python爬虫之爬取笔趣阁小说
前言
为了上班摸鱼方便,今天自己写了个爬取笔趣阁小说的程序。好吧,其实就是找个目的学习python,分享一下。
一、首先导入相关的模块
import os import requests from bs4 import BeautifulSoup
二、向网站发送请求并获取网站数据
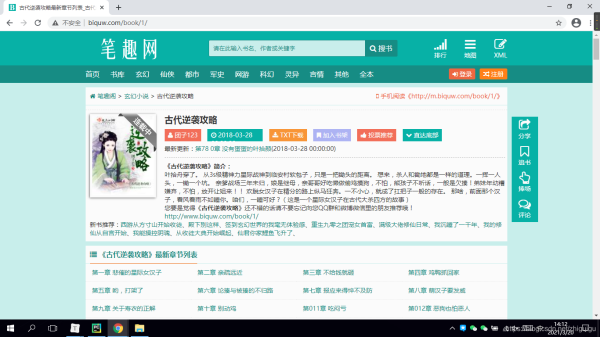
网站链接最后的一位数字为一本书的id值,一个数字对应一本小说,我们以id为1的小说为示例。
进入到网站之后,我们发现有一个章节列表,那么我们首先完成对小说列表名称的抓取
# 声明请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
# 创建保存小说文本的文件夹
if not os.path.exists('./小说'):
os.mkdir('./小说/')
# 访问网站并获取页面数据
response = requests.get('http://www.biquw.com/book/1/').text
print(response)
写到这个地方同学们可能会发现了一个问题,当我去正常访问网站的时候为什么返回回来的数据是乱码呢?
这是因为页面html的编码格式与我们python访问并拿到数据的解码格式不一致导致的,python默认的解码方式为utf-8,但是页面编码可能是GBK或者是GB2312等,所以我们需要让python代码很具页面的解码方式自动变化
#### 重新编写访问代码
```python
response = requests.get('http://www.biquw.com/book/1/')
response.encoding = response.apparent_encoding
print(response.text)
'''
这种方式返回的中文数据才是正确的
'''
三、拿到页面数据之后对数据进行提取
当大家通过正确的解码方式拿到页面数据之后,接下来需要完成静态页面分析了。我们需要从整个网页数据中拿到我们想要的数据(章节列表数据)
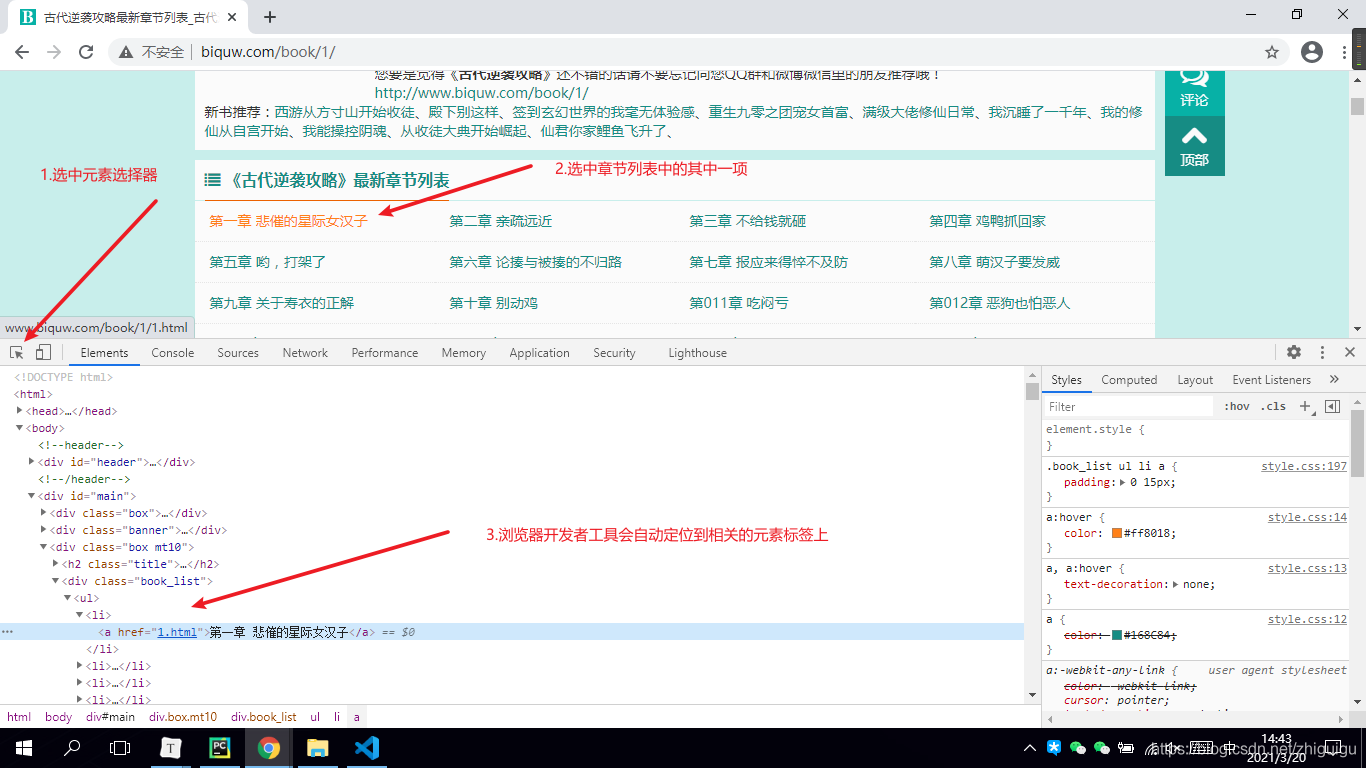
1.首先打开浏览器
2.按F12调出开发者工具
3.选中元素选择器
4.在页面中选中我们想要的数据并定位元素
5.观察数据所存在的元素标签
'''
