python数据分析之如何删除value=0的行
目录
- 前言
- 一、数据处理
- 二、删除某行方法的使用
- 总结
前言
拿到一堆数据,首先我们是要对其进行数据的预处理,其中数据存在一些值为空或者是我们不想要的数据,对其进行删除或者是修改数据值。下面是对于该例子进行删除和修改:
>>> df out[]: salary age gender 0 10000 23 男 1 15000 34 女 2 23000 21 男 3 0 20 女 4 28500 0 男 5 35000 37 男
一、数据处理
1. df.replace()方法:将“男”用1来表示,“女孩”用0来表示。
>>> df.replace(["男", "女"], [1, 0]) out[]: salary age gender 0 10000 23 1 1 15000 34 0 2 23000 21 1 3 0 20 0 4 28500 0 1 5 35000 37 1
2. pd.DataFrame.loc()方法来指定列中数据为0的行:
>>> df = df.loc[~((df['salary'] == 0) | (df['age'] == 0))] >>> df out[]: salary age gender 0 10000 23 1 1 15000 34 0 2 23000 21 1 3 35000 37 1
还可以用:
df = df.loc[df['salary'] * df['age'] != 0]
二、删除某行方法的使用
1.删除全行都是为0的行
代码如下:
>>> df.loc[~(df==0).all(axis=1)]
看起来比较对称可以这样写:
>>> df.loc[(df!=0).any(axis=1)]
使用dropna方法来删除:
>>> new_df = df[df.loc[:]!=0].dropna()
2.用nan替换零,然后删除所有行中数据都为nan的行。之后,将nan替换为零。
代码如下:
import numpy as np df = df.replace(0, np.nan)# 把0替换成nan df = df.dropna(how='all', axis=0)# 删除所有为nan的行 df = df.replace(np.nan, 0)# 再把nan替换成0
3.删除某行中某个值为0的行
代码如下:|
>>> df= df[df['salary'] != 0]
4.使用lambda函数来删除行
代码如下:
import pandas as pd
import numpy as np
np.random.seed(0)
df = pd.DataFrame(np.random.randn(5,3),
index=['one', 'two', 'three', 'four', 'five'],
columns=list('abc'))
df.loc[['one', 'three']] = 0 # 把第一行和第三行改为0
print(df)
print(df.loc[~df.apply(lambda row: (row==0).all(), axis=1)])
输出为:

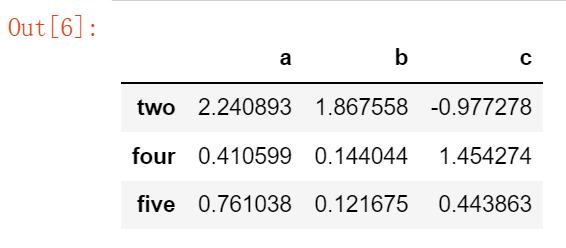
要在任何行中删除所有值为0的列:
new_df = df[df.loc[:]!=0].dropna() new_df
输出为:
总结
到此这篇关于python数据分析之如何删除value=0行的文章就介绍到这了,更多相关python删除value=0的行内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python数据分析之如何删除value=0的行
目录 前言 一.数据处理 二.删除某行方法的使用 总结 前言 拿到一堆数据,首先我们是要对其进行数据的预处理,其中数据存在一些值为空或者是我们不想要的数据,对其进行删除或者是修改数据值.下面是对于该例子进行删除和修改: >>> df out[]: salary age gender 0 10000 23 男 1 15000 34 女 2 23000 21 男 3 0 20 女 4 28500 0 男 5 35000 37 男 一.数据处理 1. df.replace()方法:将“男”用1
-

Python数据分析之 Pandas Dataframe修改和删除及查询操作
目录 一.查询操作 元素的查询 二.修改操作 行列索引的修改 元素值的修改 三.行和列的删除操作 一.查询操作 可以使用Dataframe的index属性和columns属性获取行.列索引. import pandas as pd data = {"name": ["Alice", "Bob", "Cindy", "David"], "age": [25, 23, 28, 24], &q
-
详解Python数据分析--Pandas知识点
