Django实现whoosh搜索引擎使用jieba分词
本文介绍了Django实现whoosh搜索引擎使用jieba分词,分享给大家,具体如下:
Django版本:3.0.4
python包准备:
pip install django-haystack pip install jieba
使用jieba分词
1.cd到site-packages内的haystack包,创建并编辑ChineseAnalyzer.py文件
# (注意:pip安装的是django-haystack,但是实际包的文件夹名字为haystack) cd /usr/local/lib/python3.8/site-packages/haystack/backends/ # 创建并编辑ChineseAnalyzer.py文件 vim ChineseAnalyzer.py
2.修改ChineseAnalyzer.py文件内容
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self,
value,
positions=False,
chars=False,
keeporiginal=False,
removestops=True,
start_pos=0,
start_char=0,
mode='',
**kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()
3.替换分词器
cp whoosh_backend.py whoosh_cn_backend.py vim whoosh_cn_backend.py
# 导入ChineseAnalyzer,并将原有的StemmingAnalyser替换为ChineseAnalyzer from .ChineseAnalyzer import ChineseAnalyzer # from whoosh.analysis import StemmingAnalyzer
vim替换命令: %s/StemmingAnalyzer/ChineseAnalyzer/g
4.修改setting.py文件
# 全文搜索框架配置
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
# 'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
# 使用jieba分词
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
},
}
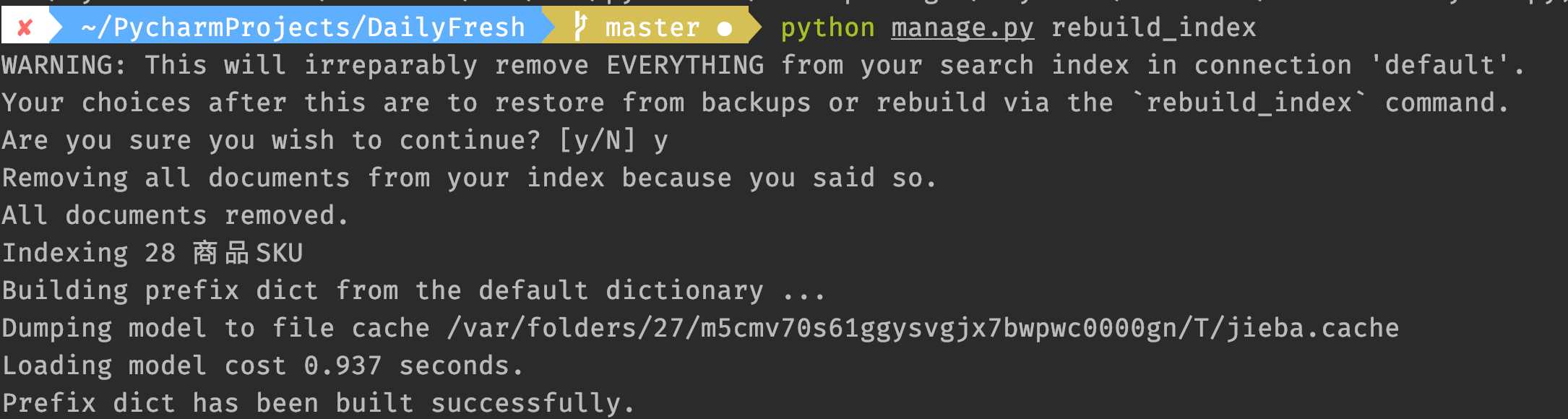
5.重新建立索引
python manage.py rebuild_index
可以看到,已经使用了jieba分词。
到此这篇关于Django实现whoosh搜索引擎使用jieba分词的文章就介绍到这了,更多相关Django jieba分词内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Django之使用haystack+whoosh实现搜索功能
为了实现项目中的搜索功能,我们使用的是全文检索框架haystack+搜索引擎whoosh+中文分词包jieba 安装和配置 安装所需包 pip install django-haystack pip install whoosh pip install jieba 去settings文件注册haystack应用 INSTALLED_APPS = [ 'haystack', # 注册全文检索框架 ] 在settings文件中配置全文检索框架 # 全文检索框架的配置 HAYSTACK_CONNECT
-
Django中使用Whoosh进行全文检索的方法
Whoosh 是纯Python实现的全文搜索引擎,通过Whoosh可以很方便的给文档加上全文索引功能. 什么是全文检索 简单讲分为两块,一块是分词,一块是搜索.比如下面一段话: 上次舞蹈演出直接在上海路的弄堂里 比如我们现在想检索上次的演出,通常我们会直接搜索关键词: 上次演出 ,但是使用传统的SQL like 查询并不能命中上面的这段话,因为在 上次 和 演出 中间还有 舞蹈 .然而全文搜索却将上文切成一个个Token,类似: 上次/舞蹈/演出/直接/在/上海路/的/弄堂/里 切分成Token
-
Django实现whoosh搜索引擎使用jieba分词
本文介绍了Django实现whoosh搜索引擎使用jieba分词,分享给大家,具体如下: Django版本:3.0.4 python包准备: pip install django-haystack pip install jieba 使用jieba分词 1.cd到site-packages内的haystack包,创建并编辑ChineseAnalyzer.py文件 # (注意:pip安装的是django-haystack,但是实际包的文件夹名字为haystack) cd /usr/local/li
-

基于python + django + whoosh + jieba 分词器实现站内检索功能
