解决 Redis 数据倾斜、热点等问题
目录
- 什么是数据倾斜?
- 数据倾斜有哪些原因呢?
- 1、存在大key
- 2、HashTag 使用不当
- 3、slot 槽位分配不均
Redis 作为一门主流技术,应用场景非常多,很多大中小厂面试都列为重点考察内容
前几天有星球小伙伴学习时,遇到下面几个问题,来咨询 Tom哥
考虑到这些问题比较高频,工作中经常会遇到,这里写篇文章系统讲解下
问题描述:
1.如果redis集群出现数据倾斜,数据分配不均,该如何解决?
2.处理hotKey时,为key创建多个副本,如k-1,k-2…, 如何让这些副本能均匀写入?如何均匀访问?
3.redis使用hash slot来维护集群。与一致性哈希类似,都可以避免全量迁移。为什么不直接使用一致性hash?
分布式缓存作为性能加速器,在系统优化中承担着非常重要的角色。相比本地缓存,虽然增加了一次网络传输,大约占用不到 1 毫秒外,但是却有集中化管理的优势,并支持非常大的存储容量。
分布式缓存领域,目前应用比较广泛的要数 Redis 了,该框架是纯内存储存,单线程执行命令,拥有丰富的底层数据结构,支持多种维度的数据存储和查找。
当然,数据量一大,各种问题就出现了,比如:数据倾斜、数据热点等
什么是数据倾斜?
单台机器的硬件配置有上限制约,一般我们会采用分布式架构将多台机器组成一个集群,下图的集群就是由三台Redis单机组成。客户端通过一定的路由策略,将读写请求转发到具体的实例上。
由于业务数据特殊性,按照指定的分片规则,可能导致不同的实例上数据分布不均匀,大量的数据集中到了一台或者几台机器节点上计算,从而导致这些节点负载多大,而其他节点处于空闲等待中,导致最终整体效率低下。
数据倾斜有哪些原因呢?
1、存在大key
比如存储一个或多个 String 类型的 bigKey 数据,内存占用很大。
Tom哥之前排查过这种问题,有同事开发时为了省事,采用JSON格式,将多个业务数据合并到一个 value,只关联一个key,导致了这个键值对容量达到了几百M。
频繁的大key读写,内存资源消耗比较重,同时给网络传输带了极大的压力,进而导致请求响应变慢,引发雪崩效应,最后系统各种超时报警。
解决方案:
办法非常简单,采用化整为零的策略,将一个bigKey拆分为多个小key,独立维护,成本会降低很多。当然这个拆也讲究些原则,既要考虑业务场景也要考虑访问场景,将关联紧密的放到一起。
比如:有个RPC接口内部对 Redis 有依赖,之前访问一次就可以拿到全部数据,拆分将要控制单值的大小,也要控制访问的次数,毕竟调用次数增多了,会拉大整体的接口响应时间。
2、HashTag 使用不当
Redis 采用单线程执行命令,从而保证了原子性。当采用集群部署后,为了解决mset、lua 脚本等对多key 批量操作,为了保证不同的 key 能路由到同一个 Redis 实例上,引入了 HashTag 机制。
用法也很简单,使用
{}大括号,指定key只计算大括号内字符串的哈希,从而将不同key的健值对插入到同一个哈希槽。
举个例子:
192.168.0.1:6380> CLUSTER KEYSLOT testtag
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT {testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey1{testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey2{testtag}
(integer) 764
check 下业务代码,有没有引入HashTag,将太多的key路由到了一个实例。结合具体场景,考虑如何做下拆分。
就像 RocketMQ 一样,很多时候只要能保证分区有序,就可以满足我们的业务需求。具体实战中,要找到这个平衡点,而不是为了解决问题而解决问题。
3、slot 槽位分配不均
如果采用 Redis Cluster 的部署方式,集群中的数据库被分为16384个槽(slot),数据库中的每个健都属于这16384个槽的其中一个,集群中的每个节点可以处理的0个或最多16384个槽。
你可以手动做迁移,将一个比较大的 slot 迁移到稍微空闲的机器上,保证存储和访问的均匀性。
什么是缓存热点?
