让你一文弄懂Pandas文本数据处理
目录
- 前言
- 1. 文本数据类型
- 1.1. 类型简介
- 1.2. 类型差异
- 2. 字符串方法
- 2.1. 文本格式
- 2.2. 文本对齐
- 2.3. 计数与编码
- 2.4. 格式判断
- 3. 文本高级操作
- 3.1. 文本拆分
- 3.2. 文本替换
- 3.3. 文本拼接
- 3.4. 文本匹配
- 3.5. 文本提取
- 总结
前言
日常工作中我们经常接触到一些文本类信息,需要从文本中解析出数据信息,然后再进行数据分析操作。
而对文本类信息进行解析是一件比较头秃的事情,好巧,Pandas刚好对这类文本数据有比较好的处理方法,那就让我们来一起学一学吧!
1. 文本数据类型
在pandas中存储文本数据有两种方式:object 和 string。在pandas 1.0版本之前,object是唯一的文本类型,在一列数据中如果包含数值和文本等混合类型则一般也会默认为object。在pandas 1.0 版本之后,新增了string文本类型,可以更好的支持字符串的处理。
1.1. 类型简介
默认情况下,object仍然是文本数据默认的类型。

如果要采用string类型,我们可以通过dtype进行指定

在Series 或 Dataframe被创建后,我们还可以通过astype进行类型强制转换

当然,我们还有个df.convert_dtypes()方法可以进行智能数据类型选择

1.2. 类型差异
string和object在操作上有所不同。
对于sting来说,返回数字输出的字符串访问器方法将始终返回可为空的整数类型;对于object来说,是 int 或 float,具体取决于 NA 值的存在

对于string类型来说,返回布尔输出的方法将返回一个可为空的布尔数据类型

2. 字符串方法
Series 和 Index 都有一些字符串处理方法,可以方便进行操作,最重要的是,这些方法会自动排除缺失/NA 值,我们可以通过str属性访问这些方法。
2.1. 文本格式
文本格式是对字符串文本进行格式操作,比如转换大小写之类的
>>> s = pd.Series( ... ["A", "B", "Aaba", "Baca", np.nan, "cat"], ... dtype="string" ... ) >>> s.str.lower() # 转小写 0 a 1 b 2 aaba 3 baca 4 <NA> 5 cat dtype: string >>> s.str.upper() # 转大写 0 A 1 B 2 AABA 3 BACA 4 <NA> 5 CAT dtype: string >>> s.str.title() # 每个单词大写 0 A 1 B 2 Aaba 3 Baca 4 <NA> 5 Cat dtype: string >>> s.str.capitalize() # 首字母大写 0 A 1 B 2 Aaba 3 Baca 4 <NA> 5 Cat dtype: string >>> s.str.swapcase() # 大小写互换 0 a 1 b 2 aABA 3 bACA 4 <NA> 5 CAT dtype: string >>> s.str.casefold() # 转为小写,支持其他语言 0 a 1 b 2 aaba 3 baca 4 <NA> 5 cat dtype: string
2.2. 文本对齐
文本对齐是指在文本显示的时候按照一定的规则进行对齐处理,比如左对齐、右对齐、居中等等
>>> s.str.center(10,fillchar='-') # 居中对齐,宽度为10,填充字符为'-' 0 ----A----- 1 ----B----- 2 ---Aaba--- 3 ---Baca--- 4 <NA> 5 ---cat---- dtype: string >>> s.str.ljust(10,fillchar='-') # 左对齐 0 A--------- 1 B--------- 2 Aaba------ 3 Baca------ 4 <NA> 5 cat------- dtype: string >>> s.str.rjust(10,fillchar='-') # 右对齐 0 ---------A 1 ---------B 2 ------Aaba 3 ------Baca 4 <NA> 5 -------cat dtype: string >>> s.str.pad(width=10, side='left', fillchar='-') # 指定宽度,填充字符对齐方式为 left,填充字符为'-' 0 ---------A 1 ---------B 2 ------Aaba 3 ------Baca 4 <NA> 5 -------cat dtype: string >>> s.str.zfill(3) # 指定宽度3,不足则在前面添加0 0 00A 1 00B 2 Aaba 3 Baca 4 <NA> 5 cat dtype: string
2.3. 计数与编码
文本计数与内容编码
>>> s.str.count("a") # 字符串中指定字母的数量
0 0
1 0
2 2
3 2
4 <NA>
5 1
dtype: Int64
>>> s.str.len() # 字符串的长度
0 1
1 1
2 4
3 4
4 <NA>
5 3
dtype: Int64
>>> s.str.encode('utf-8') # 编码
0 b'A'
1 b'B'
2 b'Aaba'
3 b'Baca'
4 <NA>
5 b'cat'
dtype: object
>>> s.str.encode('utf-8').str.decode('utf-8') # 解码
0 A
1 B
2 Aaba
3 Baca
4 <NA>
5 cat
dtype: object
2.4. 格式判断
格式判断就是对字符串进行字符格式判断,比如是不是数字,是不是字母,是不是小数等等
>>> s = pd.Series( ... ["A", "B", "Aaba", 12, 5, np.nan, "cat"], ... dtype="string" ... ) >>> s.str.isalpha() # 是否为字母 0 True 1 True 2 True 3 False 4 False 5 <NA> 6 True dtype: boolean >>> s.str.isnumeric() # 是否为数字0-9 0 False 1 False 2 False 3 True 4 True 5 <NA> 6 False dtype: boolean >>> s.str.isalnum() # 是否由数字或字母组成 0 True 1 True 2 True 3 True 4 True 5 <NA> 6 True dtype: boolean >>> s.str.isdigit() # 是否为数字 0 False 1 False 2 False 3 True 4 True 5 <NA> 6 False dtype: boolean >>> s.str.isdecimal() # 是否为小数 0 False 1 False 2 False 3 True 4 True 5 <NA> 6 False dtype: boolean >>> s.str.isspace() # 是否为空格 0 False 1 False 2 False 3 False 4 False 5 <NA> 6 False dtype: boolean >>> s.str.islower() # 是否为小写 0 False 1 False 2 False 3 False 4 False 5 <NA> 6 True dtype: boolean >>> s.str.isupper() # 是否为大写 0 True 1 True 2 False 3 False 4 False 5 <NA> 6 False dtype: boolean >>> s.str.istitle() # 是否为标题格式 0 True 1 True 2 True 3 False 4 False 5 <NA> 6 False dtype: boolean
以上这些字符串的方法其实和python原生的字符串方法基本相同。
3. 文本高级操作
文本高级操作包含文本拆分、文本替换、文本拼接、文本匹配与文本提取等,学会这些操作技巧,我们基本上就可以完成常见的复杂文本信息处理与分析了。
3.1. 文本拆分
文本拆分类似excel里的数据分列操作,将文本内容按照指定的字符进行分隔,具体大家可以看下面案例。
方法split()返回的是一个列表