根据上图所示,数据是保存在a标签当中的。a的父标签为li,li的父标签为ul标签,ul标签之上为div标签。所以如果想要获取整个页面的小说章节数据,那么需要先获取div标签。并且div标签中包含了class属性,我们可以通过class属性获取指定的div标签,详情看代码~
'''
# lxml: html解析库 将html代码转成python对象,python可以对html代码进行控制
soup = BeautifulSoup(response.text, 'lxml')
book_list = soup.find('div', class_='book_list').find_all('a')
# soup对象获取批量数据后返回的是一个列表,我们可以对列表进行迭代提取
for book in book_list:
book_name = book.text
# 获取到列表数据之后,需要获取文章详情页的链接,链接在a标签的href属性中
book_url = book['href']
四、获取到小说详情页链接之后进行详情页二次访问并获取文章数据
book_info_html = requests.get('http://www.biquw.com/book/1/' + book_url, headers=headers)
book_info_html.encoding = book_info_html.apparent_encoding
soup = BeautifulSoup(book_info_html.text, 'lxml')
五、对小说详情页进行静态页面分析
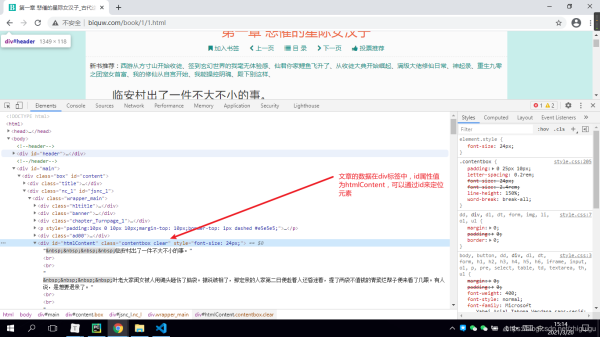
info = soup.find('div', id='htmlContent')
print(info.text)
六、数据下载
with open('./小说/' + book_name + '.txt', 'a', encoding='utf-8') as f:
f.write(info.text)
最后让我们看一下代码效果吧~
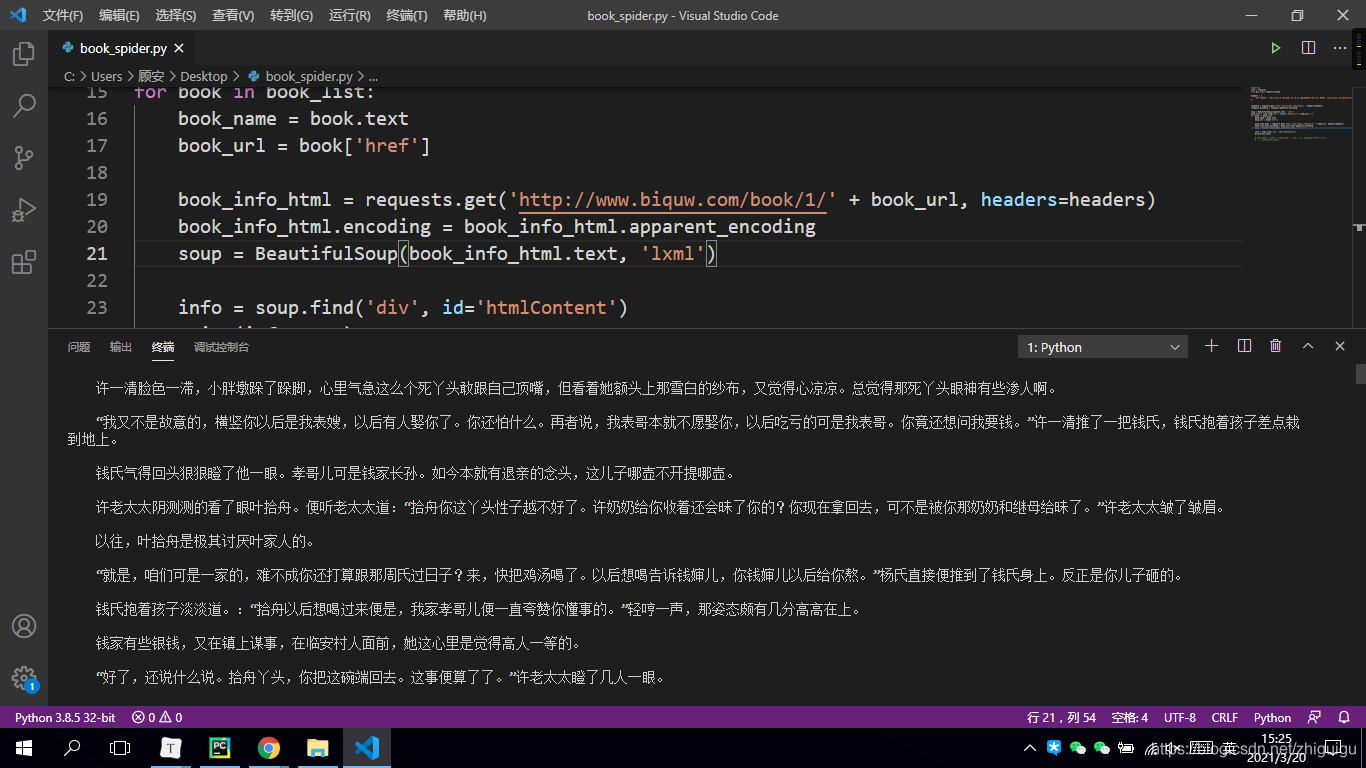
抓取的数据
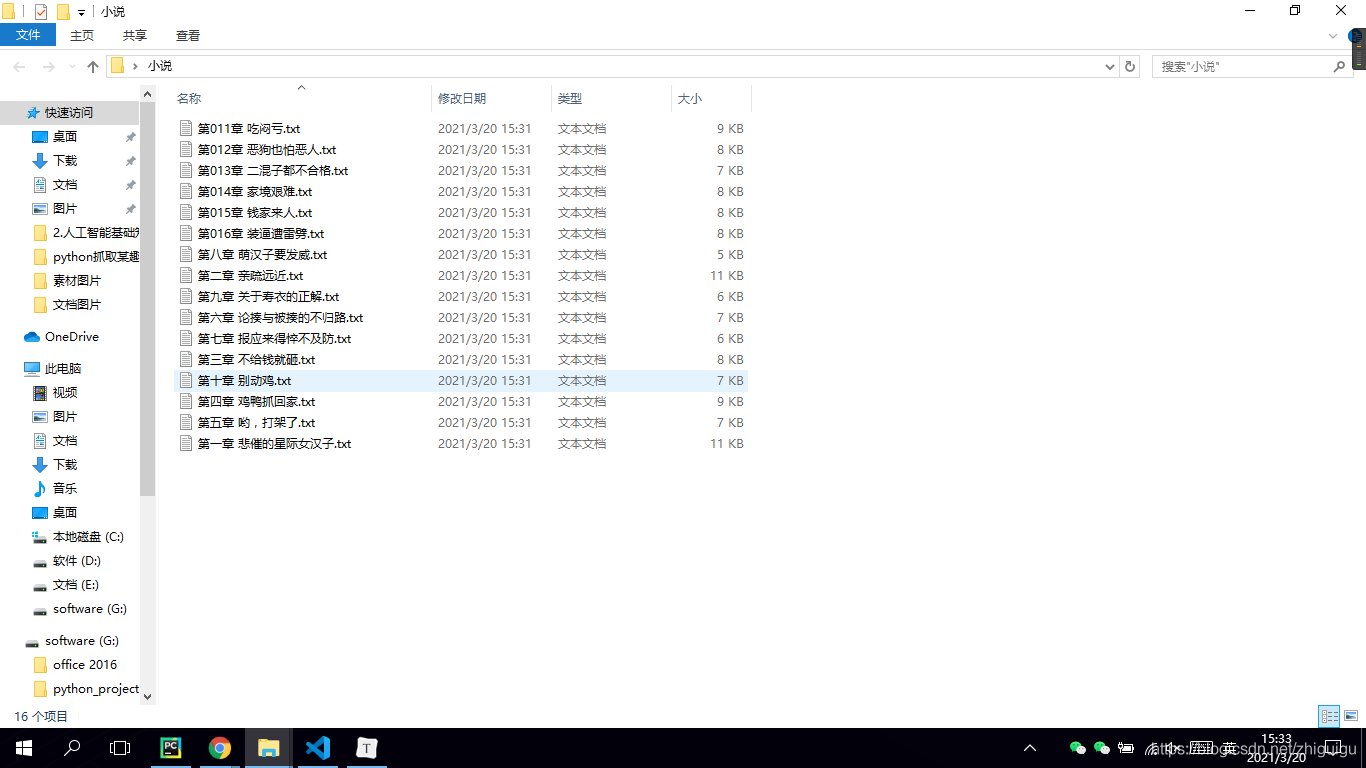
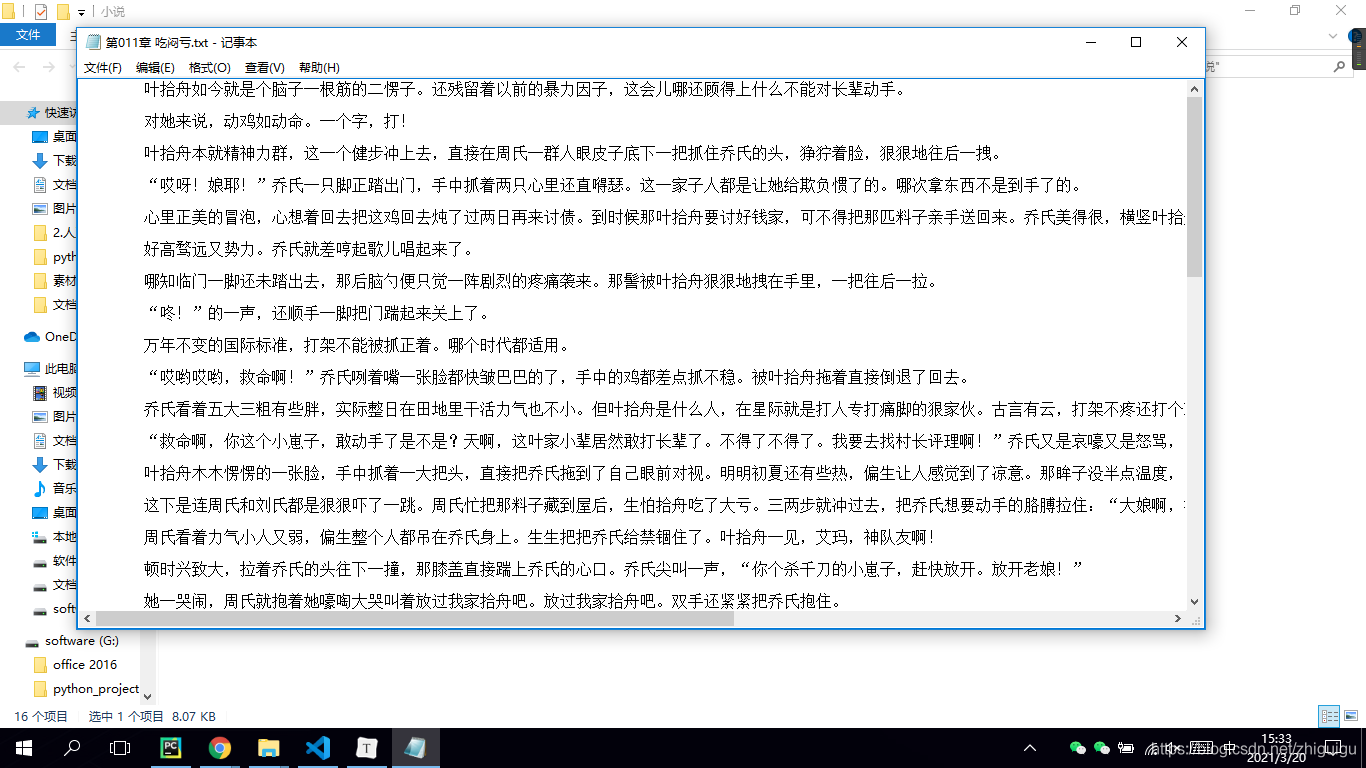
到此这篇关于python爬虫之爬取笔趣阁小说的文章就介绍到这了,更多相关python爬取小说内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python实现的爬取小说爬虫功能示例