缓存热点是指大部分甚至所有的业务请求都命中同一份缓存数据,给缓存服务器带来了巨大压力,甚至超过了单机的承载上限,导致服务器宕机。
解决方案:
解决方案:
1、复制多份副本
我们可以在key的后面拼上有序编号,比如key#01、key#02。。。key#10多个副本,这些加工后的key位于多个缓存节点上。
客户端每次访问时,只需要在原key的基础上拼接一个分片数上限的随机数,将请求路由不到的实例节点。
注意:缓存一般都会设置过期时间,为了避免缓存的集中失效,我们对缓存的过期时间尽量不要一样,可以在预设的基础上增加一个随机数。
至于数据路由的均匀性,这个由 Hash 算法来保证
2、本地内存缓存
把热点数据缓存在客户端的本地内存中,并且设置一个失效时间。对于每次读请求,将首先检查该数据是否存在于本地缓存中,如果存在则直接返回,如果不存在再去访问分布式缓存的服务器。
好思路
本地内存缓存彻底“解放”了缓存服务器,不会对缓存服务器有任何压力。
缺点:实时感知最新的缓存数据有点麻烦,会产生数据不一致的情况。我们可以设置一个比较短的过期时间,采用被动更新。当然,也可以用监控机制,如果感知到数据已经发生了变化,及时更新本地缓存。
Redis Cluster 为什么不用一致性Hash?
Redis Cluster 集群有16384个哈希槽,每个
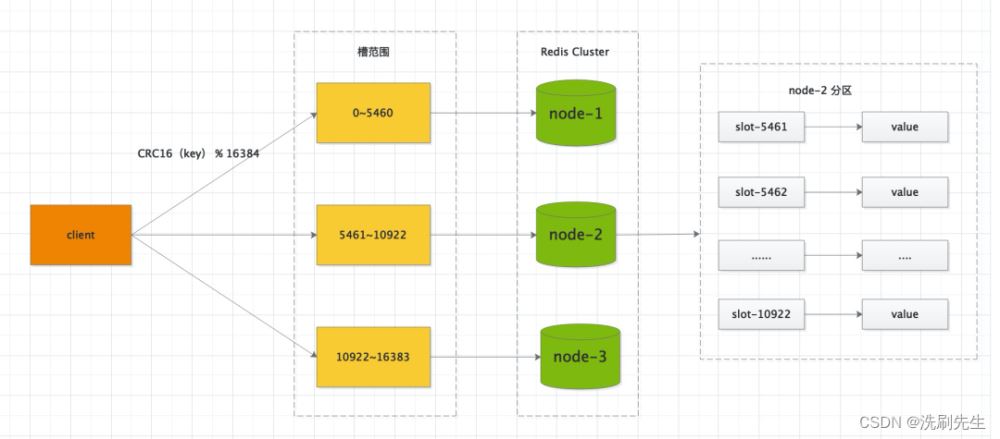
key通过CRC16校验后对16384取模来决定放置哪个槽。集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么node-1包含 0 到 5460 号哈希槽,node-2包含 5461 到 10922 号哈希槽,node-3包含 10922 到 16383 号哈希槽。
一致性哈希算法是 1997年麻省理工学院的 Karger 等人提出了,为的就是解决分布式缓存的问题。
一致性哈希算法本质上也是一种取模算法,不同于按服务器数量取模,一致性哈希是对固定值 2^32 取模。
公式 = hash(key) % 2^32
其取模的结果必然是在 [0, 2^32-1] 这个区间中的整数,从圆上映射的位置开始顺时针方向找到的第一个节点即为存储key的节点
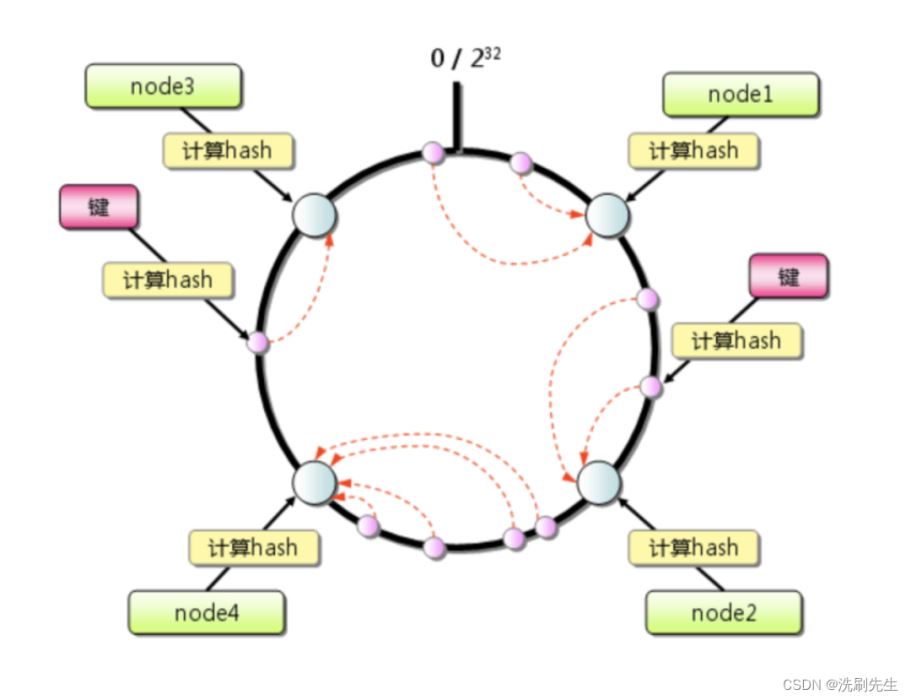
一致性哈希算法大大缓解了扩容或者缩容导致的缓存失效问题,只影响本节点负责的那一小段key。如果集群的机器不多,且平时单机的负载水位很高,某个节点宕机带来的压力很容易引发雪崩效应。
举个例子:
Redis 集群 总共有4台机器,假设数据分布均衡,每台机器承担 四分之一的流量,如果某一台机器突然挂了,顺时针方向下一台机器将要承担这多出来的 四分之一 流量,最终要承担 二分之一 的流量,还是有点恐怖。
但是如果采用 CRC16计算后,并结合槽位与实例的绑定关系,无论是扩容还是缩容,只需将相应节点的key做下数据平滑迁移,广播存储新的槽位映射关系,不会产生缓存失效,灵活性很高。
另外,如果服务器节点配置存在差异化,我们可以自定义分配不同节点负责的 slot 编号,调整不同节点的负载能力,非常方便。
当然可能有些小伙伴会好奇,Redis Cluster 为什么是 16384 个槽位?可以看下 Tom哥 之前写的一篇文章
到此这篇关于如何解决 Redis 数据倾斜、热点等问题的文章就介绍到这了,更多相关Redis 数据倾斜、热点内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

面试分析分布式架构Redis热点key大Value解决方案