我们可以使用get 或 []符号访问拆分列表中的元素

我们还可以将拆分后的列表展开,需要使用参数expand

同样,我们可以限制分隔的次数,默认是从左开始(rsplit是从右到左),用到参数n

对于更复杂的拆分规格,我们可以在分隔符处传入正则表达式

补充:像str.slice()切片选择方法与str.partition()文本划分方法都有类似效果,大家可以自定查阅官方文档案例了解。
3.2. 文本替换
我们经常在数据处理中用到替换功能,将指定的一些数据替换成我们想要替换的内容。同样,在处理文本数据替换的时候,str.repalce()也可以很好的满足这一操作。

以上案例中,将regex参数设置为False就可以进行字面替换而不是对每个字符进行转义;反之,则需要转义,为正则替换。
此外,我们还可以正则表达式替换,比如下面这个例子中我们实现的是对文本数据中英文部分进行倒序替换:
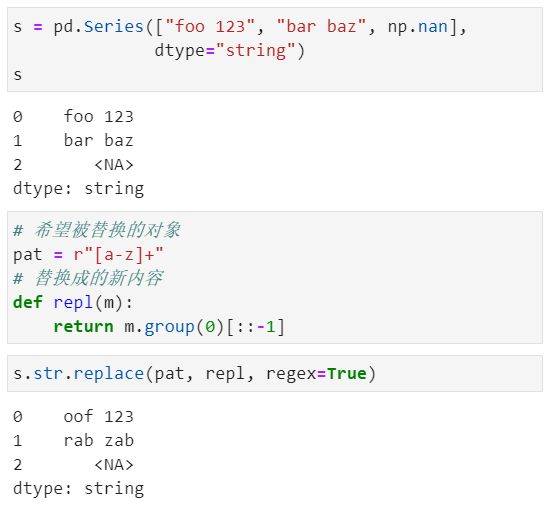
可能部分同学无法直观的理解上面的正则案例,这里简单的拆解介绍下:

关于正则表达式的一些介绍,大家还可以参考此前推文《》进行更多了解。
另外,我们还可以通过str.slice_replace()方法实现保留选定内容,替换剩余内容的操作:

补充:我们还可通过str.repeat()方法让原有的文本内容重复,具体大家可以自行体验
3.3. 文本拼接
文本拼接是指将多个文本连接在一起,基于str.cat()方法
比如,将一个序列的内容进行拼接,默认情况下会忽略缺失值,我们亦可指定缺失值

连接一个序列和另一个等长的列表,默认情况下如果有缺失值,则会导致结果中也有缺失值,不过可以通过指定缺失值na_rep的情况进行处理

连接一个序列和另一个等长的数组(索引一致)

索引对齐

在索引对齐中,我们还可以通过参数join来指定对齐形式,默认为左对齐left,还有outer, inner, right

3.4. 文本匹配
文本匹配这里我们介绍查询和包含判断,分别用到str.findall()、str.find()和str.contains()方法。
文本查询,str.findall()返回查询到的值,str.find()返回匹配到的结果所在的位置(-1表示不存在)

文本包含,其实str.contain()常见于数据筛选中

此外,还有str.startwith()和str.endwith()用于指定开头还是结尾包含某字符的情况,而str.match()则可用于正则表达式匹配。
3.5. 文本提取
我们在日常中经常遇到需要提取某序列文本中特定的字符串,这个时候采用str.extract()方法就可以很好的进行处理,它是用正则表达式将文本中满足要求的数据提取出来形成单独的列。
比如下面这个案例,我们用正则表达式将文本分为两部分,第一部分是字母a和b,第二部分匹配数字:

在上述案例中,expand参数为Fasle时如果返回结果是一列则为Series,否则是Dataframe。
我们还可以对提取的列进行命令,形式如?P<列名称>,具体如下:

提取全部匹配项,会将一个文本中所有符合规则的内容匹配出来,最后形成一个多层索引数据:

我们还可以从字符串列中提取虚拟变量,例如用"|"分隔(第一行abc只有a,第二行有a和b,第三行都没有,第四行有a和c):

以上就是本次全部内容,相信大家在熟练这些文本数据处理的操作后,在日常工作中对于文本数据的处理将会非常得心应手。
总结
到此这篇关于Pandas文本数据处理的文章就介绍到这了,更多相关Pandas文本数据处理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pandas数据处理进阶详解
一.pandas的统计分析 1.关于pandas 的数值统计(统计detail 中的 单价的相关指标) import pandas as pd # 加载数据 detail = pd.read_excel("./meal_order_detail.xlsx") print("detail :\n", detail) print("detail 的列索引名称:\n", detail.columns) print("detail 的形状:\n
-
pandas 空数据处理方法详解
这篇文章主要介绍了pandas 空数据处理方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 方法一:直接删除 1.查看行或列是否有空格(以下的df为DataFrame类型,axis=0,代表列,axis=1代表行,以下的返回值都是行或列索引加上布尔值) isnull方法 查看行:df.isnull().any(axis=1) 查看列:df.isnull().any(axis=0) notnull方法: 查看行:df.notnull().a
-