本文实例讲述了Python实现的爬取小说爬虫功能.分享给大家供大家参考,具体如下: 想把顶点小说网上的一篇持续更新的小说下下来,就写了一个简单的爬虫,可以爬取爬取各个章节的内容,保存到txt文档中,支持持续更新保存.需要配置一些信息,设置文档保存路径,书名等.写着玩,可能不大规范. # coding=utf-8 import requests from lxml import etree from urllib.parse import urljoin import re import os #
-
python爬虫爬取笔趣网小说网站过程图解
首先:文章用到的解析库介绍 BeautifulSoup: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能. 它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序. Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码. 你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了.然后,你仅仅
-
Python实现爬取逐浪小说的方法
本文实例讲述了Python实现爬取逐浪小说的方法.分享给大家供大家参考.具体分析如下: 本人喜欢在网上看小说,一直使用的是小说下载阅读器,可以自动从网上下载想看的小说到本地,比较方便.最近在学习Python的爬虫,受此启发,突然就想到写一个爬取小说内容的脚本玩玩.于是,通过在逐浪上面分析源代码,找出结构特点之后,写了一个可以爬取逐浪上小说内容的脚本. 具体实现功能如下:输入小说目录页的url之后,脚本会自动分析目录页,提取小说的章节名和章节链接地址.然后再从章节链接地址逐个提取章节内容.现阶段只
-
Python scrapy爬取小说代码案例详解
scrapy是目前python使用的最广泛的爬虫框架 架构图如下 解释: Scrapy Engine(引擎): 负责Spider.ItemPipeline.Downloader.Scheduler中间的通讯,信号.数据传递等. Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎. Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Respon
-
Python爬取365好书中小说代码实例