目录 引言 1.面试官:你在项目中有没有遇到Redis热点数据问题,一般都是什么原因引起的? 2.面试官:真实项目中,那热点数据问题你是如何准确定位的呢? 3.如何解决热点数据问题 4.面试官:关于Redis最后一个问题,Redis支持丰富的数据类型,那么这些数据类型存储的大Value如何解决,线上有遇到这种情况吗? 总结 引言 关于 Redis 热点数据 & 大 key 大 value 问题也是容易被问的高阶问题,不如一次痛快点说完,让面试官无话可说,个人工作经验中,热点数据问题在工作中相比雪
-
Redis缓存及热点key问题解决方案
今天又学到了很多,感觉雪崩和穿透很有意思理解起来也比较清晰,然后我搜索了一些资料,给自己做一个普及 我们通常使用 缓存 + 过期时间的策略来帮助我们加速接口的访问速度,减少了后端负载,同时保证功能的更新 缓存穿透 缓存系统,按照KEY去查询VALUE,当KEY对应的VALUE一定不存在的时候并对KEY并发请求量很大的时候,就会对后端造成很大的压力. (查询一个必然不存在的数据.比如文章表,查询一个不存在的id,每次都会访问DB,如果有人恶意破坏,很可能直接对DB造成影响.) 由于缓存不命中,每次
-
浅析Redis 切片集群的数据倾斜问题
目录 Redis 中如何应对数据倾斜 什么是数据倾斜 数据量倾斜 bigkey导致倾斜 Slot分配不均衡导致倾斜 Hash Tag导致倾斜 数据访问倾斜 总结 参考 Redis 中如何应对数据倾斜 什么是数据倾斜 如果 Redis 中的部署,采用的是切片集群,数据是会按照一定的规则分散到不同的实例中保存,比如,使用 Redis Cluster 或 Codis. 数据倾斜会有下面两种情况: 1.数据量倾斜:在某些情况下,实例上的数据分布不均衡,某个实例上的数据特别多. 2.数据访问倾斜:虽然每个
-
解决 Redis 数据倾斜、热点等问题
目录 什么是数据倾斜? 数据倾斜有哪些原因呢? 1.存在大key 2.HashTag 使用不当 3.slot 槽位分配不均 Redis 作为一门主流技术,应用场景非常多,很多大中小厂面试都列为重点考察内容 前几天有星球小伙伴学习时,遇到下面几个问题,来咨询 Tom哥 考虑到这些问题比较高频,工作中经常会遇到,这里写篇文章系统讲解下 问题描述: 1.如果redis集群出现数据倾斜,数据分配不均,该如何解决? 2.处理hotKey时,为key创建多个副本,如k-1,k-2…, 如何让这些副本能均匀写
-
解决redis与Python交互取出来的是bytes类型的问题
基本代码 from redis import * if __name__ == '__main__': sr = StrictRedis(host='localhost', port=6379, db=0) result=sr.set('name','python') print(result) result1 = sr.get('name') print(result1) 运行结果: True b'python' 这里我们存进去的是字符串类型的数据,取出来却是字节类型的,这是由于python3
-
为什么断电后Redis数据不会丢失
目录 前言 Redis 持久化机制 RDB 持久化机制 RDB 机制触发条件 自动触发 RDB 机制相关配置文件 RDB 机制优点 RDB 机制缺点 AOF 持久化机制 AOF 机制如何开启 AOF 机制数据是否实时写入磁盘 AOF 文件重写 AOF 重写缓冲区 AOF 机制触发条件 AOF 机制机制优点 AOF 机制机制缺点 总结 前言 Redis 作为一款内存数据库,被广泛使用于缓存,分布式锁等场景,那么假如断电或者因其他因素导致 Reids 服务宕机,在重启之后数据会丢失吗? Redis
-
Redisson如何解决Redis分布式锁提前释放问题