基于 python django 源码 前期准备 安装库: pip install django-haystack pip install whoosh pip install jieba 如果pip 安装超时,可配置pip国内源下载,如下: pip install -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com <安装的库> pip install -i http://mirrors.al
-
浅谈python jieba分词模块的基本用法
jieba(结巴)是一个强大的分词库,完美支持中文分词,本文对其基本用法做一个简要总结. 特点 支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分析: 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义: 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词. 支持繁体分词 支持自定义词典 MIT 授权协议 安装jieba pip install jieba 简单用法 结巴分词分为三种模式:精确模式(默认).全模式和搜索引擎
-
python jieba分词并统计词频后输出结果到Excel和txt文档方法
前两天,班上同学写论文,需要将很多篇论文题目按照中文的习惯分词并统计每个词出现的频率. 让我帮她实现这个功能,我在网上查了之后发现jieba这个库还挺不错的. 运行环境: 安装python2.7.13:https://www.python.org/downloads/release/python-2713/ 安装jieba:pip install jieba 安装xlwt:pip install xlwt 具体代码如下: #!/usr/bin/python # -*- coding:utf-8
-
Django利用elasticsearch(搜索引擎)实现搜索功能
1.在Django配置搜索结果页的路由映射 """pachong URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/1.10/topics/http/urls/ Examples: Function views 1. Add an import: from my_ap
-
Python基于jieba分词实现snownlp情感分析
情感分析(sentiment analysis)是2018年公布的计算机科学技术名词. 它可以根据文本内容判断出所代表的含义是积极的还是负面的,也可以用来分析文本中的意思是褒义还是贬义. 一般应用场景就是能用来做电商的大量评论数据的分析,比如好评率或者差评率的统计等等. 我们这里使用到的情感分析的模块是snownlp,为了提高情感分析的准确度选择加入了jieba模块的分词处理. 由于以上的两个python模块都是非标准库,因此我们可以使用pip的方式进行安装. pip install jieba
-
python同义词替换的实现(jieba分词)
TihuanWords.txt文档格式 注意:同一行的词用单个空格隔开,每行第一个词为同行词的替换词. 年休假 年假 年休 究竟 到底 回家场景 我回来了 代码 import jieba def replaceSynonymWords(string1): # 1读取同义词表,并生成一个字典. combine_dict = {} # synonymWords.txt是同义词表,每行是一系列同义词,用空格分割 for line in open("TihuanWords.txt", &quo
-
Python中使用haystack实现django全文检索搜索引擎功能
前言 django是python语言的一个web框架,功能强大.配合一些插件可为web网站很方便地添加搜索功能. 搜索引擎使用whoosh,是一个纯python实现的全文搜索引擎,小巧简单. 中文搜索需要进行中文分词,使用jieba. 直接在django项目中使用whoosh需要关注一些基础细节问题,而通过haystack这一搜索框架,可以方便地在django中直接添加搜索功能,无需关注索引建立.搜索解析等细节问题. haystack支持多种搜索引擎,不仅仅是whoosh,使用solr.elas
-
Django集成搜索引擎Elasticserach的方法示例
1.背景 当用户在搜索框输入关键字后,我们要为用户提供相关的搜索结果.可以选择使用模糊查询 like 关键字实现,但是 like 关键字的效率极低.查询需要在多个字段中进行,使用 like 关键字也不方便,另外分词的效果也不理想. 全文检索方案 全文检索即在指定的任意字段中进行检索查询. 全文检索方案需要配合搜索引擎来实现. 搜索引擎原理 搜索引擎 进行全文检索时,会对数据库中的数据进行一遍预处理,单独建立起一份 索引结构数据 . 索引结构数据 类似字典的索引检索页 ,里面包含了关键词与词条的对