需要转载的小伙伴转载后请注明转载的地址 需要用到的库 from bs4 import BeautifulSoup import requests import time 365好书链接:http://www.365haoshu.com/ 爬取<我以月夜寄相思>小说 首页进入到目录:http://www.365haoshu.com/Book/Chapter/List.aspx?NovelId=3026 获取小说的每个章节的名称和章节链接 打开浏览器的开发者工具,查找一个章节:如下图,找到第一章的
-

python爬取晋江文学城小说评论(情绪分析)
1. 收集数据 1.1 爬取晋江文学城收藏排行榜前50页的小说信息 获取收藏榜前50页的小说列表,第一页网址为 'http://www.jjwxc.net/bookbase.php?fw0=0&fbsj=0&ycx0=0&xx2=2&mainview0=0&sd0=0&lx0=0&fg0=0&sortType=0&isfinish=0&collectiontypes=ors&searchkeywords=&pa
-
python爬取”顶点小说网“《纯阳剑尊》的示例代码
爬取"顶点小说网"<纯阳剑尊> 代码 import requests from bs4 import BeautifulSoup # 反爬 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, \ like Gecko) Chrome/70.0.3538.102 Safari/537.36' } # 获得请求 def open_url(url):
-
python 爬取小说并下载的示例
代码 import requests import time from tqdm import tqdm from bs4 import BeautifulSoup """ Author: Jack Cui Wechat: https://mp.weixin.qq.com/s/OCWwRVDFNslIuKyiCVUoTA """ def get_content(target): req = requests.get(url = target) r
-
Python爬虫入门教程02之笔趣阁小说爬取
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 前文 01.python爬虫入门教程01:豆瓣Top电影爬取 基本开发环境 Python 3.6 Pycharm 相关模块的使用 request sparsel 安装Python并添加到环境变量,pip安装需要的相关模块即可. 单章爬取 一.明确需求 爬取小说内容保存到本地 小说名字 小说章节名字 小说内容 # 第一章小说url地址 url = 'http://www.biquges.co