Python 数据处理库 pandas 入门教程基本操作
pandas是一个Python语言的软件包,在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础编程库.本文是对它的一个入门教程. pandas提供了快速,灵活和富有表现力的数据结构,目的是使"关系"或"标记"数据的工作既简单又直观.它旨在成为在Python中进行实际数据分析的高级构建块. 入门介绍 pandas适合于许多不同类型的数据,包括: 具有异构类型列的表格数据,例如SQL表格或Excel数据 有序和无序(不一定是固定频率)时间序列数据.
-
Pandas 数据处理,数据清洗详解
如下所示: # -*-coding:utf-8-*- from pandas import DataFrame import pandas as pd import numpy as np """ 获取行列数据 """ df = DataFrame(np.random.rand(4, 5), columns=['A', 'B', 'C', 'D', 'E']) print df print df['col_sum'] = df.apply(lam
-
让你一文弄懂Pandas文本数据处理
目录 前言 1. 文本数据类型 1.1. 类型简介 1.2. 类型差异 2. 字符串方法 2.1. 文本格式 2.2. 文本对齐 2.3. 计数与编码 2.4. 格式判断 3. 文本高级操作 3.1. 文本拆分 3.2. 文本替换 3.3. 文本拼接 3.4. 文本匹配 3.5. 文本提取 总结 前言 日常工作中我们经常接触到一些文本类信息,需要从文本中解析出数据信息,然后再进行数据分析操作. 而对文本类信息进行解析是一件比较头秃的事情,好巧,Pandas刚好对这类文本数据有比较好的处理方法,那
-
一文弄懂Pytorch的DataLoader, DataSet, Sampler之间的关系
以下内容都是针对Pytorch 1.0-1.1介绍. 很多文章都是从Dataset等对象自下往上进行介绍,但是对于初学者而言,其实这并不好理解,因为有的时候会不自觉地陷入到一些细枝末节中去,而不能把握重点,所以本文将会自上而下地对Pytorch数据读取方法进行介绍. 自上而下理解三者关系 首先我们看一下DataLoader.next的源代码长什么样,为方便理解我只选取了num_works为0的情况(num_works简单理解就是能够并行化地读取数据). class DataLoader(obje
-
一文弄懂JavaScript的继承方式
目录 JavaScript中的继承方式 问:JavaScript中有几种继承方式呢 问:每种继承方式是怎么实现的呢 盗用构造函数 组合继承 原型链式继承 寄生式继承 寄生时组合继承 JavaScript中的继承方式 问:JavaScript中有几种继承方式呢 emmm...六种?五种?还是四种来着... 这次记清楚了 一共有五种继承方式 盗用构造函数 (经典继承方式 ) 组合继承 原型链式继承 寄生式继承 寄生式组合继承 问:每种继承方式是怎么实现的呢 盗用构造函数 基本思路很简单:在子类构造函
-
一文搞懂Pandas数据透视的4个函数的使用
目录 pandas.melt() pandas.pivot() pandas.pivot_table() pandas.crosstab() 大家好,我是丁小杰! 今天和大家分享Pandas中四种有关数据透视的通用函数,在数据处理中遇到这类需求时,能够很好地应对. pandas.melt() melt函数的主要作用是将DataFrame从宽格式转换成长格式. “ pandas.melt(frame,id_vars=None, value_vars=None, var_name=None, val
-
一文弄懂Nginx的location匹配的实现
由于团队在进行前后端分离,前端接管了 Nginx 和 node 层,在日常的工作中,跟 Nginx 打交道的时候挺多的.其中 location 是使用最多和改动最多的地方.之前对 location 的匹配规则是一知半解的.为了搞明白 location 是如何匹配的,特意花了点时间查了些资料,总结此文.希望能给大家带来帮助. 语法规则 location [ = | ~ | ~* | ^~ ] uri { ... } location @name { ... } 语法规则很简单,一个location
-
一文弄懂C语言如何实现单链表
目录 一.单链表与顺序表的区别: 一.顺序表: 二.链表 二.关于链表中的一些函数接口的作用及实现 1.头文件里的结构体和函数声明等等 2.创建接口空间 3.尾插尾删 4.头插头删 5.单链表查找 6.中间插入(在pos后面进行插入) 7.中间删除(在pos后面进行删除) 8.单独打印链表和从头到尾打印链表 9.test.c 总结 一.单链表与顺序表的区别: 一.顺序表: 1.内存中地址连续 2.长度可以实时变化 3.不支持随机查找 4.适用于访问大量元素的,而少量需要增添/删除的元素的程序 5
-
一文弄懂MySQL中redo log与binlog的区别
目录 前言 1. 什么是redo log? 1.1 redo日志文件名 1.2 影响redo log参数 1.3 redo log大小怎么设置? 2. 什么是binlog 2.1 binlog文件名 2.2 影响binlog的参数 2.3 查看binlog 3. redo log与binlog的区别 总结 前言 MySQL中有六种日志文件,分别是:重做日志(redo log).回滚日志(undo log).二进制日志(binlog).错误日志(errorlog).慢查询日志(slow query
-
一文弄懂MySQL索引创建原则
目录 一.适合创建索引 1.字段的数值有唯一性限制 2.频繁作为Where查询条件的字段 3.经常Groupby和Orderby的列 4.Update.Delete的where条件列 5.Distinct字段需要创建索引 6.多表Join连接操作时,创建索引注意事项 7.使用列的类型小的创建索引 8.使用字符串前缀创建索引 9.区分度高的列适合作为索引 10.使用最频繁的列放到联合索引的左侧 11.在多个字段都要创建索引的情况下,联合索引由于单值索引 二.不适合创建索引 1.在where中使用不
-
一文弄懂MYSQL如何列转行
目录 一.需求: 二.如何实现 1)首先看我们的静态SQL 2)那么就有人问了,如果我有100门课程不是要写100次名称,这也太麻烦了? 3)这样每次都写一长串sql也很麻烦? 总结 一.需求: 有三张表,学生表.成绩表和课程表,我们可以通过连表查询出学生姓名.课程及对应的成绩: 所需表sql -- ---------------------------- -- Table structure for student -- ---------------------------- DROP TA
-
一文搞懂Python中pandas透视表pivot_table功能详解
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用