弹幕与数据分析
很不幸的是,由于疫情的关系,原本线下的AWD改成线上CTF了.这就很难受了,毕竟AWD还是要比CTF难一些的,与人斗现在变成了与主办方斗. 虽然无奈归无奈,但是现在还是得打起精神去面对下一场比赛.这个开始也是线下的,决赛地点在南京,后来是由于疫情的关系也成了线上. 当然,比赛内容还是一如既往的得现学,内容是关于大数据的. 由于我们学校之前并没有开设过相关培训,所以也只能自己琢磨了. 好了,废话先不多说了,正文开始. 一.比赛介绍 大数据总体来说分为三个过程. 第一个过程是搭建hadoop环境.
-
Python批量获取基金数据的方法步骤
20年初准备投资基金,想爬取基金的业绩数据. 20年基金迎来了爆发式增长,现把代码开源以供参考. 本代码只能实现初步汇总,输出csv文件来保存基金的单位&累计净值,后期仍需要结合统计方法来筛选优质基金. 参考了网上的部分代码,实在不记得出处了,侵删. import requests import time import execjs start = time.perf_counter() # 获取所有基金编号 def getAllCode(): url = 'http://fund.eastmo
-
利用python实时刷新基金估值(摸鱼小工具)
摸鱼小工具_利用python实时刷新基金估值 效果预览 上源码 import requests import json import os from prettytable import PrettyTable import time fundlist = ['163817','161017','003860'] def GetFundJsonInfo(fundcode): url = "http://fundgz.1234567.com.cn/js/"+fundcode+"
-
Python Sweetviz轻松实现探索性数据分析
Sweetviz 是一个开源 Python 库,它只需三行代码就可以生成漂亮的高精度可视化效果来启动EDA(探索性数据分析).输出一个HTML.文末提供技术交流群,喜欢点赞支持,收藏. 如上图所示,它不仅能根据性别.年龄等不同栏目纵向分析数据,还能对每个栏目做众数.最大值.最小值等横向对比. 所有输入的数值.文本信息都会被自动检测,并进行数据分析.可视化和对比,最后自动帮你进行总结,是一个探索性数据分析的好帮手. 1.准备 请选择以下任一种方式输入命令安装依赖: 1. Windows 环境 打开