-
python爬虫之爬取笔趣阁小说
前言 为了上班摸鱼方便,今天自己写了个爬取笔趣阁小说的程序.好吧,其实就是找个目的学习python,分享一下. 一.首先导入相关的模块 import os import requests from bs4 import BeautifulSoup 二.向网站发送请求并获取网站数据 网站链接最后的一位数字为一本书的id值,一个数字对应一本小说,我们以id为1的小说为示例. 进入到网站之后,我们发现有一个章节列表,那么我们首先完成对小说列表名称的抓取 # 声明请求头 headers = { 'Use
-
python爬虫之爬取笔趣阁小说升级版
python爬虫高效爬取某趣阁小说 这次的代码是根据我之前的 笔趣阁爬取 的基础上修改的,因为使用的是自己的ip,所以在请求每个章节的时候需要设置sleep(4~5)才不会被封ip,那么在计算保存的时间,每个章节会花费6-7秒,如果爬取一部较长的小说时,时间会特别的长,所以这次我使用了代理ip.这样就可以不需要设置睡眠时间,直接大量访问. 一,获取免费ip 关于免费ip,我选择的是站大爷.因为免费ip的寿命很短,所以尽量要使用实时的ip,这里我专门使用getip.py来获取免费ip,代码会爬取最
-
Python爬虫之爬取最新更新的小说网站
一.引言 这个五一假期自驾回老家乡下,家里没装宽带,用手机热点方式访问网络.这次回去感觉4G信号没有以前好,通过百度查找小说最新更新并打开小说网站很慢,有时要打开好多个网页才能找到可以正常打开的最新更新.为了躲懒,老猿决定利用Python爬虫知识,写个简单应用自己查找小说最新更新并访问最快的网站,花了点时间研究了一下相关报文,经过近一天时间研究和编写,终于搞定,下面就来介绍一下整个过程. 二.关于相关访问请求及应答报文 2.1.百度搜索请求 我们通过百度网页的搜索框进行搜索时,提交的url请求是
-
Python爬虫之爬取二手房信息
前言 说到二手房信息,不知道你们心里最先跳出来的公司(网站)是什么,反正我心里第一个跳出来的是网站是 58 同城.哎呦,我这暴脾气,想到就赶紧去干. 但很显然,我失败了.说显然,而不是不幸,这是因为 58 同城是大公司,我这点本事爬不了数据是再正常不过的了.下面来看看 58 同城的反爬手段了.这是我爬取下来的网页源码. 我们看到爬取下来的源码有很多英文大写字母和数字是网页源码中没有的,后来我了解到 58 同城对自己的网站的源码进行了文本加密,所以就出现了我爬取到的情况. 爬取二手房信息 我打开
