python自然语言处理之字典树知识总结
一、什么是字典树
在自然语言处理中,字符串集合常用字典树存储,这是一种字符串上的树形数据结构。字典树中每条边都对应一个字,从根节点往下的路径构成一个个字符串。
字典树并不直接在节点上存储字符串,而是将词语视作根节点到某节点之间的一条路径,并在终点节点上做个标记(表明到该节点就结束了)。
要查询一个单词,指需要顺着这条路径从根节点往下走。如果能走到标记的节点,则说明该字符串在集合中,否则说明不在。下图为字典树结构示例:
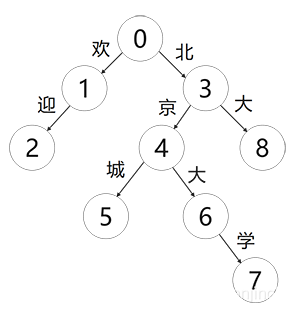
如上图所示,每条路径都是一个词汇,且没有子节点就可以判定该条路径结尾了。具体可以映射为下标所示:
| 词语 | 路径 |
| 欢迎 | 0-1-2 |
| 北大 | 0-3-8 |
| 北京城 | 0-3-4-5 |
| 北京大学 | 0-3-4-6-7 |
至于字典树的实现,相信只要认真学过数据结构的读者,都能手到擒来,这里不在赘述。因为HanLP库已经提供了多种字典树。
二、DoubleArrayTrieSegment
认识DoubleArrayTrieSegment类之前,我们需要了解双数组字典书的概念。
我们都知道,在树中遍历查找之时,我们一般用二分查找,假如某一个树的节点有N个节点,那么其复杂度就为O(logN),这样查找起来一条一条树的遍历会非常的慢,所以就诞生了双数组字典树的概念。
双数组字典树(DAT)是一种状态转移复杂度为常数的数据结构。那么什么是状态呢?从确定有限状态自动机(DFA)的角度来讲,每个节点都是一个状态,状态表示当前已查询到的前缀。
从父节点到子节点的移动过程可以看作一次状态转移。在按照某个字符进行状态转移前,我们会向父节点询问该字符与子节点的映射关系(也就是一条路径一条边)。如果父节点有满足条件的边,则状态转移到子节点;否则立即失败,查询不到。当成功完成了全部转移时,我们就拿到了最后一个状态,询问该状态是否时最终状态。如果是,就查询到该词汇,否则该单词不存在于字典中。
比如我们查询首图的“北京大学”,状态开始为0,查询到北时状态为3,查询到京时状态为4,查询到大时状态为6,查询到学时状态为7,最后判断7是否还有子节点,如果没有匹配该词汇,如果有该词汇不在字典中。比如查询“北京大”就不在词汇中。
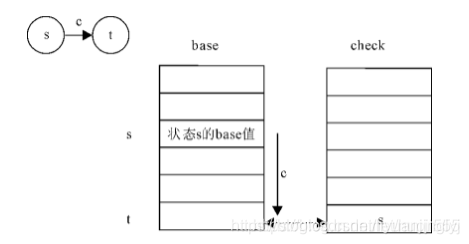
而双数组字典由base与check两个数组组成,其中base数组即节点,也是状态,分为空闲状态与占用状态,check数组为每个元素表示某个状态的前驱状态。具体公式如下:
base[s] + c = t check[t] = s
base树组中的s代表当前状态的下标,t代表转移状态的下标,c代表输入字符的数值
base[s] + c = t //表示一次状态转移
由于转移后状态下标为t,且父子关系是唯一的,所以可通过检验当前元素的前驱状态确定转移是否成功
check[t] = s //检验状态转移是否成功
这种算法相对于传统的Trie树二分查找的优点是,只需要一个加法一次比较即可完成一次状态转移,只花费了常数时间,下面给出了双数组Tree树的原理图(注意观察状态转移的过程)
了解了双数组字典树的原理,我们就可以来学习DoubleArrayTrieSegment,DoubleArrayTrieSegment分词器是对DAT(双数组字典树)最长匹配的封装,默认加载hanlp.properites中CoreDictionaryPath指定的词典。
对应的python代码如下:
if __name__ == "__main__":
HanLP.Config.ShowTermNature=False#分词结果不显示词性
segment=DoubleArrayTrieSegment()
print(segment.seg("在来到这个世界之前,一起都很Happy"))
运行之后,得到如下图所示的结果:

当然,这是HanLP提供给我们的默认词典,如果想加载自己的词典,或者前文提到的其他开源的词典库,可以替换代码如下所示:
DoubleArrayTrieSegment(["词典1","词典2"])
但是不知道读者注意到了没有,上面的英文happy,它给我们拆成了单个的字母,但其实这是一个整体,如果这里替换成数字,也是一个一个数字,那么如何不让其拆开呢?