目录 前言: 一.问题描述: 二.原因分析: 三.解决方案: 1.思考: 2.Redisson简单配置: 3.使用样例: 四.源码分析 1.lock加锁操作 2.unlock解锁操作 总结: 相关参考: 前言: 在分布式场景下,相信你或多或少需要使用分布式锁来访问临界资源,或者控制耗时操作的并发性. 当然,实现分布式锁的方案也比较多,比如数据库.redis.zk 等等.本文主要结合一个线上案例,讲解 redis 分布式锁的相关实现. 一.问题描述: 某天线上出现了数据重复处理问题,经排查后发现,
-
AngularJS ng-repeat指令中使用track by子语句解决重复数据遍历错误问题
本文实例讲述了AngularJS ng-repeat指令中使用track by子语句解决重复数据遍历错误问题.分享给大家供大家参考,具体如下: 我们可以使用ng-repeat指令遍历一个JavaScript数组,当数组中有重复元素的时候,AngularJS会报错: Error: [ngRepeat:dupes] Duplicates in a repeater are not allowed. Use 'track by' expression to specify unique keys. R
-
redis数据的两种持久化方式对比
一.概念介绍 redis提供了两种持久化的方式,分别是RDB(Redis DataBase)和AOF(Apend Only File). RDB方式 RDB方式是一种快照式的持久化方法,将某一时刻的数据持久化到磁盘中. •redis在进行数据持久化的过程中,会先将数据写入到一个临时文件中,待持久化过程都结束了,才会用这个临时文件替换上次持久化好的文件.正是这种特性,让我们可以随时来进行备份,因为快照文件总是完整可用的. •对于RDB方式,redis会单独创建(fork)一个子进程来进行持久化,而
-
简单粗暴的Redis数据备份和恢复方法
示例 目标:把服务器CentOS上的redis数据复制到Mac机上 步骤: 在CentOS上找dump文件位置 vi /etc/redis.conf dbfilename dump.rdb dir /var/lib/redis 说明文件在 /var/lib/redis/dump.rdb 在mac上查找dump文件位置 vi /usr/local/etc/redis.conf dbfilename dump.rdb dir /usr/local/var/db/redis 拷贝服务器上的dump.r
-
解决JSON数据因为null导致数据加载失败的方法
一.首先分析问题: 使用NSJSONSerialization或者AFN框架的AFHTTPSessionManager(底层也是NSJSONSerialization)将NSData数据转化成OC对象,有时会出现URL正确,加载数据任然会报错: reason: '-[NSNull length]: unrecognized selector sent to instance 分析原因发现,转化出来的OC对象中含有null.所以,NSNull没有length方法,所以会报找不到方法错误. 二.解决
-
C++开发的Redis数据导入工具优化
背景 使用C++开发了一个Redis数据导入工具 从oracle中将所有表数据导入到redis中: 不是单纯的数据导入,每条oracle中的原有记录,需要经过业务逻辑处理, 并添加索引(redis集合): 工具完成后,性能是个瓶颈: 优化效果 使用了2个样本数据测试: 样本数据a表8763 条记录: b表940279 条记录: 优化前,a表耗时11.417s: 优化后,a表耗时1.883s: 用到的工具 gprof, pstrace,time 使用time工具查看每次执行的耗时,分别包含用户时间