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘 1. 重复值的处理 利用drop_duplicates()函数删除数据表中重复多余的记录, 比如删除重复多余的ID. import pandas as pd df = pd.DataFrame({"ID": ["A1000","A1001","A1002", "A1002"], "departmentId":
-
基于Python数据分析之pandas统计分析
pandas模块为我们提供了非常多的描述性统计分析的指标函数,如总和.均值.最小值.最大值等,我们来具体看看这些函数: 1.随机生成三组数据 import numpy as np import pandas as pd np.random.seed(1234) d1 = pd.Series(2*np.random.normal(size = 100)+3) d2 = np.random.f(2,4,size = 100) d3 = np.random.randint(1,100,size = 1
-
python数据分析之公交IC卡刷卡分析
一.背景 交通大数据是由交通运行管理直接产生的数据(包括各类道路交通.公共交通.对外交通的刷卡.线圈.卡口.GPS.视频.图片等数据).交通相关行业和领域导入的数据(气象.环境.人口.规划.移动通信手机信令等数据),以及来自公众互动提供的交通状况数据(通过微博.微信.论坛.广播电台等提供的文字.图片.音视频等数据)构成的. 现在给出了一个公交刷卡样例数据集,包含有交易类型.交易时间.交易卡号.刷卡类型.线路号.车辆编号.上车站点.下车站点.驾驶员编号.运营公司编号等.试导入该数据集并做分析. 二
-
python数据分析之用sklearn预测糖尿病
一.数据集描述 本数据集内含十个属性列 Pergnancies: 怀孕次数 Glucose:血糖浓度 BloodPressure:舒张压(毫米汞柱) SkinThickness:肱三头肌皮肤褶皱厚度(毫米) Insulin:两个小时血清胰岛素(μU/毫升) BMI:身体质量指数,体重除以身高的平方 Diabets Pedigree Function: 疾病血统指数 是否和遗传相关,Height:身高(厘米) Age:年龄 Outcome:0表示不患病,1表示患病. 任务:建立机器学习模型以准确预
-
Python数据分析之Python和Selenium爬取BOSS直聘岗位
一.数据爬取的代码 #encoding='utf-8' from selenium import webdriver import time import re import pandas as pd import os def close_windows(): #如果有登录弹窗,就关闭 try: time.sleep(0.5) if dr.find_element_by_class_name("jconfirm").find_element_by_class_name("c
-
简单且有用的Python数据分析和机器学习代码
为什么选择Python进行数据分析? Python是一门动态的.面向对象的脚本语言,同时也是一门简约,通俗易懂的编程语言.Python入门简单,代码可读性强,一段好的Python代码,阅读起来像是在读一篇外语文章.Python这种特性称为"伪代码",它可以使你只关心完成什么样的工作任务,而不是纠结于Python的语法. 另外,Python是开源的,它拥有非常多优秀的库,可以用于数据分析及其他领域.更重要的是,Python与最受欢迎的开源大数据平台Hadoop具有很好的兼容性.因此,学习
-
Python数据分析的八种处理缺失值方法详解
目录 1. 删除有缺失值的行或列 2. 删除只有缺失值的行或列 3. 根据阈值删除行或列 4. 基于特定的列子集删除 5. 填充一个常数值 6. 填充聚合值 7. 替换为上一个或下一个值 8. 使用另一个数据框填充 总结 技术交流 在本文中,我们将介绍 8 种不同的方法来解决缺失值问题,哪种方法最适合特定情况取决于数据和任务.欢迎收藏学习,喜欢点赞支持,技术交流可以文末加群,尽情畅聊. 让我们首先创建一个示例数据框并向其中添加一些缺失值. 我们有一个 10 行 6 列的数据框. 下一步是添加缺失
-
Python数据分析之缺失值检测与处理详解
目录 检测缺失值 缺失值处理 删除缺失值 填补缺失值 检测缺失值 我们先创建一个带有缺失值的数据框(DataFrame). import pandas as pd df = pd.DataFrame( {'A': [None, 2, None, 4], 'B': [10, None, None, 40], 'C': [100, 200, None, 400], 'D': [None, 2000, 3000, None]}) df 数值类缺失值在 Pandas 中被显示为 NaN (Not A N