我们来看一段代码:
if __name__ == "__main__":
HanLP.Config.ShowTermNature=True
segment=DoubleArrayTrieSegment()
segment.enablePartOfSpeechTagging(True)
print(segment.seg("在来到这个世界之前,一起都很Happy"))
enablePartOfSpeechTagging函数的意思是激活数字与英文识别,同时我们把ShowTermNature改为True,观察其输出的结果:

这里与我们前面自己写的算法输出一模一样,有分开的词汇以及词汇的标记属性。
三、AhoCorasickDoubleArrayTrieSegment
虽然双数组字典树能遍历大量的数据,但是如果数据比较长的,这些长的词汇又比较多的话,比如“受命于天,既寿永昌”算一个词汇,那么其处理起来时间复杂度依旧非常耗时。所以,我们就需要使用ACDAT进行遍历。
这里博主不讲解其原理,因为太长篇幅有限,感兴趣的可以专门学习树结构的处理。读者只需要知道其原理,什么时候用双数组遍历,什么时候用ACDAT遍历就行。而HanLP封装的ACDAT的实现类是AhoCorasickDoubleArrayTrieSegment。
下面,我们来实现AhoCorasickDoubleArrayTrieSegment,代码如下:
if __name__ == "__main__":
HanLP.Config.ShowTermNature = False
segment = JClass("com.hankcs.hanlp.seg.Other.AhoCorasickDoubleArrayTrieSegment")()
print(segment.seg("在来到这个世界之前,一起都很井然有序"))
运行之后,效果如下:

需要注意的是,python的HanLP虽然提供了AhoCorasickDoubleArrayTrieSegment类,但是读者可以试试,替换后运行会报错,控制台会提示该类没有seg函数。而HanLP库又是基于Java开发的,所以在实际的项目中,尽量使用JClass加载Java类进行实战,因为python的HanLP库运行速度比Java慢一倍,但python的好处是相对简单,可以调用其他程序的类,所以速度这方面只要python引用Java类进行调用,其实速度一样。
到此这篇关于python自然语言处理之字典树知识总结的文章就介绍到这了,更多相关python字典树内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python编程使用NLTK进行自然语言处理详解
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向.自然语言工具箱(NLTK,NaturalLanguageToolkit)是一个基于Python语言的类库,它也是当前最为流行的自然语言编程与开发工具.在进行自然语言处理研究和应用时,恰当利用NLTK中提供的函数可以大幅度地提高效率.本文就将通过一些实例来向读者介绍NLTK的使用. NLTK NaturalLanguageToolkit,自然语言处理工具包,在NLP领域中,最常使用的一个Python库. NLTK是一个开源的项目,包含:P
-
Python数据结构与算法之字典树实现方法示例
本文实例讲述了Python数据结构与算法之字典树实现方法.分享给大家供大家参考,具体如下: class TrieTree(): def __init__(self): self.root = {} def addNode(self,str): # 树中每个结点(除根节点),包含到该结点的单词数,以及该结点后面出现字母的键 nowdict = self.root for i in range(len(str)): if str[i] not in nowdict: # 发现新的组合方式 nowdi
-
详解字典树Trie结构及其Python代码实现
字典树(Trie)可以保存一些字符串->值的对应关系.基本上,它跟 Java 的 HashMap 功能相同,都是 key-value 映射,只不过 Trie 的 key 只能是字符串. Trie 的强大之处就在于它的时间复杂度.它的插入和查询时间复杂度都为 O(k) ,其中 k 为 key 的长度,与 Trie 中保存了多少个元素无关.Hash 表号称是 O(1) 的,但在计算 hash 的时候就肯定会是 O(k) ,而且还有碰撞之类的问题:Trie 的缺点是空间消耗很高. 至于Trie树的实现
-
Python实现简单字典树的方法
本文实例讲述了Python实现简单字典树的方法.分享给大家供大家参考,具体如下: #coding=utf8 """代码实现了最简单的字典树,只支持由小写字母组成的字符串. 在此代码基础上扩展一下,就可以实现比较复杂的字典树,比如带统计数的,或支持更多字符的字典树, 或者是支持删除等操作. """ class TrieNode(object): def __init__(self): # 是否构成一个完成的单词 self.is_word = Fal
-
Python自然语言处理 NLTK 库用法入门教程【经典】