-
Python爬虫实例爬取网站搞笑段子
众所周知,python是写爬虫的利器,今天作者用python写一个小爬虫爬下一个段子网站的众多段子. 目标段子网站为"http://ishuo.cn/",我们先分析其下段子的所在子页的url特点,可以轻易发现发现为"http://ishuo.cn/subject/"+数字, 经过测试发现,该网站的反扒机制薄弱,可以轻易地爬遍其所有站点. 现在利用python的re及urllib库将其所有段子扒下 import sys import re import urllib
-
Python爬虫实现爬取京东手机页面的图片(实例代码)
实例如下所示: __author__ = 'Fred Zhao' import requests from bs4 import BeautifulSoup import os from urllib.request import urlretrieve class Picture(): def __init__(self): self.headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleW
-
python爬虫之爬取百度音乐的实现方法
在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法.对网页有过接触的都知道很多有用的数据都放在一个共同的父节点上,只是其子节点不同.在上次爬虫中,每一类数据都要从其父类(包括其父节点的父节点)上往下寻找ROI数据所在的子节点,这样就会使爬虫很臃肿,因为很多数据有相同的父节点,每次都要重复的找到这个父节点.这样的爬虫效率很低. 因此,笔者在上次的基础上,改进了一下爬取的策略,笔者以
-
Python爬虫实现爬取百度百科词条功能实例
本文实例讲述了Python爬虫实现爬取百度百科词条功能.分享给大家供大家参考,具体如下: 爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件.爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列.然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页