本文实例讲述了Python自然语言处理 NLTK 库用法.分享给大家供大家参考,具体如下: 在这篇文章中,我们将基于 Python 讨论自然语言处理(NLP).本教程将会使用 Python NLTK 库.NLTK 是一个当下流行的,用于自然语言处理的 Python 库. 那么 NLP 到底是什么?学习 NLP 能带来什么好处? 简单的说,自然语言处理( NLP )就是开发能够理解人类语言的应用程序和服务. 我们生活中经常会接触的自然语言处理的应用,包括语音识别,语音翻译,理解句意,理解特定词语的
-
Python自然语言处理之词干,词形与最大匹配算法代码详解
本文主要对词干提取及词形还原以及最大匹配算法进行了介绍和代码示例,Python实现,下面我们一起看看具体内容. 自然语言处理中一个很重要的操作就是所谓的stemming和lemmatization,二者非常类似.它们是词形规范化的两类重要方式,都能够达到有效归并词形的目的,二者既有联系也有区别. 1.词干提取(stemming) 定义:Stemmingistheprocessforreducinginflected(orsometimesderived)wordstotheirstem,base
-
Python自然语言处理之切分算法详解
一.前言 我们需要分析某句话,就必须检测该条语句中的词语. 一般来说,一句话肯定包含多个词语,它们互相重叠,具体输出哪一个由自然语言的切分算法决定.常用的切分算法有完全切分.正向最长匹配.逆向最长匹配以及双向最长匹配. 本篇博文将一一介绍这些常用的切分算法. 二.完全切分 完全切分是指,找出一段文本中的所有单词. 不考虑效率的话,完全切分算法其实非常简单.只要遍历文本中的连续序列,查询该序列是否在词典中即可.上一篇我们获取了词典的所有词语dic,这里我们直接用代码遍历某段文本,完全切分出所有的词
-
用Python进行一些简单的自然语言处理的教程
本月的每月挑战会主题是NLP,我们会在本文帮你开启一种可能:使用pandas和python的自然语言工具包分析你Gmail邮箱中的内容. NLP-风格的项目充满无限可能: 情感分析是对诸如在线评论.社交媒体等情感内容的测度.举例来说,关于某个话题的tweets趋向于正面还是负面的意见?一个新闻网站涵盖的主题,是使用了更正面/负面的词语,还是经常与某些情绪相关的词语?这个"正面"的Yelp点评不是很讽刺么?(祝最后去的那位好运!) 分析语言在文学中的使用,进而衡量词汇或者写作风格随时间/
-
python自然语言处理之字典树知识总结
一.什么是字典树 在自然语言处理中,字符串集合常用字典树存储,这是一种字符串上的树形数据结构.字典树中每条边都对应一个字,从根节点往下的路径构成一个个字符串. 字典树并不直接在节点上存储字符串,而是将词语视作根节点到某节点之间的一条路径,并在终点节点上做个标记(表明到该节点就结束了). 要查询一个单词,指需要顺着这条路径从根节点往下走.如果能走到标记的节点,则说明该字符串在集合中,否则说明不在.下图为字典树结构示例: 如上图所示,每条路径都是一个词汇,且没有子节点就可以判定该条路径结尾了.具体可
-
Python利用字典树实现猎词游戏
目录 解决策略 什么是 Trie? 创建 Trie 字典树 单词测试 总结 猎词(word hunt)是一类很常见的游戏,给你一张字母组成的表,然后让你在这些字母中尽可能多的去寻找单词.这类游戏有不同的变体,一类是你可以多次重复使用这些字母(这类游戏叫做猎词),或者你只能使用一次每个字母(这类游戏叫做字母重组).你组出来的单词越长就得分越高,使用了所有字母就可以获得最高分. 这类游戏对计算机而言是很「容易」去完成的,而且要强调一个相当有用的数据结构叫做 “Trie”. 解决策略 让我们先拿出一个
-
字典树的基本知识及使用C语言的相关实现
概念 如果我们有and,as,at,cn,com这些关键词,那么trie树(字典树)是这样的: 从上面的图中,我们或多或少的可以发现一些好玩的特性. 第一:根节点不包含字符,除根节点外的每一个子节点都包含一个字符. 第二:从根节点到某一节点,路径上经过的字符连接起来,就是该节点对应的字符串. 第三:每个单词的公共前缀作为一个字符节点保存. 使用范围 既然学Trie树,我们肯定要知道这玩意是用来干嘛的. 第一:词频统计. 可能有人要说了,词频统计简单啊,一个hash或者一个堆就可以打完收工,但问题
-
浅谈Python类的单继承相关知识
一.类的继承 面向对象三要素之一,继承Inheritance 人类和猫类都继承自动物类. 个体继承自父母,继承了父母的一部分特征,但也可以有自己的个性. 在面向对象的世界中,从父类继承,就可以直接拥有父类的属性和方法,这样就可以减少代码.多服用.子类可以定义自己的属性和方法 class Animal: def __init__(self,name): self._name = name def shout(self): print("{} shouts".format(self.__c
-
Python基于回溯法子集树模板实现8皇后问题
本文实例讲述了Python基于回溯法子集树模板实现8皇后问题.分享给大家供大家参考,具体如下: 问题 8×8格的国际象棋上摆放八个皇后,使其不能互相攻击,即任意两个皇后都不能处于同一行.同一列或同一斜线上,问有多少种摆法. 分析 为了简化问题,考虑到8个皇后不同行,则每一行放置一个皇后,每一行的皇后可以放置于第0.1.2.....7列,我们认为每一行的皇后有8种状态.那么,我们只要套用子集树模板,从第0行开始,自上而下,对每一行的皇后,遍历它的8个状态即可. 代码: ''' 8皇后问题 '''